
Introduction: Why Continuous Delivery and Monitoring Matter in ML
In the rapidly evolving world of machine learning, building a high-performing model is only the beginning. The true value of ML comes from delivering models to production quickly, reliably, and safely—and ensuring they continue to perform as expected over time. This is where continuous delivery (CD) and monitoring become essential pillars of modern ML operations.
Continuous Delivery in ML refers to the automated process of packaging, testing, and deploying models into production environments. Unlike traditional software, ML models are sensitive to changes in data, feature engineering, and even the underlying infrastructure. CD practices help teams release new models and updates frequently, with minimal manual intervention, reducing the risk of human error and accelerating the feedback loop between development and production.
Monitoring is equally critical. Once a model is live, its performance can degrade due to changes in data distributions, user behavior, or external factors—a phenomenon known as model drift. Without robust monitoring, organizations risk making decisions based on outdated or biased predictions, which can have serious business or ethical consequences. Monitoring enables teams to track key metrics such as accuracy, latency, and data quality, and to detect anomalies or drifts early.
Together, continuous delivery and monitoring form the backbone of reliable ML systems. They enable organizations to:
Respond quickly to new data and business requirements.
Detect and address issues before they impact users.
Maintain compliance and transparency in regulated industries.
Build trust in AI-driven products and services.
In the following chapters, we’ll explore the core concepts, practical challenges, and proven solutions for implementing effective continuous delivery and monitoring in real-world ML projects.
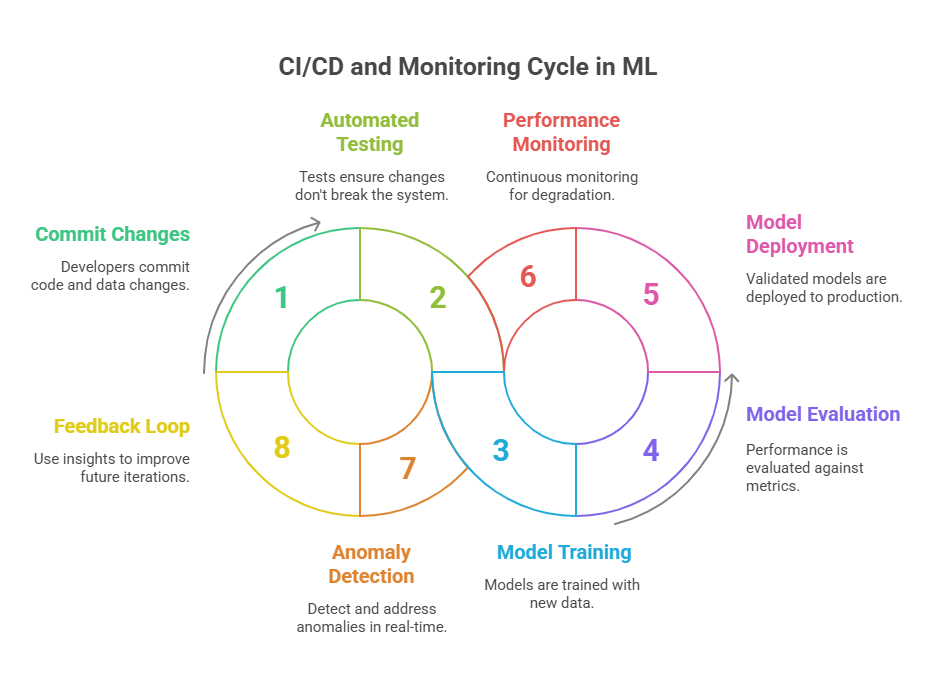
Key Concepts: CI/CD and Monitoring in Machine Learning
To build robust and scalable machine learning systems, it’s crucial to understand the foundational concepts of CI/CD (Continuous Integration and Continuous Delivery) and monitoring—both of which are adapted from traditional software engineering but require unique considerations in the ML context.
