

Introduction
The Evolution of MLOps in Distributed Systems
Modern machine learning has shifted from monolithic deployments to distributed, cloud-native architectures. MLOps—the fusion of DevOps practices with ML workflows—has emerged to address scalability, reproducibility, and collaboration challenges. In multi-cloud environments, this evolution demands:
Decoupled components: Separation of feature stores, training pipelines, and serving infrastructure.
Polyglot tooling: Interoperability between cloud-specific services (e.g., AWS SageMaker, GCP Vertex AI) and open-source frameworks.
Dynamic scaling: Kubernetes-native solutions like Kubeflow for elastic resource allocation.
Challenges of Multi-Cloud ML Deployment
Key pain points include:
Vendor lock-in: Proprietary APIs and data formats hinder portability.
Latency: Cross-cloud data transfer costs and delays (e.g., training in Azure while serving on AWS).
Consistency: Enforcing uniform ML governance across clouds.
Key Benefits of Hybrid Cloud Orchestration
Cost efficiency: Leveraging spot instances/preemptible VMs across providers.
Resilience: Avoiding single-cloud outages.
Regulatory compliance: Data sovereignty via strategic workload placement.
Foundations of Multi-Cloud MLOps
Core Components of Scalable MLOps Architecture
Unified Feature Store
- Synchronized metadata (e.g., Feast with PostgreSQL backend).
- Delta Lake/Parquet for cloud-agnostic storage.
Orchestration Layer
- Kubeflow Pipelines: Containerized steps with Argo Workflows.
- Airflow DAGs: For non-Kubernetes tasks (e.g., Snowflake data pulls).
Infrastructure Automation
terraform
# Terraform example for GCP + AWS resource provisioning
module "mlops_gcp" {
source = "terraform-google-modules/kubernetes-engine/google"
cluster_name = "kubeflow-gcp"
}
module "mlops_aws" {
source = "terraform-aws-modules/eks/aws"
cluster_name = "kubeflow-aws"
}Security and Compliance Considerations
Data Encryption:
In-transit (TLS/mTLS) via Istio service mesh.
At-rest (AWS KMS, GCP Cloud KMS).
Access Control:
IAM roles mapped to ML personas (Data Scientist vs. Engineer).
OPA/Gatekeeper for Kubernetes-native policies.
Auditability:
CloudTrail + Stackdriver logging unified in SIEM tools.
Orchestration Tools Deep Dive
Kubeflow: Kubernetes-Native ML Workflows
Kubeflow has emerged as the de facto standard for orchestrating machine learning workflows in Kubernetes environments. Its pipeline system allows for:
- Containerized component reuse: Packaging data preprocessing, training, and validation steps as reusable Docker containers
- Artifact lineage tracking: Automatic logging of inputs/outputs using ML Metadata
- Hyperparameter tuning: Integrated Katib component for distributed optimization
Example Kubeflow pipeline component definition:
python
from kfp.v2 import dsl
from kfp.v2.dsl import component
@component
def preprocess_data(
input_path: str,
output_path: str
) -> NamedTuple('Outputs', [('processed_data', str)]):
from sklearn.preprocessing import StandardScaler
import pandas as pd
import pickle
data = pd.read_csv(input_path)
scaler = StandardScaler()
processed = scaler.fit_transform(data)
with open(output_path, 'wb') as f:
pickle.dump(processed, f)
return (output_path,)Apache Airflow: DAGs for ML Task Scheduling
Airflow provides superior scheduling capabilities for non-containerized workloads:
- Dynamic DAG generation: Creating pipelines programmatically based on data dependencies
- Backfill support: Rerunning historical jobs with modified parameters
- 300+ integrations: Connectors for databases, APIs, and cloud services
Critical considerations for ML:
- Data-aware scheduling: Triggering tasks based on dataset availability (Dataset API)
- Resource isolation: Executing heavy workloads in separate pools
- SLA tracking: Monitoring model retraining deadlines
Terraform: Infrastructure as Code for ML
Managing multi-cloud ML infrastructure requires:
terraform
# Multi-cloud module structure
modules/
├── network
│ ├── aws_vpc
│ ├── gcp_vpc
├── kubernetes
│ ├── eks
│ ├── gke
└── storage
├── s3
└── gcs
