

1. Introduction to MLOps in Practice
In recent years, machine learning (ML) has become a driving force behind innovation in various industries, from finance and healthcare to retail and manufacturing. However, building a successful machine learning model is only the beginning of the journey. The real challenge lies in deploying, managing, and maintaining these models in production environments, where they must deliver consistent value and adapt to changing data and business requirements.
This is where MLOps—short for Machine Learning Operations—comes into play. MLOps is a set of practices that combines machine learning, DevOps, and data engineering to streamline and automate the end-to-end lifecycle of ML models. The goal of MLOps is to bridge the gap between data science and IT operations, enabling organizations to develop, deploy, monitor, and update models efficiently and reliably.
By adopting MLOps, companies can accelerate the time-to-market for their ML solutions, improve collaboration between teams, ensure reproducibility, and reduce operational risks. MLOps is not just about tools and automation; it’s also about establishing processes, standards, and a culture that supports continuous improvement and innovation in machine learning projects.
2. Why Is Automating the ML Model Lifecycle Essential?
The lifecycle of a machine learning model involves several complex and interdependent stages, including data collection, preprocessing, model training, validation, deployment, and ongoing monitoring. Managing these stages manually can be time-consuming, error-prone, and difficult to scale, especially as the number of models and data sources grows.
Automating the ML model lifecycle is essential for several reasons:
First, automation reduces the risk of human error and ensures that processes are repeatable and consistent. This is crucial for maintaining model quality and compliance, especially in regulated industries.
Second, automation accelerates the development and deployment of models. By automating tasks such as data preprocessing, model training, and deployment, data science teams can focus on experimentation and innovation rather than repetitive manual work.
Third, automated workflows enable rapid iteration and continuous delivery. As new data becomes available or business requirements change, models can be retrained, validated, and redeployed quickly, ensuring that they remain accurate and relevant.
Finally, automation supports better collaboration between data scientists, engineers, and operations teams. With standardized pipelines and clear handoffs, teams can work more efficiently and respond to issues faster.
In summary, automating the ML model lifecycle is a key enabler for scaling machine learning initiatives, improving model performance, and delivering real business value.
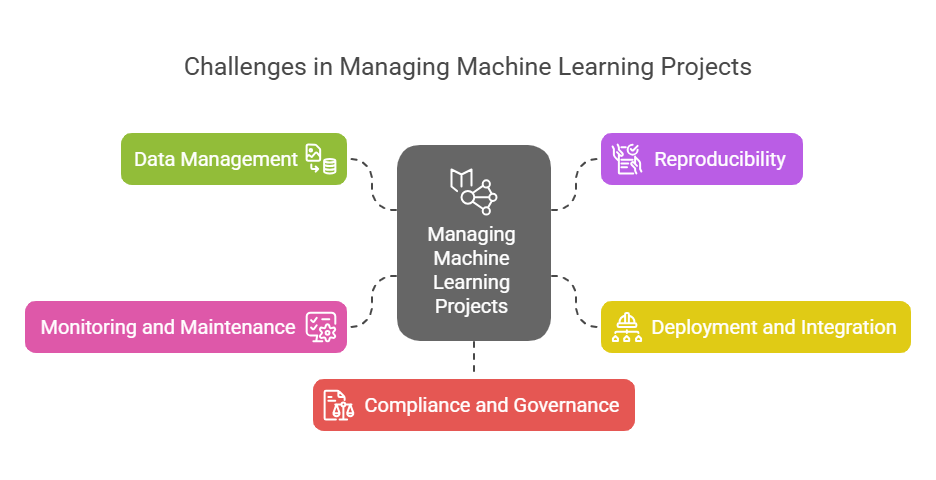
3. Main Challenges in Managing Machine Learning Projects
Managing machine learning projects presents unique challenges that go beyond traditional software development. While building a model in a research environment can be straightforward, moving it into production and ensuring its long-term success is a complex process. Here are some of the main challenges organizations face:
One of the biggest challenges is data management. Machine learning models rely on high-quality, well-labeled data, but collecting, cleaning, and maintaining this data can be difficult. Data can change over time (a phenomenon known as data drift), leading to decreased model performance if not monitored and updated regularly.
