
Introduction: The Role of Feature Engineering in MLOps
Feature engineering is a cornerstone of successful machine learning projects, and its importance only grows in the context of MLOps. While powerful algorithms and scalable infrastructure are essential, the quality and relevance of features often determine the ultimate performance of a model. In MLOps, where the goal is to operationalize and scale machine learning across an organization, feature engineering becomes a systematic and collaborative process rather than a one-off experiment.
In traditional data science workflows, feature engineering is often performed manually and tailored to a specific dataset or problem. However, in MLOps, features must be reproducible, versioned, and shareable across teams and projects. This shift requires new tools and practices, such as feature stores and automated feature pipelines, to ensure consistency and efficiency. Moreover, as models are deployed and retrained in production, ongoing monitoring of feature quality and relevance is crucial to maintain model performance over time.
Ultimately, robust feature engineering in MLOps bridges the gap between raw data and actionable insights, enabling organizations to build high-performance models that deliver real business value.
Key Principles of Effective Feature Engineering
Effective feature engineering in MLOps is guided by several key principles that help ensure features are not only useful for model training but also maintainable and scalable in production environments.
First, reproducibility is essential. Every transformation applied to raw data must be documented and automated so that features can be consistently regenerated as data evolves. This includes using code-based pipelines, version control, and clear metadata for each feature.
Second, collaboration and reusability are important. Features should be designed and stored in a way that allows multiple teams to access and reuse them across different projects. Feature stores play a critical role here, serving as centralized repositories that manage feature definitions, versions, and access controls.
Third, robustness and quality must be prioritized. Features should be engineered to handle missing values, outliers, and data drift. Regular validation and monitoring help ensure that features remain relevant and reliable as new data arrives.
Fourth, scalability is key. Feature engineering processes should be able to handle large volumes of data and adapt to changing requirements. This often involves leveraging distributed computing frameworks and automating feature generation and selection.
Finally, alignment with business objectives ensures that engineered features capture the most relevant information for the problem at hand. Close collaboration between data scientists, domain experts, and MLOps engineers helps identify features that drive meaningful outcomes.
Automating Feature Engineering in MLOps Pipelines
Automating feature engineering is a key step in making machine learning workflows more efficient, scalable, and reliable within MLOps. Manual feature engineering, while powerful for prototyping, can become a bottleneck as projects grow and move into production. Automation addresses this by standardizing feature creation, reducing human error, and enabling rapid iteration.
In practice, automated feature engineering involves building pipelines that transform raw data into model-ready features using code and configuration rather than ad hoc scripts. Tools such as Apache Airflow, Kubeflow Pipelines, and MLflow can orchestrate these processes, ensuring that every transformation is tracked, versioned, and reproducible. Automated pipelines can include steps for data cleaning, encoding categorical variables, generating interaction terms, scaling numerical features, and more.
Another important aspect is the use of feature engineering libraries and frameworks, such as Featuretools or scikit-learn’s Pipeline and ColumnTransformer. These tools allow data scientists and engineers to define reusable feature transformations that can be applied consistently across datasets and projects. Automation also makes it easier to retrain models with updated data, as the same feature engineering steps can be applied without manual intervention.
By automating feature engineering, organizations can accelerate experimentation, reduce operational risk, and ensure that models deployed in production are always using the most up-to-date and relevant features. This is especially important in dynamic environments where data changes frequently and models need to adapt quickly.
Feature Stores: Centralizing and Reusing Features
Feature stores have emerged as a foundational component of modern MLOps architectures, addressing the challenges of feature management, reuse, and consistency. A feature store is a centralized repository that stores, manages, and serves features for machine learning models, both during training and inference.
The primary benefit of a feature store is reusability. Once a feature is engineered and validated, it can be registered in the feature store and made available to other teams and projects. This reduces duplication of effort, ensures consistency across models, and accelerates the development of new solutions. Feature stores also support versioning, so teams can track changes to feature definitions and roll back to previous versions if needed.
Another key advantage is consistency between training and serving. Feature stores provide APIs that allow models to access the exact same feature transformations in production as were used during training, minimizing the risk of data leakage or training-serving skew. This is crucial for maintaining model performance and reliability after deployment.
Feature stores also enhance governance and monitoring. They enable organizations to track feature usage, monitor data quality, and enforce access controls, which is especially important in regulated industries. Popular open-source and commercial feature stores include Feast, Tecton, and Databricks Feature Store, each offering integration with common data platforms and MLOps tools.
