

Introduction: The Importance of Automation in MLOps
In the rapidly evolving landscape of artificial intelligence, deploying machine learning (ML) models to production is no longer a one-off task—it’s a continuous journey. As organizations scale their AI initiatives, the need for robust, reliable, and efficient operations becomes paramount. This is where MLOps automation steps in, transforming the way developers build, deploy, and maintain AI systems.
MLOps (Machine Learning Operations) is the discipline that applies DevOps principles to the machine learning lifecycle. At its core, MLOps aims to automate every stage of this lifecycle, from data preparation and model training to deployment, monitoring, and retraining. The ultimate goal is to build resilient AI systems that can adapt to changing data, business requirements, and infrastructure, all with minimal human intervention.
Why is automation so critical in MLOps?
Accelerated Delivery: Manual processes are slow and prone to errors. Automation speeds up the entire ML workflow, allowing new models and updates to reach production faster.
Enhanced Reliability: Automated pipelines ensure consistency and reproducibility, reducing the risk of human error and ensuring models perform as expected.
Scalability: As the number of models and datasets grows, automation is the only way to manage complexity without ballooning operational costs.
Reduced Operational Burden: Developers and data scientists can focus on innovation and problem-solving, rather than repetitive, time-consuming tasks.
Proactive Issue Detection: Automated monitoring and alerting systems can detect data drift, model degradation, or pipeline failures early, enabling rapid response.
In summary, MLOps automation is not just about efficiency; it’s about building a foundation for trustworthy, scalable, and sustainable AI. By embracing automation, organizations can unlock the full potential of their machine learning investments and drive significant business value.
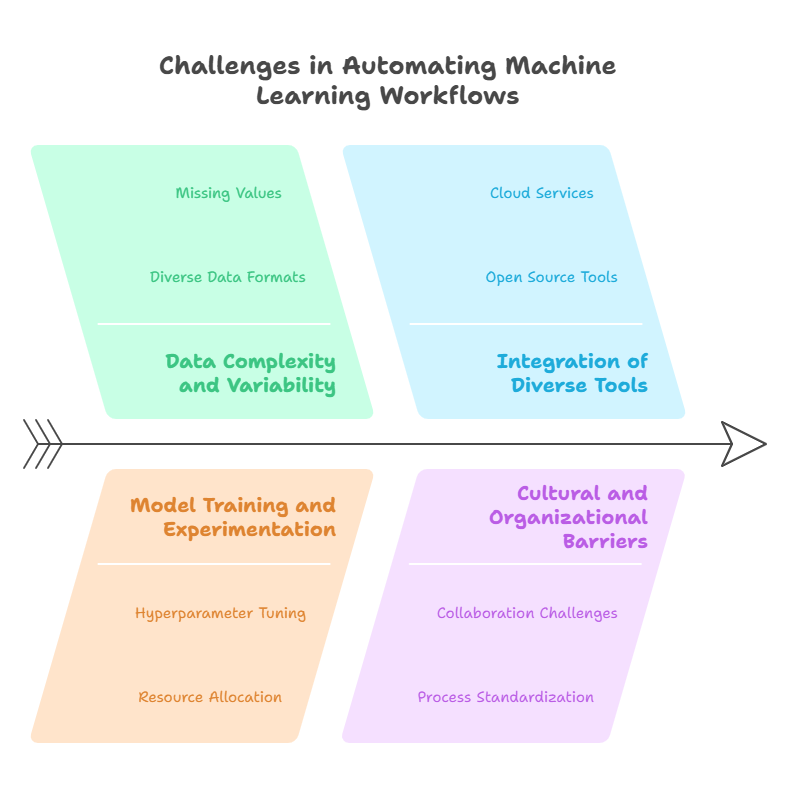
Key Challenges in Automating ML Workflows
Automating machine learning workflows is a complex endeavor that presents unique challenges distinct from traditional software development. Understanding these challenges is essential for developers and organizations aiming to build resilient, scalable, and efficient MLOps pipelines.