Another significant challenge is reproducibility. In many organizations, experiments are run in ad-hoc environments, making it hard to reproduce results or track which data, code, and parameters were used to train a particular model. This lack of reproducibility can hinder collaboration and make it difficult to debug or improve models.
Deployment and integration with existing systems also pose challenges. Unlike traditional software, ML models often require specialized infrastructure for serving predictions, handling large volumes of data, and scaling to meet demand. Integrating models into business processes and ensuring they work reliably in production environments requires close collaboration between data scientists, engineers, and IT teams.
Monitoring and maintenance are critical but often overlooked aspects of ML projects. Once deployed, models must be continuously monitored for performance, fairness, and security. Over time, changes in data or user behavior can cause models to degrade, requiring retraining or updates. Without proper monitoring, organizations risk making decisions based on outdated or biased models.
Finally, compliance and governance are increasingly important, especially in regulated industries. Organizations must ensure that their ML models meet legal and ethical standards, protect user privacy, and provide transparency into how decisions are made.
Addressing these challenges requires a combination of robust processes, effective collaboration, and the right tools—core principles at the heart of MLOps.
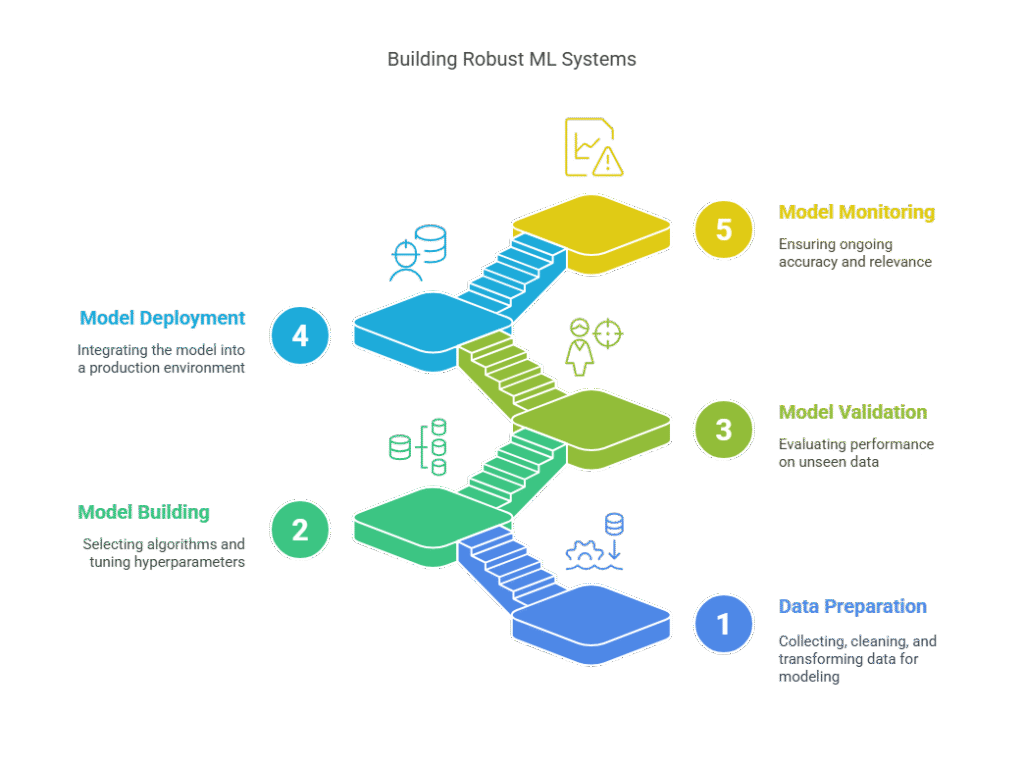
4. Key Elements of the ML Model Lifecycle
Successfully managing machine learning projects requires a clear understanding of the model lifecycle and its key components. Each stage plays a crucial role in ensuring that models are accurate, reliable, and deliver real business value. Below, we explore the main elements of the ML model lifecycle.
4.1. Data Preparation
Data preparation is the foundation of any machine learning project. This stage involves collecting raw data from various sources, cleaning it to remove errors or inconsistencies, and transforming it into a format suitable for modeling. Tasks such as handling missing values, encoding categorical variables, and feature engineering are essential to ensure the quality and relevance of the data. Well-prepared data not only improves model performance but also reduces the risk of bias and overfitting.
