

Introduction: The Importance of Advanced Model Monitoring
In today’s data-driven world, machine learning models are at the heart of many business processes, powering everything from personalized recommendations to fraud detection and automated decision-making. As organizations increasingly rely on these models in production, the importance of advanced model monitoring has never been greater.
Advanced model monitoring is about much more than just checking if a model is running or if its predictions are being generated. It’s a holistic approach that ensures models remain accurate, reliable, and fair over time, even as the data and business environment evolve. This is crucial because models that perform well during development can degrade in production due to changes in data patterns, user behavior, or external factors—a phenomenon known as model drift.
Effective monitoring allows teams to detect issues early, such as drops in prediction accuracy, unexpected changes in input data distributions, or anomalies in model outputs. By identifying these problems quickly, organizations can take corrective actions—like retraining models, updating features, or investigating data sources—before they impact business outcomes.
Moreover, advanced monitoring supports regulatory compliance and ethical standards by providing transparency into how models make decisions and ensuring they perform consistently across different user groups. This transparency is increasingly important as regulations around AI and data usage become stricter.
Finally, robust monitoring builds trust among stakeholders. When engineers, data scientists, and business leaders know that models are being continuously evaluated and maintained, they are more likely to support and invest in machine learning initiatives.
In summary, advanced model monitoring is a foundational practice for any organization that wants to scale machine learning safely and effectively. It not only protects against risks but also unlocks the full potential of AI by ensuring models deliver value in real-world, ever-changing environments.
Key Architectural Patterns for Advanced Feature Stores
As machine learning systems scale, the architecture of feature stores becomes a critical factor in ensuring efficient, reliable, and maintainable ML pipelines. Advanced feature stores are designed to centralize, standardize, and automate the management of features—making them accessible, consistent, and reusable across teams and projects.
At the core of an advanced feature store architecture are several key components. The feature registry acts as a catalog, storing metadata about each feature, such as its definition, data sources, owners, and version history. This registry enables discoverability and governance, ensuring that teams can easily find and reuse features while maintaining control over changes.
The storage layer is another essential element. It typically supports both batch and real-time access patterns, allowing features to be retrieved efficiently for training and serving. This often involves a combination of data warehouses (for historical, batch features) and low-latency databases or key-value stores (for real-time, online features). The architecture must ensure consistency between these layers so that the same feature values are available during both training and inference.
A transformation engine is responsible for computing features from raw data. In advanced setups, this engine supports both batch and streaming transformations, enabling the creation of features from static datasets as well as real-time event streams. This flexibility is crucial for supporting a wide range of ML use cases, from fraud detection to recommendation systems.
Access control and security are also integral to the architecture. Advanced feature stores implement fine-grained permissions, audit logging, and data encryption to protect sensitive information and comply with regulatory requirements.
Finally, integration with MLOps pipelines is a hallmark of advanced architectures. Feature stores are designed to plug seamlessly into automated workflows for data ingestion, model training, validation, and deployment. This integration ensures that features are always up-to-date, reproducible, and traceable throughout the ML lifecycle.
In summary, the architecture of advanced feature stores is built around modularity, scalability, and automation. By combining robust registries, flexible storage, powerful transformation engines, and strong security, these systems empower organizations to manage features efficiently and accelerate the development and deployment of high-quality machine learning models.
Real-Time vs. Batch Feature Stores: Design Considerations
In advanced machine learning systems, the choice between real-time and batch feature stores is a fundamental architectural decision that shapes how features are generated, stored, and served to models. Each approach has distinct strengths and is suited to different types of ML applications.
Batch feature stores are designed to process and store features computed on large volumes of historical data at scheduled intervals—typically hourly, daily, or weekly. These features are ideal for use cases where real-time freshness is not critical, such as credit scoring, churn prediction, or customer segmentation. Batch processing leverages data warehouses or distributed file systems, enabling efficient computation over massive datasets. The main advantages are scalability, cost-effectiveness, and the ability to perform complex aggregations or transformations that require access to large data windows.