Handling Categorical, Numerical, and Text Features
Different types of features require different preprocessing approaches to be effectively used in machine learning models. Here’s a comprehensive example of handling various feature types using Python:
python
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
class FeatureProcessor:
def __init__(self):
self.numerical_features = []
self.categorical_features = []
self.text_features = []
self.preprocessor = None
def setup_preprocessing(self, numerical_features, categorical_features, text_features):
"""Setup preprocessing pipeline for different feature types"""
self.numerical_features = numerical_features
self.categorical_features = categorical_features
self.text_features = text_features
# Define preprocessing steps for each feature type
numeric_transformer = Pipeline(steps=[
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(handle_unknown='ignore', sparse=False))
])
text_transformer = Pipeline(steps=[
('tfidf', TfidfVectorizer(
max_features=1000,
stop_words='english',
ngram_range=(1, 2)
))
])
# Combine all transformers
self.preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, self.numerical_features),
('cat', categorical_transformer, self.categorical_features),
('text', text_transformer, self.text_features)
])
def process_features(self, df):
"""Process all features using the defined pipeline"""
return self.preprocessor.fit_transform(df)
@staticmethod
def handle_missing_values(df):
"""Handle missing values for different feature types"""
# Fill numerical missing values with median
numerical_cols = df.select_dtypes(include=['int64', 'float64']).columns
df[numerical_cols] = df[numerical_cols].fillna(df[numerical_cols].median())
# Fill categorical missing values with mode
categorical_cols = df.select_dtypes(include=['object']).columns
df[categorical_cols] = df[categorical_cols].fillna(df[categorical_cols].mode().iloc[0])
return df
# Example usage
if __name__ == "__main__":
# Sample data
data = {
'age': [25, 30, np.nan, 45],
'income': [50000, 60000, 75000, np.nan],
'category': ['A', 'B', np.nan, 'A'],
'text_description': [
'This is a sample text',
'Another example',
'More text data',
np.nan
]
}
df = pd.DataFrame(data)
# Initialize processor
processor = FeatureProcessor()
# Handle missing values
df = processor.handle_missing_values(df)
# Setup preprocessing
processor.setup_preprocessing(
numerical_features=['age', 'income'],
categorical_features=['category'],
text_features=['text_description']
)
# Process features
processed_features = processor.process_features(df)
print("Processed features shape:", processed_features.shape)Feature Selection and Dimensionality Reduction Techniques
Feature selection and dimensionality reduction are crucial for building efficient and interpretable models. Here’s an implementation of various techniques:
python
from sklearn.feature_selection import SelectKBest, f_classif, mutual_info_classif
from sklearn.decomposition import PCA
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
class FeatureSelector:
def __init__(self):
self.selected_features = None
self.feature_importance = None
def statistical_selection(self, X, y, method='f_classif', k=10):
"""Select features using statistical tests"""
if method == 'f_classif':
selector = SelectKBest(score_func=f_classif, k=k)
elif method == 'mutual_info':
selector = SelectKBest(score_func=mutual_info_classif, k=k)
X_selected = selector.fit_transform(X, y)
self.selected_features = selector.get_support()
return X_selected
def pca_reduction(self, X, n_components=0.95):
"""Reduce dimensionality using PCA"""
pca = PCA(n_components=n_components)
X_reduced = pca.fit_transform(X)
# Plot explained variance ratio
plt.figure(figsize=(10, 6))
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.xlabel('Number of Components')
plt.ylabel('Cumulative Explained Variance Ratio')
plt.title('PCA Components vs Explained Variance')
plt.show()
return X_reduced
def importance_based_selection(self, X, y, n_features=10):
"""Select features based on importance scores"""