4.2. Model Building and Training
Once the data is ready, the next step is to build and train machine learning models. This involves selecting appropriate algorithms, splitting the data into training and validation sets, and tuning hyperparameters to optimize performance. Data scientists often experiment with different models and configurations to find the best solution for the problem at hand. Proper documentation and versioning of code, data, and model parameters are critical at this stage to ensure reproducibility and facilitate collaboration.
4.3. Model Validation and Testing
Before deploying a model to production, it must be thoroughly validated and tested. This stage involves evaluating the model’s performance on unseen data, using metrics such as accuracy, precision, recall, or F1-score, depending on the use case. Validation helps identify issues like overfitting, underfitting, or data leakage. In some cases, additional tests for fairness, robustness, and explainability are required, especially in sensitive applications. Rigorous validation ensures that the model will perform reliably in real-world scenarios.
4.4. Model Deployment
Model deployment is the process of integrating the trained model into a production environment where it can make real-time or batch predictions. This step often requires collaboration between data scientists, software engineers, and IT teams to ensure the model is accessible, scalable, and secure. Deployment can take various forms, such as REST APIs, batch processing jobs, or embedded systems. Automation tools and CI/CD pipelines are increasingly used to streamline and standardize the deployment process, reducing the risk of errors and downtime.
4.5. Model Monitoring and Maintenance
The lifecycle does not end with deployment. Continuous monitoring and maintenance are essential to ensure that the model remains accurate and relevant over time. Monitoring involves tracking key performance metrics, detecting data drift, and identifying anomalies or unexpected behavior. When performance degrades, retraining or updating the model may be necessary. Maintenance also includes managing model versions, handling rollback procedures, and ensuring compliance with regulatory requirements. Effective monitoring and maintenance help organizations maximize the value of their machine learning investments and respond quickly to changing business needs.
Understanding and optimizing each of these stages is fundamental to building robust, scalable, and trustworthy machine learning systems. MLOps practices and tools are designed to support and automate these elements, enabling organizations to deliver high-quality models efficiently and at scale.
5. Automating MLOps Processes – Tools and Technologies
Automation is at the heart of MLOps, enabling organizations to efficiently manage the complex and repetitive tasks involved in the machine learning lifecycle. By leveraging the right tools and technologies, teams can streamline workflows, improve collaboration, and ensure that models are delivered quickly and reliably. Below, we discuss the key areas of automation in MLOps and the technologies that support them.
5.1. Data Management Systems
Effective data management is essential for building robust machine learning models. Modern data management systems automate the collection, storage, versioning, and governance of data. Tools such as Data Version Control (DVC), Delta Lake, and Apache Hudi help track changes in datasets, ensure data lineage, and facilitate collaboration between teams. Automated data pipelines, built with tools like Apache Airflow or Kubeflow Pipelines, orchestrate the flow of data from raw sources to processed, model-ready formats, reducing manual intervention and errors.
5.2. Training and Experiment Automation
Automating the training and experimentation process allows data scientists to iterate quickly and efficiently. Experiment tracking tools like MLflow, Weights & Biases, and Neptune.ai record model parameters, metrics, and artifacts, making it easy to compare results and reproduce experiments. Automated training pipelines can be triggered by new data or code changes, ensuring that models are always up to date. Hyperparameter optimization frameworks, such as Optuna or Ray Tune, further automate the search for the best model configurations, saving time and computational resources.
5.3. CI/CD for Machine Learning
Continuous Integration and Continuous Deployment (CI/CD) practices, widely used in software engineering, are increasingly adopted in machine learning projects. CI/CD pipelines automate the testing, validation, and deployment of models, ensuring that only high-quality models reach production. Tools like Jenkins, GitHub Actions, and GitLab CI/CD can be integrated with ML-specific platforms such as Seldon Core or Kubeflow to automate the end-to-end workflow. Automated CI/CD reduces the risk of human error, accelerates release cycles, and enables rapid rollback in case of issues.