Data Complexity and Variability
Machine learning workflows depend heavily on data, which is often messy, heterogeneous, and constantly evolving. Automating data ingestion, validation, and preprocessing requires handling diverse data formats, missing values, and schema changes. Ensuring data quality and consistency across automated pipelines is a significant challenge.
Model Training and Experimentation
Unlike traditional software, ML models require extensive experimentation with hyperparameters, architectures, and training data. Automating this experimentation while tracking results, managing resource allocation, and selecting the best models demands sophisticated orchestration and versioning systems.
Integration of Diverse Tools and Technologies
MLOps pipelines often involve a mix of open source tools, cloud services, and custom components. Integrating these disparate technologies into a seamless, automated workflow requires careful design and robust interfaces. Ensuring compatibility and managing dependencies across environments adds to the complexity.
Monitoring and Handling Drift
Models in production face data drift and concept drift, which can degrade performance over time. Automating the detection of drift, triggering retraining, and validating new models without human intervention is challenging but critical for maintaining model accuracy.
Scalability and Resource Management
Training and serving ML models can be resource-intensive, especially with large datasets and complex architectures. Automating efficient resource allocation, scaling, and cost management across on-premises and cloud environments is a key challenge.
Security and Compliance
Automated pipelines must incorporate security best practices, including access control, data encryption, and audit logging. Ensuring compliance with regulations like GDPR or HIPAA adds additional layers of complexity to automation.
Cultural and Organizational Barriers
Beyond technical challenges, automating ML workflows requires cultural shifts. Collaboration between data scientists, engineers, and operations teams must be fostered, and processes standardized to support automation.
Designing Resilient and Scalable ML Pipelines
Designing resilient and scalable machine learning pipelines is fundamental to successful MLOps automation. As organizations deploy more models and handle increasing data volumes, pipelines must be robust enough to handle failures gracefully and scalable enough to meet growing demands.
Resilience in ML Pipelines
Resilience means that pipelines can recover from failures without manual intervention. This includes handling transient errors in data sources, network issues, or compute resource failures. Techniques such as retry mechanisms, checkpointing, and idempotent operations ensure that pipelines can resume from the last successful step, preventing data loss or corruption.
Building resilience also involves comprehensive monitoring and alerting. By tracking pipeline health, data quality, and model performance in real time, teams can detect issues early and trigger automated recovery or escalation processes.
Scalability Considerations
Scalability ensures that pipelines can process increasing amounts of data and support more complex models without degradation. This requires designing pipelines that can parallelize tasks, distribute workloads across multiple nodes or cloud services, and dynamically allocate resources based on demand.
Using containerization (e.g., Docker) and orchestration platforms (e.g., Kubernetes) enables portability and efficient scaling. Cloud-native services offer managed scaling capabilities, allowing pipelines to elastically adjust to workload fluctuations.
Modularity and Reusability
Designing pipelines as modular components promotes reusability and easier maintenance. Each stage—data ingestion, preprocessing, training, evaluation, deployment—should be encapsulated and independently testable. This modularity facilitates rapid iteration and integration of new features or models.
Automation and Workflow Orchestration
Automated orchestration tools like Apache Airflow, Kubeflow Pipelines, or Prefect manage dependencies, scheduling, and execution of pipeline components. They provide visibility into pipeline status and support complex workflows with conditional logic and parallelism.
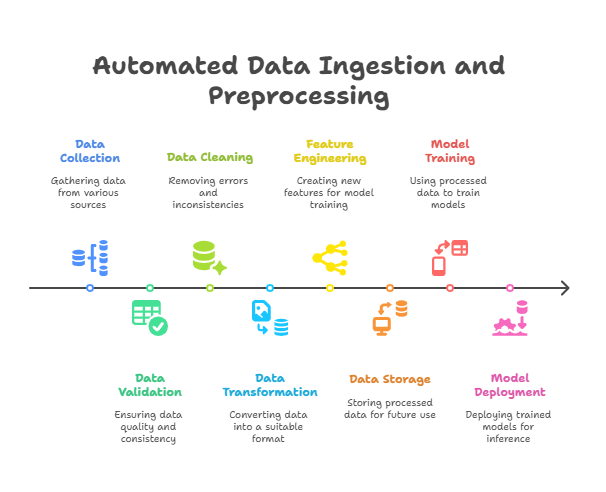
Automating Data Ingestion and Preprocessing
Automating data ingestion and preprocessing is a critical step in building efficient and reliable MLOps pipelines. These processes lay the foundation for high-quality machine learning models by ensuring that data is consistently collected, cleaned, transformed, and made ready for training and inference—without manual intervention.
