

Introduction: The Next Evolution of MLOps
The world of machine learning is evolving at a breathtaking pace, and so is the discipline of MLOps. What started as a set of best practices for deploying and maintaining machine learning models has now become a strategic pillar for organizations seeking to harness the full power of AI. As the scale, complexity, and business impact of ML systems grow, the future of MLOps promises to fundamentally change the way developers work with AI.
Why Is MLOps Evolving?
Traditional MLOps focused on automating model training, deployment, and monitoring. However, the explosion of data sources, the rise of edge and federated learning, and the growing demand for explainability, security, and compliance are pushing the boundaries of what MLOps must deliver. Developers are no longer just writing code—they are orchestrating complex, distributed systems that must be robust, transparent, and adaptable to constant change.
The New Role of Developers in AI
In the next era of MLOps, developers will need to think beyond code and algorithms. They will be responsible for building self-healing pipelines, integrating real-time monitoring and observability, and ensuring that AI systems are ethical, explainable, and secure. Collaboration with data engineers, DevOps, and business stakeholders will become even more critical, as AI solutions move from isolated projects to core business infrastructure.
Key Drivers of Change
Automation and Intelligence: AI-driven automation will handle more of the routine tasks in model testing, deployment, and monitoring, freeing developers to focus on innovation and problem-solving.
Unified Platforms: The convergence of DataOps, MLOps, and DevOps will break down silos, enabling seamless workflows from data ingestion to model serving and feedback.
Edge and Federated AI: As AI moves closer to the data source, developers will need to manage distributed, privacy-preserving ML systems that operate reliably outside the cloud.
Responsible and Explainable AI: Regulatory and ethical demands will make explainability, fairness, and compliance non-negotiable features of every ML pipeline.
Automated and Self-Healing ML Pipelines
The future of MLOps is defined by automation and self-healing capabilities that fundamentally change how developers build, deploy, and maintain machine learning systems. As organizations scale their AI initiatives, manual intervention becomes a bottleneck—making automated, resilient pipelines a necessity rather than a luxury.
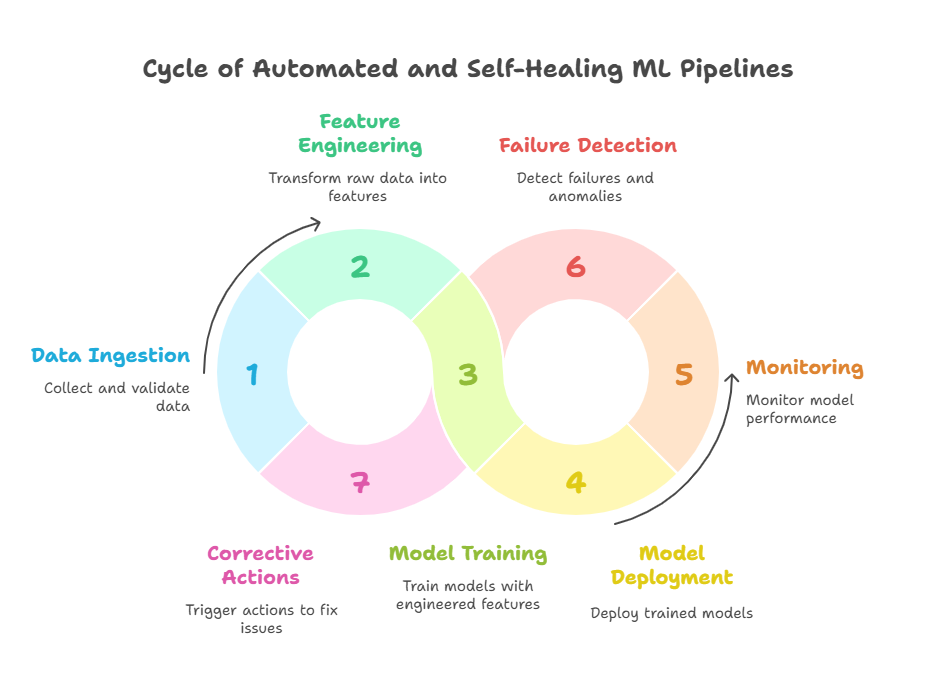
What Are Automated and Self-Healing ML Pipelines?
