

Introduction: Why Programmers Should Care About MLOps
In today’s technology landscape, machine learning is no longer the exclusive domain of data scientists. As organizations increasingly rely on AI-driven solutions, programmers are finding themselves at the heart of machine learning projects. MLOps—short for Machine Learning Operations—bridges the gap between software engineering and data science, enabling teams to build, deploy, and maintain machine learning models efficiently and reliably.
For programmers, understanding MLOps is becoming essential. It’s not just about writing code for models, but about ensuring that these models can be integrated into real-world applications, scaled to handle production workloads, and maintained over time. MLOps introduces practices such as version control, continuous integration, automated testing, and monitoring—concepts familiar to software engineers, but now applied to the unique challenges of machine learning. By embracing MLOps, programmers can contribute to robust, scalable AI systems and play a key role in delivering business value from machine learning initiatives.
The Evolution of MLOps: From DevOps to Machine Learning
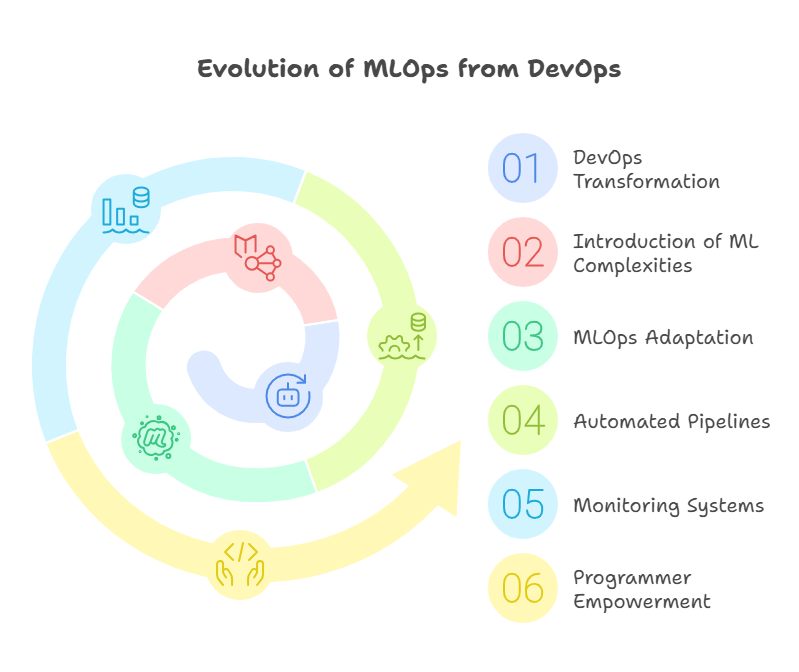
The rise of MLOps is closely linked to the evolution of DevOps in traditional software development. DevOps transformed the way software is built, tested, and deployed by promoting automation, collaboration, and continuous delivery. However, machine learning projects introduce new complexities: data changes over time, models can degrade, and reproducibility is more challenging due to the stochastic nature of training.
MLOps adapts DevOps principles to the world of machine learning. It extends the focus beyond code to include data, model artifacts, and the entire ML lifecycle. This means tracking not only code changes, but also data versions and model parameters. Automated pipelines are used to retrain and redeploy models as new data arrives, and monitoring systems are put in place to detect data drift or performance drops in production.
For programmers, this evolution means learning new tools and workflows, but also leveraging familiar concepts in a new context. MLOps empowers developers to collaborate more effectively with data scientists, automate repetitive tasks, and ensure that machine learning models deliver consistent, reliable results in production environments. As MLOps continues to mature, programmers who embrace these practices will be well-positioned to drive innovation in AI-powered applications.
Key Skills for Programmers Entering MLOps
Transitioning into the world of MLOps requires programmers to expand their skill set beyond traditional software development. While strong coding abilities in languages like Python or Java remain fundamental, MLOps introduces new domains that blend software engineering, data science, and operations.
A solid understanding of machine learning concepts is essential, even if you’re not building models from scratch. Familiarity with data preprocessing, model training, evaluation metrics, and the basics of supervised and unsupervised learning helps programmers communicate effectively with data scientists and understand the requirements of ML workflows.
Version control is another critical skill, but in MLOps, it extends beyond code to include data and model artifacts. Tools like Git, DVC (Data Version Control), and MLflow help track changes and ensure reproducibility. Experience with containerization technologies such as Docker and orchestration platforms like Kubernetes is increasingly valuable, as these tools are often used to package and deploy ML models at scale.
