

Introduction: The Rise of MLOps
In recent years, the field of machine learning has experienced rapid growth, with organizations across industries leveraging AI to gain a competitive edge. However, as machine learning models move from research and experimentation to real-world applications, new challenges have emerged. Deploying, monitoring, and maintaining models in production environments requires more than just data science expertise—it demands robust engineering practices and seamless collaboration between teams.
This is where MLOps comes into play. MLOps, short for Machine Learning Operations, is an evolving discipline that combines machine learning, software engineering, and DevOps principles to streamline the entire machine learning lifecycle. By adopting MLOps, organizations can accelerate model deployment, ensure reproducibility, and maintain high-quality AI systems at scale. For developers, understanding MLOps is becoming essential, as it bridges the gap between building models and delivering real business value.
What is MLOps? A Developer-Friendly Definition
MLOps is a set of practices and tools designed to automate and manage the end-to-end machine learning workflow. It covers everything from data preparation and model training to deployment, monitoring, and ongoing maintenance. The goal of MLOps is to make machine learning projects more reliable, scalable, and collaborative—much like how DevOps transformed traditional software development.
For developers, MLOps means treating machine learning models as first-class software components. This involves using version control for code and data, automating testing and deployment pipelines, and continuously monitoring models in production. MLOps also emphasizes collaboration between data scientists, engineers, and operations teams, ensuring that models are not only accurate but also robust, secure, and easy to maintain.
In summary, MLOps empowers developers to move beyond isolated experiments and build machine learning solutions that deliver consistent, long-term value in real-world environments.
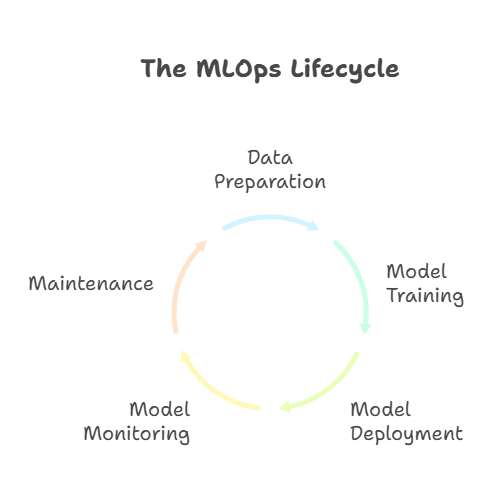
Why MLOps Matters to Developers
MLOps is not just a buzzword; it’s a critical set of practices that directly impacts developers involved in machine learning projects. Here’s why MLOps matters to developers:
Faster Deployment Cycles: MLOps automates the deployment process, allowing developers to quickly move models from development to production. This reduces the time it takes to get AI-powered features into the hands of users.
Improved Model Reliability: MLOps ensures that models are thoroughly tested and validated before deployment, reducing the risk of errors and unexpected behavior in production.
Enhanced Collaboration: MLOps promotes collaboration between data scientists, engineers, and operations teams, breaking down silos and fostering a shared understanding of the machine learning lifecycle.
Scalability: MLOps provides the tools and processes needed to scale machine learning projects, allowing developers to handle increasing data volumes and user traffic without sacrificing performance.
Maintainability: MLOps makes it easier to monitor and maintain models in production, ensuring that they continue to perform well over time and adapt to changing data patterns.
Reproducibility: MLOps emphasizes version control and automated pipelines, making it easier to reproduce experiments and track changes to models and data.