Automated ML pipelines orchestrate the entire machine learning lifecycle—from data ingestion and validation, through feature engineering and model training, to deployment and monitoring—without requiring constant human oversight. These pipelines leverage workflow orchestration tools (like Kubeflow, Airflow, or cloud-native solutions) to schedule, execute, and monitor every step, ensuring consistency and repeatability.
Self-healing pipelines take automation a step further. They are designed to detect failures, anomalies, or performance drops in real time and automatically trigger corrective actions. This might include rolling back to a previous model version, retraining a model on fresh data, restarting failed jobs, or alerting the right team members for intervention.
Why Do They Matter for Developers?
Reduced Operational Burden: Developers spend less time firefighting and more time innovating, as pipelines handle routine failures and maintenance tasks automatically.
Faster Iteration: Automated retraining and deployment mean that new models and improvements reach production faster, accelerating the feedback loop.
Higher Reliability: Self-healing mechanisms minimize downtime and ensure that models continue to deliver value, even in the face of data drift, infrastructure failures, or unexpected edge cases.
Scalability: As the number of models and pipelines grows, automation is the only way to manage complexity without ballooning operational costs.
Key Features of Next-Gen Pipelines
Automated triggers for retraining, rollback, or scaling based on real-time monitoring and performance metrics.
Integrated validation and testing at every stage, ensuring only high-quality data and models move forward.
Event-driven architecture that responds dynamically to data changes, failures, or business events.
Seamless integration with model registries, monitoring tools, and CI/CD systems for end-to-end traceability.
Real-Time Monitoring and Observability in MLOps
Real-time monitoring and observability are rapidly becoming non-negotiable features of modern MLOps workflows. As machine learning models move from research to production, the need for instant visibility into their health, performance, and business impact is more critical than ever. For developers, this shift means adopting new tools and practices that enable proactive detection, diagnosis, and resolution of issues—before they affect users or business outcomes.
Why Real-Time Monitoring Matters
In production, ML models are exposed to constantly changing data, user behaviors, and system environments. Data drift, model staleness, infrastructure failures, or integration bugs can silently degrade performance. Without real-time monitoring, these issues may go undetected for days or weeks, leading to lost revenue, compliance violations, or eroded trust in AI systems.
What to Monitor in Real Time
Model Performance Metrics: Track accuracy, precision, recall, F1-score, and business KPIs on live data streams.
Prediction Latency and Throughput: Monitor response times and request volumes to ensure models meet SLAs and scale with demand.
Data Quality and Drift: Continuously check for missing values, outliers, schema changes, and shifts in feature distributions.
System Health: Observe resource utilization (CPU, GPU, memory), error rates, and infrastructure bottlenecks.
Observability: Beyond Basic Monitoring
Observability goes further by combining metrics, logs, and traces to provide a holistic view of the entire ML pipeline. This enables teams to:
Correlate model performance drops with data or infrastructure events
Trace the flow of a single prediction through all pipeline components
Quickly identify root causes and implement targeted fixes
Best Practices for Developers
Automate metric collection and alerting using tools like Prometheus, Grafana, or cloud-native monitoring platforms.
Set up real-time dashboards for key metrics and trends.
Integrate monitoring with CI/CD and model registry for end-to-end traceability.
Test monitoring pipelines regularly to ensure alerts are actionable and reliable.