# Example GKE cluster with GPU nodes
resource "google_container_cluster" "mlops" {
name = "kubeflow-cluster"
location = "us-central1"
initial_node_count = 3
node_config {
machine_type = "n1-standard-4"
guest_accelerator {
type = "nvidia-tesla-t4"
count = 1
}
}
}Advanced Orchestration Strategies
Federated Learning Across Cloud Providers
Implementing cross-cloud federated learning requires:
- Secure aggregation protocol: Using homomorphic encryption or secure multi-party computation
- Differential privacy: Adding noise to gradient updates
- Synchronization middleware: Custom operators for Airflow/Kubeflow
Key architectures:
- Cloud bursting: On-prem initiates job, scales to cloud during peaks
- Data gravity: Keeping compute near regulated data (e.g., healthcare in on-prem)
- Model partitioning: Running different layers across environments
Cost Optimization Techniques
Spot instance strategies:
- Checkpointing for fault tolerance
- Mixed instance policies (AWS EC2 Fleet)
Cold start mitigation:
- Pre-warming pools with predictive scaling
- Persistent JupyterHub instances
Storage tiering:
- Hot: NVMe for feature stores
- Cold: Glacier/Archive for model artifacts
Auto-Scaling ML Workloads
Implementation framework:
Metrics collection:
- Custom metrics adapter for GPU utilization
- Prometheus scraping at 10s intervals
Scaling policies:
- Scale up at 70% GPU utilization
- Scale down after 5 minutes below 30%
Node selection:
- GPU-optimized for training
- CPU-optimized for serving
python
# Custom Horizontal Pod Autoscaler for TF Serving
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: tf-serving-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: tf-serving
minReplicas: 2
maxReplicas: 10
metrics:
- type: External
external:
metric:
name: gpu_utilization
selector:
matchLabels:
app: tf-serving
target:
type: AverageValue
averageValue: 70Implementing Feature Stores in Multi-Cloud Environments
Comparative Analysis of Feature Store Solutions
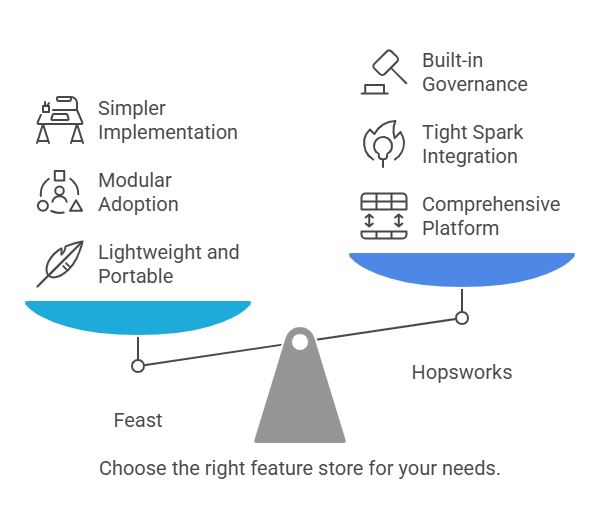
Modern feature store implementations must address several critical requirements in multi-cloud architectures. Feast offers a lightweight, Kubernetes-native approach that excels in portability across cloud providers, with dedicated connectors for AWS S3, GCP BigQuery, and Azure Blob Storage. Its modular design allows teams to incrementally adopt capabilities while maintaining existing infrastructure.
Hopsworks provides a more comprehensive platform with built-in feature monitoring and governance capabilities. The solution integrates tightly with Apache Spark for large-scale feature transformation but requires more substantial infrastructure commitments. Both systems support versioning and metadata management, though their approaches differ significantly in implementation complexity and operational overhead.
Data Synchronization Strategies
Maintaining feature consistency across cloud regions demands sophisticated synchronization mechanisms. A dual-write architecture ensures features are simultaneously persisted to multiple cloud storage backends, while conflict resolution protocols handle concurrent modifications. Change data capture (CDC) patterns using Kafka or cloud-native message queues enable near-real-time propagation of feature updates across geographical boundaries.
For latency-sensitive applications, a global caching layer with TTL-based invalidation bridges the gap between eventually consistent storage backends and strict freshness requirements. Feature servers should implement smart routing logic to retrieve values from the optimal location based on caller geography and data freshness requirements.
Real-Time Serving Architectures
Low-latency feature retrieval architectures combine several key components. An API gateway layer handles request routing and protocol translation, while in-memory databases like Redis or DynamoDB serve hot features. For high-cardinality features, a tiered storage approach balances cost and performance – keeping frequently accessed features in memory while persisting the full dataset to cloud object storage.