The Importance of Automation in Data Ingestion
Data ingestion involves collecting data from various sources such as databases, APIs, streaming platforms, or external files. Automating this step ensures that data is ingested reliably and on schedule, reducing delays and human errors. Automated ingestion pipelines can handle data validation, schema enforcement, and error handling, ensuring that only clean and consistent data enters the ML workflow.
Automating Data Preprocessing
Preprocessing transforms raw data into a format suitable for model training. This includes handling missing values, encoding categorical variables, normalizing or scaling features, and generating new features. Automating these steps guarantees that preprocessing is consistent across training and inference, which is essential for model accuracy and reproducibility.
Tools and Techniques
Workflow Orchestration: Tools like Apache Airflow, Prefect, or Kubeflow Pipelines can schedule and manage data ingestion and preprocessing tasks, handling dependencies and retries.
Data Validation: Frameworks such as Great Expectations automate data quality checks, alerting teams to anomalies or schema changes.
Feature Stores: Centralized feature stores (e.g., Feast) enable reusable, versioned feature pipelines that serve both training and real-time inference.
Containerization: Packaging preprocessing code in containers ensures consistent execution across environments.
Benefits of Automation
Consistency: Automated pipelines reduce variability and ensure that data is processed identically every time.
Scalability: Automation enables handling large and growing datasets without increasing manual workload.
Speed: Faster data availability accelerates model training and deployment cycles.
Reliability: Automated error handling and monitoring reduce pipeline failures and data quality issues.
Continuous Integration and Continuous Deployment (CI/CD) for ML
Continuous Integration and Continuous Deployment (CI/CD) are essential practices in modern MLOps that enable teams to deliver machine learning models rapidly, reliably, and at scale. Unlike traditional software development, ML CI/CD pipelines must handle not only code changes but also data validation, model training, evaluation, and deployment, ensuring that every update maintains or improves model quality.
Why CI/CD Is Critical for ML
ML models are sensitive to changes in data, code, and environment. Without automated CI/CD pipelines, deploying new models or updates can be error-prone and slow, leading to inconsistent performance or downtime. CI/CD automates testing, validation, and deployment, reducing manual effort and enabling faster iteration.
Key Components of ML CI/CD Pipelines
Automated Testing: Run unit tests on data preprocessing and model code, integration tests on pipeline components, and validation tests on model performance.
Model Training and Validation: Automate training jobs triggered by new data or code changes, with automated evaluation against predefined metrics.
Model Registry Integration: Automatically register new model versions with metadata and performance metrics.
Deployment Automation: Deploy models to staging or production environments using containerization and orchestration tools.
Monitoring and Feedback: Integrate monitoring to track model performance post-deployment and trigger retraining or rollback if necessary.
Benefits of CI/CD in MLOps
Faster Time-to-Market: Automate repetitive tasks to accelerate model delivery.
Improved Quality: Automated tests and validations catch issues early.
Reproducibility: Version control and automated pipelines ensure consistent deployments.
Scalability: Manage multiple models and environments efficiently.
Automated Model Training and Hyperparameter Tuning
Automated model training and hyperparameter tuning are critical components of modern MLOps pipelines. They enable data science and engineering teams to efficiently explore a wide range of model configurations, optimize performance, and reduce manual effort. By automating these processes, organizations can accelerate experimentation, improve model accuracy, and ensure reproducibility.
Why Automate Model Training and Tuning?
Manual model training and hyperparameter tuning are time-consuming and often rely on trial-and-error. Automation allows for systematic exploration of hyperparameter spaces using advanced optimization algorithms, such as Bayesian optimization, grid search, or evolutionary strategies. This leads to better-performing models in less time.