CI/CD in Machine Learning
Continuous Integration (CI) is the practice of automatically building, testing, and validating code changes as soon as they are committed to a shared repository. In ML, CI extends beyond code to include data, model artifacts, and configuration files. This means that every change—whether it’s a new feature, a data preprocessing step, or a model parameter—should trigger automated tests to ensure nothing breaks downstream.
Continuous Delivery (CD) takes this a step further by automating the deployment of validated models to production or staging environments. The goal is to make model releases frequent, predictable, and low-risk. In ML, CD pipelines often include steps such as model training, evaluation, packaging, and deployment, as well as automated rollback mechanisms in case of failure.
Key elements of CI/CD in ML include:
Version control for code, data, and models
Automated testing (unit, integration, and data validation tests)
Reproducible pipelines for training and deployment
Automated deployment and rollback strategies
Monitoring in Machine Learning
Once a model is deployed, monitoring becomes essential to ensure it continues to perform as expected. Unlike traditional software, ML models can degrade over time due to changes in input data (data drift), changes in the relationship between features and target (concept drift), or unexpected user behavior.
Effective monitoring in ML involves:
Tracking model performance metrics (e.g., accuracy, precision, recall, latency)
Monitoring data quality and distribution
Detecting anomalies, drift, and outliers in real time
Logging predictions and input data for auditing and debugging
Setting up alerting and incident response workflows
Why These Concepts Matter
Integrating CI/CD and monitoring into the ML lifecycle helps teams deliver models faster, with higher quality and reliability. It also enables rapid iteration, early detection of issues, and continuous improvement—key ingredients for successful AI-driven products.
Building Automated ML Pipelines: Tools and Best Practices
Automated machine learning pipelines are the backbone of modern MLOps, enabling teams to move from experimentation to production quickly, reliably, and repeatably. An ML pipeline orchestrates the sequence of steps required to transform raw data into actionable predictions, automating everything from data ingestion to model deployment.
What Is an ML Pipeline?
An ML pipeline is a structured workflow that typically includes stages such as data collection, preprocessing, feature engineering, model training, evaluation, and deployment. Automation ensures that each step is executed consistently, reducing manual errors and making it easier to reproduce results.
Key Tools for Building ML Pipelines
Several open-source and commercial tools help automate and manage ML pipelines. Some of the most popular include:
Kubeflow Pipelines: Built on Kubernetes, Kubeflow Pipelines allow you to define, deploy, and manage complex ML workflows at scale. They support versioning, experiment tracking, and integration with other cloud-native tools.
Apache Airflow: Widely used for orchestrating data workflows, Airflow can also manage ML pipelines by scheduling and monitoring tasks, handling dependencies, and integrating with various data sources.
MLflow: While primarily known for experiment tracking and model registry, MLflow also supports pipeline automation through its Projects and Pipelines modules.
Prefect and Dagster: Modern workflow orchestration tools that offer strong support for data and ML pipelines, with features like dynamic task mapping, retries, and observability.
Best Practices for Automated ML Pipelines
To build robust and maintainable ML pipelines, consider the following best practices:
Modularity: Break down the pipeline into reusable, independent components (e.g., data preprocessing, feature engineering, model training). This makes it easier to test, debug, and update individual steps.
Versioning: Track versions of code, data, and models to ensure reproducibility and enable rollbacks if needed.
Parameterization: Use configuration files or parameter stores to manage hyperparameters and environment-specific settings, making pipelines flexible and portable.
Testing and Validation: Integrate automated tests at each stage—such as data validation, model evaluation, and integration tests—to catch issues early.
Monitoring and Logging: Instrument pipelines with logging and monitoring to track performance, detect failures, and enable rapid troubleshooting.
Scalability: Design pipelines to handle increasing data volumes and model complexity, leveraging distributed computing and cloud resources when necessary.
Security and Compliance: Ensure sensitive data is handled securely, and that pipelines comply with relevant regulations and organizational policies.
The Value of Automation
Automated ML pipelines free data scientists and engineers from repetitive manual tasks, allowing them to focus on experimentation and innovation. They also provide a foundation for continuous delivery and monitoring, making it possible to deploy new models and updates rapidly, with confidence in their quality and reliability.