Real-time feature stores, on the other hand, are built to handle streaming data and provide features with minimal latency—often within milliseconds or seconds. This is essential for applications like fraud detection, online recommendations, or dynamic pricing, where models must react instantly to new information. Real-time feature stores rely on technologies such as message queues, stream processing frameworks, and low-latency databases. They are optimized for high availability and fast access, but may require more sophisticated engineering to ensure consistency and reliability.
A key design consideration is synchronization between batch and real-time features. In many organizations, a hybrid approach is used: batch features provide rich historical context, while real-time features capture the latest user actions or events. Ensuring that both types of features are consistent—so that the same logic and data transformations are applied in both batch and real-time pipelines—is crucial for model accuracy and reproducibility.
Other important factors include data freshness requirements, cost constraints, and operational complexity. Real-time systems can be more expensive and harder to maintain, but they unlock new ML capabilities that batch systems cannot support. The choice often depends on the business problem, the criticality of low-latency predictions, and the available infrastructure.
In summary, the decision between real-time and batch feature stores is not either-or; advanced ML platforms often combine both, leveraging the strengths of each. The key is to design a system that delivers the right features, at the right time, with the right level of consistency and reliability for your specific use case.
Data Lineage, Versioning, and Governance in Feature Stores
As machine learning projects grow in complexity and scale, maintaining transparency, control, and trust in the data pipeline becomes essential. This is where data lineage, versioning, and governance play a pivotal role in advanced feature stores.
Data lineage refers to the ability to trace the origin, movement, and transformation of data throughout its lifecycle. In the context of feature stores, lineage means knowing exactly how each feature was created—from raw data sources, through transformation steps, to the final feature value used in model training or inference. This traceability is crucial for debugging, auditing, and ensuring reproducibility. If a model’s performance suddenly drops, lineage allows teams to quickly identify whether a change in the data pipeline or a new data source is responsible.
Versioning in feature stores applies to both features and the data they are derived from. Every change to a feature’s definition, transformation logic, or underlying data source should be tracked and versioned. This enables teams to roll back to previous versions if issues arise, compare model performance across different feature sets, and ensure that experiments are reproducible. Versioning also supports A/B testing and model comparison, as it’s possible to train and evaluate models on different feature versions.
Governance encompasses the policies, processes, and controls that ensure data is managed responsibly and in compliance with organizational and regulatory requirements. In feature stores, governance includes access control (who can view or modify features), audit logging (who did what and when), and data quality checks (ensuring features meet defined standards). Good governance helps prevent unauthorized changes, supports compliance with data privacy laws, and builds trust among stakeholders.
Together, data lineage, versioning, and governance form the backbone of responsible feature management. They provide the transparency needed for effective collaboration between data scientists, engineers, and business teams, and they are essential for meeting the growing demands of regulatory compliance in AI and machine learning.
In summary, advanced feature stores that prioritize lineage, versioning, and governance empower organizations to build more reliable, auditable, and trustworthy ML systems—laying the foundation for scalable and sustainable machine learning operations.
Integrating Feature Stores with MLOps Pipelines
Integrating feature stores with MLOps pipelines is a cornerstone of modern, scalable machine learning operations. This integration ensures that features are consistently available, up-to-date, and reproducible across the entire ML lifecycle—from data ingestion and model training to deployment and monitoring.
A well-integrated feature store acts as a single source of truth for all features used in ML projects. When connected to MLOps pipelines, it automates the process of feature extraction, transformation, and delivery. This means that data scientists and engineers no longer need to manually recreate feature engineering steps for each new model or deployment. Instead, they can simply reference features from the store, ensuring consistency and reducing the risk of errors.
One of the key benefits of this integration is reproducibility. By versioning both features and their transformation logic, feature stores make it possible to recreate the exact feature set used in any past experiment or production model. This is essential for debugging, auditing, and regulatory compliance.
Another advantage is automation. MLOps pipelines can be configured to automatically trigger feature updates, retraining, and redeployment whenever new data arrives or when features are modified. This reduces manual intervention, speeds up the development cycle, and helps keep models fresh and relevant.
Monitoring and validation are also enhanced by this integration. Feature stores can provide real-time statistics and quality checks on feature values, alerting teams to anomalies, missing data, or drift. This proactive monitoring helps maintain model performance and reliability in production.