Automated training pipelines also ensure consistency by standardizing data preprocessing, training routines, and evaluation metrics. This reduces human error and makes it easier to reproduce results across different environments.
Popular Tools and Frameworks
Ray Tune: A scalable library for distributed hyperparameter tuning with support for various search algorithms.
Optuna: An efficient hyperparameter optimization framework with pruning and visualization capabilities.
Hyperopt: A Python library for serial and parallel optimization over search spaces.
Keras Tuner: A user-friendly hyperparameter tuning framework for Keras models.
Example: Automated Hyperparameter Tuning with Ray Tune
Below is a simple Python example demonstrating how to use Ray Tune to automate hyperparameter tuning for a scikit-learn model:
python
import ray
from ray import tune
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
import numpy as np
def train_model(config):
data = load_iris()
X, y = data.data, data.target
model = RandomForestClassifier(
n_estimators=int(config["n_estimators"]),
max_depth=int(config["max_depth"]),
min_samples_split=int(config["min_samples_split"])
)
scores = cross_val_score(model, X, y, cv=3)
tune.report(mean_accuracy=np.mean(scores))
if __name__ == "__main__":
ray.init()
search_space = {
"n_estimators": tune.randint(10, 200),
"max_depth": tune.randint(1, 20),
"min_samples_split": tune.randint(2, 10)
}
analysis = tune.run(
train_model,
config=search_space,
num_samples=20,
resources_per_trial={"cpu": 1}
)
print("Best hyperparameters found were: ", analysis.best_config)Summary
Automated model training and hyperparameter tuning streamline the development of high-quality machine learning models. By leveraging scalable optimization frameworks, teams can efficiently explore complex parameter spaces, improve model performance, and accelerate deployment—key advantages in competitive, data-driven industries.
Implementing Automated Model Validation and Testing
Automated model validation and testing are essential components of a robust MLOps pipeline. They ensure that machine learning models meet quality standards before deployment, reducing the risk of errors, bias, or performance degradation in production. By integrating validation and testing into automated workflows, teams can accelerate development cycles while maintaining high confidence in their models.
Why Automated Validation and Testing Matter
Machine learning models are sensitive to changes in data, code, and environment. Without systematic validation, models may perform well during development but fail in production due to data drift, feature changes, or unexpected edge cases. Automated testing helps catch these issues early, ensuring models are reliable, fair, and aligned with business goals.
Key Components of Automated Validation
Data Validation: Check input data for schema consistency, missing values, outliers, and distribution shifts.
Model Performance Testing: Evaluate models on holdout datasets using metrics like accuracy, precision, recall, and F1-score.
Fairness and Bias Testing: Assess models for potential biases across different demographic groups.
Robustness Testing: Test model behavior on adversarial or noisy inputs to ensure stability.
Integration Testing: Verify that models work correctly within the full pipeline, including feature transformations and serving infrastructure.
Example: Simple Automated Validation in Python
python
from sklearn.metrics import accuracy_score, precision_score, recall_score
def validate_model(y_true, y_pred, min_accuracy=0.8):
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred, average='weighted')
recall = recall_score(y_true, y_pred, average='weighted')
print(f"Accuracy: {accuracy:.3f}")
print(f"Precision: {precision:.3f}")
print(f"Recall: {recall:.3f}")
if accuracy < min_accuracy:
raise ValueError(f"Model accuracy {accuracy:.3f} below threshold {min_accuracy}")
else:
print("Model validation passed.")
# Example usage
y_true = [0, 1, 1, 0, 1]
y_pred = [0, 1, 0, 0, 1]
validate_model(y_true, y_pred)Best Practices
Integrate validation tests into CI/CD pipelines to automate quality checks.
Use realistic and diverse datasets for testing to cover edge cases.
Continuously update validation criteria based on business needs and model evolution.
Combine multiple metrics to get a comprehensive view of model quality.
Real-Time Monitoring and Alerting for ML Systems
Real-time monitoring and alerting are critical components of modern MLOps, enabling organizations to maintain the health, performance, and reliability of machine learning models in production. As models interact with dynamic data and evolving environments, continuous observation ensures that issues are detected early and addressed promptly, minimizing business impact.
