
Introduction: Bridging Data Science and Business Goals
In recent years, machine learning has become a key driver of innovation across industries. However, the true value of data science is realized only when models move beyond experimentation and start delivering measurable business outcomes. This is where MLOps—Machine Learning Operations—comes into play. MLOps is a set of practices and tools that enable organizations to streamline the deployment, monitoring, and management of machine learning models in production environments.
The gap between data science and business value often arises from challenges in operationalizing models. Data scientists may develop highly accurate models, but without robust processes for deployment and maintenance, these models rarely make a tangible impact. MLOps bridges this gap by introducing automation, collaboration, and governance into the machine learning lifecycle. As a result, organizations can accelerate the journey from data exploration to delivering solutions that address real business needs.
The Role of MLOps in Modern Organizations
MLOps plays a transformative role in how organizations leverage machine learning. It provides a framework for integrating data science workflows with IT operations and business processes, ensuring that models are not only built efficiently but also deployed, monitored, and improved continuously.
By adopting MLOps, organizations can achieve several key objectives. First, they can reduce the time it takes to move models from development to production, enabling faster innovation and responsiveness to market changes. Second, MLOps ensures consistency and reliability by automating repetitive tasks such as testing, deployment, and monitoring. This reduces the risk of human error and increases the stability of machine learning systems.
Moreover, MLOps fosters collaboration between data scientists, engineers, and business stakeholders. It encourages the use of standardized tools and processes, making it easier to track experiments, reproduce results, and comply with regulatory requirements. Ultimately, MLOps helps organizations turn data science initiatives into scalable, maintainable, and valuable business solutions, unlocking the full potential of machine learning investments.
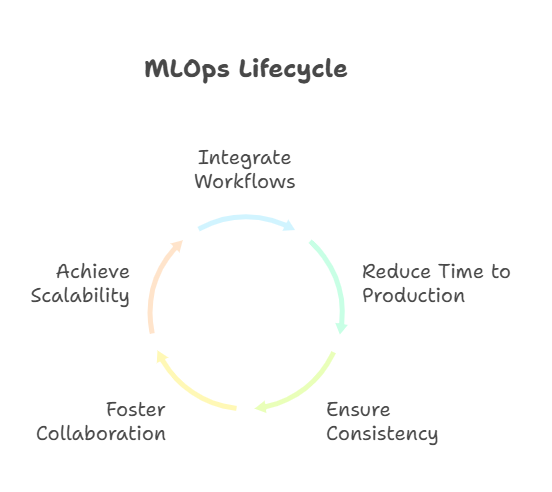
Key Stages of the MLOps Lifecycle
The MLOps lifecycle consists of several interconnected stages that guide a machine learning project from initial idea to delivering business value. It begins with data collection and preparation, where raw data is gathered, cleaned, and transformed into a format suitable for modeling. This stage is crucial, as the quality of data directly impacts model performance.
Next comes model development, where data scientists experiment with different algorithms, features, and hyperparameters to build predictive models. This phase often involves iterative experimentation and evaluation to identify the best-performing approach. Once a satisfactory model is developed, it moves to the validation and testing stage, where its performance is assessed on unseen data to ensure generalizability and robustness.
After validation, the model is ready for deployment. This involves integrating the model into production systems so it can make real-time or batch predictions on new data. Deployment is not the end of the journey; continuous monitoring is essential to track model performance, detect data drift, and identify any issues that may arise in a dynamic business environment. If performance degrades, the model may need to be retrained or updated, completing the lifecycle and starting the process anew.