Finally, integrating feature stores with MLOps pipelines fosters collaboration. Teams across the organization can share, discover, and reuse features, accelerating experimentation and reducing duplication of effort.
In summary, the integration of feature stores with MLOps pipelines transforms feature management from a manual, error-prone process into an automated, reliable, and collaborative workflow. This not only improves the efficiency and quality of machine learning projects but also lays the groundwork for scaling ML operations across the enterprise.
Monitoring Feature Quality and Data Drift
Monitoring feature quality and detecting data drift are essential practices in maintaining robust and reliable machine learning systems. As models move from development to production, the data they encounter can change in subtle or significant ways, potentially degrading model performance. Advanced feature stores play a crucial role in automating and streamlining this monitoring process.
Feature quality monitoring involves continuously checking the statistical properties of features—such as mean, standard deviation, missing value rates, and distribution shapes. By tracking these metrics over time, teams can quickly spot anomalies, such as sudden spikes in missing values or unexpected shifts in feature distributions. These issues might indicate upstream data problems, pipeline bugs, or changes in user behavior.
Data drift detection focuses on identifying when the distribution of incoming data diverges from the data used to train the model. Drift can occur due to seasonality, market changes, or evolving user patterns. If not detected and addressed, drift can lead to model predictions becoming less accurate or even biased.
Feature stores can automate both quality monitoring and drift detection by integrating with MLOps pipelines and providing dashboards, alerts, and logs. For example, they can compare the distribution of features in real-time data against historical baselines and trigger notifications if significant deviations are detected.
Example: Detecting Data Drift in Python
Here’s a simple example using Python and the scikit-learn library to compare the distribution of a feature in training and production data using the Kolmogorov-Smirnov test:
python
from scipy.stats import ks_2samp
import numpy as np
# Example feature values from training and production
train_feature = np.random.normal(loc=0, scale=1, size=1000)
prod_feature = np.random.normal(loc=0.2, scale=1.1, size=1000)
# Kolmogorov-Smirnov test for distribution drift
statistic, p_value = ks_2samp(train_feature, prod_feature)
if p_value < 0.05:
print("Data drift detected for this feature!")
else:
print("No significant data drift detected.")This approach can be extended to monitor all features in a feature store, with results visualized in dashboards or used to trigger automated retraining workflows.
In summary, monitoring feature quality and data drift is vital for sustaining high-performing ML models in production. Advanced feature stores, with built-in monitoring and alerting capabilities, help teams detect issues early, maintain trust in model predictions, and ensure that machine learning systems remain reliable as data evolves.
Cost Drivers in Feature Store Operations
Operating a feature store at scale introduces a range of costs that organizations must understand and manage to ensure efficiency and sustainability. The main cost drivers in feature store operations can be grouped into several key areas: storage, compute, data transfer, integration overhead, and ongoing maintenance.
Storage costs are often the most visible, especially as the volume of features and historical data grows. Feature stores need to retain raw data, transformed features, and multiple versions for reproducibility and auditing. The choice of storage backend (e.g., cloud object storage, distributed databases) and retention policies directly impact these costs. Storing high-cardinality or real-time features can further increase storage requirements.
Compute costs arise from the processing required to generate, transform, and serve features. Batch feature engineering jobs may require significant resources for large datasets, while real-time feature computation demands low-latency, always-on infrastructure. The complexity of feature transformations, frequency of updates, and the need for on-demand feature serving all contribute to compute expenses.
Data transfer costs can become significant, particularly in cloud environments where moving data between storage, compute, and serving layers—or across regions—incurs additional charges. Real-time feature stores that serve features to low-latency applications may also generate high network traffic, further increasing costs.
Integration overhead includes the engineering effort and resources needed to connect the feature store with various data sources, ML pipelines, and production systems. This can involve building and maintaining connectors, APIs, and monitoring tools, as well as ensuring compatibility with evolving data schemas and infrastructure.
Maintenance and operational costs cover the ongoing work required to monitor, update, and secure the feature store. This includes patching software, scaling infrastructure, managing access controls, and responding to incidents or outages. As the feature store becomes a critical part of the ML stack, ensuring high availability and reliability can require additional investment in redundancy and support.
