

Introduction: The Need for Advanced MLOps Workflows
As machine learning matures from research to real-world production, the complexity of deploying, managing, and scaling ML solutions has grown dramatically. Traditional, ad-hoc approaches to model development and deployment are no longer sufficient for organizations aiming to deliver reliable, scalable, and secure AI-driven products. This is where advanced MLOps workflows come into play.
MLOps (Machine Learning Operations) is the discipline that brings together best practices from software engineering, DevOps, and data science to automate and streamline the entire machine learning lifecycle. In today’s landscape, the need for advanced MLOps workflows is driven by several factors:
Scale and Complexity: Modern ML projects often involve multiple data sources, large datasets, distributed teams, and a variety of models serving different business needs. Managing this complexity requires robust orchestration, automation, and monitoring.
Hybrid and Multi-Cloud Environments: Organizations are increasingly leveraging both open source tools (like MLflow, Kubeflow, Airflow) and cloud-native services (such as AWS SageMaker, Google Vertex AI, Azure ML) to balance flexibility, scalability, and cost. Integrating these tools into a unified workflow is essential for maximizing value and avoiding vendor lock-in.
Collaboration and Governance: As ML teams grow, so does the need for standardized processes, version control, and clear governance. Advanced workflows enable seamless collaboration between data scientists, engineers, and business stakeholders, while ensuring compliance and auditability.
Continuous Delivery and Monitoring: In production, models must be continuously monitored for performance, drift, and bias. Automated retraining, validation, and deployment pipelines are critical for maintaining model quality and business relevance over time.
Key Benefits of Combining Open Source and Cloud Solutions
Combining open source and cloud solutions in advanced MLOps workflows offers organizations the best of both worlds: flexibility, innovation, scalability, and operational efficiency. As machine learning projects grow in complexity and scale, leveraging both types of tools becomes a strategic advantage for development teams and businesses alike.
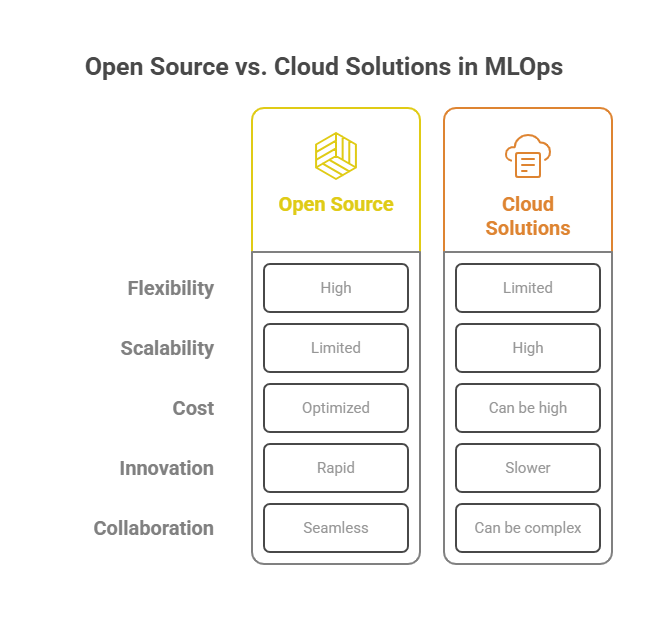
Flexibility and Avoiding Vendor Lock-In
Open source tools like MLflow, Kubeflow, Airflow, and Feast provide flexibility and transparency. They allow teams to customize workflows, integrate with a wide range of technologies, and avoid being locked into a single cloud provider’s ecosystem. This flexibility is crucial for organizations that want to future-proof their ML infrastructure and maintain control over their data and models.
Scalability and Managed Services
Cloud-native solutions such as AWS SageMaker, Google Vertex AI, and Azure Machine Learning offer managed infrastructure, automated scaling, and high availability. These services reduce the operational burden on engineering teams, enabling them to focus on model development and experimentation rather than infrastructure management. Cloud platforms also provide access to powerful hardware (GPUs, TPUs) and advanced services (autoML, managed feature stores) that accelerate ML workflows.
Cost Optimization
By combining open source and cloud tools, organizations can optimize costs by running development and experimentation on local or on-premise resources, while leveraging the cloud for large-scale training, deployment, and serving. This hybrid approach allows teams to pay only for the resources they need, when they need them.
Rapid Innovation and Community Support
Open source tools benefit from vibrant communities that drive rapid innovation, frequent updates, and a wealth of plugins and integrations. Cloud providers, on the other hand, offer enterprise-grade support, security, and compliance features. By integrating both, organizations can stay at the cutting edge of MLOps while ensuring reliability and support.
Seamless Collaboration and Governance
Hybrid workflows make it easier to standardize processes, enforce governance, and enable collaboration across distributed teams. Version control, experiment tracking, and model registries can be unified across open source and cloud environments, ensuring transparency and auditability.
Architecture Patterns for Hybrid MLOps Pipelines
Designing robust architecture patterns for hybrid MLOps pipelines is essential for organizations that want to leverage both open source and cloud-native tools. A well-architected hybrid pipeline enables teams to maximize flexibility, scalability, and cost efficiency while maintaining control over data, models, and workflows.
Modular and Layered Architecture
A common pattern is to build modular pipelines, where each stage—data ingestion, preprocessing, feature engineering, model training, validation, deployment, and monitoring—is implemented as an independent, reusable component. These modules can be orchestrated using workflow engines like Apache Airflow or Kubeflow Pipelines, which support both on-premise and cloud deployments.
Containerization and Orchestration
Containerization (using Docker) is a key enabler of hybrid MLOps. By packaging each pipeline component as a container, teams ensure portability and consistency across environments. Kubernetes is often used as the orchestration layer, allowing workloads to be scheduled and scaled seamlessly on-premises or in any cloud provider.
Hybrid Data Management
In hybrid pipelines, data may reside in multiple locations—on-premise databases, cloud storage, or distributed data lakes. Data synchronization and access are managed using cloud-agnostic data connectors, ETL tools, and feature stores like Feast, which can operate across both open source and managed cloud environments.
