

Introduction: The Importance of Integrating Data Engineering and MLOps
In today’s fast-paced AI-driven world, the seamless integration of data engineering and MLOps is crucial for delivering reliable, scalable, and impactful machine learning solutions. While data engineering focuses on collecting, processing, and managing data, MLOps ensures that machine learning models are developed, deployed, and maintained efficiently. Bridging these two disciplines is essential to create end-to-end workflows that transform raw data into actionable AI insights.
The traditional approach often treats data engineering and MLOps as separate silos, leading to inefficiencies, miscommunication, and delays. Data engineers may build pipelines that deliver data without considering the specific needs of ML models, while ML teams may struggle with inconsistent or low-quality data. This disconnect can result in models that perform poorly in production or require extensive manual intervention to maintain.
Integrating data engineering with MLOps enables organizations to automate and standardize the entire AI delivery process. It ensures that data pipelines are designed with ML requirements in mind—such as feature consistency, data freshness, and validation—while MLOps workflows incorporate data quality checks and lineage tracking. This collaboration accelerates model development, improves accuracy, and reduces operational risks.
Moreover, a unified approach supports better governance and compliance. By linking data provenance with model versions and deployment history, organizations can maintain full traceability and meet regulatory requirements more easily. It also fosters a culture of collaboration, where data scientists, engineers, and operations teams work together toward shared business goals.
In summary, integrating data engineering and MLOps is not just a technical necessity—it’s a strategic advantage. It enables seamless AI delivery, reduces time-to-market, and ensures that machine learning models consistently deliver value in production. As AI continues to transform industries, organizations that master this integration will be best positioned to innovate and compete.
Understanding the Roles of Data Engineering and MLOps Teams
To successfully bridge data engineering and MLOps, it’s essential to understand the distinct yet complementary roles each team plays in the AI delivery process. While their responsibilities often overlap, clear delineation and collaboration between these teams are key to building efficient, scalable, and reliable machine learning systems.
Data Engineering Team
Data engineers are responsible for designing, building, and maintaining the data infrastructure that powers machine learning models. Their core tasks include:
Data Ingestion: Collecting data from various sources such as databases, APIs, and streaming platforms.
Data Processing: Cleaning, transforming, and aggregating raw data into usable formats.
Data Storage: Managing data lakes, warehouses, and databases to ensure efficient and secure storage.
Data Quality and Validation: Implementing automated checks to ensure data accuracy, completeness, and consistency.
Data Pipeline Orchestration: Scheduling and monitoring data workflows to ensure timely and reliable data delivery.
Data engineers focus on creating robust, scalable pipelines that provide high-quality data to downstream consumers, including data scientists and ML engineers.
MLOps Team
MLOps teams focus on operationalizing machine learning models, ensuring that they are developed, deployed, monitored, and maintained effectively. Their responsibilities include:
Model Development Support: Collaborating with data scientists to package models and prepare them for deployment.
Model Versioning and Registry: Managing model versions, metadata, and deployment status.
CI/CD for ML: Automating testing, validation, and deployment of models.
Monitoring and Alerting: Tracking model performance, data drift, and system health in production.
Automated Retraining and Rollback: Implementing workflows to update or revert models based on monitoring insights.
MLOps teams ensure that models are production-ready, reliable, and compliant with organizational and regulatory standards.
Collaboration Between Teams
Effective AI delivery requires close collaboration between data engineering and MLOps teams. This includes:
Aligning Data and Model Requirements: Data engineers must understand the feature and data needs of ML models, while MLOps teams should provide feedback on data quality and availability.
Shared Tooling and Processes: Using integrated platforms and standardized workflows to reduce friction and improve transparency.
Joint Monitoring and Incident Response: Coordinating on data and model monitoring to quickly identify and resolve issues.
Designing Unified Data and ML Pipelines
Designing unified data and machine learning (ML) pipelines is essential for achieving seamless AI delivery in modern organizations. By integrating DataOps and MLOps workflows, teams can automate the entire journey from raw data ingestion to model deployment and monitoring, ensuring consistency, scalability, and efficiency.