Model Versioning and Rollback Strategies
As machine learning systems mature and scale, managing multiple versions of models becomes a critical aspect of MLOps. Proper model versioning ensures traceability, reproducibility, and the ability to quickly respond to issues in production. Equally important are rollback strategies, which allow teams to revert to a previous, stable model version if a new deployment causes problems.
Why Model Versioning Matters
Unlike traditional software, ML models are products of both code and data. Any change in training data, feature engineering, or hyperparameters can lead to a new model version with different behavior. Without systematic versioning, it becomes nearly impossible to track which model is running in production, reproduce results, or audit decisions—especially in regulated industries.
Model versioning enables teams to:
Track the lineage of each model, including code, data, and configuration used for training.
Compare performance across different versions.
Reproduce experiments and debug issues.
Meet compliance and audit requirements.
How to Version Models
Effective model versioning typically involves:
Model Registry: A centralized repository (such as MLflow Model Registry, Sagemaker Model Registry, or custom solutions) that stores model artifacts, metadata, and version history.
Unique Identifiers: Assigning unique version numbers or hashes to each model artifact, along with metadata about the training run (e.g., dataset version, code commit, hyperparameters).
Automated Tracking: Integrating versioning into the CI/CD pipeline so that every new model is automatically registered and tracked.
Example using MLflow in Python:
python
import mlflow
import mlflow.sklearn
# Train and log a model
with mlflow.start_run():
mlflow.sklearn.log_model(model, "model")
mlflow.log_param("param_name", param_value)
mlflow.log_metric("accuracy", accuracy)
# The model and its metadata are now versioned in the registryRollback Strategies
Even with thorough testing, new model versions can sometimes underperform or introduce unexpected issues in production. Rollback strategies are essential for minimizing business impact and restoring service quickly.
Common rollback approaches include:
Blue-Green Deployment: Running the new model (blue) alongside the current production model (green). If issues are detected, traffic can be switched back to the green model instantly.
Canary Release: Gradually rolling out the new model to a small subset of users or data. If problems arise, the rollout can be halted or reversed.
Model Registry Rollback: Using the model registry to redeploy a previous, stable version with minimal effort.
Best practices for rollback:
Automate rollback procedures as part of the deployment pipeline.
Monitor key metrics and set up alerts to trigger rollback if performance drops.
Maintain clear documentation and version history for all deployed models.
Conclusion
Model versioning and rollback strategies are foundational for reliable, auditable, and scalable ML operations. By systematically tracking models and preparing for rapid rollback, organizations can innovate quickly while minimizing risk—ensuring that machine learning delivers consistent value in production.
Popular Model Deployment Patterns: Blue-Green, Canary, and Shadow Deployments
Deploying machine learning models to production is a critical step in the MLOps lifecycle, but it comes with unique risks. A new model might perform well in testing but behave unpredictably in the real world due to unseen data, integration issues, or changing user behavior. To minimize these risks, organizations use proven deployment patterns—blue-green, canary, and shadow deployments—that allow for safer, more controlled rollouts.
Blue-Green Deployment
In the blue-green deployment pattern, two identical production environments are maintained: one active (green) and one idle (blue). The current model runs in the green environment, serving all user traffic. When a new model is ready, it’s deployed to the blue environment. After thorough testing, traffic is switched from green to blue in a single step. If any issues arise, reverting to the previous version is as simple as redirecting traffic back to green.
Benefits:
Instant rollback capability
Minimal downtime
Easy to test the new model in a production-like environment before going live
Canary Deployment
Canary deployment introduces the new model gradually. Initially, only a small percentage of user requests are routed to the new model (the “canary”), while the majority continue to use the existing model. Performance and stability are closely monitored. If the canary performs well, the rollout is expanded to more users until the new model fully replaces the old one. If problems are detected, the deployment can be paused or rolled back.
Benefits:
Early detection of issues with minimal user impact
Controlled, incremental rollout
Ability to compare model performance in real-world conditions
Shadow Deployment
Shadow deployment allows the new model to run in parallel with the current production model, but without affecting user-facing results. Real user requests are sent to both models, but only the output of the production model is used. The new model’s predictions are logged and analyzed for comparison. This approach is ideal for validating model behavior on live data before a full rollout.