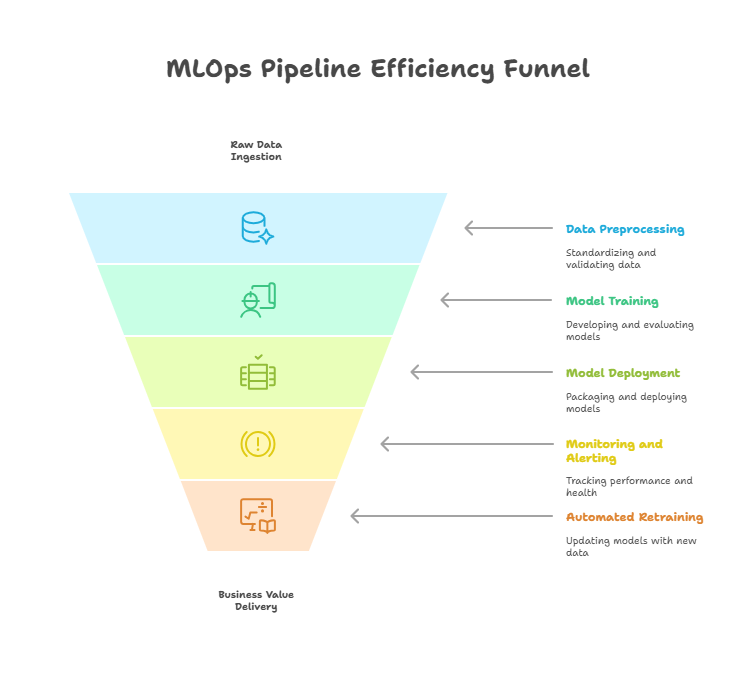
Building Effective MLOps Pipelines
An effective MLOps pipeline automates and orchestrates the various stages of the machine learning lifecycle, ensuring that models can be developed, deployed, and maintained efficiently and reliably. The pipeline typically starts with automated data ingestion and preprocessing, which standardizes and validates incoming data to maintain consistency.
The next component is automated model training and evaluation. By using tools for experiment tracking and version control, teams can systematically compare different models and configurations, making it easier to select the best candidate for deployment. Once a model is chosen, the pipeline handles packaging and deployment, often using containerization technologies to ensure reproducibility across environments.
Monitoring and alerting are integral parts of the pipeline, providing real-time insights into model performance and system health. Automated retraining mechanisms can be triggered when performance drops or when new data becomes available, ensuring that models remain accurate and relevant. By integrating these components, an MLOps pipeline reduces manual effort, minimizes errors, and accelerates the delivery of machine learning solutions that drive business value.
Automating Model Deployment and Monitoring
Automating model deployment is a cornerstone of effective MLOps, enabling organizations to move from manual, error-prone processes to streamlined, repeatable workflows. Automated deployment ensures that machine learning models can be reliably transferred from development environments to production systems, whether on-premises or in the cloud. This process typically involves packaging the model, creating APIs or batch jobs for inference, and integrating with existing business applications.
Automation tools and frameworks, such as CI/CD pipelines tailored for machine learning, play a crucial role in this stage. They allow for consistent testing, validation, and deployment of models, reducing the risk of human error and ensuring that only well-performing models reach production. Automated deployment also supports versioning, making it possible to roll back to previous model versions if issues arise.
Equally important is the automation of model monitoring. Once a model is live, continuous monitoring tracks its performance, data quality, and operational metrics such as latency and throughput. Automated alerts can notify teams of anomalies, data drift, or performance degradation, enabling rapid response and minimizing business impact. By automating both deployment and monitoring, organizations can maintain high model reliability and quickly adapt to changing data or business requirements.
Ensuring Model Reliability and Scalability
Model reliability and scalability are essential for delivering consistent business value from machine learning initiatives. Reliability means that models perform as expected under various conditions, while scalability ensures that solutions can handle increasing data volumes and user demands without degradation.
To achieve reliability, organizations implement robust testing and validation procedures throughout the MLOps lifecycle. This includes not only evaluating model accuracy but also stress-testing models with edge cases and monitoring for unexpected behaviors in production. Automated retraining and rollback mechanisms further enhance reliability by allowing teams to quickly address issues as they arise.