Automation is at the heart of MLOps. Programmers should be comfortable with scripting, building CI/CD pipelines, and using workflow orchestration tools like Airflow or Kubeflow Pipelines. Additionally, knowledge of cloud platforms (AWS, Azure, GCP) and their ML services can be a significant advantage, as many organizations run their ML workloads in the cloud.
Finally, strong collaboration and communication skills are vital. MLOps is inherently cross-functional, requiring close cooperation between software engineers, data scientists, and operations teams. Programmers who can bridge these disciplines and adapt to new tools and processes will thrive in the evolving landscape of MLOps.
Setting Up Your MLOps Development Environment
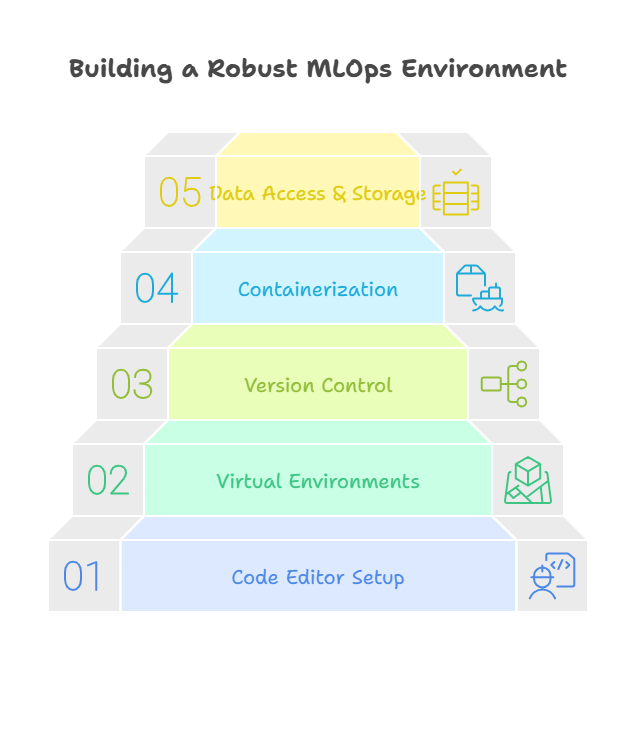
A well-configured development environment is the foundation for effective work in MLOps. For programmers, this means creating a setup that supports experimentation, collaboration, and smooth transition from local development to production deployment.
Start with a robust code editor or IDE, such as VS Code or PyCharm, equipped with plugins for Python, Docker, and version control. Use virtual environments (like venv or conda) to manage dependencies and ensure consistency across projects. Integrate Git for source code management, and consider tools like DVC or MLflow for tracking data and model versions.
Containerization is a best practice in MLOps, so installing Docker is highly recommended. This allows you to package your code, dependencies, and models into portable containers that can run anywhere—from your laptop to a cloud server. For more advanced setups, Kubernetes can be used to orchestrate containers and manage resources at scale.
Data access and storage are also key considerations. Set up secure connections to data sources, whether they’re local files, databases, or cloud storage buckets. Use environment variables or secret managers to handle credentials safely.
Finally, consider integrating workflow automation tools early in your environment. Tools like Airflow, Prefect, or Kubeflow Pipelines can help automate data ingestion, model training, and deployment tasks. By investing time in setting up a flexible, reproducible, and secure development environment, programmers lay the groundwork for successful MLOps projects and seamless collaboration with the broader team.
Version Control for Code, Data, and Models
Version control is a cornerstone of modern software development, and in MLOps, its importance extends far beyond just tracking code changes. In machine learning projects, not only the code but also the data and model artifacts evolve over time. Managing these elements systematically is essential for reproducibility, collaboration, and troubleshooting.
For code, Git remains the standard tool, enabling teams to collaborate, review changes, and roll back to previous versions when needed. However, machine learning workflows introduce new challenges: datasets can be large and change frequently, and models are often retrained and updated as new data arrives. This is where specialized tools like DVC (Data Version Control) and MLflow come into play. DVC allows you to version datasets and model files alongside your code, storing large files efficiently and tracking their lineage. MLflow, on the other hand, helps manage model experiments, track parameters, and store model artifacts, making it easier to reproduce results and compare different runs.