A unified pipeline begins with automated data ingestion from diverse sources such as databases, APIs, and streaming platforms. Data is then validated, cleaned, and transformed through standardized preprocessing steps. DataOps practices ensure that these processes are repeatable, monitored, and versioned, providing high-quality, reliable data for ML models.
Next, the pipeline incorporates feature engineering and feature stores, which enable reusable, consistent feature definitions accessible to both training and inference workflows. This reduces duplication and ensures that models operate on the same data representations in production as during development.
The ML component of the pipeline automates model training, hyperparameter tuning, and validation, leveraging scalable compute resources and experiment tracking tools. Once validated, models are registered in a centralized model registry that tracks versions, metadata, and deployment status.
Deployment automation ensures that models are seamlessly pushed to staging or production environments, with integrated monitoring and alerting to track performance and detect drift. When issues arise, automated retraining or rollback workflows maintain model quality and business continuity.
By designing pipelines that span both data and ML workflows, organizations break down traditional silos, enabling better collaboration between data engineers, data scientists, and ML engineers. This unified approach accelerates innovation, reduces operational risk, and ensures that AI solutions deliver consistent, measurable business value.
Data Quality and Validation in Integrated Workflows
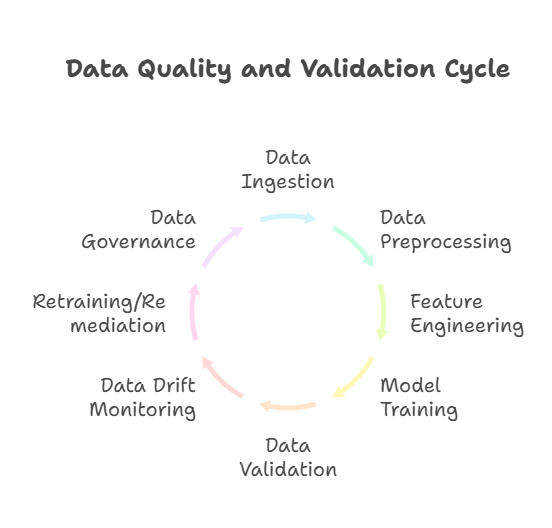
Data quality and validation are fundamental to the success of integrated DataOps and MLOps workflows. High-quality, reliable data is the foundation upon which effective machine learning models are built. Without rigorous data validation, models risk being trained on flawed or inconsistent data, leading to poor performance and unreliable predictions in production.
In integrated workflows, data quality checks are embedded throughout the pipeline—from initial ingestion and preprocessing to feature engineering and model training. Automated validation frameworks, such as Great Expectations or custom validation scripts, verify that data conforms to expected schemas, contains no missing or anomalous values, and maintains consistency with historical patterns.
Validation also includes monitoring for data drift, where the statistical properties of input data change over time, potentially degrading model accuracy. By continuously validating data in production, teams can detect drift early and trigger retraining or remediation workflows.
Moreover, integrated workflows ensure that data validation results are linked with model metadata and experiment tracking. This linkage provides full traceability, enabling teams to understand how data quality impacts model performance and to reproduce results reliably.
Effective data governance complements validation by enforcing access controls, data lineage tracking, and compliance with regulatory requirements. Together, these practices ensure that data used in ML pipelines is trustworthy, secure, and compliant.
Feature Engineering and Feature Stores: Shared Responsibilities
Feature engineering is a critical step in the machine learning lifecycle, transforming raw data into meaningful inputs that models can learn from. In integrated DataOps and MLOps workflows, feature engineering becomes a shared responsibility that bridges data engineering and machine learning teams, ensuring consistency, reusability, and scalability.
Traditionally, feature engineering was often performed ad hoc by data scientists, leading to duplicated efforts, inconsistent feature definitions, and challenges in maintaining production pipelines. Modern MLOps practices advocate for centralized feature stores—repositories that store, manage, and serve features for both training and inference.
Feature stores enable teams to define features once, version them, and serve them consistently across environments. This reduces discrepancies between training and production data, a common source of model performance issues. Data engineers typically build and maintain the pipelines that compute and update features, while ML engineers and data scientists consume these features for model development and serving.