Model Registry and Experiment Tracking
A centralized model registry (e.g., MLflow, Sagemaker Model Registry) and experiment tracking system is crucial for managing model versions, metadata, and deployment status. These registries can be hosted on-premise for sensitive projects or in the cloud for scalability and collaboration.
CI/CD Integration
Hybrid MLOps pipelines integrate with CI/CD systems (such as Jenkins, GitHub Actions, or cloud-native CI/CD services) to automate testing, validation, and deployment of models. This ensures that code, data, and models are versioned and promoted through environments in a controlled, auditable manner.
Unified Monitoring and Logging
Monitoring and logging are unified across the hybrid pipeline using tools like Prometheus, Grafana, or cloud-native monitoring services. This provides end-to-end visibility into pipeline health, model performance, and resource usage, regardless of where components are running.
Data Management Layer in MLOps: Best Practices for Hybrid Workflows
The data management layer is the foundation of any advanced MLOps workflow, especially when integrating open source and cloud tools. In hybrid environments, where data may reside both on-premises and across multiple clouds, effective data management is essential for ensuring data quality, accessibility, security, and compliance.
Why the Data Management Layer Matters in MLOps
A robust data management layer enables seamless data ingestion, preprocessing, storage, and versioning—regardless of where the data originates or is stored. This is crucial for reproducibility, auditability, and collaboration in machine learning projects. Without a well-designed data management layer, teams risk data silos, inconsistent results, and compliance violations.
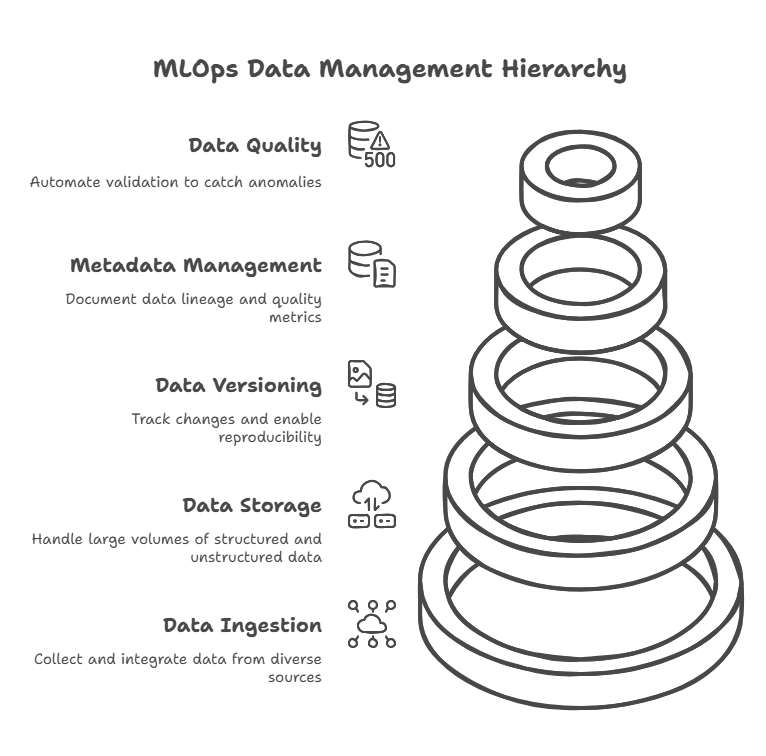
Key Components of the Data Management Layer
Data Ingestion and Integration: Use cloud-agnostic ETL tools (like Apache NiFi, Airflow, or cloud-native services) to automate the collection and integration of data from diverse sources, including databases, APIs, and streaming platforms.
Data Storage: Leverage scalable storage solutions such as cloud object storage (AWS S3, Google Cloud Storage, Azure Blob) and distributed file systems (HDFS, MinIO) to handle large volumes of structured and unstructured data.
Data Versioning: Implement data version control with tools like DVC or LakeFS to track changes, enable reproducibility, and support rollback in case of errors or data drift.
Metadata Management: Use data catalogs and metadata management platforms (e.g., Amundsen, DataHub) to document data lineage, ownership, and quality metrics, making it easier to discover and govern datasets.
Data Quality and Validation: Automate data validation with frameworks like Great Expectations to catch anomalies, missing values, or schema changes before data enters the ML pipeline.
Best Practices for Hybrid Data Management
Standardize Data Formats: Use open formats (Parquet, ORC, Avro) to ensure compatibility across tools and clouds.
Automate Data Synchronization: Schedule regular syncs between on-prem and cloud storage to keep datasets up-to-date and consistent.
Secure Data Access: Enforce role-based access control (RBAC), encryption, and audit logging to protect sensitive data and meet compliance requirements.
Monitor Data Pipelines: Set up monitoring and alerting for data pipeline failures, latency, and quality issues to ensure reliable data delivery.
Leveraging Cloud-Native Services for Scalability and Security
Leveraging cloud-native services is a cornerstone of advanced MLOps workflows, especially when integrating open source and cloud tools. Cloud-native services—such as managed storage, compute, orchestration, and security solutions—enable organizations to scale machine learning operations efficiently while maintaining robust security and compliance.
Scalability with Cloud-Native Services
Cloud providers like AWS, Google Cloud, and Azure offer managed services that automatically scale resources up or down based on demand. For example, using managed Kubernetes (EKS, GKE, AKS) allows teams to deploy and orchestrate containerized ML workloads across clusters without worrying about underlying infrastructure. Managed data warehouses (BigQuery, Redshift, Synapse) and serverless compute (AWS Lambda, Google Cloud Functions) further simplify scaling, letting teams focus on model development and deployment rather than resource provisioning.