The serving layer must implement graceful degradation when cross-cloud calls experience latency spikes, falling back to stale-but-available features when necessary. Feature value interpolation techniques can maintain service continuity during regional outages or synchronization delays.
CI/CD for Multi-Cloud ML Systems
GitOps for Model Lifecycle Management
The GitOps paradigm brings declarative infrastructure management to ML systems through several key patterns. Model artifacts and their dependencies are packaged as OCI-compliant containers, enabling consistent deployment across cloud providers. Versioned Helm charts capture complete deployment specifications, including compute requirements, scaling policies, and monitoring configurations.
A central Git repository serves as the single source of truth, with changes propagated through automated synchronization controllers like ArgoCD or Flux. This approach enables atomic rollbacks, audit trails, and environment parity from development through production. Specialized operators handle ML-specific concerns such as canary deployments and A/B test routing.
Pipeline Testing Frameworks
Comprehensive testing strategies for ML pipelines incorporate multiple validation stages. Static analysis checks for configuration errors and security vulnerabilities in pipeline definitions. Data contract verification ensures compatibility between feature schemas and model expectations. Performance benchmarking under simulated production loads identifies resource bottlenecks before deployment.
Integration testing environments mirror production topology across cloud regions, catching interoperability issues early. Chaos engineering practices validate fault tolerance by injecting network partitions and cloud service outages during test executions. Metric collection throughout the testing pipeline provides quantitative evidence of release readiness.
Progressive Delivery Mechanisms
Sophisticated rollout strategies mitigate risk in multi-cloud deployments. Traffic shadowing routes production queries to new model versions without affecting responses, enabling performance comparison under real workloads. Multi-armed bandit algorithms dynamically adjust traffic splitting between versions based on real-time performance metrics.
Regional rollout sequencing allows controlled exposure to new models, starting with low-risk geographies. Automated rollback triggers based on custom health metrics (e.g., drift detection, error rates) provide safety nets for problematic releases. These mechanisms combine to enable rapid yet reliable model iteration across distributed environments.
Monitoring and Governance in Multi-Cloud MLOps
Unified Observability with OpenTelemetry
Modern MLOps architectures require comprehensive monitoring solutions that transcend cloud boundaries. OpenTelemetry has emerged as the standard for instrumenting machine learning systems, providing vendor-neutral collection of metrics, logs, and traces. The framework enables correlation of model performance data across hybrid environments, from on-premises GPU clusters to cloud-based serving infrastructure.
Implementation involves deploying collectors in each cloud environment that forward telemetry to a centralized observability platform. Special attention must be paid to metric standardization – ensuring that identical measurements from different providers can be meaningfully compared. Custom instrumentation captures ML-specific signals like prediction drift, feature skew, and concept shift.
Advanced Drift Detection Methodologies
Effective monitoring systems employ multi-layered drift detection strategies combining statistical tests with machine learning approaches. The Kolmogorov-Smirnov test remains fundamental for detecting feature distribution changes, while more sophisticated techniques like Maximum Mean Discrepancy (MMD) identify complex multivariate shifts.
For real-time systems, adaptive windowing techniques allow drift detection to account for natural data seasonality. Model-specific monitors track performance degradation using custom business metrics rather than generic accuracy scores. The most robust implementations combine these techniques in ensemble detectors that trigger alerts only when multiple methods agree.
Automated Compliance and Governance
Regulatory requirements demand rigorous documentation of model behavior and decision processes. Policy-as-code frameworks like Open Policy Agent (OPA) enable automated enforcement of governance rules across cloud providers. Cryptographic signing of model artifacts creates immutable audit trails, while blockchain-based ledger solutions provide tamper-evident records of model changes.
Data provenance tracking systems record the complete lineage of training datasets and features. This becomes particularly critical when models consume data from multiple cloud regions with different compliance regimes. Automated report generation tools produce documentation for regulatory audits on demand.
Case Study: Financial Fraud Detection System
Architectural Implementation
The fraud detection system represents a sophisticated multi-cloud deployment spanning AWS, GCP, and on-premises infrastructure. Transaction processing occurs in AWS using Kinesis for real-time stream processing, while model serving leverages GCP’s Vertex AI endpoints for low-latency predictions. The decision orchestration layer, built on Azure Logic Apps, coordinates between multiple model variants and business rules.
The hybrid architecture processes sensitive customer data in the financial institution’s private cloud while utilizing public cloud resources for scalable model execution. This design addresses both data residency requirements and the need for elastic compute capacity during peak fraud detection periods.