Unified MLOps Platforms: Breaking Down Silos
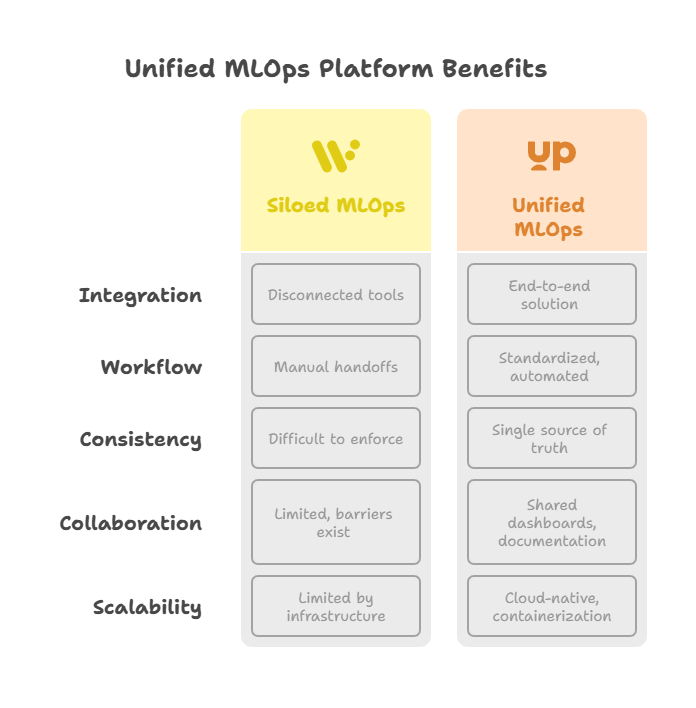
The future of MLOps is being shaped by the rise of unified platforms that break down traditional silos between data engineering, machine learning, and operations teams. In the past, organizations often relied on a patchwork of disconnected tools and manual handoffs, leading to inefficiencies, miscommunication, and slow delivery of AI solutions. Unified MLOps platforms are changing this landscape by providing end-to-end solutions that streamline every stage of the machine learning lifecycle.
A unified MLOps platform integrates data ingestion, feature engineering, model training, experiment tracking, deployment, monitoring, and governance into a single, cohesive environment. This integration eliminates the need for custom glue code, reduces the risk of errors, and accelerates the path from raw data to business value. Developers benefit from standardized workflows, reusable components, and automated best practices that make it easier to build, test, and deploy models at scale.
One of the key advantages of unified platforms is the ability to enforce consistency and compliance across teams and projects. With a single source of truth for data, models, and metadata, organizations can ensure that every model is versioned, every experiment is tracked, and every deployment is auditable. This is especially important in regulated industries, where traceability and governance are non-negotiable.
Unified MLOps platforms also foster collaboration by providing shared dashboards, documentation, and communication channels. Data scientists, ML engineers, DevOps, and business stakeholders can work together seamlessly, reviewing experiments, monitoring model performance, and responding to incidents in real time. This collaborative environment breaks down barriers and empowers teams to innovate faster.
From a technical perspective, unified platforms often leverage cloud-native technologies, containerization, and orchestration tools like Kubernetes to provide scalability and flexibility. They support hybrid and multi-cloud deployments, enabling organizations to run workloads wherever it makes the most sense—on-premises, in the cloud, or at the edge.
Looking ahead, the trend toward unified MLOps platforms will only accelerate. As AI becomes more deeply embedded in business processes, the need for integrated, automated, and collaborative solutions will grow. Developers who embrace these platforms will be better equipped to deliver reliable, scalable, and compliant AI systems—while spending less time on manual integration and more time on innovation.
Edge and Federated MLOps: AI at the Source
The future of MLOps is not just in the cloud—it’s at the edge and across distributed data sources. As organizations seek to deliver real-time, privacy-preserving, and scalable AI solutions, edge and federated MLOps are emerging as game-changers for developers and enterprises alike.
Edge MLOps: Bringing AI Closer to the Data
Edge MLOps refers to the deployment, monitoring, and management of machine learning models directly on edge devices—such as IoT sensors, smartphones, industrial equipment, or autonomous vehicles. By running models at the source of data generation, organizations can achieve ultra-low latency, reduce bandwidth costs, and enable AI-powered decision-making even in environments with limited or intermittent connectivity.
For developers, edge MLOps introduces new challenges and opportunities:
Model optimization: Models must be compressed, quantized, or pruned to fit the resource constraints of edge hardware.
Automated deployment: CI/CD pipelines need to support cross-compilation, remote updates, and rollback for fleets of devices.