Key Components of MLOps
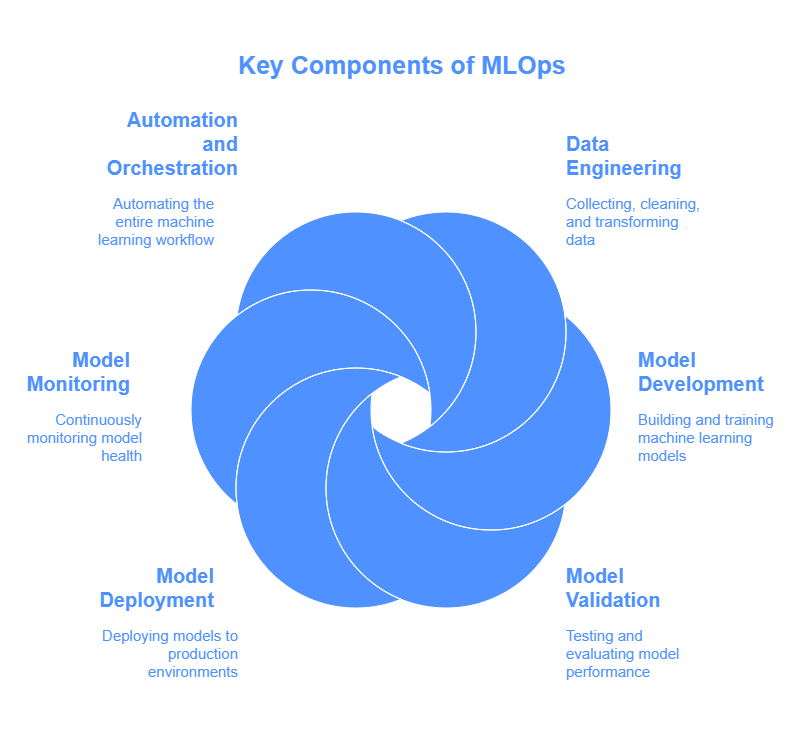
MLOps encompasses several key components that work together to streamline the machine learning lifecycle. These components include:
Data Engineering: This involves collecting, cleaning, and transforming data for use in machine learning models. Developers need to ensure that data pipelines are reliable, scalable, and secure.
Model Development: This is where data scientists and developers collaborate to build and train machine learning models. MLOps emphasizes version control, experiment tracking, and reproducible builds.
Model Validation: This involves testing and evaluating models to ensure that they meet performance and quality standards. MLOps automates the validation process and provides tools for monitoring model behavior.
Model Deployment: This is the process of deploying trained models to production environments. MLOps automates deployment pipelines and provides tools for managing model versions and rollbacks.
Model Monitoring: This involves continuously monitoring models in production to detect performance degradation, data drift, and other issues. MLOps provides alerts and dashboards for tracking model health.
Automation and Orchestration: This involves automating the entire machine learning workflow, from data preparation to model deployment and monitoring. MLOps uses tools like CI/CD pipelines and workflow orchestration engines to streamline the process.
By understanding these key components, developers can effectively contribute to MLOps initiatives and help their organizations build and deploy high-quality machine learning solutions.
Implementing MLOps: A Step-by-Step Guide
Below is a pragmatic, developer-friendly roadmap for turning a notebook experiment into a monitored production service. Each step can (and should) be automated in a CI/CD pipeline.
5.1 Version everything
• Code → Git
• Data & artifacts → DVC, lakeFS, or MLflow Artifacts
• Environments → requirements.txt / Dockerfile
5.2 Automate training & experiment tracking
Use a single, reproducible script that logs parameters, metrics and the serialized model.
python
# train_and_register.py
import mlflow, mlflow.sklearn
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
EXPERIMENT = "california_rf"
def train():
mlflow.set_experiment(EXPERIMENT)
with mlflow.start_run() as run:
X, y = fetch_california_housing(return_X_y=True, as_frame=True)
X_tr, X_te, y_tr, y_te = train_test_split(X, y, test_size=0.2, random_state=42)
params = {"n_estimators": 150, "max_depth": 10}
model = RandomForestRegressor(**params).fit(X_tr, y_tr)
rmse = mean_squared_error(y_te, model.predict(X_te), squared=False)
mlflow.log_params(params)
mlflow.log_metric("rmse", rmse)
mlflow.sklearn.log_model(model, "model",
registered_model_name="california_rf")
# simple promotion rule
if rmse < 0.55:
mlflow.register_model(f"runs:/{run.info.run_id}/model",
"california_rf_prod")
if __name__ == "__main__":
train()
Continuous-integration job ➜ python train_and_register.pySuccess criteria (e.g., rmse < 0.55) decide whether the model is promoted.
5.3 Package & deploy
Containerise the promoted model once the CI stage passes.
dockerfile
# Dockerfile
FROM python:3.11-slim
RUN pip install mlflow fastapi uvicorn[standard] scikit-learn pandas
COPY serve.py /app/serve.py
CMD ["python", "/app/serve.py"]serve.py exposes a lightweight REST API:
python
from fastapi import FastAPI
import mlflow.pyfunc, numpy as np
app = FastAPI()
model = mlflow.pyfunc.load_model("models:/california_rf_prod/Production")
@app.post("/predict")
async def predict(payload: list[list[float]]):
preds = model.predict(np.array(payload))
return {"predictions": preds.tolist()}A CD pipeline (GitHub Actions, Argo CD, etc.) builds the image, pushes it to a registry and rolls it out to Kubernetes or another target.