Scalability is addressed through the use of cloud-native technologies, containerization, and orchestration platforms such as Kubernetes. These tools enable models to be deployed across distributed environments, automatically scaling resources up or down based on demand. Load balancing, parallel processing, and efficient resource management ensure that machine learning services remain responsive and cost-effective as usage grows.
By focusing on both reliability and scalability, organizations can confidently deploy machine learning models that support critical business processes, deliver consistent results, and adapt to evolving needs. This foundation is key to realizing the full potential of MLOps and turning data science efforts into sustainable business value.
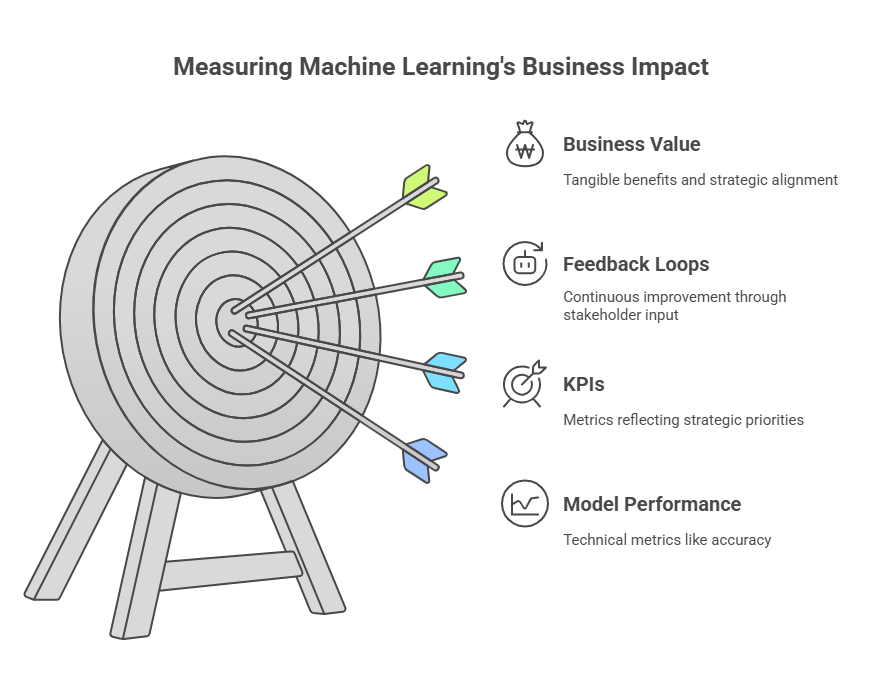
Measuring Business Impact of Machine Learning
One of the most important aspects of any machine learning initiative is the ability to measure its real impact on business outcomes. While technical metrics such as accuracy, precision, or recall are essential for evaluating model performance, they do not always translate directly into business value. To bridge this gap, organizations must define clear business objectives at the outset and align machine learning goals with these objectives.
Measuring business impact involves tracking key performance indicators (KPIs) that reflect the organization’s strategic priorities. For example, in e-commerce, this might mean monitoring conversion rates, customer retention, or average order value. In finance, relevant KPIs could include fraud detection rates or cost savings from process automation. By linking model outputs to these business metrics, organizations can assess whether their machine learning solutions are delivering tangible benefits.
It is also important to establish feedback loops between business stakeholders and data science teams. Regular reviews of business outcomes, combined with model monitoring data, help identify areas for improvement and ensure that machine learning efforts remain focused on delivering value. Ultimately, a disciplined approach to measuring business impact enables organizations to justify investments in machine learning and prioritize projects that drive the greatest returns.
Overcoming Common MLOps Challenges
Despite the promise of MLOps, organizations often encounter a range of challenges when operationalizing machine learning. One common issue is the lack of collaboration between data science, engineering, and business teams, which can lead to misaligned priorities and communication gaps. Establishing cross-functional teams and clear processes helps ensure that everyone is working toward shared goals.