Benefits:
No risk to end users
Real-world validation of model predictions
Opportunity to analyze discrepancies and refine the model
Choosing the Right Pattern
The choice of deployment pattern depends on the organization’s risk tolerance, infrastructure, and business requirements. Blue-green is best for quick, all-or-nothing switches; canary is ideal for gradual, monitored rollouts; and shadow is perfect for testing models in production without user impact.
Best Practices
Automate deployment and rollback processes to reduce manual errors.
Monitor key metrics (accuracy, latency, error rates) during and after deployment.
Use feature flags or routing rules to control traffic between model versions.
Document deployment history and decisions for traceability.
By leveraging these deployment patterns, teams can deliver new models to production with greater confidence, ensuring both innovation and stability in ML-powered applications.
Automated Testing and Model Validation Before Deployment
Automated testing is crucial in MLOps to ensure that models perform reliably before reaching production. Unlike traditional software testing, ML model validation involves testing not just code, but also data quality, model performance, and integration with existing systems. A comprehensive testing strategy catches issues early and prevents problematic models from affecting end users.
Types of Tests in MLOps
Unit Tests verify individual components of the ML pipeline, such as data preprocessing functions, feature engineering logic, and model inference code.
Integration Tests ensure that different components work together correctly, including data pipelines, model serving infrastructure, and API endpoints.
Data Validation Tests check data quality, schema compliance, and distribution consistency to detect data drift or corruption.
Model Performance Tests validate that the model meets predefined performance thresholds on test datasets.
Implementing Automated Testing
Here’s a comprehensive Python example demonstrating various types of automated tests for ML models:
python
import pytest
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score
import joblib
import json
from scipy import stats
class ModelValidator:
def __init__(self, model_path, test_data_path, performance_thresholds):
self.model = joblib.load(model_path)
self.test_data = pd.read_csv(test_data_path)
self.thresholds = performance_thresholds
def test_data_schema(self):
"""Test that input data matches expected schema"""
expected_columns = ['feature1', 'feature2', 'feature3', 'target']
assert all(col in self.test_data.columns for col in expected_columns), \
f"Missing columns: {set(expected_columns) - set(self.test_data.columns)}"
# Check data types
assert self.test_data['feature1'].dtype == 'float64', "feature1 should be float64"
assert self.test_data['feature2'].dtype == 'int64', "feature2 should be int64"
print("✓ Data schema validation passed")
def test_data_quality(self):
"""Test data quality and detect anomalies"""
# Check for missing values
missing_ratio = self.test_data.isnull().sum().sum() / len(self.test_data)
assert missing_ratio < 0.05, f"Too many missing values: {missing_ratio:.2%}"
# Check for outliers using IQR method
for col in ['feature1', 'feature2', 'feature3']:
Q1 = self.test_data[col].quantile(0.25)
Q3 = self.test_data[col].quantile(0.75)
IQR = Q3 - Q1
outliers = ((self.test_data[col] < (Q1 - 1.5 * IQR)) |
(self.test_data[col] > (Q3 + 1.5 * IQR))).sum()
outlier_ratio = outliers / len(self.test_data)
assert outlier_ratio < 0.1, f"Too many outliers in {col}: {outlier_ratio:.2%}"
print("✓ Data quality validation passed")
def test_data_drift(self, reference_data_path):
"""Detect data drift using Kolmogorov-Smirnov test"""
reference_data = pd.read_csv(reference_data_path)
for col in ['feature1', 'feature2', 'feature3']:
# Perform KS test
ks_stat, p_value = stats.ks_2samp(
reference_data[col].dropna(),
self.test_data[col].dropna()
)
# If p-value < 0.05, there's significant drift
assert p_value >= 0.05, f"Data drift detected in {col}: p-value={p_value:.4f}"