5.4 Monitor & iterate
• Service health → Prometheus + Grafana
• Data & concept drift → Evidently, WhyLabs
• A/B or shadow testing → Istio, KServe
Feedback loops automatically trigger retraining when performance degrades, closing the MLOps cycle.
Tools and Technologies for MLOps
The MLOps ecosystem offers a rich variety of tools and technologies designed to address different aspects of the machine learning lifecycle. Understanding these tools and how they fit together is crucial for developers looking to implement effective MLOps practices.
Experiment Tracking and Model Management: Tools like MLflow, Weights & Biases, and Neptune help track experiments, log metrics, and manage model versions. These platforms provide centralized repositories for storing models, metadata, and artifacts.
Data Pipeline and Orchestration: Apache Airflow, Kubeflow Pipelines, and Prefect enable developers to create complex, automated workflows that handle data processing, model training, and deployment tasks.
Containerization and Deployment: Docker and Kubernetes provide the foundation for packaging and deploying models in scalable, reproducible environments. Tools like KServe and Seldon Core offer specialized model serving capabilities.
Monitoring and Observability: Prometheus, Grafana, and specialized ML monitoring tools like Evidently AI help track model performance, detect data drift, and ensure system health in production.
Here’s a practical example of setting up a complete MLOps pipeline using popular tools:
python
# mlops_pipeline.py
import mlflow
import mlflow.sklearn
from prefect import flow, task
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import joblib
import os
@task
def load_and_prepare_data():
"""Load and prepare the dataset."""
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
data.data, data.target, test_size=0.2, random_state=42
)
return X_train, X_test, y_train, y_test
@task
def train_model(X_train, y_train, n_estimators=100):
"""Train the machine learning model."""
model = RandomForestClassifier(n_estimators=n_estimators, random_state=42)
model.fit(X_train, y_train)
return model
@task
def evaluate_model(model, X_test, y_test):
"""Evaluate model performance."""
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
return accuracy
@task
def log_experiment(model, accuracy, n_estimators):
"""Log experiment to MLflow."""
with mlflow.start_run():
mlflow.log_param("n_estimators", n_estimators)
mlflow.log_metric("accuracy", accuracy)
mlflow.sklearn.log_model(model, "model")
# Register model if accuracy is above threshold
if accuracy > 0.95:
mlflow.register_model(
f"runs:/{mlflow.active_run().info.run_id}/model",
"iris_classifier"
)
return mlflow.active_run().info.run_id
@flow
def mlops_training_pipeline(n_estimators=100):
"""Complete MLOps training pipeline."""
# Data preparation
X_train, X_test, y_train, y_test = load_and_prepare_data()
# Model training
model = train_model(X_train, y_train, n_estimators)
# Model evaluation
accuracy = evaluate_model(model, X_test, y_test)
# Experiment logging
run_id = log_experiment(model, accuracy, n_estimators)
print(f"Pipeline completed. Accuracy: {accuracy:.4f}, Run ID: {run_id}")
return run_id
# Model serving with FastAPI
from fastapi import FastAPI
import numpy as np
from pydantic import BaseModel
app = FastAPI()
class PredictionRequest(BaseModel):
features: list[float]
class PredictionResponse(BaseModel):
prediction: int
probability: list[float]
# Load the latest model from MLflow
model = mlflow.sklearn.load_model("models:/iris_classifier/latest")
@app.post("/predict", response_model=PredictionResponse)
async def predict(request: PredictionRequest):
"""Make predictions using the deployed model."""
features = np.array(request.features).reshape(1, -1)
prediction = model.predict(features)[0]
probabilities = model.predict_proba(features)[0].tolist()
return PredictionResponse(
prediction=int(prediction),
probability=probabilities
)
@app.get("/health")
async def health_check():
"""Health check endpoint."""
return {"status": "healthy", "model": "iris_classifier"}
if __name__ == "__main__":
# Run the training pipeline
mlops_training_pipeline()Overcoming Common MLOps Challenges
Despite the benefits of MLOps, developers often encounter several challenges when implementing these practices. Understanding these challenges and their solutions is essential for successful MLOps adoption.
Challenge 1: Data Quality and Versioning
Poor data quality and lack of data versioning can lead to unreproducible experiments and unreliable models. Solution: Implement robust data validation pipelines and use tools like DVC or Delta Lake for data versioning.
Challenge 2: Model Drift and Performance Degradation
Models can lose accuracy over time due to changes in data patterns or business requirements. Solution: Implement continuous monitoring and automated retraining pipelines.
Challenge 3: Scalability and Resource Management
As the number of models and data volume grows, resource management becomes complex. Solution: Use containerization and orchestration tools like Kubernetes to manage resources efficiently.
