

1. Introduction to MLOps: From Code to Production
In the rapidly evolving world of artificial intelligence and machine learning, building a high-performing model is only the beginning. The real challenge lies in efficiently moving that model from the development environment to production, where it can deliver real value to users and businesses. This transition is often fraught with obstacles, including reproducibility issues, deployment complexities, and the need for continuous monitoring and updates.
MLOps, short for Machine Learning Operations, is a set of practices and tools designed to streamline and automate the entire machine learning lifecycle. By integrating principles from software engineering, DevOps, and data science, MLOps enables teams to collaborate more effectively, reduce manual errors, and accelerate the journey from code to production. For developers, adopting MLOps means not only writing better code but also ensuring that models are robust, scalable, and maintainable in real-world scenarios.
2. Why MLOps Matters for Developers
For developers working with machine learning, the traditional workflow often ends with a trained model and a Jupyter notebook full of results. However, deploying and maintaining that model in a production environment introduces a new set of challenges. These include version control for both code and data, reproducibility of experiments, automated testing, scalable deployment, and ongoing monitoring for model drift or performance degradation.
MLOps addresses these challenges by providing a structured framework and a suite of tools that automate repetitive tasks, enforce best practices, and facilitate collaboration between data scientists, engineers, and operations teams. With MLOps, developers can:
- Track and manage different versions of datasets, code, and models, ensuring that experiments are reproducible and auditable.
- Automate the process of training, testing, and deploying models, reducing the risk of human error and speeding up release cycles.
- Monitor models in production to detect issues early, such as data drift or unexpected drops in performance, and trigger automated retraining or rollback procedures.
- Collaborate more effectively with other team members by using standardized workflows and shared tools.
In summary, MLOps empowers developers to deliver machine learning solutions that are not only innovative but also reliable, scalable, and ready for real-world use. By embracing MLOps, developers can bridge the gap between experimentation and production, unlocking the full potential of their machine learning projects.
3. Key Challenges in Deploying Machine Learning Models
Deploying machine learning models into production is a complex process that goes far beyond simply writing code or training a model. Developers and data scientists often encounter several significant challenges that can slow down or even block the transition from research to real-world application.
One of the main challenges is reproducibility. In machine learning, results can vary depending on the data version, code changes, or even the environment in which the model is trained. Without proper version control for both code and data, it becomes difficult to reproduce experiments or debug issues that arise after deployment.
Another critical issue is scalability. A model that works well on a small dataset or in a local environment may not perform efficiently when exposed to large-scale, real-time data in production. Developers must ensure that their models and pipelines can handle increased loads, integrate with existing systems, and maintain low latency.
Monitoring and maintenance are also essential. Once a model is deployed, its performance can degrade over time due to changes in the underlying data—a phenomenon known as data drift. Without continuous monitoring, it’s easy to miss these changes, leading to poor predictions and business outcomes. Automated monitoring tools and alerting systems are necessary to detect and respond to such issues promptly.
Collaboration between teams is another challenge. Machine learning projects often involve data scientists, software engineers, and operations specialists. Without standardized workflows and tools, communication gaps can lead to misunderstandings, duplicated work, or deployment delays.
Finally, security and compliance must be considered. Models often process sensitive data, so it’s crucial to implement robust security measures and ensure compliance with relevant regulations, such as GDPR.
Addressing these challenges requires a combination of best practices, automation, and the right set of MLOps tools. By understanding and preparing for these obstacles, developers can create machine learning solutions that are not only effective but also reliable and sustainable in production environments.
4. Essential MLOps Tools Overview
The MLOps ecosystem is rich with tools designed to address the unique challenges of deploying, managing, and maintaining machine learning models in production. These tools help automate repetitive tasks, ensure reproducibility, and streamline collaboration between teams. Below, we present an overview of the most important categories of MLOps tools and their key functionalities.
4.1. Version Control for Data and Models
Version control is fundamental in software development, and it’s equally important in machine learning. Tools like DVC (Data Version Control) and Git allow teams to track changes not only in code but also in datasets and model files. This ensures that every experiment is reproducible and that previous versions can be restored if needed. With proper version control, developers can collaborate more effectively, avoid data inconsistencies, and maintain a clear history of all changes.