Monitoring at scale: Observability tools must aggregate metrics and logs from thousands of distributed endpoints, often with limited connectivity.
Federated MLOps: Privacy-Preserving Collaboration
Federated MLOps enables organizations to train and update models across decentralized data sources—such as hospitals, banks, or mobile devices—without moving raw data to a central server. Instead, models are trained locally and only model updates or gradients are shared and aggregated. This approach preserves data privacy, supports regulatory compliance, and unlocks the value of siloed datasets.
Key considerations for developers include:
Orchestration: Managing the coordination of training rounds, aggregation, and model updates across distributed nodes.
Security: Ensuring that model updates are encrypted, authenticated, and protected against adversarial attacks.
Monitoring and validation: Tracking model performance, drift, and fairness across heterogeneous data sources.
The Future: Unified Edge and Federated MLOps Platforms
As edge and federated learning mature, unified MLOps platforms will emerge to support seamless deployment, monitoring, and management across cloud, edge, and federated environments. Developers will need to master new tools and workflows for model optimization, distributed orchestration, and privacy-preserving analytics.
Explainability and Responsible AI as Standard Practice
The future of MLOps is inseparable from the principles of explainability and responsible AI. As machine learning models become more deeply embedded in critical business decisions—from loan approvals to medical diagnoses—the demand for transparency, fairness, and accountability is driving a fundamental shift in how developers build and deploy AI systems.
Why Explainability Matters in MLOps
Explainability is no longer a nice-to-have feature—it’s becoming a regulatory and business requirement. Organizations need to understand not just what their models predict, but why they make specific decisions. This is essential for:
Regulatory compliance: Laws like GDPR’s „right to explanation” and emerging AI regulations require transparency in automated decision-making.
Building trust: Stakeholders, customers, and end users need to understand and trust AI-driven recommendations.
Debugging and improvement: Explainability helps identify bias, errors, or unexpected model behavior that could impact business outcomes.
Responsible AI: Beyond Accuracy
Responsible AI encompasses fairness, accountability, transparency, and ethical considerations throughout the ML lifecycle. This means:
Bias detection and mitigation: Continuously monitoring models for discriminatory outcomes across different demographic groups.
Data governance: Ensuring that training data is representative, high-quality, and ethically sourced.
Model validation: Testing models not just for accuracy, but also for fairness, robustness, and alignment with organizational values.
Integrating Explainability into MLOps Workflows
Modern MLOps platforms are beginning to integrate explainability tools directly into CI/CD pipelines, model registries, and monitoring dashboards. This enables teams to:
Automatically generate explanations for model predictions during deployment
Track explanation drift alongside data and concept drift
Set up alerts for bias or fairness violations
Example: Automated Bias Detection in Python
Here’s a simple Python example demonstrating how to integrate bias detection into an MLOps pipeline:
python
import pandas as pd
from sklearn.metrics import accuracy_score
import numpy as np
def detect_bias(y_true, y_pred, sensitive_feature, threshold=0.1):
"""
Simple bias detection for binary classification
"""
groups = pd.Series(sensitive_feature).unique()
group_accuracies = {}
for group in groups:
mask = sensitive_feature == group
group_acc = accuracy_score(y_true[mask], y_pred[mask])
group_accuracies[group] = group_acc
# Calculate fairness metric (equalized odds)
max_acc = max(group_accuracies.values())
min_acc = min(group_accuracies.values())
bias_score = max_acc - min_acc
if bias_score > threshold:
print(f"⚠️ Bias detected! Accuracy difference: {bias_score:.3f}")
print(f"Group accuracies: {group_accuracies}")
return False
else:
print(f"✅ Fairness check passed. Bias score: {bias_score:.3f}")
return True
# Example usage in MLOps pipeline
y_true = np.array([1, 0, 1, 0, 1, 0, 1, 0])
y_pred = np.array([1, 0, 1, 1, 1, 0, 0, 0])
sensitive_attr = np.array(['A', 'A', 'B', 'B', 'A', 'A', 'B', 'B'])
is_fair = detect_bias(y_true, y_pred, sensitive_attr)
if not is_fair:
print("Model deployment blocked due to bias concerns")The Future: Explainability by Design
In the future, explainability and responsible AI will be built into every stage of the MLOps lifecycle—from data collection and model training to deployment and monitoring. Developers will use automated tools to generate explanations, detect bias, and ensure compliance, making responsible AI a standard practice rather than an afterthought.