Challenge 4: Collaboration Between Teams
Data scientists and engineers often work in silos, leading to communication gaps and deployment issues. Solution: Establish clear workflows, shared tools, and regular cross-team meetings.
Here’s a practical example of implementing monitoring and alerting for model drift:
python
# model_monitoring.py
import pandas as pd
import numpy as np
from scipy import stats
from datetime import datetime, timedelta
import logging
class ModelMonitor:
def __init__(self, reference_data, threshold=0.05):
self.reference_data = reference_data
self.threshold = threshold
self.logger = logging.getLogger(__name__)
def detect_data_drift(self, new_data):
"""Detect data drift using Kolmogorov-Smirnov test."""
drift_detected = {}
for column in self.reference_data.columns:
if column in new_data.columns:
# Perform KS test
ks_statistic, p_value = stats.ks_2samp(
self.reference_data[column],
new_data[column]
)
drift_detected[column] = {
'ks_statistic': ks_statistic,
'p_value': p_value,
'drift_detected': p_value < self.threshold
}
if p_value < self.threshold:
self.logger.warning(
f"Data drift detected in column {column}: "
f"p-value = {p_value:.4f}"
)
return drift_detected
def monitor_prediction_quality(self, predictions, actuals):
"""Monitor prediction quality over time."""
accuracy = np.mean(predictions == actuals)
# Log metrics
self.logger.info(f"Current accuracy: {accuracy:.4f}")
# Alert if accuracy drops below threshold
if accuracy < 0.8: # Example threshold
self.logger.error(
f"Model accuracy dropped to {accuracy:.4f}. "
"Consider retraining the model."
)
return accuracy
def generate_monitoring_report(self, new_data, predictions, actuals):
"""Generate comprehensive monitoring report."""
drift_results = self.detect_data_drift(new_data)
accuracy = self.monitor_prediction_quality(predictions, actuals)
report = {
'timestamp': datetime.now().isoformat(),
'data_drift': drift_results,
'model_accuracy': accuracy,
'recommendations': []
}
# Add recommendations based on findings
if any(result['drift_detected'] for result in drift_results.values()):
report['recommendations'].append("Data drift detected. Consider retraining the model.")
if accuracy < 0.8:
report['recommendations'].append("Model accuracy below threshold. Immediate retraining recommended.")
return report
# Example usage
if __name__ == "__main__":
# Simulate reference and new data
np.random.seed(42)
reference_data = pd.DataFrame({
'feature1': np.random.normal(0, 1, 1000),
'feature2': np.random.normal(5, 2, 1000)
})
# Simulate drifted data
new_data = pd.DataFrame({
'feature1': np.random.normal(0.5, 1.2, 500), # Slight drift
'feature2': np.random.normal(5, 2, 500)
})
# Initialize monitor
monitor = ModelMonitor(reference_data)
# Simulate predictions and actuals
predictions = np.random.choice([0, 1], 500)
actuals = np.random.choice([0, 1], 500)
# Generate monitoring report
report = monitor.generate_monitoring_report(new_data, predictions, actuals)
print("Monitoring Report:", report)By addressing these challenges proactively and implementing robust monitoring solutions, developers can build more reliable and maintainable MLOps systems that deliver consistent value in production environments.
MLOps Best Practices for Developers
To maximize the benefits of MLOps and ensure the success of machine learning projects, developers should adhere to the following best practices:
Treat Models as Code: Apply software engineering principles to machine learning models, including version control, testing, and code review.
Automate Everything: Automate all aspects of the machine learning lifecycle, from data preparation to model deployment and monitoring.
Monitor Continuously: Implement robust monitoring systems to track model performance, detect data drift, and ensure system health in production.
Collaborate Across Teams: Foster collaboration between data scientists, engineers, and operations teams to break down silos and promote shared understanding.
Embrace Infrastructure as Code: Use tools like Terraform or CloudFormation to manage infrastructure in a reproducible and scalable manner.
Implement Security Best Practices: Secure all components of the MLOps pipeline, including data storage, model repositories, and deployment environments.
Document Everything: Document all aspects of the machine learning lifecycle, including data sources, model training procedures, and deployment configurations.
The Future of MLOps: What’s Next?