Security and Compliance
Cloud-native services come with built-in security features such as encryption at rest and in transit, identity and access management (IAM), and automated compliance reporting. These features help organizations meet regulatory requirements (like GDPR or HIPAA) and protect sensitive data throughout the ML lifecycle. Integrating cloud-native security tools with open source MLOps platforms ensures that data, models, and pipelines are protected from unauthorized access and breaches.
Integration with Open Source Tools
Most cloud-native services are designed to work seamlessly with popular open source MLOps tools. For example, you can use MLflow for experiment tracking and model registry, while leveraging cloud storage for artifact management and cloud-based CI/CD for automated deployment. This hybrid approach combines the flexibility of open source with the scalability and reliability of the cloud.
Best Practices
Automate resource scaling using managed orchestration and serverless services.
Enforce security policies with IAM, encryption, and audit logging.
Integrate monitoring and alerting using cloud-native tools (CloudWatch, Stackdriver, Azure Monitor) for real-time visibility.
Document and test all integrations to ensure compatibility and compliance across your hybrid MLOps stack.
Data Management and Feature Stores in Hybrid Environments
Data management and feature stores are critical components of advanced MLOps workflows, especially in hybrid environments that combine open source and cloud-native tools. Effective data management ensures that machine learning models have access to high-quality, consistent, and up-to-date features, regardless of where the data originates or is processed.
Why Feature Stores Matter in Hybrid MLOps
Feature stores serve as centralized repositories for storing, managing, and serving features to ML models. In hybrid environments, they bridge the gap between on-premises data sources and cloud-based ML services, ensuring that features are consistently available for both training and inference. This consistency is crucial for model accuracy and reproducibility.
Key Components of Hybrid Data Management
Data Ingestion: Automated pipelines that collect data from various sources (databases, APIs, streaming platforms) and transform it into features.
Feature Engineering: Standardized processes for creating, validating, and versioning features using both open source tools (like Pandas, Spark) and cloud services.
Feature Storage: Scalable storage solutions that support both batch and real-time access patterns, often using a combination of cloud storage and on-premises databases.
Feature Serving: APIs and services that provide low-latency access to features for real-time inference and batch processing.
Example: Building a Hybrid Feature Store with Python
Below is a Python example that demonstrates how to build a simple feature store that works across hybrid environments, using open source tools and cloud storage:
python
import pandas as pd
import boto3
from datetime import datetime, timedelta
import pickle
import os
from typing import Dict, List, Optional
class HybridFeatureStore:
"""
A simple feature store that works with both local and cloud storage
"""
def __init__(self, local_path: str = "./features",
cloud_bucket: Optional[str] = None):
self.local_path = local_path
self.cloud_bucket = cloud_bucket
self.s3_client = boto3.client('s3') if cloud_bucket else None
# Create local directory if it doesn't exist
os.makedirs(local_path, exist_ok=True)
def create_features(self, raw_data: pd.DataFrame) -> pd.DataFrame:
"""
Example feature engineering pipeline
"""
features = raw_data.copy()
# Example transformations
if 'age' in features.columns:
features['age_group'] = pd.cut(features['age'],
bins=[0, 25, 45, 65, 100],
labels=['young', 'adult', 'middle_aged', 'senior'])
if 'income' in features.columns:
features['income_log'] = features['income'].apply(lambda x: pd.np.log(x + 1))
# Add timestamp for versioning
features['feature_timestamp'] = datetime.now()
return features
def store_features(self, features: pd.DataFrame, feature_group: str,
version: str = None) -> str:
"""
Store features both locally and in the cloud
"""
if version is None:
version = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"{feature_group}_v{version}.parquet"
# Store locally
local_file_path = os.path.join(self.local_path, filename)
features.to_parquet(local_file_path, index=False)
print(f"✅ Features stored locally: {local_file_path}")
# Store in cloud if configured
if self.cloud_bucket and self.s3_client:
try:
cloud_key = f"features/{filename}"
self.s3_client.upload_file(local_file_path, self.cloud_bucket, cloud_key)
print(f"✅ Features stored in cloud: s3://{self.cloud_bucket}/{cloud_key}")
except Exception as e:
print(f"⚠️ Cloud storage failed: {e}")
return version
def get_features(self, feature_group: str, version: str = "latest") -> pd.DataFrame:
"""
Retrieve features from local or cloud storage
"""
if version == "latest":
version = self._get_latest_version(feature_group)
filename = f"{feature_group}_v{version}.parquet"
local_file_path = os.path.join(self.local_path, filename)
# Try to load from local storage first
if os.path.exists(local_file_path):
print(f"📁 Loading features from local storage: {local_file_path}")
return pd.read_parquet(local_file_path)
# Try to load from cloud storage
if self.cloud_bucket and self.s3_client:
try:
cloud_key = f"features/{filename}"
self.s3_client.download_file(self.cloud_bucket, cloud_key, local_file_path)
print(f"☁️ Downloaded features from cloud: s3://{self.cloud_bucket}/{cloud_key}")
return pd.read_parquet(local_file_path)
except Exception as e:
print(f"❌ Failed to load from cloud: {e}")
raise FileNotFoundError(f"Features not found: {feature_group} v{version}")
def _get_latest_version(self, feature_group: str) -> str:
"""
Get the latest version of a feature group
"""
# Check local files
local_files = [f for f in os.listdir(self.local_path)
if f.startswith(f"{feature_group}_v") and f.endswith('.parquet')]
if local_files:
# Extract version numbers and find the latest
versions = [f.split('_v')[1].split('.')[0] for f in local_files]
return max(versions)