rf = RandomForestClassifier(n_estimators=100)
rf.fit(X, y)
self.feature_importance = pd.Series(
rf.feature_importances_,
index=X.columns
).sort_values(ascending=False)
# Plot feature importance
plt.figure(figsize=(12, 6))
self.feature_importance[:n_features].plot(kind='bar')
plt.title('Feature Importance Scores')
plt.xlabel('Features')
plt.ylabel('Importance')
plt.tight_layout()
plt.show()
return X[self.feature_importance[:n_features].index]
# Example usage
if __name__ == "__main__":
# Generate sample data
from sklearn.datasets import make_classification
X, y = make_classification(
n_samples=1000,
n_features=20,
n_informative=10,
n_redundant=5
)
X = pd.DataFrame(X, columns=[f'feature_{i}' for i in range(X.shape[1])])
# Initialize selector
selector = FeatureSelector()
# Statistical selection
X_statistical = selector.statistical_selection(X, y, method='f_classif', k=10)
# PCA reduction
X_pca = selector.pca_reduction(X, n_components=0.95)
# Importance-based selection
X_importance = selector.importance_based_selection(X, y, n_features=10)
print("Original features:", X.shape[1])
print("Features after statistical selection:", X_statistical.shape[1])
print("Features after PCA:", X_pca.shape[1])
print("Features after importance selection:", X_importance.shape[1])These implementations provide a comprehensive framework for handling different types of features and selecting the most relevant ones for your models. The code includes:
A FeatureProcessor class for handling different feature types
Automated missing value handling
Standardized preprocessing pipelines
A FeatureSelector class implementing multiple feature selection methods
Visualization capabilities for feature importance and PCA analysis
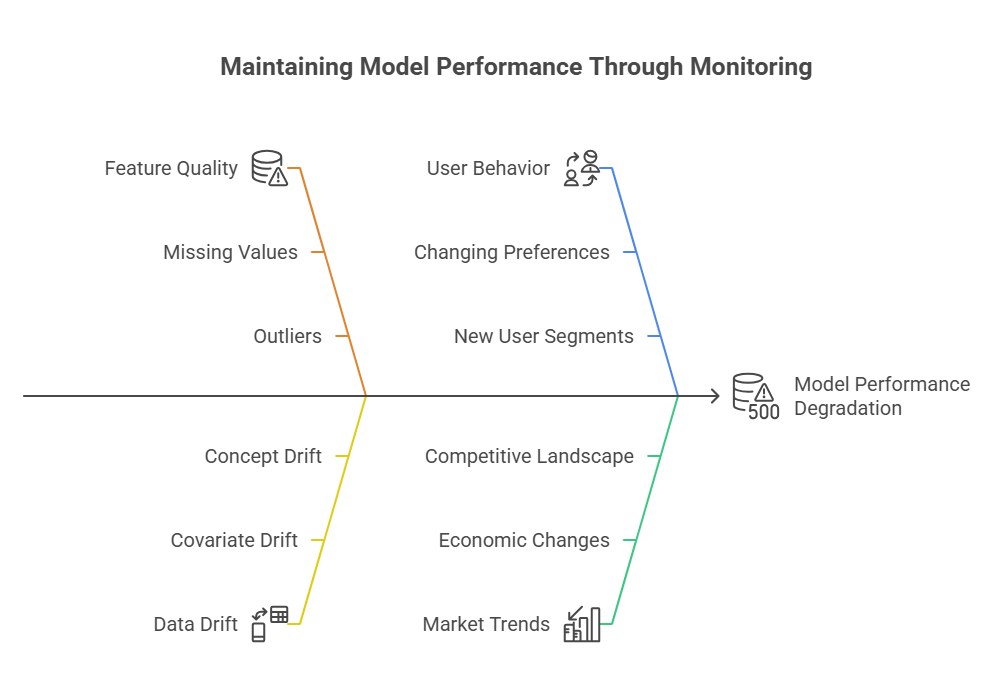
Monitoring Feature Quality and Data Drift in Production
Once a machine learning model is deployed, monitoring the quality of features and detecting data drift become essential for maintaining model performance and reliability. Feature quality monitoring involves tracking statistics such as missing values, outliers, and distribution changes in the input data. If the characteristics of features in production start to differ significantly from those seen during training, the model’s predictions may become less accurate or even unreliable.
Data drift refers to changes in the statistical properties of input data over time. This can happen due to evolving user behavior, market trends, or changes in data collection processes. There are several types of drift, including covariate drift (changes in feature distributions), prior probability shift (changes in class distribution), and concept drift (changes in the relationship between features and target). Early detection of drift allows teams to investigate, retrain, or update models before performance degrades.
Modern MLOps platforms and open-source tools like Evidently AI, WhyLabs, and Arize AI provide dashboards and automated alerts for monitoring feature statistics and drift. These tools can compare real-time or batch data distributions to reference distributions from training, using statistical tests such as the Kolmogorov-Smirnov test or Population Stability Index (PSI). Integrating such monitoring into the MLOps pipeline ensures that issues are detected early and addressed proactively, reducing the risk of business impact from model failures.
Case Studies: Feature Engineering Success Stories
Feature engineering has played a pivotal role in the success of many real-world machine learning projects. For example, in the financial sector, a leading bank improved its credit scoring models by engineering features that captured customer transaction patterns, such as rolling averages of account balances and frequency of large withdrawals. By automating the creation and monitoring of these features in their MLOps pipeline, the bank was able to quickly adapt to changing customer behavior and regulatory requirements, resulting in more accurate risk assessments and reduced loan defaults.