5.4. Model Monitoring and Retraining
Once models are deployed, continuous monitoring is crucial to detect performance degradation, data drift, or anomalies. Automated monitoring tools, such as Evidently AI, Prometheus, or Azure Monitor, track key metrics and trigger alerts when issues are detected. When a model’s performance drops below a certain threshold, automated retraining pipelines can be initiated to update the model with new data. This closed-loop system ensures that models remain accurate and relevant, minimizing manual intervention and operational risk.
By adopting these automation tools and technologies, organizations can build scalable, reliable, and efficient machine learning systems. Automation not only accelerates the delivery of ML solutions but also enhances reproducibility, transparency, and collaboration across teams—key benefits that drive the success of MLOps initiatives.
6. Example MLOps Workflow in Practice
To understand how MLOps works in a real-world setting, let’s walk through a typical workflow that automates the end-to-end lifecycle of a machine learning model. This example demonstrates how different stages and tools come together to deliver a robust, production-ready solution.
The process begins with data ingestion, where raw data is automatically collected from various sources such as databases, APIs, or data lakes. Automated data pipelines, often built with tools like Apache Airflow or Kubeflow Pipelines, handle data cleaning, transformation, and feature engineering. The processed data is then stored in a version-controlled repository, ensuring traceability and reproducibility.
Next, the model training phase is triggered, either on a schedule or in response to new data. Experiment tracking tools like MLflow or Weights & Biases log all relevant information, including code versions, parameters, and evaluation metrics. Hyperparameter optimization frameworks can be used to automatically search for the best model configuration, further improving performance.
Once a satisfactory model is trained, it undergoes automated validation and testing. The model is evaluated on holdout datasets, and additional checks for fairness, robustness, and explainability may be performed. If the model meets predefined quality thresholds, it is automatically packaged and deployed to a production environment using CI/CD pipelines. Tools like Jenkins, GitHub Actions, or Seldon Core ensure that deployment is consistent, repeatable, and can be rolled back if necessary.
After deployment, the model is continuously monitored using automated tools that track performance metrics, detect data drift, and identify anomalies. If the model’s performance degrades or new data patterns emerge, the workflow can trigger automated retraining and redeployment, ensuring that the model remains accurate and relevant.
Throughout this process, collaboration between data scientists, engineers, and operations teams is facilitated by shared tools, standardized workflows, and clear documentation. Automation reduces manual effort, minimizes errors, and accelerates the delivery of machine learning solutions.
This example illustrates how MLOps practices and tools can transform the machine learning lifecycle from a series of manual, disconnected steps into a streamlined, automated, and scalable process—enabling organizations to unlock the full potential of their data and models.
Let’s look at some practical Python code examples that demonstrate key elements of the MLOps workflow:
Data Pipeline Example
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import mlflow
def prepare_data(raw_data_path):
# Log the data preparation step
mlflow.start_run(run_name="data_preparation")
# Load and preprocess data
df = pd.read_csv(raw_data_path)
# Basic data cleaning
df = df.dropna()
# Feature engineering
X = df.drop('target', axis=1)
y = df['target']
# Split the data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Log parameters
mlflow.log_param("data_path", raw_data_path)
mlflow.log_param("train_size", len(X_train))
mlflow.log_param("test_size", len(X_test))
mlflow.end_run()
return X_train_scaled, X_test_scaled, y_train, y_testModel Training and Experiment Tracking
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score
import mlflow.sklearn
def train_model(X_train, X_test, y_train, y_test):
# Start MLflow run
with mlflow.start_run(run_name="model_training"):
# Define model parameters
params = {
"n_estimators": 100,
"max_depth": 10,
"random_state": 42
}
# Train model
model = RandomForestClassifier(**params)
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Calculate metrics
metrics = {
"accuracy": accuracy_score(y_test, y_pred),
"precision": precision_score(y_test, y_pred, average='weighted'),
"recall": recall_score(y_test, y_pred, average='weighted')
}
# Log parameters and metrics
mlflow.log_params(params)
mlflow.log_metrics(metrics)
# Log model
mlflow.sklearn.log_model(model, "random_forest_model")
return model, metrics
Model Monitoring
import numpy as np
from datetime import datetime
class ModelMonitor:
def __init__(self, model, threshold=0.7):
self.model = model
self.threshold = threshold
self.predictions_log = []
self.performance_history = []
def monitor_prediction(self, X, y_true):
# Make prediction
y_pred = self.model.predict(X)
# Calculate accuracy
accuracy = accuracy_score(y_true, y_pred)
# Log performance
timestamp = datetime.now()
self.performance_history.append({
'timestamp': timestamp,
'accuracy': accuracy
})
# Check for performance degradation
if accuracy < self.threshold:
self._alert_performance_degradation(accuracy)
return accuracy
def _alert_performance_degradation(self, current_accuracy):
print(f"ALERT: Model performance below threshold!")