4.2. Experiment Tracking and Reproducibility
Experiment tracking tools help data scientists and developers log, compare, and reproduce their experiments. Solutions such as MLflow, Weights & Biases, and Neptune.ai provide interfaces for recording parameters, metrics, artifacts, and results of each run. This makes it easy to identify the best-performing models, understand the impact of different hyperparameters, and share findings with the team. Experiment tracking is crucial for transparency and continuous improvement in machine learning projects.
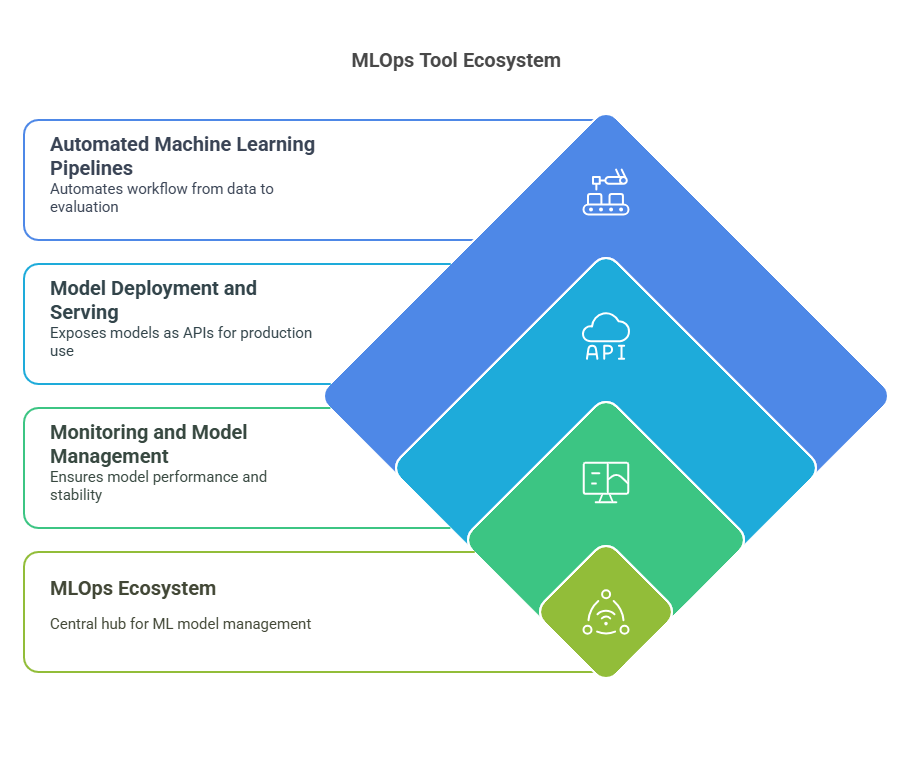
4.3. Automated Machine Learning Pipelines
Automating the machine learning workflow—from data preprocessing to model training and evaluation—saves time and reduces the risk of human error. Tools like Kubeflow, TensorFlow Extended (TFX), and Apache Airflow enable developers to define, schedule, and manage complex ML pipelines. These platforms support modular pipeline components, making it easier to update or reuse parts of the workflow and ensuring consistency across different environments.
4.4. Model Deployment and Serving
Deploying models into production requires robust and scalable serving solutions. Tools such as Seldon Core, TensorFlow Serving, and TorchServe allow developers to expose trained models as APIs, manage multiple versions, and scale deployments based on demand. These tools often integrate with container orchestration platforms like Kubernetes, enabling seamless scaling and management of model endpoints.
4.5. Monitoring and Model Management
Once a model is live, continuous monitoring is essential to ensure it performs as expected. Monitoring tools like Prometheus, Evidently AI, and Fiddler track key metrics such as latency, throughput, and prediction accuracy. They also help detect data drift, anomalies, or performance degradation. Model management platforms provide dashboards for tracking deployed models, managing versions, and automating retraining or rollback processes when issues are detected.
By leveraging these essential MLOps tools, developers can build robust, scalable, and maintainable machine learning systems that deliver consistent value in production environments.
5. Top MLOps Tools for Developers
Choosing the right MLOps tools can significantly accelerate the machine learning workflow, improve collaboration, and ensure reliable deployment of models. Below are some of the most popular and effective MLOps tools that every developer should consider.