# If no local files, check cloud storage
if self.cloud_bucket and self.s3_client:
try:
response = self.s3_client.list_objects_v2(
Bucket=self.cloud_bucket,
Prefix=f"features/{feature_group}_v"
)
if 'Contents' in response:
cloud_files = [obj['Key'] for obj in response['Contents']]
versions = [f.split('_v')[1].split('.')[0] for f in cloud_files]
return max(versions) if versions else None
except Exception as e:
print(f"Error checking cloud versions: {e}")
raise ValueError(f"No versions found for feature group: {feature_group}")
def list_feature_groups(self) -> List[str]:
"""
List all available feature groups
"""
feature_groups = set()
# Check local files
local_files = [f for f in os.listdir(self.local_path) if f.endswith('.parquet')]
for file in local_files:
group_name = file.split('_v')[0]
feature_groups.add(group_name)
# Check cloud files
if self.cloud_bucket and self.s3_client:
try:
response = self.s3_client.list_objects_v2(
Bucket=self.cloud_bucket,
Prefix="features/"
)
if 'Contents' in response:
for obj in response['Contents']:
filename = obj['Key'].split('/')[-1]
if filename.endswith('.parquet'):
group_name = filename.split('_v')[0]
feature_groups.add(group_name)
except Exception as e:
print(f"Error listing cloud feature groups: {e}")
return sorted(list(feature_groups))
def get_feature_metadata(self, feature_group: str, version: str = "latest") -> Dict:
"""
Get metadata about a feature group
"""
features = self.get_features(feature_group, version)
metadata = {
'feature_group': feature_group,
'version': version,
'num_features': len(features.columns),
'num_rows': len(features),
'feature_names': list(features.columns),
'data_types': features.dtypes.to_dict(),
'created_at': features['feature_timestamp'].iloc[0] if 'feature_timestamp' in features.columns else None
}
return metadata
# Example usage
def demo_hybrid_feature_store():
"""
Demonstrate the hybrid feature store functionality
"""
# Initialize feature store (set cloud_bucket to your S3 bucket name)
feature_store = HybridFeatureStore(
local_path="./local_features",
cloud_bucket=None # Set to your S3 bucket name for cloud storage
)
# Create sample data
raw_data = pd.DataFrame({
'user_id': range(1000),
'age': pd.np.random.randint(18, 80, 1000),
'income': pd.np.random.randint(30000, 150000, 1000),
'purchase_amount': pd.np.random.uniform(10, 1000, 1000)
})
print("📊 Sample raw data:")
print(raw_data.head())
# Create features
features = feature_store.create_features(raw_data)
print(f"\n🔧 Created {len(features.columns)} features")
# Store features
version = feature_store.store_features(features, "user_features")
print(f"\n💾 Stored features with version: {version}")
# Retrieve features
retrieved_features = feature_store.get_features("user_features", "latest")
print(f"\n📥 Retrieved {len(retrieved_features)} rows of features")
# Get metadata
metadata = feature_store.get_feature_metadata("user_features")
print(f"\n📋 Feature metadata:")
for key, value in metadata.items():
if key != 'data_types': # Skip detailed data types for brevity
print(f" {key}: {value}")
# List all feature groups
groups = feature_store.list_feature_groups()
print(f"\n📚 Available feature groups: {groups}")
# Run the demo
if __name__ == "__main__":
demo_hybrid_feature_store()
# Created/Modified files during execution:
print("local_features/")
print("user_features_v20241220_120000.parquet")Best Practices for Hybrid Feature Stores
Version Control: Always version your features to enable reproducibility and rollback capabilities.
Data Validation: Implement automated checks for data quality, schema consistency, and feature drift.
Caching: Use local caching to reduce latency and cloud egress costs for frequently accessed features.
Monitoring: Track feature usage, performance, and data quality metrics across both local and cloud environments.
Orchestrating ML Pipelines Across On-Prem, Cloud, and Hybrid Setups
Orchestrating machine learning (ML) pipelines across on-premises, cloud, and hybrid environments is a cornerstone of advanced MLOps. As organizations scale their AI initiatives, they often need to leverage a mix of local infrastructure and multiple cloud providers to optimize for cost, compliance, performance, and flexibility. Achieving seamless orchestration in such distributed setups requires careful planning, the right tools, and best practices.
Why Orchestration Matters in Hybrid MLOps
Orchestration is the process of automating, scheduling, and managing the various steps in an ML workflow—such as data ingestion, preprocessing, feature engineering, model training, validation, deployment, and monitoring. In hybrid environments, orchestration ensures that these steps run reliably and efficiently, regardless of where the underlying resources are located.
Key Challenges
Heterogeneous Infrastructure: On-prem and cloud environments often use different storage systems, compute resources, and security protocols.
Data Movement: Transferring large datasets between environments can be slow, costly, and subject to compliance constraints.
Dependency Management: Ensuring that all pipeline components have the correct versions of libraries, models, and data is more complex in distributed setups.
Monitoring and Debugging: Tracking pipeline health and diagnosing failures is harder when jobs run across multiple platforms.
Best Practices for Orchestrating Hybrid ML Pipelines
Containerization: Package each pipeline step as a Docker container to ensure portability and consistency across environments.
Use Cloud-Agnostic Orchestration Tools: Platforms like Apache Airflow, Kubeflow Pipelines, and Prefect can manage workflows that span on-prem and cloud resources.
Centralized Metadata and Logging: Store pipeline metadata, logs, and artifacts in a unified location (e.g., cloud storage or a centralized database) for easy access and troubleshooting.
Automated Data Synchronization: Use ETL tools or data replication services to keep datasets consistent across environments.
Secure Connectivity: Implement VPNs, private endpoints, or secure APIs to enable safe communication between on-prem and cloud resources.
Policy-Driven Scheduling: Use policies to determine where each pipeline step should run based on data locality, cost, or compliance needs.