print(f"Current accuracy: {current_accuracy:.4f}")
print(f"Threshold: {self.threshold}")
print("Recommendation: Consider retraining the model.")
# Example usage
def monitor_model_performance(model, X_test, y_test):
monitor = ModelMonitor(model, threshold=0.7)
# Simulate monitoring over time
for i in range(3): # Simulate 3 monitoring periods
# Add some noise to test data to simulate data drift
X_test_noisy = X_test + np.random.normal(0, 0.1 * i, X_test.shape)
# Monitor performance
accuracy = monitor.monitor_prediction(X_test_noisy, y_test)
print(f"Monitoring period {i+1}: Accuracy = {accuracy:.4f}")Automated Retraining Pipeline
class AutomatedRetraining:
def __init__(self, base_model, retrain_threshold=0.7):
self.base_model = base_model
self.retrain_threshold = retrain_threshold
self.current_model = base_model
def evaluate_and_retrain(self, X_train, X_test, y_train, y_test):
# Evaluate current model
current_accuracy = accuracy_score(
y_test,
self.current_model.predict(X_test)
)
if current_accuracy < self.retrain_threshold:
print("Performance below threshold. Initiating retraining...")
# Retrain model with new data
new_model = RandomForestClassifier(
n_estimators=100,
max_depth=10,
random_state=42
)
new_model.fit(X_train, y_train)
# Evaluate new model
new_accuracy = accuracy_score(
y_test,
new_model.predict(X_test)
)
if new_accuracy > current_accuracy:
self.current_model = new_model
print(f"Model updated. New accuracy: {new_accuracy:.4f}")
else:
print("New model did not improve performance. Keeping current model.")
return self.current_model7. Best Practices for Implementing MLOps in an Organization
Successfully implementing MLOps in an organization requires more than just adopting new tools—it involves building a culture of collaboration, standardizing processes, and continuously improving workflows. Here are some best practices to help organizations get the most out of their MLOps initiatives:
First, establish clear roles and responsibilities across teams. Data scientists, data engineers, DevOps specialists, and business stakeholders should work together from the start, ensuring that everyone understands their part in the machine learning lifecycle. Cross-functional collaboration helps avoid silos and accelerates problem-solving.
Second, standardize workflows and processes. Use version control for code, data, and models to ensure reproducibility and traceability. Implement automated pipelines for data processing, model training, validation, and deployment. Standardization not only improves efficiency but also makes it easier to onboard new team members and scale projects.
Third, prioritize monitoring and observability. Set up automated monitoring for model performance, data quality, and system health. Define clear metrics and thresholds for triggering alerts and retraining. Proactive monitoring helps catch issues early, reducing downtime and ensuring that models continue to deliver value.
Fourth, invest in documentation and knowledge sharing. Maintain comprehensive documentation for data sources, model architectures, experiment results, and deployment procedures. Encourage teams to share lessons learned and best practices, fostering a culture of continuous learning and improvement.
Fifth, focus on security, compliance, and ethical considerations. Ensure that data privacy and security standards are met throughout the ML lifecycle. Regularly review models for fairness, bias, and explainability, especially in regulated industries. Establish governance frameworks to manage access, approvals, and audit trails.
Finally, start small and iterate. Begin with pilot projects to demonstrate value and refine processes before scaling MLOps practices across the organization. Gather feedback, measure outcomes, and continuously optimize workflows based on real-world experience.
By following these best practices, organizations can build a strong foundation for MLOps, enabling them to deliver reliable, scalable, and impactful machine learning solutions that drive business success.