Another challenge is managing the complexity of machine learning pipelines, which often involve multiple tools, frameworks, and environments. Standardizing workflows, adopting version control, and using orchestration platforms can help reduce this complexity and improve reproducibility. Data quality and availability also pose significant hurdles; robust data validation and monitoring processes are essential to prevent issues from propagating into production.
Security and compliance are increasingly important, especially as regulations around data privacy and AI ethics evolve. Organizations must implement strong access controls, audit trails, and documentation to meet regulatory requirements and build trust in their machine learning systems.
Finally, scaling MLOps practices across the organization requires ongoing investment in skills, infrastructure, and culture. Training teams, automating repetitive tasks, and fostering a culture of continuous improvement are key to overcoming these challenges and unlocking the full potential of MLOps.
Case Studies: Turning Data Science into Business Value
Let’s explore two real-world examples of organizations successfully implementing MLOps to drive business value, along with the code implementations that made it possible.
Case Study 1: E-commerce Recommendation System
A major online retailer improved their product recommendations by implementing an automated MLOps pipeline. Here’s a simplified version of their recommendation model:
python
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
import mlflow
class RecommendationSystem:
def __init__(self):
mlflow.set_tracking_uri("http://mlflow-server:5000")
mlflow.set_experiment("recommendation_system")
def prepare_data(self, data_path):
df = pd.read_csv(data_path)
features = ['user_behavior', 'product_category', 'previous_purchases']
X = df[features]
y = df['purchase_probability']
return train_test_split(X, y, test_size=0.2)
def train_model(self, X_train, y_train):
with mlflow.start_run():
model = LightGBM()
model.fit(X_train, y_train)
# Log parameters and metrics
mlflow.log_params({
"learning_rate": 0.1,
"num_leaves": 31
})
mlflow.log_metric("training_score", model.score(X_train, y_train))
# Register model
mlflow.sklearn.log_model(model, "recommendation_model")
return model
def monitor_performance(self, model, X_test, y_test):
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
# Alert if error exceeds threshold
if mse > 0.1:
self.send_alert(f"Model performance degraded: MSE = {mse}")Case Study 2: Financial Fraud Detection
A financial institution implemented real-time fraud detection using an automated MLOps pipeline:
python
from datetime import datetime
import numpy as np
from sklearn.ensemble import RandomForestClassifier
import prometheus_client as prom
class FraudDetectionSystem:
def __init__(self):
self.model = None
# Prometheus metrics for monitoring
self.prediction_counter = prom.Counter(
'fraud_predictions_total',
'Total number of fraud predictions made'
)
self.detection_rate = prom.Gauge(
'fraud_detection_rate',
'Current fraud detection rate'
)
def preprocess_transaction(self, transaction):
features = [
transaction['amount'],
transaction['location_score'],
transaction['device_risk_score'],
transaction['time_since_last_transaction']
]
return np.array(features).reshape(1, -1)
def predict_fraud(self, transaction):
features = self.preprocess_transaction(transaction)
prediction = self.model.predict_proba(features)[0][1]
# Update monitoring metrics
self.prediction_counter.inc()
self.detection_rate.set(prediction)
return prediction > 0.8 # Threshold for fraud alert
def log_prediction(self, transaction_id, prediction, actual=None):
log_entry = {
'timestamp': datetime.now(),
'transaction_id': transaction_id,
'prediction': prediction,
'actual': actual
}
# Log to monitoring system
self.log_to_elasticsearch(log_entry)Best Practices and Recommendations
Based on successful implementations, here are key best practices for MLOps, illustrated with code examples:
python
class MLOpsbestPractices:
def __init__(self):
self.version_control = GitVersionControl()
self.experiment_tracker = MLflowTracker()
self.model_registry = ModelRegistry()
def implement_ci_cd(self):
"""Continuous Integration and Deployment pipeline"""
pipeline = Pipeline([
('data_validation', DataValidator()),
('model_training', ModelTrainer()),
('model_evaluation', ModelEvaluator()),
('deployment', ModelDeployer())
])
return pipeline
def monitor_data_drift(self, production_data, reference_data):
"""Monitor for data drift in production"""