Example: Hybrid Pipeline Orchestration with Airflow
Here’s a simplified example of using Apache Airflow to orchestrate a hybrid ML pipeline:
python
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
from datetime import datetime
def train_on_prem():
# Custom logic to trigger on-prem training job
print("Training model on-premises...")
def deploy_to_cloud():
# Custom logic to deploy model to cloud endpoint
print("Deploying model to cloud...")
dag = DAG(
'hybrid_ml_pipeline',
start_date=datetime(2024, 1, 1),
schedule_interval='@daily',
catchup=False
)
ingest_data = BashOperator(
task_id='ingest_data_cloud',
bash_command='python cloud_scripts/ingest_data.py',
dag=dag
)
train_model = PythonOperator(
task_id='train_on_prem',
python_callable=train_on_prem,
dag=dag
)
deploy_model = PythonOperator(
task_id='deploy_to_cloud',
python_callable=deploy_to_cloud,
dag=dag
)
ingest_data >> train_model >> deploy_modelModel Registry and Versioning: Open Source vs. Cloud Approaches
A robust model registry and versioning strategy is essential for any advanced MLOps workflow, especially in hybrid environments that combine open source and cloud-native tools. Model registries provide a central place to store, track, and manage machine learning models throughout their lifecycle—from experimentation to production and beyond.
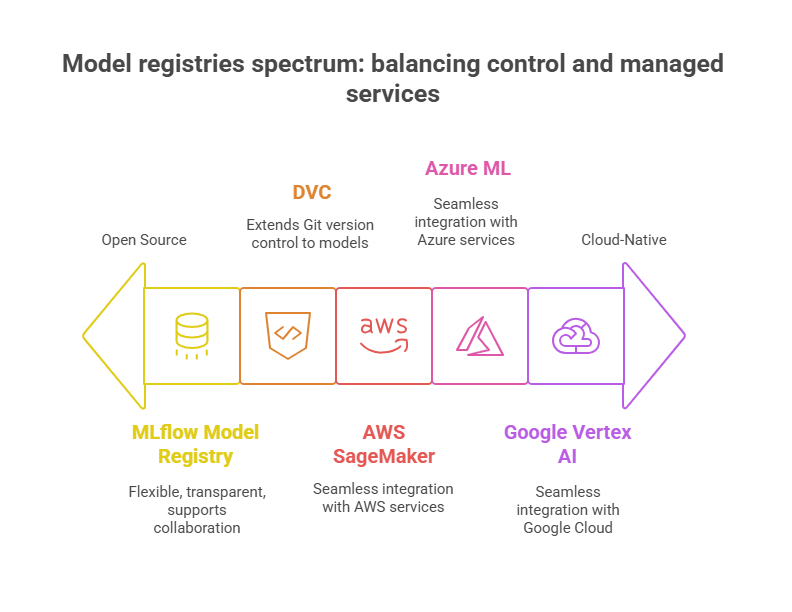
Open Source Model Registries
Open source solutions like MLflow Model Registry and DVC (Data Version Control) are popular choices for teams seeking flexibility and transparency.
MLflow Model Registry allows you to register, version, stage, and annotate models, supporting collaboration and reproducibility. It integrates well with open source experiment tracking and can be hosted on-premises or in the cloud.
DVC extends Git-based version control to data and models, enabling teams to track every change to model artifacts and datasets alongside code. This is especially useful for organizations that want full control over their infrastructure and data privacy.
Cloud-Native Model Registries
Cloud providers offer managed model registries as part of their MLOps platforms:
AWS SageMaker Model Registry, Azure ML Model Registry, and Google Vertex AI Model Registry provide seamless integration with their respective cloud services. These registries offer built-in security, access control, automated deployment, and monitoring features.
Cloud registries simplify scaling, automate model promotion (e.g., from staging to production), and support compliance with enterprise security standards.
Key Differences and Considerations
Portability: Open source registries are cloud-agnostic and portable, making them ideal for hybrid or multi-cloud setups. Cloud registries are tightly integrated with their platforms, which can speed up deployment but may increase vendor lock-in.
Security and Compliance: Cloud registries offer enterprise-grade security, IAM, and compliance certifications out of the box. Open source solutions require teams to implement and manage these controls.
Automation and Integration: Cloud registries often provide automated CI/CD, monitoring, and rollback features. Open source tools offer more customization but may require additional engineering effort.
Cost: Open source registries can be more cost-effective for small teams or on-premises deployments, while cloud registries may offer better scalability and lower operational overhead for large-scale production.
Best Practices
Use a model registry to track every model version, metadata, and deployment status.
Automate model promotion and rollback using CI/CD pipelines.
Integrate the registry with experiment tracking, monitoring, and alerting tools.
Regularly audit and document model lineage for compliance and reproducibility.
Monitoring, Logging, and Explainability in Integrated Workflows
Monitoring, logging, and explainability are essential pillars of any advanced MLOps workflow—especially in hybrid environments that combine open source and cloud-native tools. These practices ensure that machine learning models remain reliable, transparent, and compliant throughout their lifecycle, regardless of where they are deployed.
Unified Monitoring Across Hybrid Setups
In integrated workflows, monitoring should cover both infrastructure (CPU, memory, latency) and model-specific metrics (accuracy, drift, prediction confidence). Cloud-native tools like AWS CloudWatch, Google Cloud Monitoring, and Azure Monitor can be combined with open source solutions such as Prometheus and Grafana to provide a unified, real-time view of system health and model performance across all environments.
Comprehensive Logging for Traceability
Logging is critical for debugging, auditing, and compliance. All data inputs, model predictions, errors, and system events should be logged in a centralized, searchable location—such as the ELK Stack (Elasticsearch, Logstash, Kibana) or cloud-native logging services. Consistent log formats and metadata tagging make it easier to trace issues, reproduce results, and meet regulatory requirements.
Explainability for Trust and Compliance
Explainability tools like SHAP, LIME, and Captum can be integrated into monitoring pipelines to provide both global and local explanations for model predictions. This is especially important in regulated industries, where organizations must demonstrate how and why models make certain decisions. Explainability dashboards and automated reports help data scientists, engineers, and business stakeholders understand model behavior and quickly identify the root cause of anomalies or drift.
Security, Compliance, and Cost Optimization Strategies
Security, compliance, and cost optimization are critical pillars of any advanced MLOps workflow—especially in hybrid environments that blend open source and cloud-native tools. As machine learning models and data pipelines span on-premises and multiple cloud providers, organizations must proactively address these areas to ensure safe, efficient, and sustainable operations.