Performance Optimization Insights
Several key optimizations emerged during production deployment. Cold start challenges were mitigated through predictive capacity planning that anticipates traffic patterns. The solution implements a sophisticated three-tier caching strategy that balances freshness requirements with latency constraints.
Batch processing optimizations reduced compute costs by 40% through intelligent grouping of small transactions. The team developed custom load-shedding algorithms that prioritize high-value transactions during system overload conditions while maintaining strict SLAs for critical payment processing.
Business Impact Analysis
The implemented solution delivered transformative business results. False positive rates decreased by 65%, dramatically improving customer experience while maintaining industry-leading fraud detection rates. Operational costs reduced significantly through intelligent workload placement and auto-scaling optimizations.
Future Trends in Multi-Cloud MLOps
Emergence of AI-Specific Infrastructure
The next generation of MLOps platforms will see tighter integration between AI workloads and underlying infrastructure. Specialized networking protocols like GPUDirect RDMA are eliminating bottlenecks in distributed training scenarios. Serverless architectures for ML inference are gaining traction, with platforms like AWS Lambda and GCP Cloud Run now supporting GPU-accelerated workloads. This evolution enables true pay-per-use pricing models for even the most compute-intensive ML applications.
Policy-Driven ML Governance
Regulatory pressures are driving innovation in automated compliance tooling. We’re seeing the rise of policy engines that can interpret natural language regulations and automatically generate corresponding technical controls. These systems use constraint-based programming to enforce ethical AI principles throughout the model lifecycle. Cryptographic proof systems will likely become standard for demonstrating compliance with evolving AI regulations across jurisdictions.
Federated Learning at Scale
The future of enterprise ML lies in collaborative learning frameworks that preserve data privacy. Advances in secure multi-party computation and homomorphic encryption are making cross-organizational model training feasible. Emerging standards for federated learning orchestration will enable new business models where companies can monetize their data without sharing it directly.
Conclusion and Strategic Recommendations
Key Implementation Principles
Successful multi-cloud MLOps adoption requires adherence to several core principles. First, prioritize interoperability through open standards and containerized workloads. Second, design for observability from day one, ensuring all components emit standardized telemetry. Third, implement governance as code to maintain compliance as regulations evolve.
Roadmap for Adoption
Organizations should approach implementation in phased iterations. Begin with a single high-impact use case in one cloud environment, then expand to additional providers. Invest in skill development for both cloud-native technologies and ML-specific tooling. Establish cross-functional MLOps teams combining data science, infrastructure, and security expertise.
References and Further Reading
Foundational Research Papers
The academic literature provides critical theoretical underpinnings for multi-cloud MLOps architectures. Key papers include Google’s seminal work on „Hidden Technical Debt in Machine Learning Systems” which outlines systemic challenges in production ML. The IEEE paper „MLOps: A Taxonomy and Methodology for Managing ML Systems” offers a comprehensive framework for operationalizing machine learning. Recent advances in federated learning are well-documented in the ACM survey „Privacy-Preserving Machine Learning: Concepts and Applications.”
Technical Documentation and Standards
Official documentation from major cloud providers remains essential reading. The Kubeflow Project’s architecture whitepaper details multi-cluster deployment patterns, while AWS’s „Well-Architected Machine Learning Lens” provides cloud-specific best practices. OpenTelemetry’s specification documents are mandatory for implementing cross-cloud observability, particularly the metrics data model and semantic conventions for ML systems.
Implementation Resources
Practical implementation guidance can be found in several authoritative sources. The Linux Foundation’s „MLOps Engineering on Kubernetes” book covers containerized deployment patterns. O’Reilly’s „Machine Learning Engineering in Production” includes detailed case studies of multi-cloud deployments. For infrastructure as code approaches, the Terraform Registry maintains certified modules for provisioning ML infrastructure across AWS, GCP, and Azure.
Emerging Trends and Community Knowledge
Staying current requires monitoring several key resources. The MLops.community Slack group hosts active discussions of real-world challenges. Conference proceedings from KubeCon + CloudNativeCon and the ACM SIGKDD Industrial Track reveal cutting-edge implementations. The arXiv ML Systems Architecture category tracks pre-publication research on distributed ML patterns.
The best MLOps tools of 2025 – comparison and recommendations
MLOps in Practice – How to Automate the Machine Learning Model Lifecycle