In summary, the total cost of operating a feature store is shaped by storage, compute, data transfer, integration, and maintenance. Understanding these drivers helps organizations make informed decisions about architecture, technology choices, and optimization strategies—ultimately enabling them to balance performance, scalability, and cost-effectiveness in their ML operations.
Strategies for Cost Optimization in Feature Stores
As feature stores become central to large-scale machine learning operations, managing their operational costs is crucial for long-term sustainability. Effective cost optimization requires a combination of architectural choices, process improvements, and smart use of cloud and open-source technologies. Here are some practical strategies for reducing costs in feature store operations:
Optimizing storage is often the first step. This can be achieved by implementing data retention policies that automatically archive or delete outdated feature versions and raw data that are no longer needed for compliance or reproducibility. Using efficient storage formats (like Parquet or ORC) and compressing data can also significantly reduce storage footprints and associated costs. For rarely accessed historical data, consider moving it to lower-cost, infrequently accessed storage tiers.
Reducing compute expenses involves scheduling batch feature engineering jobs during off-peak hours to take advantage of lower cloud pricing, or using spot/preemptible instances for non-critical workloads. For real-time features, optimize transformation pipelines to minimize unnecessary computations and leverage serverless or autoscaling infrastructure to match resource usage with demand.
Minimizing data transfer costs can be addressed by co-locating storage and compute resources within the same cloud region, reducing cross-region or cross-zone data movement. Caching frequently accessed features closer to the point of consumption (e.g., using in-memory stores like Redis) can also help lower network traffic and latency.
Streamlining integration and maintenance is possible by standardizing APIs and connectors, automating monitoring and alerting, and using managed feature store solutions when appropriate. Open-source feature stores can reduce licensing costs, but require careful planning to avoid hidden operational overhead.
Monitoring and right-sizing resources is an ongoing process. Regularly review usage metrics, identify underutilized resources, and adjust infrastructure accordingly. Implementing cost dashboards and automated alerts can help teams stay proactive about cost management.
In summary, cost optimization in feature stores is a continuous effort that balances performance, reliability, and budget. By combining smart storage management, efficient compute usage, minimized data transfer, and streamlined operations, organizations can ensure their feature stores remain both powerful and cost-effective as their machine learning initiatives scale.
Security and Compliance in Advanced Feature Stores
Security and compliance are critical considerations when operating advanced feature stores, especially in industries with strict regulatory requirements or sensitive data. As feature stores become a central hub for data used in machine learning, they must be designed and managed to protect data integrity, privacy, and ensure adherence to legal and organizational standards.
Data access control is fundamental. Feature stores should implement robust authentication and authorization mechanisms, ensuring that only approved users and services can access specific features or datasets. Role-based access control (RBAC) and fine-grained permissions help restrict access to sensitive features, supporting the principle of least privilege.
Data encryption is essential both at rest and in transit. Storing features in encrypted formats and using secure communication protocols (such as TLS) for data transfer helps prevent unauthorized access and data breaches. Many cloud providers and managed feature store solutions offer built-in encryption options that can be configured to meet compliance requirements.
Audit logging and monitoring are necessary for tracking who accessed or modified features, when, and how. Comprehensive audit trails support forensic investigations, compliance audits, and help detect suspicious activity. Automated monitoring can alert teams to unusual access patterns or potential security incidents in real time.
Data lineage and versioning are also important for compliance. Feature stores should track the origin, transformation, and usage of each feature, making it possible to reproduce results, respond to regulatory inquiries, and demonstrate compliance with data governance policies.
Compliance with regulations such as GDPR, HIPAA, or industry-specific standards requires careful management of personal or sensitive data. This may involve data anonymization, masking, or implementing data retention and deletion policies to ensure that data is only stored and processed as long as necessary.
Regular security reviews and updates are vital. As threats evolve, feature store configurations, dependencies, and integrations should be regularly assessed and updated to address new vulnerabilities. Security best practices—such as patch management, vulnerability scanning, and incident response planning—should be part of ongoing operations.
In summary, advanced feature stores must be built with security and compliance at their core. By implementing strong access controls, encryption, audit logging, data lineage, and adhering to relevant regulations, organizations can protect their data assets, maintain trust, and ensure that their machine learning workflows remain secure and compliant as they scale.