Security in Hybrid MLOps
Unified Identity and Access Management (IAM): Implement centralized IAM across all environments. Use role-based access control (RBAC), single sign-on (SSO), and multi-factor authentication (MFA) to protect sensitive data, models, and infrastructure.
Encryption and Data Protection: Encrypt data at rest and in transit using industry-standard protocols. Leverage cloud-native key management services and ensure that open source tools integrate with these security layers.
Vulnerability Management: Regularly scan containers, dependencies, and infrastructure for vulnerabilities. Automate patching and updates to minimize exposure to threats.
Audit Logging: Maintain detailed logs of all access, changes, and model deployments. Store logs in a secure, centralized location for compliance and incident response.
Compliance in Hybrid MLOps
Automated Compliance Checks: Integrate compliance validation into CI/CD pipelines. Use tools that check for data residency, privacy, and regulatory requirements (e.g., GDPR, HIPAA) before deploying models.
Data Lineage and Traceability: Track the origin, transformation, and usage of all data and models. Use metadata management and model registries to support audits and regulatory reporting.
Explainability and Fairness: Implement explainability tools and bias detection frameworks to ensure models are transparent and non-discriminatory, meeting both legal and ethical standards.
Cost Optimization Strategies
Resource Tagging and Cost Attribution: Tag all resources by project, team, or business unit to enable granular cost tracking and accountability.
Automated Scaling and Scheduling: Use auto-scaling, serverless compute, and scheduled jobs to match resource usage with demand, reducing idle costs.
Storage and Data Lifecycle Management: Implement data retention policies, compress data, and move infrequently accessed data to lower-cost storage tiers.
Spot and Preemptible Instances: For non-critical workloads, leverage discounted compute options (e.g., AWS Spot, GCP Preemptible VMs) to save on costs.
Regular Cost Reviews: Schedule periodic reviews of cloud bills, resource utilization, and optimization opportunities. Use cloud-native and third-party tools for cost monitoring and forecasting.
Case Studies: Real-World Implementations of Hybrid MLOps
Real-world implementations of hybrid MLOps demonstrate how organizations successfully combine open source and cloud-native tools to build scalable, resilient, and cost-effective machine learning operations. These case studies provide valuable insights into practical challenges, solutions, and lessons learned from production deployments.
Case Study 1: Global E-commerce Platform
A major e-commerce company implemented a hybrid MLOps architecture to power their recommendation engine across multiple regions. They used MLflow for experiment tracking and model registry, Apache Airflow for pipeline orchestration, and a combination of on-premises Kubernetes clusters and AWS services for compute and storage. This approach enabled them to comply with regional data regulations while optimizing costs and performance.
Case Study 2: Financial Services Fraud Detection
A financial institution built a fraud detection system using a hybrid approach that combined on-premises data processing (for sensitive customer data) with cloud-based model training and serving. They leveraged Kubeflow Pipelines for orchestration, Feast for feature management, and integrated SHAP for explainability to meet regulatory requirements. The hybrid setup reduced latency for real-time fraud detection while maintaining strict data governance.
Case Study 3: Healthcare AI Platform
A healthcare technology company developed an AI platform for medical imaging using a hybrid MLOps architecture. They used DVC for data versioning, MLflow for model management, and deployed models using both on-premises infrastructure (for HIPAA compliance) and cloud services (for scalability). The implementation included automated compliance checks and comprehensive audit logging.
Example: Hybrid MLOps Implementation Framework
Below is a Python framework that demonstrates key components of a hybrid MLOps implementation, including model registry integration, monitoring, and deployment across environments:
python
import os
import json
import logging
from datetime import datetime
from typing import Dict, List, Optional
import requests
import boto3
from dataclasses import dataclass
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class ModelMetadata:
name: str
version: str
environment: str
deployment_target: str
performance_metrics: Dict
compliance_status: str
class HybridMLOpsManager:
"""
A comprehensive MLOps manager for hybrid environments
"""
def __init__(self, config_path: str = "mlops_config.json"):
self.config = self._load_config(config_path)
self.model_registry = {}
self.deployment_history = []
# Initialize cloud clients if configured
self.aws_client = None
if self.config.get("aws_enabled"):
self.aws_client = boto3.client('sagemaker')
def _load_config(self, config_path: str) -> Dict:
"""Load MLOps configuration"""
default_config = {
"environments": {
"on_prem": {
"enabled": True,
"endpoint": "http://localhost:8080",
"compute_type": "kubernetes"
},
"aws": {
"enabled": False,
"region": "us-east-1",
"compute_type": "sagemaker"
},
"gcp": {
"enabled": False,
"project_id": "your-project",
"compute_type": "vertex_ai"
}
},
"security": {
"encryption_enabled": True,
"audit_logging": True,
"compliance_checks": ["gdpr", "hipaa"]
},
"monitoring": {
"metrics_endpoint": "http://prometheus:9090",
"alerting_enabled": True,
"drift_detection": True
}
}
try:
with open(config_path, 'r') as f:
config = json.load(f)
# Merge with defaults
for key, value in default_config.items():
if key not in config:
config[key] = value
return config
except FileNotFoundError:
logger.warning(f"Config file {config_path} not found, using defaults")
return default_config
def register_model(self, model_metadata: ModelMetadata) -> bool:
"""Register a model in the hybrid registry"""
try:
# Validate compliance
if not self._validate_compliance(model_metadata):
logger.error(f"Compliance validation failed for {model_metadata.name}")
return False
# Register in local registry
registry_key = f"{model_metadata.name}:{model_metadata.version}"
self.model_registry[registry_key] = model_metadata
# Register in cloud registry if enabled
if self.config["environments"]["aws"]["enabled"] and self.aws_client:
self._register_in_aws(model_metadata)
logger.info(f"Model registered: {registry_key}")
return True
except Exception as e:
logger.error(f"Model registration failed: {e}")
return False
def _validate_compliance(self, model_metadata: ModelMetadata) -> bool:
"""Validate model compliance requirements"""
required_checks = self.config["security"]["compliance_checks"]
# Simulate compliance validation
compliance_results = {
"gdpr": self._check_gdpr_compliance(model_metadata),