AI-Driven Automation in Testing and Deployment
AI-driven automation is rapidly transforming the way developers test and deploy machine learning models. As MLOps matures, the integration of artificial intelligence into automation pipelines is enabling faster, more reliable, and more scalable workflows—freeing developers from repetitive manual tasks and reducing the risk of human error.
How AI-Driven Automation Changes Testing
Traditional testing in ML pipelines often relies on static rules and manual validation. With AI-driven automation, testing becomes dynamic and adaptive. Automated systems can:
Continuously monitor model performance and data drift in real time
Trigger retraining or rollback when anomalies are detected
Generate synthetic test data to simulate rare or edge-case scenarios
Automatically select and run the most relevant tests based on recent code or data changes
This approach not only accelerates the feedback loop for developers but also ensures that models remain robust and reliable as data and business requirements evolve.
Smarter, Safer Deployments
AI-driven automation extends to deployment as well. Intelligent deployment systems can:
Analyze historical deployment outcomes to predict and avoid risky releases
Orchestrate canary or blue-green deployments, gradually rolling out new models and monitoring their impact before full production release
Automatically roll back to previous model versions if performance drops or errors spike
Optimize resource allocation and scaling based on real-time demand and model usage patterns
Example: Automated Retraining Triggered by AI-Driven Monitoring
Here’s a concise Python example that simulates an AI-driven automation workflow for retraining and deployment:
python
def ai_monitoring_and_deployment(current_accuracy, drift_score, acc_threshold=0.85, drift_threshold=0.1):
if current_accuracy < acc_threshold or drift_score > drift_threshold:
print("AI system: Performance issue detected. Triggering retraining and canary deployment...")
# Simulate retraining and canary deployment
print("Retraining new model...")
print("Deploying canary model to 10% of traffic...")
print("Monitoring canary performance...")
# Simulate canary success
print("Canary successful. Rolling out to full production.")
else:
print("AI system: Model healthy. No action needed.")
# Example usage
ai_monitoring_and_deployment(current_accuracy=0.82, drift_score=0.12)The Future of AI-Driven Automation in MLOps
As AI-driven automation becomes standard, developers will spend less time on manual testing and deployment, and more time on innovation and optimization. Automated systems will not only detect and respond to issues faster than humans, but also learn from past incidents to continuously improve the reliability and efficiency of ML operations.
Security, Compliance, and Privacy in Future MLOps
As machine learning becomes deeply embedded in enterprise operations, the future of MLOps will be defined by its ability to deliver not just performance and scalability, but also robust security, regulatory compliance, and data privacy. For developers, this means that building and deploying AI models will require a new level of discipline and automation to protect sensitive data, meet legal obligations, and maintain user trust.
Security in MLOps
Future MLOps platforms will enforce security at every stage of the ML lifecycle. This includes:
Role-Based Access Control (RBAC): Ensuring only authorized users can access, modify, or deploy models and data.
Encryption: Protecting data and model artifacts both at rest and in transit, using industry-standard encryption protocols.
Vulnerability Scanning: Automatically scanning code, dependencies, and containers for known vulnerabilities before deployment.
Secure Model Serving: Isolating model endpoints, using private networking, and monitoring for abnormal access patterns or inference attacks.
Compliance as a Built-In Feature
With regulations like GDPR, HIPAA, and upcoming AI-specific laws, compliance will be a first-class citizen in MLOps workflows. This means:
Automated Audit Trails: Every action—model registration, deployment, access, and prediction—will be logged and easily auditable.
Data Residency and Retention Policies: Automated enforcement of where data is stored and how long it is retained, with regular compliance checks.