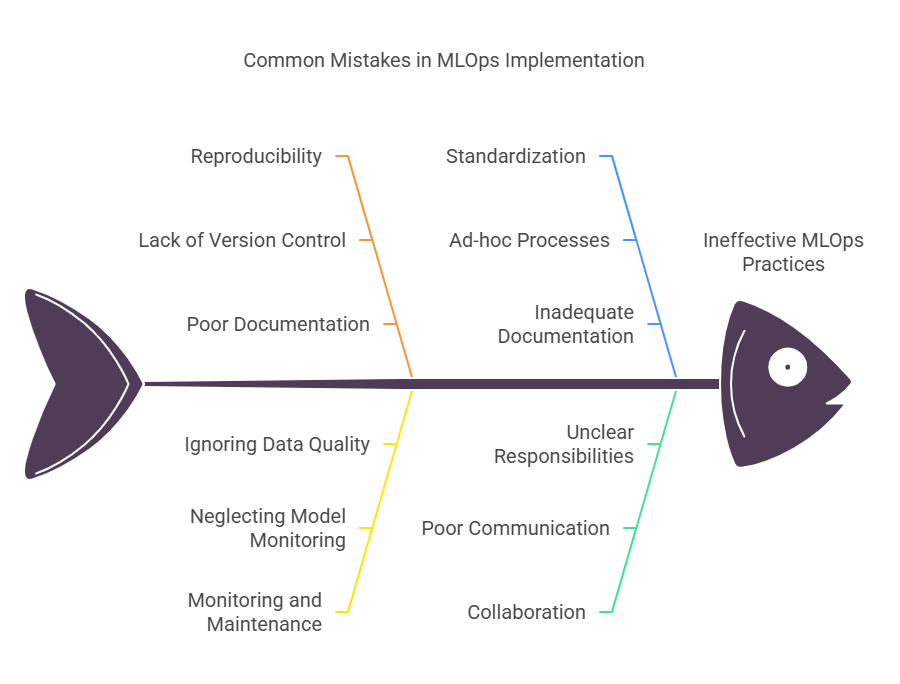
8. Common Mistakes and How to Avoid Them
Implementing MLOps can bring significant benefits, but organizations often encounter common pitfalls that can hinder progress and reduce the value of their machine learning initiatives. Recognizing these mistakes early and taking steps to avoid them is crucial for building effective and sustainable MLOps practices.
One frequent mistake is neglecting reproducibility. Without proper version control for data, code, and models, it becomes difficult to reproduce results, debug issues, or collaborate effectively. To avoid this, always use tools that track changes and maintain detailed records of experiments, datasets, and model versions.
Another common issue is underestimating the importance of monitoring and maintenance. Many teams focus heavily on model development and deployment but overlook the need for continuous monitoring of model performance and data quality. This can lead to unnoticed model drift, degraded performance, or even biased predictions. Setting up automated monitoring and alerting systems ensures that issues are detected and addressed promptly.
A third mistake is failing to standardize workflows and processes. Ad-hoc or inconsistent approaches to data preparation, model training, and deployment can result in inefficiencies, errors, and difficulties in scaling. Establishing standardized, automated pipelines and clear documentation helps maintain consistency and quality across projects.
Organizations also sometimes overlook collaboration between teams. Machine learning projects require input from data scientists, engineers, IT, and business stakeholders. Poor communication or unclear responsibilities can slow down progress and lead to misaligned goals. Encouraging cross-functional collaboration and regular communication helps keep projects on track.
Security and compliance are often underestimated, especially in the rush to deploy models quickly. Ignoring data privacy, access controls, or regulatory requirements can expose organizations to significant risks. Integrating security and compliance checks into every stage of the ML lifecycle is essential for protecting sensitive data and meeting legal obligations.
Finally, trying to automate everything from the start can be counterproductive. Overcomplicating workflows or investing in unnecessary tools can slow down adoption and create confusion. It’s better to start with the most impactful automation opportunities, demonstrate value, and gradually expand as the organization matures.
By being aware of these common mistakes and proactively addressing them, organizations can build more robust, scalable, and successful MLOps practices that deliver lasting business value.