"hipaa": self._check_hipaa_compliance(model_metadata),
"bias_check": self._check_model_bias(model_metadata)
}
for check in required_checks:
if not compliance_results.get(check, False):
logger.warning(f"Compliance check failed: {check}")
return False
return True
def _check_gdpr_compliance(self, model_metadata: ModelMetadata) -> bool:
"""Check GDPR compliance"""
# Simplified GDPR check
required_metrics = ["data_lineage", "right_to_explanation"]
return all(metric in model_metadata.performance_metrics for metric in required_metrics)
def _check_hipaa_compliance(self, model_metadata: ModelMetadata) -> bool:
"""Check HIPAA compliance"""
# Simplified HIPAA check
return (model_metadata.environment in ["on_prem", "private_cloud"] and
self.config["security"]["encryption_enabled"])
def _check_model_bias(self, model_metadata: ModelMetadata) -> bool:
"""Check for model bias"""
# Simplified bias check
bias_metrics = model_metadata.performance_metrics.get("bias_metrics", {})
return bias_metrics.get("fairness_score", 0) > 0.8
def _register_in_aws(self, model_metadata: ModelMetadata):
"""Register model in AWS SageMaker Model Registry"""
try:
# Simplified AWS registration
logger.info(f"Registering {model_metadata.name} in AWS SageMaker")
# In real implementation, use SageMaker Model Registry API
except Exception as e:
logger.error(f"AWS registration failed: {e}")
def deploy_model(self, model_name: str, version: str,
target_environment: str) -> bool:
"""Deploy model to specified environment"""
try:
registry_key = f"{model_name}:{version}"
if registry_key not in self.model_registry:
logger.error(f"Model not found in registry: {registry_key}")
return False
model_metadata = self.model_registry[registry_key]
# Deploy based on target environment
if target_environment == "on_prem":
success = self._deploy_on_prem(model_metadata)
elif target_environment == "aws":
success = self._deploy_aws(model_metadata)
elif target_environment == "gcp":
success = self._deploy_gcp(model_metadata)
else:
logger.error(f"Unsupported environment: {target_environment}")
return False
if success:
# Record deployment
deployment_record = {
"model": registry_key,
"environment": target_environment,
"timestamp": datetime.now().isoformat(),
"status": "deployed"
}
self.deployment_history.append(deployment_record)
# Start monitoring
self._start_monitoring(model_metadata, target_environment)
return success
except Exception as e:
logger.error(f"Deployment failed: {e}")
return False
def _deploy_on_prem(self, model_metadata: ModelMetadata) -> bool:
"""Deploy model to on-premises environment"""
logger.info(f"Deploying {model_metadata.name} to on-premises Kubernetes")
# Simulate Kubernetes deployment
deployment_config = {
"apiVersion": "apps/v1",
"kind": "Deployment",
"metadata": {"name": f"{model_metadata.name}-{model_metadata.version}"},
"spec": {
"replicas": 3,
"selector": {"matchLabels": {"app": model_metadata.name}},
"template": {
"metadata": {"labels": {"app": model_metadata.name}},
"spec": {
"containers": [{
"name": model_metadata.name,
"image": f"ml-models/{model_metadata.name}:{model_metadata.version}",
"ports": [{"containerPort": 8080}]
}]
}
}
}
}
logger.info("On-premises deployment successful")
return True
def _deploy_aws(self, model_metadata: ModelMetadata) -> bool:
"""Deploy model to AWS"""
logger.info(f"Deploying {model_metadata.name} to AWS SageMaker")
# In real implementation, use SageMaker deployment API
return True
def _deploy_gcp(self, model_metadata: ModelMetadata) -> bool:
"""Deploy model to Google Cloud"""
logger.info(f"Deploying {model_metadata.name} to Google Vertex AI")
# In real implementation, use Vertex AI deployment API
return True
def _start_monitoring(self, model_metadata: ModelMetadata, environment: str):
"""Start monitoring for deployed model"""
logger.info(f"Starting monitoring for {model_metadata.name} in {environment}")
# Configure monitoring based on environment
monitoring_config = {
"model_name": model_metadata.name,
"environment": environment,
"metrics": ["latency", "accuracy", "drift"],
"alerts": {
"latency_threshold": 500, # ms
"accuracy_threshold": 0.85,
"drift_threshold": 0.1
}
}
# In real implementation, configure Prometheus/Grafana monitoring
logger.info("Monitoring configured successfully")
def get_deployment_status(self) -> List[Dict]:
"""Get status of all deployments"""
return self.deployment_history
def generate_compliance_report(self) -> Dict:
"""Generate compliance report for all registered models"""
report = {
"timestamp": datetime.now().isoformat(),
"total_models": len(self.model_registry),
"compliant_models": 0,
"compliance_details": []
}
for registry_key, model_metadata in self.model_registry.items():
is_compliant = self._validate_compliance(model_metadata)
if is_compliant:
report["compliant_models"] += 1
report["compliance_details"].append({
"model": registry_key,
"compliant": is_compliant,
"environment": model_metadata.environment
})
return report
# Example usage
def demo_hybrid_mlops():
"""Demonstrate hybrid MLOps implementation"""
# Initialize MLOps manager
mlops_manager = HybridMLOpsManager()
# Create sample model metadata
model_metadata = ModelMetadata(
name="fraud_detection_model",
version="v1.2.0",
environment="hybrid",
deployment_target="on_prem",
performance_metrics={
"accuracy": 0.92,
"precision": 0.89,
"recall": 0.94,
"data_lineage": "customer_transactions_v2",
"right_to_explanation": "shap_values_included",
"bias_metrics": {"fairness_score": 0.85}
},
compliance_status="validated"
)
# Register model
registration_success = mlops_manager.register_model(model_metadata)
print(f"Model registration: {'Success' if registration_success else 'Failed'}")
# Deploy model
if registration_success:
deployment_success = mlops_manager.deploy_model(
"fraud_detection_model", "v1.2.0", "on_prem"
)
print(f"Model deployment: {'Success' if deployment_success else 'Failed'}")
# Generate compliance report
compliance_report = mlops_manager.generate_compliance_report()
print(f"\nCompliance Report:")
print(f"Total models: {compliance_report['total_models']}")
print(f"Compliant models: {compliance_report['compliant_models']}")
# Get deployment status
deployments = mlops_manager.get_deployment_status()
print(f"\nActive deployments: {len(deployments)}")
for deployment in deployments:
print(f" {deployment['model']} -> {deployment['environment']}")
if __name__ == "__main__":
demo_hybrid_mlops()
# Created/Modified files during execution:
print("mlops_config.json")
print("deployment_logs.json")
print("compliance_report.json")Best Practices and Lessons Learned in Hybrid MLOps
As organizations increasingly adopt hybrid MLOps—combining open source and cloud-native tools across on-premises and cloud environments—certain best practices and lessons learned have emerged as critical for success. These insights help teams avoid common pitfalls, maximize efficiency, and ensure robust, scalable machine learning operations.