In e-commerce, a global retailer used feature stores to centralize and reuse features like user purchase history, product popularity, and time since last purchase across multiple recommendation systems. This not only accelerated the development of new models but also ensured consistency in customer experience across different channels. Automated monitoring of feature quality and drift helped the retailer maintain high recommendation accuracy even as product catalogs and user preferences evolved.
Another example comes from healthcare, where a hospital network engineered features from electronic health records, such as trends in vital signs and medication changes, to predict patient readmissions. By integrating feature engineering and monitoring into their MLOps workflow, the hospital could rapidly deploy updated models as new data became available, improving patient outcomes and operational efficiency.
Best Practices and Recommendations for Feature Engineering in MLOps
Feature engineering in the context of MLOps is not just about creating new variables—it’s about building a sustainable, collaborative, and production-ready process. To achieve this, several best practices have emerged from industry experience.
First, always prioritize reproducibility. Every transformation, from raw data to final features, should be implemented in code and version-controlled. This ensures that features can be regenerated for retraining, debugging, or auditing purposes. Using tools like feature stores and pipeline orchestration frameworks helps maintain this reproducibility across teams and projects.
Second, focus on collaboration and reusability. Centralizing feature definitions in a feature store allows different teams to share and reuse features, reducing duplication of effort and ensuring consistency across models. Documenting feature logic and maintaining clear metadata further supports collaboration.
Third, implement continuous monitoring of feature quality and data drift. Automated monitoring tools should be integrated into the MLOps pipeline to track feature distributions, detect anomalies, and alert teams to potential issues. This proactive approach helps maintain model performance and reliability in changing environments.
Fourth, ensure alignment with business objectives. Work closely with domain experts to design features that capture the most relevant information for the problem at hand. Regularly review and update features as business needs evolve.
Finally, invest in automation. Automate as much of the feature engineering process as possible, from data extraction and transformation to validation and monitoring. This not only accelerates development but also reduces the risk of human error and operational bottlenecks.
By following these best practices, organizations can build robust, scalable, and maintainable feature engineering workflows that support the full machine learning lifecycle in production.
Conclusion: The Impact of Feature Engineering on Business Value
Feature engineering is a critical driver of machine learning success, especially in production environments managed by MLOps practices. Well-designed features can dramatically improve model accuracy, robustness, and interpretability, directly impacting business outcomes such as revenue growth, cost reduction, and risk mitigation.
Incorporating feature engineering into the MLOps pipeline ensures that features are not only effective but also reproducible, shareable, and continuously monitored. This enables organizations to respond quickly to changes in data, business requirements, or regulatory environments, maintaining the relevance and reliability of their AI solutions.
Future Directions in Feature Engineering for MLOps
The landscape of feature engineering is rapidly evolving, especially as organizations mature in their adoption of MLOps. Looking ahead, several trends and innovations are shaping the future of this field.
One of the most significant directions is the increasing automation of feature engineering. Tools and platforms are emerging that leverage machine learning itself to suggest, generate, and even select features automatically. Automated Feature Engineering (AutoFE) solutions, often integrated with AutoML platforms, can analyze raw data and propose complex feature transformations that might be missed by human experts. This not only accelerates experimentation but also democratizes access to advanced machine learning for teams with varying levels of expertise.
Another important trend is the integration of real-time feature pipelines. As more applications require instant predictions—such as fraud detection, personalized recommendations, or dynamic pricing—feature engineering must support low-latency, streaming data. Modern feature stores and data platforms are increasingly designed to handle both batch and real-time feature computation, ensuring that models always receive up-to-date information.
Feature governance and compliance are also gaining prominence. With growing regulatory scrutiny around AI, organizations must ensure that features are explainable, auditable, and free from bias. This is driving the adoption of tools that track feature lineage, monitor for drift and fairness, and provide detailed documentation for every feature used in production.
The future will also see greater collaboration between data scientists, engineers, and domain experts. Feature engineering is becoming a more collaborative process, supported by shared repositories, standardized templates, and integrated communication tools. This helps bridge the gap between technical teams and business stakeholders, ensuring that engineered features align closely with business goals.
Finally, the rise of generative AI and foundation models is influencing feature engineering practices. As large language models and multimodal systems become more prevalent, feature engineering is expanding to include embeddings, vector representations, and hybrid features that combine structured and unstructured data. This opens new possibilities for capturing complex patterns and relationships in data.
MLOps in the Era of Generative Artificial Intelligence: New Challenges and Opportunities
From Jupyter Notebook to the Cloud: MLOps Step by Step
Monitoring ML models in production: tools, challenges, and best practices