print("✓ Data drift validation passed")
def test_model_performance(self):
"""Test model performance against thresholds"""
X_test = self.test_data[['feature1', 'feature2', 'feature3']]
y_test = self.test_data['target']
# Make predictions
y_pred = self.model.predict(X_test)
# Calculate metrics
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
# Validate against thresholds
assert accuracy >= self.thresholds['min_accuracy'], \
f"Accuracy {accuracy:.3f} below threshold {self.thresholds['min_accuracy']}"
assert precision >= self.thresholds['min_precision'], \
f"Precision {precision:.3f} below threshold {self.thresholds['min_precision']}"
assert recall >= self.thresholds['min_recall'], \
f"Recall {recall:.3f} below threshold {self.thresholds['min_recall']}"
print(f"✓ Model performance validation passed:")
print(f" Accuracy: {accuracy:.3f}")
print(f" Precision: {precision:.3f}")
print(f" Recall: {recall:.3f}")
return {
'accuracy': accuracy,
'precision': precision,
'recall': recall
}
def test_model_inference(self):
"""Test model inference functionality"""
# Test single prediction
sample_input = np.array([[1.0, 2, 3.5]])
prediction = self.model.predict(sample_input)
assert len(prediction) == 1, "Single prediction should return one result"
# Test batch prediction
batch_input = np.array([[1.0, 2, 3.5], [2.0, 3, 4.5], [3.0, 4, 5.5]])
batch_predictions = self.model.predict(batch_input)
assert len(batch_predictions) == 3, "Batch prediction should return three results"
# Test prediction probabilities (if supported)
if hasattr(self.model, 'predict_proba'):
probabilities = self.model.predict_proba(sample_input)
assert np.sum(probabilities[0]) == pytest.approx(1.0, rel=1e-5), \
"Probabilities should sum to 1"
print("✓ Model inference validation passed")
def run_all_tests(self, reference_data_path=None):
"""Run all validation tests"""
print("Starting automated model validation...")
try:
self.test_data_schema()
self.test_data_quality()
if reference_data_path:
self.test_data_drift(reference_data_path)
metrics = self.test_model_performance()
self.test_model_inference()
print("\n🎉 All validation tests passed! Model is ready for deployment.")
return True, metrics
except AssertionError as e:
print(f"\n❌ Validation failed: {e}")
return False, None
except Exception as e:
print(f"\n💥 Unexpected error during validation: {e}")
return False, None
# Usage example
if __name__ == "__main__":
# Define performance thresholds
thresholds = {
'min_accuracy': 0.85,
'min_precision': 0.80,
'min_recall': 0.80
}
# Initialize validator
validator = ModelValidator(
model_path='models/latest_model.pkl',
test_data_path='data/test_data.csv',
performance_thresholds=thresholds
)
# Run validation
is_valid, metrics = validator.run_all_tests(
reference_data_path='data/reference_data.csv'
)
# Save validation results
if is_valid:
validation_report = {
'status': 'PASSED',
'metrics': metrics,
'timestamp': pd.Timestamp.now().isoformat()
}
else:
validation_report = {
'status': 'FAILED',
'timestamp': pd.Timestamp.now().isoformat()
}
with open('validation_report.json', 'w') as f:
json.dump(validation_report, f, indent=2)
print(f"\nValidation report saved to validation_report.json")
# Created/Modified files during execution:
print("validation_report.json")Integration with CI/CD Pipeline
This validation framework can be integrated into CI/CD pipelines using tools like GitHub Actions, Jenkins, or GitLab CI. The pipeline would automatically run these tests whenever a new model is trained, preventing deployment of models that don’t meet quality standards.
Managing the Model Lifecycle and Automated Retraining in Production
Deploying a machine learning model to production is not the end of the journey—it’s just the beginning of its lifecycle. Models that initially perform well can lose effectiveness over time due to changes in data, user behavior, or the business environment. That’s why managing the model lifecycle and automating retraining are essential for maintaining high prediction quality and system stability.