In hybrid environments, feature stores must support both batch and real-time feature computation, integrating with diverse data sources and serving low-latency requests. They also track feature lineage and metadata, supporting governance and compliance.
By sharing responsibility for feature engineering and leveraging feature stores, organizations improve collaboration, reduce operational risk, and accelerate model development. This unified approach ensures that features are reliable, scalable, and aligned with business needs.
Automating Data and Model Versioning
Automating data and model versioning is a fundamental practice in integrated DataOps and MLOps workflows. It ensures reproducibility, traceability, and efficient collaboration across teams by systematically tracking every change to datasets, features, code, and models. Automation reduces manual errors and accelerates the development and deployment of machine learning solutions.
Why Automate Versioning?
Manual versioning is error-prone and difficult to scale, especially as the number of models and datasets grows. Automated versioning links data versions with corresponding model versions and code commits, enabling teams to reproduce experiments, audit changes, and roll back to previous states if needed.
Tools for Automated Versioning
DVC (Data Version Control): Extends Git to track large datasets and model files, integrating seamlessly with code repositories.
MLflow: Provides model versioning and experiment tracking, capturing metadata and artifacts.
LakeFS: Offers Git-like versioning for data lakes, enabling snapshotting and branching of datasets.
Git: Used for versioning code and configuration files.
Example: Simple Data and Model Versioning with DVC
Below is a minimal example demonstrating how to version data and models using DVC commands in a Python project:
bash
# Initialize DVC in your project
dvc init
# Add data file to DVC tracking
dvc add data/raw_dataset.csv
# Commit changes to Git
git add data/raw_dataset.csv.dvc .gitignore
git commit -m "Add raw dataset to DVC"
# Train your model (example Python script)
python train.py
# Add model file to DVC tracking
dvc add models/model.pkl
# Commit model version
git add models/model.pkl.dvc
git commit -m "Add trained model to DVC"
# Push data and model to remote storage
dvc remote add -d myremote s3://mybucket/path
dvc pushIn your Python code (train.py), you can load the versioned data and save the model accordingly. DVC ensures that the exact versions of data and models are tracked alongside your code.
Orchestrating End-to-End Workflows Across Teams
Orchestrating end-to-end workflows across data engineering, data science, and MLOps teams is essential for delivering seamless, scalable, and reliable AI solutions. As machine learning projects grow in complexity, involving multiple data sources, models, and deployment environments, effective orchestration ensures that all components work together smoothly and efficiently.
Why Orchestration Matters
Without proper orchestration, ML workflows can become fragmented, leading to delays, errors, and miscommunication. Orchestration tools automate the scheduling, execution, and monitoring of pipeline steps, managing dependencies and resource allocation. This automation reduces manual intervention, accelerates delivery, and improves reproducibility.
Key Aspects of Orchestrating Workflows
Cross-Team Collaboration:
Orchestration platforms provide a shared framework where data engineers, data scientists, and ML engineers can collaborate. Clear interfaces and modular pipeline components enable teams to work independently yet integrate their work seamlessly.
Workflow Automation:
Automate data ingestion, preprocessing, feature engineering, model training, validation, deployment, and monitoring. Orchestration tools handle retries, error handling, and conditional execution to ensure robustness.
Scalability and Flexibility:
Support for distributed execution across on-premises and cloud environments allows workflows to scale with data volume and model complexity.
Visibility and Monitoring:
Centralized dashboards provide real-time insights into pipeline status, performance metrics, and failures, enabling rapid troubleshooting and continuous improvement.
Popular Orchestration Tools
Apache Airflow: Widely used for general-purpose workflow orchestration with rich scheduling and monitoring features.
Kubeflow Pipelines: Designed specifically for ML workflows on Kubernetes, supporting containerized, scalable pipelines.
Prefect: A modern, flexible orchestration tool with dynamic workflows and strong error handling.
Cloud-Native Services: AWS Step Functions, Google Cloud Composer, and Azure Data Factory offer managed orchestration with deep cloud integration.