Integrating Feature Stores with Enterprise Security and Compliance Workflows
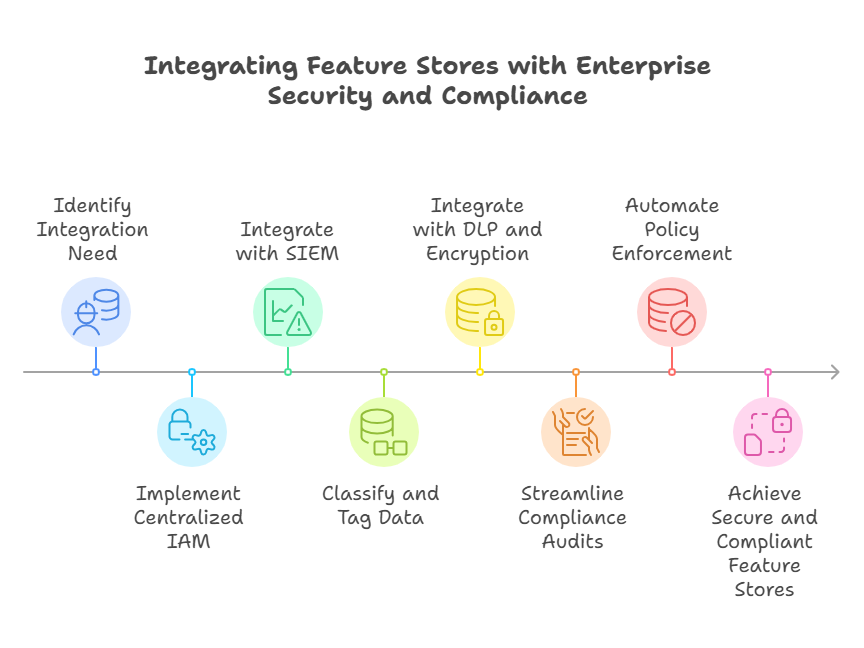
Integrating feature stores with broader enterprise security and compliance workflows is essential for organizations that operate at scale or handle sensitive data. This integration ensures that the feature store does not become a weak link in the organization’s data governance, risk management, or regulatory compliance strategies.
Centralized identity and access management (IAM) is a foundational step. By connecting the feature store to enterprise IAM systems (such as Active Directory, LDAP, or cloud-native IAM services), organizations can enforce consistent authentication and authorization policies across all data platforms. This enables single sign-on (SSO), multi-factor authentication (MFA), and centralized management of user roles and permissions, reducing the risk of unauthorized access.
Automated compliance monitoring can be achieved by integrating the feature store with enterprise security information and event management (SIEM) systems. This allows for real-time aggregation and analysis of audit logs, access records, and anomaly detection across the entire data ecosystem. Automated alerts and incident response workflows can be triggered if suspicious activity or policy violations are detected.
Data classification and tagging within the feature store help align with enterprise data governance policies. By tagging features with metadata such as sensitivity level, data owner, or regulatory requirements, organizations can automate enforcement of data handling rules—such as masking, encryption, or retention policies—based on the classification.
Integration with data loss prevention (DLP) and encryption services ensures that sensitive features are protected according to enterprise standards. DLP tools can scan feature data for personally identifiable information (PII) or other sensitive content, while managed encryption services can enforce encryption at rest and in transit, with key management handled centrally.
Regular compliance audits and reporting are streamlined when feature stores are integrated with enterprise compliance tools. Automated reporting on data access, lineage, and retention helps demonstrate adherence to regulations like GDPR, HIPAA, or industry-specific standards. This is especially important for organizations that must provide evidence of compliance to regulators or customers.
Policy-driven automation is another benefit of integration. For example, if a feature is tagged as containing PII, automated workflows can ensure it is only accessible to authorized users, is always encrypted, and is deleted after a specified retention period.
In summary, integrating feature stores with enterprise security and compliance workflows transforms them from isolated data tools into fully governed, auditable, and secure components of the organization’s ML infrastructure. This not only reduces risk and operational overhead but also builds trust with stakeholders and regulators as machine learning initiatives scale.