By adopting robust version control practices for code, data, and models, programmers ensure that every experiment is traceable, every deployment is reproducible, and collaboration across teams is seamless. This approach not only reduces errors but also accelerates the development cycle, as teams can confidently build on previous work and quickly identify the source of any issues.
Automating Machine Learning Workflows
Automation is at the heart of MLOps, transforming manual, error-prone processes into reliable, repeatable pipelines. For programmers, automating machine learning workflows means orchestrating tasks such as data ingestion, preprocessing, model training, evaluation, and deployment, so that they can run with minimal human intervention.
Workflow orchestration tools like Apache Airflow, Prefect, or Kubeflow Pipelines are commonly used to define and manage these pipelines. With these tools, you can schedule tasks, handle dependencies, and monitor execution, ensuring that each step in the ML lifecycle is executed in the correct order and under the right conditions. For example, a pipeline might automatically retrain a model when new data is available, run validation tests, and deploy the updated model to production if it meets performance criteria.
Continuous integration and continuous deployment (CI/CD) practices, familiar from software engineering, are also applied in MLOps. Automated testing ensures that code changes do not break existing functionality, while automated deployment pipelines make it possible to release new models quickly and safely.
By embracing automation, programmers reduce the risk of human error, speed up development cycles, and free up time for more creative and impactful work. Automated workflows also make it easier to scale machine learning operations, as processes that work for one model or dataset can be replicated across many projects and environments.
Model Deployment: From Local to Production
Deploying an ML model is more than “saving a .pkl file and calling predict()”. Production-grade deployment must guarantee:
Reproducible environments
Scalable and low-latency inference
CI/CD safety nets (tests, roll-backs, canary releases)
Observability hooks for monitoring
Typical Deployment Path
Local validation (notebooks / scripts)
API wrapper (Flask, FastAPI, Django REST)
Containerization (Docker) to freeze dependencies
Orchestration (Kubernetes, ECS, Cloud Run, Azure AKS, etc.)
Automated promotion via CI/CD (GitHub Actions, GitLab CI, Azure DevOps)
Example: FastAPI Inference Service + Docker
Below is a minimal but production-ready pattern for deploying a Scikit-learn classifier. It exposes:
• /health — liveness probe
• /predict — JSON inference endpoint
• /metrics — Prometheus metrics for monitoring (see section 8)
python
# app.py
import os
import joblib
import uvicorn
from fastapi import FastAPI
from pydantic import BaseModel
from prometheus_client import Counter, Histogram, generate_latest
# ----- FastAPI setup -----
app = FastAPI(title="Iris Classifier")
class IrisRequest(BaseModel):
sepal_length: float
sepal_width: float
petal_length: float
petal_width: float
# ----- Prometheus metrics -----
PREDICTIONS = Counter("pred_total", "Number of predictions")
LATENCY = Histogram("pred_latency_seconds", "Prediction latency")
# ----- Load model once at startup -----
MODEL_PATH = os.getenv("MODEL_PATH", "model.joblib")
model = joblib.load(MODEL_PATH)
@app.get("/health")
def health():
return {"status": "ok"}
@app.post("/predict")
@LATENCY.time()
def predict(req: IrisRequest):
PREDICTIONS.inc()
data = [[
req.sepal_length, req.sepal_width,
req.petal_length, req.petal_width
]]
pred = int(model.predict(data)[0])
return {"class": pred}
@app.get("/metrics")
def metrics():
return generate_latest(), 200, {"Content-Type": "text/plain; version=0.0.4"}
if __name__ == "__main__":
uvicorn.run("app:app", host="0.0.0.0", port=8000)Dockerfile:
dockerfile
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY model.joblib .
COPY app.py .
EXPOSE 8000
CMD ["python", "app.py"]CI/CD pipelines (GitHub Actions example) can build, test, push the image to a registry, then roll out the new tag to Kubernetes with a canary strategy.
Monitoring and Maintaining ML Systems
Once live, a model becomes a moving target: data drifts, concepts shift, and infra hiccups threaten performance. Monitoring ≠ only accuracy; it spans business, model, and operational metrics.