Monitoring Data and Model Performance Together
In modern MLOps workflows, monitoring data and model performance together is crucial for maintaining the accuracy, reliability, and trustworthiness of machine learning systems. Data quality directly influences model predictions, so observing both aspects in tandem enables early detection of issues and proactive remediation, ensuring sustained business value.
Why Monitor Data and Model Performance Together?
Machine learning models are highly sensitive to the quality and distribution of input data. Changes in data—such as missing values, outliers, or shifts in feature distributions (data drift)—can degrade model performance without immediate detection if only model metrics are monitored. Conversely, monitoring only data quality without assessing model outcomes may miss subtle performance issues.
By integrating data and model monitoring, teams gain a holistic view of the ML pipeline’s health. This approach helps identify whether performance degradation stems from data issues, model staleness, or infrastructure problems, enabling targeted interventions.
Key Metrics to Monitor
Data Quality Metrics:
Track completeness, validity, consistency, and distribution of input features. Use statistical tests (e.g., Kolmogorov-Smirnov, Population Stability Index) to detect drift.
Model Performance Metrics:
Monitor accuracy, precision, recall, F1-score, and business-specific KPIs on live or recent data.
Prediction Confidence and Distribution:
Analyze prediction probabilities and output distributions to detect anomalies or uncertainty.
Latency and Throughput:
Measure response times and request volumes to ensure models meet operational requirements.
Tools and Techniques
Modern observability platforms—such as Evidently AI, WhyLabs, Arize AI, or custom solutions built on Prometheus and Grafana—support integrated monitoring of data and model metrics. These tools provide real-time dashboards, automated alerts, and root cause analysis capabilities.
Best Practices
Automate Data and Model Validation: Embed validation checks in data pipelines and model evaluation workflows.
Correlate Metrics: Use unified dashboards to visualize data and model metrics side by side.
Set Thresholds and Alerts: Define actionable thresholds for both data quality and model performance to trigger timely responses.
Continuous Feedback Loops: Use monitoring insights to drive automated retraining or manual investigations.
Managing Security and Compliance Across Data and ML
Managing security and compliance across both data and machine learning (ML) workflows is critical for organizations operating in regulated industries or handling sensitive information. As AI systems become more pervasive, ensuring that data and models are protected, auditable, and compliant with legal requirements is essential to maintain trust and avoid costly penalties.
Security in Data and ML Workflows
Security measures must be integrated throughout the entire ML lifecycle—from data ingestion and storage to model training, deployment, and monitoring. This includes implementing role-based access control (RBAC), encrypting data at rest and in transit, and securing model artifacts and APIs. Identity and access management (IAM) systems help enforce fine-grained permissions, ensuring that only authorized users and services can access sensitive resources.
Compliance Considerations
Regulatory frameworks such as GDPR, HIPAA, and CCPA impose strict requirements on data privacy, consent, and auditability. Compliance in ML workflows involves maintaining detailed records of data lineage, model versions, training datasets, and deployment history. Automated compliance checks and audit logs are necessary to demonstrate adherence to these regulations during internal reviews or external audits.
Best Practices for Security and Compliance
Data Encryption: Use strong encryption standards for all data and model storage and communication channels.
Access Control: Implement RBAC and integrate with enterprise identity providers for centralized user management.
Audit Logging: Maintain immutable logs of all data and model access, changes, and deployments.
Automated Compliance Checks: Integrate compliance validation into CI/CD pipelines to prevent non-compliant models from reaching production.
Privacy-Preserving Techniques: Employ methods like data anonymization, differential privacy, or federated learning to protect sensitive information.