Explainability and Fairness Monitoring: Integrated tools to ensure models are transparent, explainable, and free from bias, supporting both ethical AI and regulatory requirements.
Privacy by Design
Privacy will be embedded into every step of the ML pipeline:
Data Anonymization and Masking: Automated tools will anonymize sensitive data before it enters the ML workflow.
Federated and Differential Privacy: Techniques that allow models to learn from decentralized data without exposing raw information, reducing privacy risks.
Consent Management: Systems to track and enforce user consent for data usage in training and inference.
The Developer’s Role
Developers will need to:
Integrate security and compliance checks into CI/CD and monitoring pipelines.
Use tools that automate audit logging, access control, and data governance.
Stay up to date with evolving regulations and best practices for responsible AI.
Cost and Resource Optimization in Next-Gen MLOps
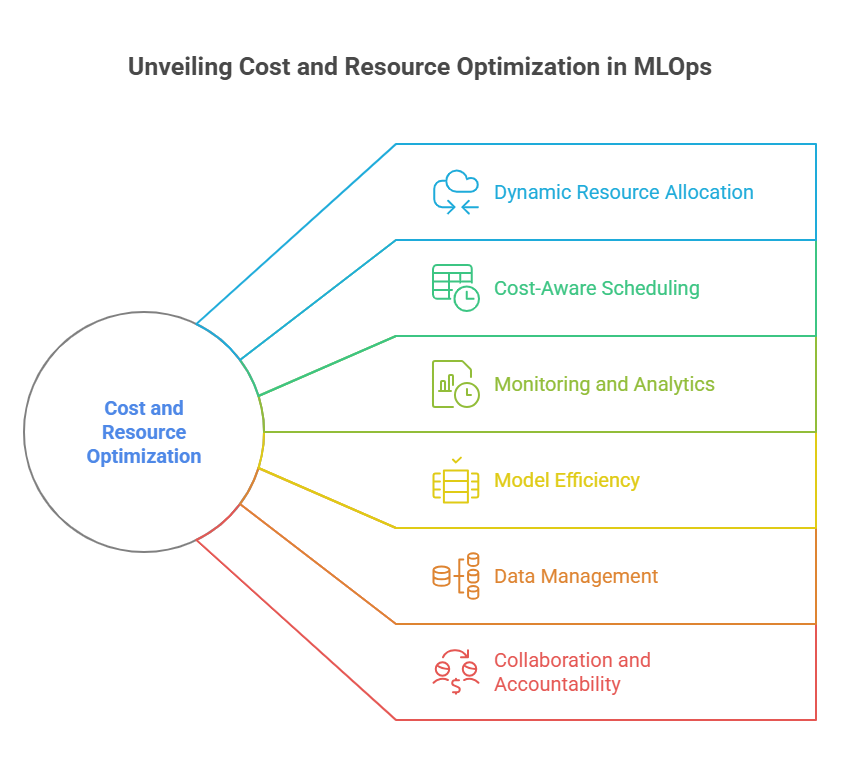
As machine learning workloads grow in scale and complexity, managing costs and optimizing resource usage become critical priorities for organizations. Next-generation MLOps platforms are evolving to provide intelligent, automated solutions that help teams balance performance, scalability, and budget constraints.
Dynamic Resource Allocation
Modern MLOps systems leverage cloud-native features like auto-scaling, spot instances, and serverless computing to dynamically allocate resources based on workload demands. This ensures that training and inference jobs use just the right amount of compute power, reducing waste and lowering costs.
Cost-Aware Scheduling
Advanced schedulers optimize job placement and timing to take advantage of lower-cost resources or off-peak pricing. For example, non-urgent training jobs can be scheduled during cheaper time windows or run on preemptible instances without impacting SLAs.
Monitoring and Analytics
Real-time cost monitoring dashboards provide visibility into resource consumption across teams, projects, and environments. Detailed analytics help identify cost drivers, inefficiencies, and opportunities for optimization.
Model Efficiency
Optimizing model architectures and training processes—such as using model pruning, quantization, or transfer learning—reduces compute requirements and speeds up deployment. MLOps platforms increasingly integrate these techniques into automated pipelines.