Why Real-Time Monitoring Matters
Machine learning models can degrade over time due to data drift, concept drift, or changes in user behavior. Real-time monitoring provides immediate visibility into these changes, allowing teams to detect anomalies such as sudden drops in accuracy, increased latency, or unexpected prediction distributions. This proactive approach helps prevent silent failures that could lead to incorrect decisions or customer dissatisfaction.
Key Metrics to Monitor
Model Performance: Track accuracy, precision, recall, F1-score, and other relevant metrics on live data.
Data Quality: Monitor input data for missing values, outliers, and distribution shifts.
Prediction Latency: Measure the time taken to generate predictions to ensure responsiveness.
Resource Utilization: Keep an eye on CPU, GPU, memory, and network usage to optimize infrastructure.
Error Rates: Detect failed predictions, timeouts, or system errors.
Implementing Automated Alerts
Automated alerting systems notify teams when metrics cross predefined thresholds or when anomalies are detected. Alerts can be configured to trigger emails, SMS, Slack messages, or integrate with incident management tools like PagerDuty. Effective alerting reduces response times and helps maintain service-level agreements (SLAs).
Example: Simple Python Alert for Accuracy Drop
python
def send_alert(message):
# Placeholder for alerting logic (email, Slack, etc.)
print(f"ALERT: {message}")
def monitor_accuracy(current_accuracy, threshold=0.85):
if current_accuracy < threshold:
send_alert(f"Model accuracy dropped to {current_accuracy:.2f}, below threshold {threshold}")
else:
print(f"Model accuracy is healthy: {current_accuracy:.2f}")
# Example usage
monitor_accuracy(0.82)Best Practices
Define meaningful thresholds to balance sensitivity and false positives.
Combine multiple metrics for comprehensive monitoring.
Regularly review and update alerting rules based on operational experience.
Integrate monitoring with automated retraining and rollback workflows.
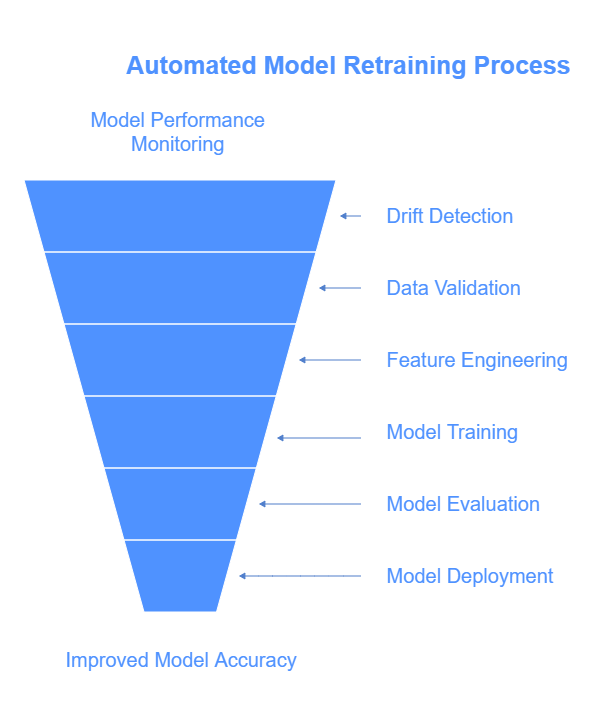
Automated Retraining and Model Lifecycle Management
Automated retraining and effective model lifecycle management are vital components of modern MLOps, ensuring that machine learning models remain accurate, relevant, and compliant over time. As data evolves and business environments change, models can degrade—a phenomenon known as model drift. Automated retraining pipelines help organizations proactively address this challenge by continuously updating models without manual intervention.
Automated Retraining
Automated retraining involves monitoring model performance and data quality in production, detecting when models no longer meet predefined thresholds, and triggering retraining workflows. These workflows typically include data validation, feature engineering, model training, evaluation, and deployment. By automating these steps, organizations can reduce downtime, improve model accuracy, and respond quickly to changing conditions.