Example: Simple Python Script for Access Logging
Below is a basic example of logging access events to support auditability in ML workflows:
python
from datetime import datetime
def log_access(user_id: str, resource: str, action: str):
timestamp = datetime.utcnow().isoformat()
log_entry = f"{timestamp} | USER: {user_id} | ACTION: {action} | RESOURCE: {resource}"
with open("access_log.txt", "a") as log_file:
log_file.write(log_entry + "\n")
print(f"Access logged: {log_entry}")
# Example usage
log_access(user_id="alice", resource="model_v1.pkl", action="download")
log_access(user_id="bob", resource="training_data.csv", action="modify")Collaboration Tools and Communication Best Practices
Effective collaboration and clear communication are vital for the success of MLOps initiatives, especially in complex, cross-functional teams that include data scientists, ML engineers, data engineers, and business stakeholders. As machine learning projects scale, fostering a collaborative culture and using the right tools can significantly improve productivity, reduce errors, and accelerate the delivery of AI solutions.
The Importance of Collaboration in MLOps
MLOps workflows involve multiple stages—from data preparation and model development to deployment and monitoring—each often handled by different teams. Without seamless collaboration, knowledge silos can form, leading to misaligned goals, duplicated efforts, and delayed deployments. Clear communication ensures that everyone understands project objectives, responsibilities, and timelines.
Key Collaboration Tools
Version Control Systems:
Tools like Git and GitHub enable collaborative code development, versioning, and review processes, ensuring that changes are tracked and integrated smoothly.
Experiment Tracking and Model Registry:
Platforms such as MLflow, Weights & Biases, or Neptune provide shared spaces for tracking experiments, model versions, and metadata, facilitating transparency and reproducibility.
Workflow Orchestration:
Tools like Apache Airflow, Kubeflow, or Prefect allow teams to define, schedule, and monitor complex ML pipelines collaboratively.
Communication Platforms:
Slack, Microsoft Teams, or similar tools support real-time communication, file sharing, and integration with other MLOps tools for notifications and alerts.
Documentation and Knowledge Sharing:
Wikis, Confluence, or Notion help maintain up-to-date documentation, best practices, and onboarding materials accessible to all team members.
Best Practices for Communication
Define Clear Roles and Responsibilities:
Establish who owns each part of the ML lifecycle to avoid confusion and ensure accountability.
Regular Cross-Team Meetings:
Schedule syncs to discuss progress, challenges, and upcoming work, fostering alignment and collaboration.
Use Shared Dashboards and Reports:
Provide visibility into model performance, pipeline status, and project metrics to all stakeholders.
Encourage Open Feedback:
Create a culture where team members can raise concerns, suggest improvements, and share knowledge freely.
Case Studies: Successful Integration of Data Engineering and MLOps
The integration of data engineering and MLOps is pivotal for organizations aiming to build scalable, reliable, and efficient AI systems. Real-world case studies demonstrate how companies have successfully bridged these disciplines to streamline workflows, improve model quality, and accelerate time-to-market.
Case Study 1: Global E-commerce Platform
A global e-commerce company faced challenges managing vast amounts of customer data and deploying personalized recommendation models. By integrating their data engineering pipelines with MLOps workflows using Apache Airflow and MLflow, they automated data validation, feature engineering, model training, and deployment. This unified approach reduced manual errors, improved model accuracy, and shortened deployment cycles from weeks to days.
Case Study 2: Financial Services Firm
A financial institution needed to comply with stringent regulatory requirements while deploying credit risk models. They implemented a hybrid architecture combining on-premises data processing with cloud-based MLOps tools. Data engineers ensured data quality and lineage using DataOps practices, while MLOps teams managed model versioning, automated testing, and monitoring. This collaboration enabled rapid model updates with full auditability and compliance.
Case Study 3: Healthcare Analytics Company
A healthcare analytics startup integrated data engineering and MLOps to deliver predictive models for patient outcomes. Using feature stores and automated pipelines, they ensured consistent feature availability for training and inference. Continuous monitoring and automated retraining workflows maintained model performance despite evolving clinical data. The integrated approach enhanced patient care and operational efficiency.
Lessons Learned
Automation is key: Automate data and model workflows to reduce errors and accelerate delivery.
Centralize metadata: Unified tracking of data and model lineage supports reproducibility and compliance.
Foster collaboration: Cross-functional teams improve alignment and problem-solving.
Monitor continuously: Integrated monitoring detects issues early and triggers automated responses.
MLOps in the Cloud: Tools and Strategies
Monitoring ML models in production: tools, challenges, and best practices