The field of MLOps is rapidly evolving, with new tools, techniques, and best practices emerging all the time. Looking ahead, we can expect to see several key trends shaping the future of MLOps:
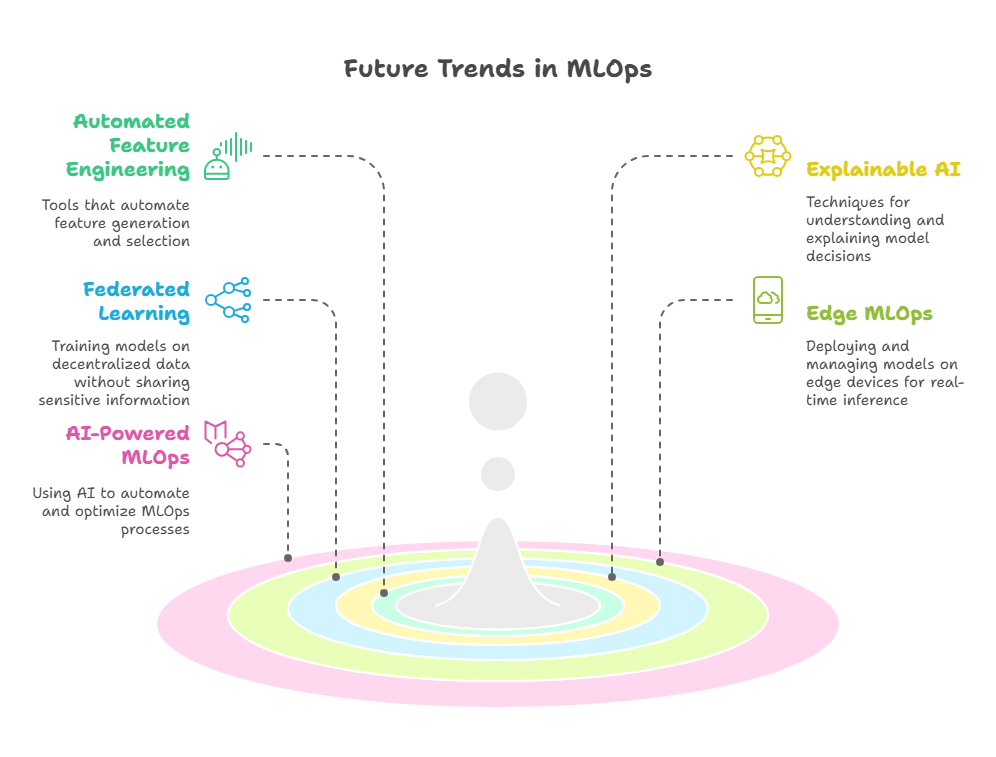
Automated Feature Engineering: Tools that automatically generate and select relevant features from raw data will become more prevalent, reducing the manual effort required for feature engineering.
Explainable AI (XAI): Techniques for understanding and explaining how machine learning models make decisions will become more important, especially in regulated industries.
Federated Learning: Approaches for training models on decentralized data sources without sharing sensitive information will gain traction, enabling new applications in healthcare and finance.
Edge MLOps: Deploying and managing machine learning models on edge devices will become more common, enabling real-time inference and reduced latency in IoT and autonomous systems.
AI-Powered MLOps: AI will be used to automate and optimize various aspects of the MLOps pipeline, including model selection, hyperparameter tuning, and anomaly detection.
By staying informed about these trends and adopting new technologies as they emerge, developers can position themselves at the forefront of the MLOps revolution and help their organizations build more innovative and impactful AI solutions.
Conclusion: Embracing MLOps for Scalable AI
As machine learning continues to transform industries and drive innovation, the need for robust and scalable MLOps practices has never been greater. For developers, understanding and embracing MLOps is essential for building reliable, maintainable, and high-performing AI systems that deliver real business value.
By adopting the principles and practices outlined in this article, developers can bridge the gap between code and AI, streamline the machine learning lifecycle, and foster collaboration between data scientists, engineers, and operations teams. From automating data pipelines to monitoring model performance in production, MLOps empowers developers to build and deploy AI solutions at scale.
As the field of MLOps continues to evolve, it’s crucial for developers to stay informed about new tools, techniques, and best practices. By embracing a mindset of continuous learning and experimentation, developers can position themselves at the forefront of the MLOps revolution and help their organizations unlock the full potential of AI.
In conclusion, MLOps is not just a set of tools or processes; it’s a cultural shift that transforms how organizations approach machine learning. By embracing MLOps, developers can build more scalable, reliable, and impactful AI solutions that drive innovation and create lasting value.
The Future of MLOps: Trends and Innovations in Machine Learning Operations
The best MLOps tools of 2025 – comparison and recommendations
MLOps in Practice – How to Automate the Machine Learning Model Lifecycle