Case Study: Feature Store Security and Compliance in a Financial Institution
To illustrate the practical application of advanced security and compliance in feature stores, let’s look at a case study from a large financial institution deploying machine learning models for fraud detection and credit risk assessment.
Background:
The institution manages sensitive customer data and operates under strict regulatory frameworks such as GDPR and PCI DSS. As machine learning adoption grew, the need for a centralized feature store became clear to ensure consistency, reusability, and governance of features across multiple ML projects.
Security Integration:
The feature store was integrated with the bank’s enterprise IAM system, enabling single sign-on and multi-factor authentication for all users. Role-based access control (RBAC) was enforced, so only authorized data scientists and engineers could access or modify specific features. All data at rest was encrypted using the bank’s managed key service, and TLS was required for all data transfers.
Compliance Automation:
Features were tagged with metadata indicating data sensitivity, regulatory requirements, and data owners. Automated data loss prevention (DLP) tools scanned feature data for PII and flagged any policy violations. The feature store’s audit logs were streamed to the bank’s SIEM platform, enabling real-time monitoring and alerting for suspicious access patterns.
Data Lineage and Retention:
Every feature’s lineage was tracked, from raw data ingestion through transformation and usage in models. This made it possible to reproduce model results for audits and respond quickly to regulatory inquiries. Automated retention policies ensured that features containing sensitive data were deleted after the required period, with compliance reports generated monthly.
Results:
The integration of the feature store with enterprise security and compliance workflows led to several benefits:
Reduced risk of data breaches and unauthorized access
Faster and more reliable compliance reporting
Improved trust with regulators and customers
Streamlined audits and incident response
Key Takeaways:
This case study demonstrates that with the right architecture and integration, feature stores can meet the highest standards of security and compliance—even in highly regulated industries. The combination of centralized access control, automated monitoring, data lineage, and policy-driven automation enabled the institution to scale its ML initiatives confidently and securely.
Future Directions: Innovations in Feature Store Security, Monitoring, and Cost Management
As machine learning systems continue to scale and diversify, the demands on feature stores are evolving rapidly. The future of advanced feature stores will be shaped by innovations in security, monitoring, and cost management, driven by both technological advances and increasing regulatory expectations.
Security will become even more proactive and intelligent. We can expect the adoption of AI-driven threat detection within feature stores, where machine learning models monitor access patterns and flag anomalies in real time. Zero-trust architectures—where every access request is continuously verified, regardless of network location—will become standard, especially in multi-cloud and hybrid environments. Automated policy enforcement, such as dynamic masking or encryption based on feature sensitivity, will further reduce the risk of data leaks.
Monitoring will move beyond basic logging to provide deep, actionable insights. Feature stores will integrate with observability platforms to offer end-to-end visibility into data flows, feature transformations, and model consumption. Real-time dashboards will track feature freshness, data drift, and quality metrics, enabling teams to respond instantly to issues. Automated root cause analysis, powered by AI, will help diagnose and resolve data or model problems faster than ever.
Cost management will benefit from smarter automation and predictive analytics. Feature stores will leverage usage analytics to recommend optimal storage tiers, compute resources, and data retention policies. Dynamic scaling—automatically adjusting resources based on workload—will become more granular and efficient, minimizing waste. Some platforms may even offer “cost simulators” to forecast the financial impact of new features or workloads before deployment.
Interoperability and standardization are also on the horizon. As organizations adopt multiple ML platforms and cloud providers, feature stores will need to support open standards for data exchange, security, and monitoring. This will make it easier to integrate with enterprise governance tools and migrate workloads as needed.
Privacy-enhancing technologies such as federated learning, differential privacy, and secure multi-party computation will be increasingly integrated into feature stores, enabling organizations to collaborate on ML projects without exposing sensitive data.
In summary, the next generation of feature stores will be smarter, more secure, and more cost-efficient—empowering organizations to scale machine learning confidently while meeting the highest standards of governance and operational excellence. Staying ahead in this space will require not just adopting new tools, but also fostering a culture of continuous improvement and cross-functional collaboration between data, security, and operations teams.
Continuous Delivery and Monitoring of ML Models: Practical Challenges and Solutions
Testing ML Models: From Unit Tests to End-to-End Testing
MLOps in Practice: Automation and Scaling of AI Model Deployments