9. Summary and Recommendations
In summary, MLOps is a critical set of practices for organizations looking to scale their machine learning initiatives and realize the full potential of their data. By automating the end-to-end lifecycle of ML models, MLOps enables teams to develop, deploy, monitor, and maintain models efficiently and reliably. This not only accelerates the time-to-market for ML solutions but also improves collaboration, ensures reproducibility, and reduces operational risks.
Throughout this article, we’ve explored the key elements of the ML model lifecycle, the main challenges in managing ML projects, and the tools and technologies that support automation. We’ve also discussed best practices for implementing MLOps in an organization and common mistakes to avoid.
Based on these insights, here are some key recommendations for organizations embarking on their MLOps journey:
First, prioritize automation. Identify the most time-consuming and error-prone tasks in your ML lifecycle and automate them using appropriate tools and technologies. Start with data preparation, model training, and deployment, and gradually expand to other areas.
Second, foster collaboration. Break down silos between data scientists, engineers, and operations teams by establishing clear roles and responsibilities, promoting open communication, and using shared tools and workflows.
Third, focus on monitoring and maintenance. Implement automated monitoring for model performance, data quality, and system health. Set up alerts and retraining pipelines to ensure that models remain accurate and relevant over time.
Fourth, embrace standardization. Use version control for code, data, and models. Implement standardized pipelines for data processing, model training, validation, and deployment. This will improve efficiency, reproducibility, and scalability.
Fifth, start small and iterate. Begin with pilot projects to demonstrate value and refine processes before scaling MLOps practices across the organization. Gather feedback, measure outcomes, and continuously optimize workflows based on real-world experience.
By following these recommendations, organizations can build a strong foundation for MLOps, enabling them to deliver high-quality machine learning solutions that drive business success. MLOps is not just a set of tools or processes—it’s a cultural shift that requires commitment, collaboration, and continuous improvement. With the right approach, organizations can unlock the full potential of their data and models, transforming their businesses and creating new opportunities for innovation.
10. Additional Resources and Literature
For organizations and professionals looking to deepen their understanding of MLOps and stay up to date with the latest trends, there is a wealth of resources available. Below are some recommended books, articles, online courses, and communities that can help you expand your knowledge and successfully implement MLOps in your projects.
Books:
Some of the most comprehensive books on MLOps include “Practical MLOps” by Noah Gift and Alfredo Deza, “Machine Learning Engineering” by Andriy Burkov, and “Introducing MLOps” by Mark Treveil and Alok Shukla. These books cover both the theoretical foundations and practical aspects of deploying and managing machine learning systems at scale.
Online Courses:
Platforms like Coursera, Udemy, and DataCamp offer specialized courses on MLOps, such as “MLOps (Machine Learning Operations) Fundamentals” by Google Cloud and “Production Machine Learning Systems” by DeepLearning.AI. These courses provide hands-on experience with popular tools and real-world workflows.
Articles and Blogs:
Leading technology companies and research organizations regularly publish articles and case studies on MLOps best practices. Blogs from Google Cloud, AWS, Microsoft Azure, and Databricks are excellent sources of up-to-date information, tutorials, and industry insights.
Open Source Tools and Documentation:
Exploring the official documentation of open source MLOps tools—such as MLflow, Kubeflow, DVC, Seldon Core, and TFX—can provide practical guidance on implementing automation, experiment tracking, and deployment pipelines.
Communities and Forums:
Engaging with the MLOps community can accelerate learning and problem-solving. Online forums like Stack Overflow, the MLOps Community Slack, and LinkedIn groups offer opportunities to ask questions, share experiences, and connect with experts in the field.
Academic Papers and Conferences:
For those interested in the latest research, academic conferences such as NeurIPS, ICML, and KDD often feature sessions on MLOps, model deployment, and production machine learning. Reading recent papers can provide insights into emerging trends and advanced techniques.
By leveraging these resources, you can stay informed about the evolving landscape of MLOps, learn from industry leaders, and continuously improve your organization’s machine learning operations. Continuous learning and active participation in the MLOps community are key to building robust, scalable, and innovative ML solutions.
Read more
Real-Time Monitoring Strategies for LLMs in MLOps Pipelines
Understanding MLOps: Transforming Business Operations Through Machine Learning
MLOps for Small Teams: How to Implement Without Breaking the Budget