Model Lifecycle Management
Managing the model lifecycle encompasses tracking model versions, managing promotions between stages (e.g., development, staging, production), and handling deprecation or archiving of outdated models. Effective lifecycle management ensures that only validated models are deployed, facilitates rollback in case of issues, and maintains audit trails for compliance.
Integration with Monitoring and CI/CD
Automated retraining pipelines are tightly integrated with monitoring systems that track key metrics and detect drift. They also connect with CI/CD pipelines to automate testing, validation, and deployment of new model versions. This integration creates a closed feedback loop that maintains model quality and operational efficiency.
Handling Failures and Implementing Self-Healing Mechanisms
In enterprise MLOps, handling failures effectively and implementing self-healing mechanisms are critical for maintaining the reliability and availability of machine learning systems. As ML pipelines become more complex and distributed across various environments, the likelihood of encountering failures—whether due to data issues, infrastructure problems, or model degradation—increases significantly. Proactive failure management ensures minimal downtime and sustained business value.
Understanding Failure Points
Failures can occur at multiple stages of the ML lifecycle: data ingestion may fail due to connectivity issues, feature engineering jobs might encounter corrupted data, model training can be interrupted by resource constraints, and deployed models may experience performance degradation or serving errors. Identifying these potential failure points is the first step toward building resilient systems.
Self-Healing Mechanisms
Self-healing refers to automated processes that detect failures or anomalies and initiate corrective actions without human intervention. Examples include:
Automatic retries: Re-executing failed jobs with exponential backoff.
Fallback models: Serving a previous stable model version if the current one fails or underperforms.
Automated retraining: Triggering model retraining when performance drops below thresholds.
Resource scaling: Dynamically adjusting compute resources to handle load spikes or recover from failures.
Alerting and escalation: Notifying teams only when automated recovery is insufficient.
Implementing Self-Healing in MLOps
Modern orchestration tools like Apache Airflow, Kubeflow Pipelines, and Prefect support retry policies, error handling, and conditional workflows that enable self-healing. Integrating these with monitoring systems allows pipelines to respond dynamically to real-time conditions.
Benefits
Increased uptime: Automated recovery reduces service interruptions.
Reduced operational burden: Less manual intervention frees teams to focus on innovation.
Improved user experience: Consistent model availability and performance maintain customer trust.
Faster incident resolution: Automated diagnostics and remediation speed up recovery.
Future Trends in MLOps Automation and Best Practices
The field of MLOps is rapidly evolving, driven by advances in automation, cloud computing, and AI itself. As organizations scale their machine learning initiatives, staying ahead of emerging trends and adopting best practices is essential for maintaining competitive advantage and operational excellence.
AI-Powered Automation
Future MLOps platforms will increasingly leverage AI to automate complex tasks such as anomaly detection, root cause analysis, and even automated model retraining. Self-healing pipelines will proactively identify and resolve issues without human intervention, reducing downtime and operational costs.
Unified Platforms and Toolchains
The trend toward unified MLOps platforms that integrate data engineering, model training, deployment, monitoring, and governance will continue. These platforms will provide seamless workflows across hybrid and multi-cloud environments, simplifying management and improving collaboration.
Explainability and Responsible AI
As regulatory scrutiny and ethical considerations grow, explainability and fairness monitoring will become integral to MLOps automation. Automated bias detection, transparency reports, and compliance checks will be standard features, helping organizations build trustworthy AI systems.
Edge and Federated Learning Support
With the rise of edge computing and federated learning, MLOps tools will evolve to support distributed training, deployment, and monitoring across decentralized environments. This will require new approaches to data privacy, synchronization, and resource management.
Cost and Sustainability Focus
Future MLOps solutions will provide real-time insights into resource usage, cost optimization, and environmental impact. Automated scheduling, resource allocation, and workload optimization will help organizations balance performance with sustainability goals.
MLOps for Developers – A Guide to Modern Workflows
MLOps in Practice – How to Automate the Machine Learning Model Lifecycle
Monitoring Models in Production – Tools and Strategies for 2025