What to Track
Layer Examples
Business conversion rate, churn lift
Model Quality accuracy, precision, F1, AUC, drift stats
Data feature distributions, missing-value rate
Ops / Infra latency, throughput, CPU/GPU, memory
Fairness / XAI group metrics, SHAP stability
Instrumentation Strategy
In-service metrics (Prometheus/OpenTelemetry) for latency & traffic
Prediction logs streamed to a feature store or lake for offline analysis
Drift detection jobs that compare real-time data to reference windows
Automated retraining triggers when performance crosses thresholds
Alerting (PagerDuty, Slack) wired to critical SLO breaches
Extending the FastAPI Service with Drift Detection
Below, a background task collects 1000 latest predictions and runs Evidently every 10 minutes. If drift exceeds a threshold, it publishes an alert (here: simple log, but could call Slack or create a Jira ticket).
python
# monitor.py
import asyncio
import logging
import pandas as pd
from evidently.report import Report
from evidently.metrics import DataDriftPreset
LATEST = [] # circular buffer; in prod send to Redis, Kafka, etc.
DRIFT_THRESHOLD = 0.6 # Evidently returns drift share [0,1]
def add_record(features: list):
LATEST.append(features)
if len(LATEST) > 1000:
LATEST.pop(0)
async def drift_watcher():
while True:
await asyncio.sleep(600) # 10 minutes
if len(LATEST) < 200: # wait for enough data
continue
current = pd.DataFrame(LATEST,
columns=["sepal_len","sepal_wid","petal_len","petal_wid"])
reference = pd.read_parquet("reference.parquet") # baseline
report = Report(metrics=[DataDriftPreset()])
report.run(reference_data=reference, current_data=current)
drift_share = report.as_dict()["metrics"][0]["result"]["dataset_drift"]
if drift_share > DRIFT_THRESHOLD:
logging.warning(f"⚠️ Drift detected! Share={drift_share:.2f}")Integrate with app.py:
python
from fastapi import BackgroundTasks
@app.post("/predict")
@LATENCY.time()
def predict(req: IrisRequest, background_tasks: BackgroundTasks):
...
features = data[0]
background_tasks.add_task(add_record, features)
return {"class": pred}
# start drift watcher when app starts
@app.on_event("startup")
async def startup_event():
import asyncio
asyncio.create_task(drift_watcher())Continuous Maintenance Loop
Detect: metrics & drift job raise an alert
Diagnose: notebook or dashboard pinpoints root cause
Retrain: CI pipeline kicks off with fresh data
Validate: automated tests + shadow deployment
Rollout: promote new model; old version kept for rollback
Security and Compliance in MLOps
Security and compliance are critical aspects of any production system, and machine learning operations are no exception. As ML models increasingly handle sensitive data and make decisions that impact users and businesses, programmers must ensure that their MLOps pipelines are both secure and compliant with relevant regulations.
Securing an MLOps workflow starts with data protection. This means encrypting data at rest and in transit, using secure authentication and authorization mechanisms, and ensuring that only authorized personnel can access sensitive datasets and model artifacts. Secrets such as API keys, database credentials, and cloud tokens should never be hardcoded in scripts or configuration files; instead, use secret managers provided by cloud platforms or tools like HashiCorp Vault.
Model security is another important consideration. Models can be vulnerable to adversarial attacks, data poisoning, or model theft. To mitigate these risks, restrict access to model endpoints, monitor for unusual prediction patterns, and consider techniques like input validation and adversarial training. Logging and monitoring are essential for detecting suspicious activity and responding quickly to incidents.
Compliance is especially important in regulated industries such as finance, healthcare, or any domain affected by GDPR, HIPAA, or similar frameworks. Programmers should ensure that data lineage is tracked, consent is managed, and audit trails are maintained for all data and model changes. Automated tools can help enforce compliance policies, generate reports, and alert teams to potential violations.
By integrating security and compliance into every stage of the MLOps lifecycle—from data ingestion to model deployment and monitoring—programmers help protect users, maintain trust, and avoid costly legal or reputational consequences.
Real-World Challenges and How to Overcome Them
While MLOps offers powerful tools and practices for managing machine learning in production, real-world implementations often come with significant challenges. Programmers entering the MLOps space should be prepared to address these obstacles with practical solutions and a collaborative mindset.
One common challenge is dealing with data quality and consistency. In production, data can be messy, incomplete, or change in unexpected ways. Automated data validation checks, robust preprocessing pipelines, and clear data contracts between teams can help catch issues early and prevent downstream failures.