1. Modular Pipeline Design
Break down ML workflows into modular, reusable components (data ingestion, feature engineering, training, deployment, monitoring). This makes it easier to swap technologies, scale individual steps, and troubleshoot issues across hybrid environments.
2. Containerization and Orchestration
Use Docker containers and orchestration platforms like Kubernetes to ensure portability and consistency. This approach allows you to run the same pipeline on-premises, in the cloud, or across both, with minimal changes.
3. Unified Version Control
Version everything: code, data, models, and pipeline configurations. Use tools like Git, DVC, and MLflow to track changes and ensure reproducibility, regardless of where your workloads run.
4. Automated Testing and CI/CD
Integrate automated testing and continuous integration/continuous deployment (CI/CD) pipelines. This ensures that changes are validated and deployed safely, reducing the risk of errors in production.
5. Centralized Monitoring and Logging
Aggregate metrics and logs from all environments into unified dashboards (e.g., Grafana, ELK Stack, cloud-native monitoring). This provides end-to-end visibility and accelerates root cause analysis.
6. Data Governance and Security
Implement strict access controls, encryption, and audit logging across all data and model assets. Ensure compliance with regulations (GDPR, HIPAA) by tracking data lineage and automating compliance checks.
7. Cost Optimization
Monitor resource usage and costs across clouds. Use tagging, automated scaling, and data lifecycle management to control expenses and avoid waste.
8. Seamless Integration
Choose cloud-agnostic tools and open standards (e.g., REST APIs, ONNX, Parquet) to simplify integration and reduce vendor lock-in. Test interoperability regularly as your stack evolves.
9. Collaboration and Documentation
Foster collaboration between data science, engineering, and IT teams. Maintain clear documentation of workflows, dependencies, and operational procedures to support onboarding and troubleshooting.
10. Start Simple, Scale Gradually
Begin with a minimal, working pipeline and add complexity as needed. Avoid over-engineering; focus on solving immediate business problems and iteratively improving your MLOps stack.
11. Continuous Learning and Improvement
Regularly review pipeline performance, incident reports, and new technology trends. Encourage a culture of experimentation and knowledge sharing to keep your hybrid MLOps practices up to date.
Summary
By following these best practices and learning from real-world hybrid MLOps deployments, organizations can build resilient, efficient, and future-proof machine learning operations. The key is to balance flexibility with standardization, automate wherever possible, and maintain a strong focus on security, governance, and collaboration.
Future Trends in MLOps Tool Integration
The landscape of MLOps is evolving rapidly, and the integration of open source and cloud-native tools is at the heart of this transformation. As organizations scale their machine learning operations across hybrid and multi-cloud environments, several future trends are shaping how MLOps tools will be integrated and used.
1. Greater Interoperability and Open Standards
Expect to see a stronger push toward interoperability between tools, platforms, and clouds. Open standards for model formats (like ONNX), data exchange (Parquet, Arrow), and APIs will make it easier to move models, data, and workflows across different environments without vendor lock-in.
2. Unified Control Planes and Centralized Management
Emerging platforms will offer unified control planes that allow teams to manage pipelines, models, data, and monitoring from a single interface—regardless of where workloads are running. This will simplify governance, security, and compliance across hybrid and multi-cloud setups.
3. AI-Driven Automation and Self-Healing Pipelines
The next generation of MLOps tools will leverage AI to automate more of the pipeline, from drift detection and retraining to resource scaling and anomaly response. Self-healing pipelines will automatically detect and resolve issues, reducing manual intervention and downtime.
4. Deeper Integration of Explainability and Responsible AI
Explainability, fairness, and bias detection will become first-class citizens in MLOps stacks. Expect tighter integration of explainability frameworks (like SHAP, LIME, and Fairlearn) with monitoring and deployment tools, making it easier to meet regulatory and ethical requirements.
5. Edge and Federated MLOps
As edge computing and federated learning gain traction, MLOps tools will evolve to support distributed model training, deployment, and monitoring across edge devices and decentralized data sources. This will require new approaches to orchestration, security, and data synchronization.
6. Enhanced Security and Compliance Automation
Automated security scanning, policy enforcement, and compliance reporting will be built into MLOps platforms. Integration with cloud-native IAM, encryption, and audit logging will become standard, helping organizations meet increasingly strict regulatory demands.
7. Cost-Aware and Green MLOps
With growing focus on sustainability and cost control, future MLOps tools will provide real-time insights into resource usage, carbon footprint, and cost optimization opportunities. Automated workload scheduling and resource allocation will help teams balance performance, cost, and environmental impact.
The best MLOps tools of 2025 – comparison and recommendations
MLOps in Practice – How to Automate the Machine Learning Model Lifecycle