Data Management
Efficient data storage and access patterns, including tiered storage and data compression, help control storage costs. Automated data lifecycle policies ensure that obsolete or infrequently accessed data is archived or deleted.
Collaboration and Accountability
Resource tagging and chargeback mechanisms promote accountability among teams, encouraging cost-conscious development and deployment practices.
Case Studies: Enterprise-Scale Model Monitoring in Action
Enterprise-scale model monitoring is critical for ensuring the reliability, performance, and compliance of machine learning systems deployed across complex, distributed environments. Real-world case studies provide valuable insights into how leading organizations implement comprehensive monitoring strategies to maintain high-quality AI services.
Case Study 1: Global Retailer Enhances Customer Experience
A global retail company deployed hundreds of recommendation models across multiple regions. They implemented a centralized monitoring platform using open-source tools like Prometheus and Grafana, integrated with their model registry and CI/CD pipelines. This setup enabled real-time tracking of model accuracy, latency, and data drift. Automated alerts triggered retraining workflows and rollbacks, reducing downtime and improving customer satisfaction.
Case Study 2: Financial Institution Ensures Regulatory Compliance
A major financial institution used cloud-native monitoring services combined with MLflow’s model registry to track credit risk models. They enforced strict access controls and audit logging to meet regulatory requirements. Continuous monitoring of fairness metrics and model performance helped detect bias and performance degradation early, ensuring compliance and reducing operational risk.
Case Study 3: Healthcare Provider Safeguards Patient Outcomes
A healthcare analytics firm deployed predictive models for patient risk assessment. They integrated explainability tools with their monitoring dashboards to provide transparency into model decisions. Real-time monitoring of prediction confidence and error rates, coupled with automated incident response, ensured patient safety and maintained trust with clinicians.
Key Takeaways
Centralized, real-time monitoring is essential for managing large-scale ML deployments.
Integration with model registries and CI/CD pipelines enables automated retraining and rollback.
Security, compliance, and explainability must be embedded in monitoring strategies.
Collaboration across data science, engineering, and compliance teams drives success.
Preparing for the Future: Skills and Mindset for MLOps-Driven AI Development
As MLOps continues to transform the way organizations develop, deploy, and maintain AI systems, preparing for the future requires both new skills and a forward-thinking mindset. Developers and data professionals must adapt to the evolving landscape to stay effective and drive innovation in AI-driven environments.
Essential Skills for Future MLOps Practitioners
Cross-Disciplinary Expertise:
Future MLOps professionals need a blend of skills spanning data engineering, software development, machine learning, and cloud infrastructure. Understanding how these domains intersect enables seamless pipeline development and deployment.
Automation and Orchestration:
Mastery of automation tools (e.g., Apache Airflow, Kubeflow) and infrastructure-as-code (IaC) frameworks (e.g., Terraform, Pulumi) is critical for building scalable, repeatable ML workflows.
Cloud and Hybrid Environment Proficiency:
Familiarity with multiple cloud platforms and hybrid architectures allows teams to design flexible, cost-effective solutions that leverage the best of on-premises and cloud resources.
Monitoring and Observability:
Skills in setting up comprehensive monitoring, logging, and alerting systems ensure models remain reliable and performant in production.
Security and Compliance Awareness:
Understanding data privacy laws, ethical AI principles, and security best practices is essential for building trustworthy AI systems.
Collaboration and Communication:
Effective teamwork across data scientists, engineers, and business stakeholders requires strong communication skills and a collaborative mindset.
Adopting a Growth Mindset
The AI and MLOps landscape is rapidly evolving. Embracing a growth mindset—being open to continuous learning, experimentation, and adaptation—is vital. This includes staying current with emerging tools, frameworks, and methodologies, as well as learning from failures and successes alike.
Fostering a Culture of Innovation
Organizations should encourage experimentation, knowledge sharing, and cross-functional collaboration. Providing training, mentorship, and opportunities for hands-on experience helps build a skilled, motivated MLOps workforce ready to tackle future challenges.