Another challenge is managing the complexity of ML pipelines. As projects grow, pipelines can become difficult to maintain, debug, and scale. Modular design, clear documentation, and the use of workflow orchestration tools like Airflow or Kubeflow Pipelines can make pipelines more manageable and resilient.
Model drift and performance degradation are ongoing concerns. Even the best models can become outdated as data distributions shift. Regular monitoring, automated retraining, and alerting systems are essential for keeping models accurate and reliable over time.
Collaboration between data scientists, engineers, and operations teams can also be a hurdle, especially when teams use different tools or have different priorities. Adopting shared standards, using collaborative platforms, and fostering a culture of open communication can bridge these gaps.
Finally, resource constraints—such as limited compute, storage, or budget—can impact the ability to scale and automate MLOps processes. Cloud platforms, efficient resource management, and prioritizing automation for the most critical workflows can help teams do more with less.
By anticipating these challenges and applying best practices, programmers can help their organizations build robust, scalable, and maintainable MLOps systems that deliver real business value.

Essential Tools and Frameworks for Programmers
The MLOps ecosystem is rich with tools and frameworks designed to streamline every stage of the machine learning lifecycle. For programmers, choosing the right set of tools can make the difference between a fragile, manual process and a robust, automated pipeline.
For version control, Git remains the foundation, but tools like DVC (Data Version Control) and MLflow extend these capabilities to datasets and model artifacts. DVC allows you to track large files and data dependencies alongside your code, while MLflow provides experiment tracking, model registry, and reproducibility features.
When it comes to workflow automation, Apache Airflow and Prefect are popular choices for orchestrating complex data and ML pipelines. For teams working with Kubernetes, Kubeflow Pipelines offers native integration with containerized environments and supports scalable, reproducible workflows.
Containerization is a best practice for deploying ML models, and Docker is the industry standard. It enables you to package your code, dependencies, and models into portable containers that can run anywhere. For managing containers at scale, Kubernetes is widely used in production environments.
For model deployment, FastAPI and Flask are lightweight frameworks for building RESTful APIs, while TensorFlow Serving and TorchServe provide specialized solutions for serving deep learning models. Cloud platforms like AWS SageMaker, Google Vertex AI, and Azure Machine Learning offer end-to-end MLOps services, including training, deployment, monitoring, and scaling.
Monitoring and observability are crucial for production systems. Prometheus and Grafana are commonly used for collecting and visualizing operational metrics, while tools like Evidently AI and WhyLabs focus on monitoring data and model quality.
By mastering these tools and frameworks, programmers can build efficient, scalable, and maintainable MLOps pipelines that support the entire machine learning lifecycle—from development to deployment and beyond.
Future Directions: How MLOps is Shaping Software Development
MLOps is rapidly transforming the landscape of software development, blurring the lines between traditional engineering, data science, and operations. As organizations increasingly rely on AI-driven solutions, the principles and practices of MLOps are becoming integral to how software is built, deployed, and maintained.
One major trend is the growing automation of the entire ML lifecycle. Automated data validation, model retraining, and deployment pipelines are reducing manual effort and enabling faster, more reliable releases. This shift allows programmers to focus on higher-level problem solving and innovation, rather than repetitive tasks.
Another key direction is the integration of monitoring, explainability, and fairness into MLOps workflows. As models are deployed in critical applications, there is a greater emphasis on transparency, accountability, and compliance. Tools that provide real-time insights into model behavior, detect bias, and ensure regulatory compliance are becoming standard components of the MLOps toolkit.
Collaboration is also evolving. MLOps encourages cross-functional teams, where programmers, data scientists, and operations specialists work together using shared platforms and standards. This collaborative approach accelerates development, improves model quality, and ensures that AI solutions align with business goals.
Finally, the rise of low-code and no-code MLOps platforms is democratizing access to machine learning, enabling a broader range of professionals to contribute to AI projects. As these platforms mature, programmers will play a crucial role in extending, customizing, and integrating them into existing systems.
In summary, MLOps is not just a set of tools or practices—it represents a cultural and technological shift in how intelligent software is created and maintained. Programmers who embrace MLOps will be at the forefront of this transformation, driving the next generation of AI-powered applications and shaping the future of software development.
MLOps in the Era of Generative Artificial Intelligence: New Challenges and Opportunities
MLOps in Practice – How to Automate the Machine Learning Model Lifecycle