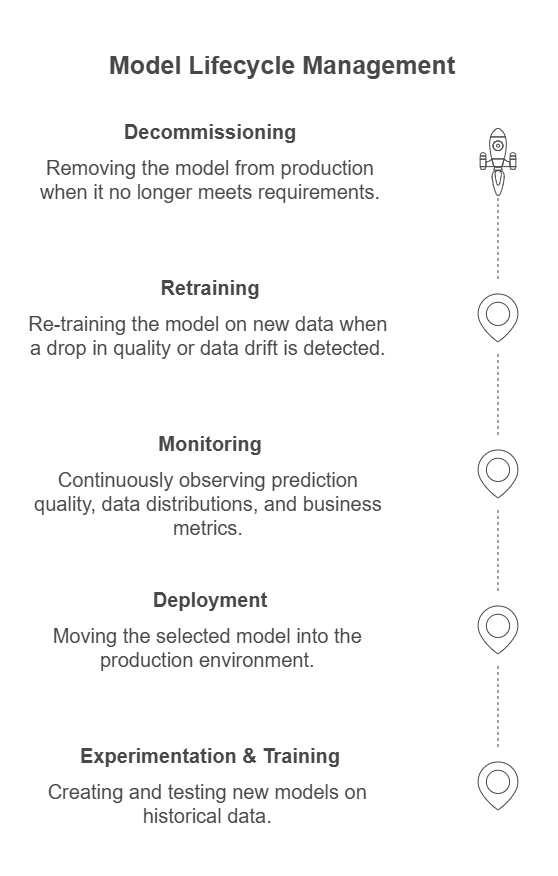
What is the Model Lifecycle?
The model lifecycle covers all stages from experimentation and training, through deployment and monitoring, to retraining and decommissioning. In practice, this means:
Experimentation and Training: Creating and testing new models on historical data.
Deployment: Moving the selected model into the production environment.
Monitoring: Continuously observing prediction quality, data distributions, and business metrics.
Retraining: Re-training the model on new data when a drop in quality or data drift is detected.
Decommissioning: Removing the model from production when it no longer meets requirements or is replaced by a better solution.
When Should You Retrain a Model?
Automated retraining becomes necessary when:
Data drift or changes in feature distributions are detected.
Prediction quality (e.g., accuracy, precision, recall) drops below established thresholds.
Business conditions change or new data becomes available that could improve model performance.
The model operates in a highly dynamic environment (e.g., e-commerce, finance, IoT).
Automating Retraining
In modern MLOps systems, retraining is automated and integrated with CI/CD pipelines. A typical process includes:
Automatic Detection of Retraining Need: The system monitors metrics and triggers retraining when certain thresholds are crossed.
Fetching and Preparing New Data: The pipeline automatically collects, cleans, and prepares the latest data for training.
Training and Validating the New Model: The new model is trained, tested, and compared with the current production model.
Automatic Deployment or Rejection: If the new model meets quality requirements, it is automatically deployed; otherwise, the process is halted and the team is alerted.
Challenges and Best Practices
Transparency: Every retraining step should be logged and auditable.
Security: New models must pass the same tests and validations as the original deployment.
Version Control: All models, data, and pipelines should be versioned to enable quick rollback if issues arise.
Continuous Optimization: Regularly review and adjust the retraining process to match evolving business and technical needs.
Summary
Managing the model lifecycle and automating retraining are foundational to modern MLOps. They not only help maintain high prediction quality but also enable organizations to respond quickly to changes in data and the business environment. This ensures that machine learning delivers lasting value over time.
Security and Compliance in Production ML Environments
As machine learning models become integral to business operations, ensuring their security and compliance is no longer optional—it’s a necessity. Production ML systems often process sensitive data, make critical decisions, and interact with other core business systems. Any breach, misuse, or regulatory violation can have serious consequences, including financial loss, reputational damage, or legal penalties.
Key Security Challenges in ML Systems
Data Privacy and Protection: ML models often require access to large volumes of data, some of which may be personally identifiable or confidential. Protecting this data—both at rest and in transit—is essential. This includes encrypting data, restricting access, and ensuring proper anonymization or pseudonymization where required.