drift_detector = DriftDetector()
drift_metrics = drift_detector.calculate_drift(
production_data,
reference_data
)
if drift_metrics['drift_score'] > 0.1:
self.trigger_retraining()
def implement_feature_store(self):
"""Feature store implementation"""
feature_store = FeatureStore(
storage_config={
'online': 'redis',
'offline': 'postgresql'
}
)
return feature_store
def setup_monitoring(self):
"""Setup comprehensive monitoring"""
monitors = {
'model_performance': PerformanceMonitor(),
'data_quality': DataQualityMonitor(),
'system_metrics': SystemMetricsMonitor()
}
return monitorsKey recommendations include:
Implement comprehensive version control for code, data, and models
Use automated testing and validation throughout the pipeline
Maintain detailed documentation and model cards
Set up robust monitoring and alerting systems
Establish clear processes for model updates and rollbacks
Ensure reproducibility of experiments and deployments
Regular auditing of model performance and business impact
Continuous training and knowledge sharing among teams
Future Directions in MLOps
The field of MLOps is evolving rapidly, and its future is shaped by both technological innovation and growing business expectations. In the coming years, we can expect several key trends to redefine how organizations approach machine learning operations.
One of the most significant directions is the increasing automation of the entire machine learning lifecycle. Tools for automated data validation, feature engineering, model selection, and deployment are becoming more sophisticated, allowing teams to focus on solving business problems rather than managing infrastructure. AutoML and hyper-automation will make it easier for non-experts to participate in building and deploying models, democratizing access to AI.
Another important trend is the integration of MLOps with other areas of IT and business, such as DevOps, DataOps, and business intelligence. This convergence will enable organizations to create unified pipelines that connect data ingestion, model training, deployment, and monitoring with business decision-making processes. As a result, machine learning will become more deeply embedded in everyday business operations.
The future of MLOps will also be shaped by advances in model monitoring and governance. With increasing regulatory scrutiny and the need for responsible AI, organizations will invest in tools that provide explainability, fairness checks, and automated compliance reporting. Real-time monitoring and adaptive retraining will become standard, ensuring that models remain accurate and trustworthy as data and business conditions change.
Finally, the adoption of cloud-native technologies, serverless architectures, and edge computing will make it easier to scale machine learning solutions and deploy them closer to where data is generated. This will open new opportunities for real-time analytics and AI-driven automation in industries ranging from manufacturing to healthcare.
In summary, the future of MLOps lies in greater automation, integration, governance, and scalability—enabling organizations to unlock even more business value from their data science initiatives.
Conclusion: Realizing the Full Potential of MLOps
MLOps has become a critical enabler for organizations seeking to turn data science into real business value. By bridging the gap between experimentation and production, MLOps ensures that machine learning models are not only accurate but also reliable, scalable, and aligned with business goals.
To realize the full potential of MLOps, organizations must invest in modern tools and processes that support automation, monitoring, and collaboration across teams. It is essential to establish clear metrics for success, integrate machine learning workflows with business operations, and foster a culture of continuous improvement.
The journey does not end with deploying a model; ongoing monitoring, retraining, and governance are necessary to maintain performance and trust. As the field evolves, embracing new technologies and best practices will be key to staying ahead of the competition and meeting the growing demands of the market.
Ultimately, MLOps transforms machine learning from isolated experiments into a strategic asset—driving innovation, efficiency, and measurable business outcomes. Organizations that prioritize MLOps will be best positioned to harness the power of AI and achieve lasting success in the data-driven economy.
MLOps in the Cloud: Tools and Strategies