Model Security: Models themselves can be targets. Attackers may attempt to reverse-engineer models, extract sensitive information (model inversion), or manipulate inputs to cause incorrect predictions (adversarial attacks). Protecting model artifacts, using secure storage, and limiting access are crucial steps.
Infrastructure Security: ML pipelines run on complex infrastructure—cloud services, containers, APIs, and databases. Each component must be secured using best practices such as network segmentation, strong authentication, and regular vulnerability scanning.
Supply Chain Risks: ML projects often rely on open-source libraries and third-party tools. These dependencies can introduce vulnerabilities if not properly managed and updated.
Compliance Considerations
Regulatory Requirements: Depending on the industry and geography, ML systems may be subject to regulations such as GDPR (Europe), HIPAA (US healthcare), or CCPA (California). These laws dictate how data must be collected, processed, stored, and deleted, and often require transparency and explainability in automated decision-making.
Auditability and Traceability: Organizations must be able to demonstrate how models were trained, what data was used, and how predictions are made. This means maintaining detailed logs, versioning data and models, and documenting all changes.
Bias and Fairness: Regulatory bodies increasingly require organizations to assess and mitigate bias in automated systems. Regular audits, fairness testing, and explainability tools help ensure compliance and build trust.
Best Practices for Security and Compliance
Encrypt data and model artifacts both at rest and in transit.
Implement strict access controls for data, models, and infrastructure.
Monitor and log all access and changes to data, models, and pipelines.
Regularly update dependencies and scan for vulnerabilities in third-party libraries.
Automate compliance checks as part of the CI/CD pipeline.
Use explainability and fairness tools to detect and mitigate bias.
Maintain detailed documentation for all processes, decisions, and model versions.
The Business Value
Investing in security and compliance not only protects against risks but also builds customer trust and enables organizations to operate in regulated markets. It ensures that ML systems are robust, reliable, and ready to scale without unexpected setbacks.
Future Trends and Innovations in Managing Production ML Systems
The landscape of production machine learning is evolving rapidly, driven by advances in technology, growing business demands, and increasing regulatory scrutiny. Organizations that want to stay ahead must keep an eye on emerging trends and be ready to adapt their MLOps practices accordingly.
Key Future Trends
1. Greater Automation and Orchestration
The next generation of MLOps platforms will offer even deeper automation—from data ingestion and feature engineering to model retraining and deployment. Orchestration tools will become more intelligent, enabling seamless management of complex, multi-step ML workflows with minimal human intervention.
2. Real-Time and Streaming ML
As businesses demand faster insights, real-time and streaming machine learning will become standard. This shift requires robust infrastructure for low-latency data processing, real-time feature stores, and instant model updates, especially in industries like finance, e-commerce, and IoT.
3. Explainable and Responsible AI
With regulations tightening and public awareness growing, explainability, fairness, and transparency will be at the core of production ML systems. Tools for model interpretability, bias detection, and automated documentation will be integrated into MLOps pipelines, making it easier to meet compliance requirements and build user trust.
4. Edge and Federated Learning
The rise of edge computing and privacy concerns is pushing more ML workloads away from centralized data centers. Edge and federated learning will enable models to be trained and deployed closer to where data is generated, reducing latency and improving privacy.
5. Advanced Monitoring and Self-Healing Systems
Monitoring will go beyond simple metrics, incorporating advanced anomaly detection, root cause analysis, and self-healing capabilities. Systems will be able to automatically detect issues, roll back to previous model versions, or trigger retraining without manual intervention.
6. Cost Optimization and Green AI
As ML workloads scale, so do infrastructure costs and environmental impact. Future MLOps solutions will focus on optimizing resource usage, reducing carbon footprints, and providing tools for tracking and managing the cost and sustainability of ML operations.
7. Integration with Broader Enterprise Ecosystems
ML systems will become more tightly integrated with other enterprise platforms—such as data warehouses, business intelligence tools, and ERP systems—enabling end-to-end automation and more direct business impact.
Preparing for the Future
To stay competitive, organizations should:
Continuously evaluate and adopt new MLOps tools and practices.
Invest in upskilling teams on automation, cloud-native technologies, and responsible AI.
Build flexible, modular ML architectures that can evolve with changing requirements.
Foster a culture of collaboration between data scientists, engineers, and business stakeholders.
Summary and Key Takeaways
Managing production machine learning systems is a complex, ongoing process that extends far beyond simply deploying a model. As organizations increasingly rely on ML to drive business value, the importance of robust, secure, and scalable MLOps practices continues to grow.
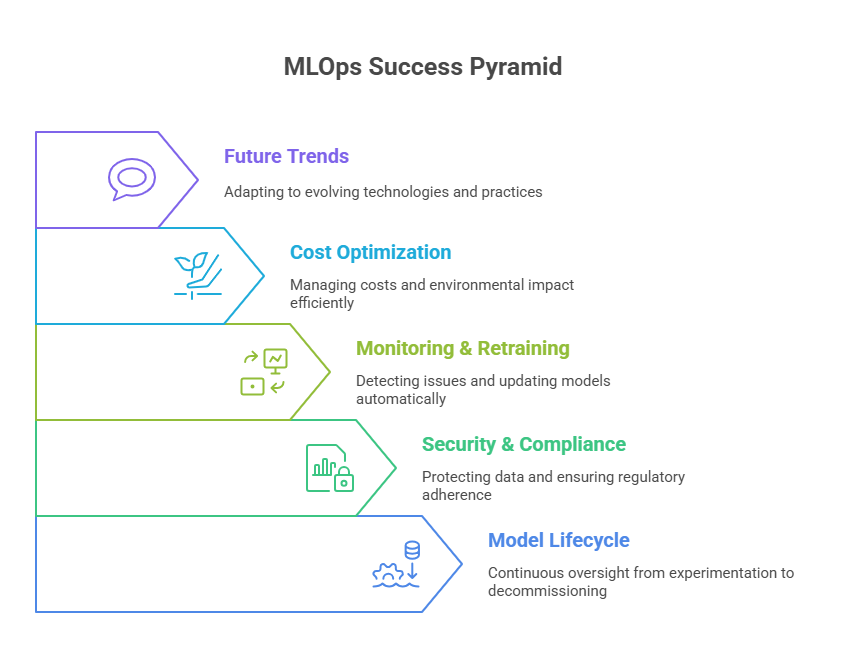
Throughout this guide, we’ve explored the essential components of modern MLOps in production environments:
Model Lifecycle Management: Effective MLOps requires continuous oversight of the entire model lifecycle—from experimentation and deployment to monitoring, retraining, and decommissioning. Automation and orchestration are crucial for maintaining model performance and reliability over time.
Security and Compliance: Protecting data, models, and infrastructure is non-negotiable. Implementing strong security measures and ensuring compliance with relevant regulations not only mitigates risk but also builds trust with customers and stakeholders.
Monitoring and Automated Retraining: Ongoing monitoring of model performance and data quality enables early detection of issues such as data drift or performance degradation. Automated retraining pipelines help keep models accurate and relevant in dynamic environments.
Cost Optimization and Sustainability: As ML systems scale, managing costs and environmental impact becomes increasingly important. Future-ready MLOps solutions will focus on resource efficiency and green AI practices.
Future Trends: The field is rapidly evolving, with trends like real-time ML, explainable AI, edge computing, and advanced monitoring shaping the next generation of production ML systems.
Key Takeaways
MLOps is not a one-time effort but a continuous process that requires collaboration between data scientists, engineers, and business teams.
Automation, transparency, and strong governance are the foundations of successful production ML.
Security, compliance, and responsible AI practices are essential for sustainable and trustworthy machine learning operations.
Staying informed about new tools, technologies, and best practices is critical for maintaining a competitive edge.
By embracing these principles, organizations can unlock the full potential of machine learning, delivering reliable, scalable, and impactful solutions that drive real business value.
MLOps in the Cloud: Tools and Strategies
MLOps: Automated Anomaly Detection in Live Data
Advanced feature stores: Architecture, monitoring, and cost optimization