5.1. MLflow
MLflow is an open-source platform designed to manage the complete machine learning lifecycle. It offers four main components: tracking experiments, packaging code into reproducible runs, sharing and deploying models, and managing model versions. MLflow integrates easily with popular ML libraries and frameworks, making it a flexible choice for teams using different technologies. Its user-friendly interface allows developers to log parameters, metrics, and artifacts, compare results, and deploy models to various environments.
5.2. Kubeflow
Kubeflow is a powerful MLOps platform built on top of Kubernetes. It enables the orchestration of complex machine learning workflows, from data preprocessing to model training and deployment. Kubeflow supports scalable, distributed training and provides tools for experiment tracking, hyperparameter tuning, and model serving. Its modular architecture allows teams to customize pipelines and integrate with other cloud-native tools, making it ideal for organizations that require scalability and flexibility.
5.3. DVC (Data Version Control)
DVC brings version control to data and machine learning models, extending the capabilities of Git. With DVC, developers can track changes in datasets, model files, and experiments, ensuring full reproducibility. DVC also supports data sharing and collaboration, making it easier to manage large files and remote storage. By integrating seamlessly with existing Git workflows, DVC helps teams maintain a clear history of all changes and simplifies the process of rolling back to previous versions.
5.4. TFX (TensorFlow Extended)
TensorFlow Extended (TFX) is an end-to-end platform for deploying production-ready machine learning pipelines. Developed by Google, TFX is optimized for TensorFlow models but can be adapted for other frameworks. It provides components for data validation, transformation, model training, evaluation, and serving. TFX emphasizes automation, scalability, and reliability, making it a strong choice for organizations looking to operationalize ML at scale.
5.5. Metaflow
Metaflow is a human-friendly framework developed by Netflix to help scientists and engineers build and manage real-life data science projects. Metaflow simplifies the process of designing, executing, and scaling ML workflows. It supports versioning, experiment tracking, and seamless integration with cloud services. With its intuitive Python API, Metaflow allows developers to focus on building models while handling infrastructure and orchestration in the background.
These tools represent the foundation of a modern MLOps stack, each addressing specific needs in the machine learning lifecycle. By adopting solutions like MLflow, Kubeflow, DVC, TFX, and Metaflow, developers can streamline their workflows, improve reproducibility, and ensure that their models are ready for production deployment.
5.6. Weights & Biases
Weights & Biases (W&B) is a popular platform for experiment tracking, model management, and collaboration in machine learning projects. W&B allows developers to log and visualize metrics, hyperparameters, and artifacts in real time, making it easy to compare different runs and share results with teammates. The platform integrates seamlessly with major ML frameworks such as TensorFlow, PyTorch, and Keras. Its dashboard provides interactive reports, enabling teams to monitor training progress, analyze model performance, and maintain a complete history of experiments. W&B also supports dataset versioning and model registry, which are essential for reproducibility and production deployment.
5.7. Seldon Core
Seldon Core is an open-source platform for deploying, scaling, and managing machine learning models on Kubernetes. It enables developers to package models from any framework (such as scikit-learn, TensorFlow, or PyTorch) and deploy them as REST or gRPC microservices. Seldon Core supports advanced deployment patterns, including A/B testing, canary releases, and multi-armed bandits, which help optimize model performance in production. The platform also provides monitoring, logging, and security features, making it a robust solution for organizations that require scalable and reliable model serving.
5.8. Airflow
Apache Airflow is a powerful workflow orchestration tool widely used in data engineering and MLOps. Airflow allows developers to define, schedule, and monitor complex machine learning pipelines as Directed Acyclic Graphs (DAGs). With Airflow, teams can automate tasks such as data preprocessing, model training, evaluation, and deployment. Its modular architecture and extensive library of operators make it easy to integrate with various data sources, cloud services, and ML frameworks. Airflow’s monitoring and alerting capabilities help ensure that pipelines run reliably and that any issues are quickly detected and resolved.
By incorporating tools like Weights & Biases, Seldon Core, and Apache Airflow into their MLOps stack, developers can further enhance experiment tracking, model deployment, and workflow automation, ensuring a smooth and efficient path from code to production.
6. How to Choose the Right MLOps Tool for Your Project
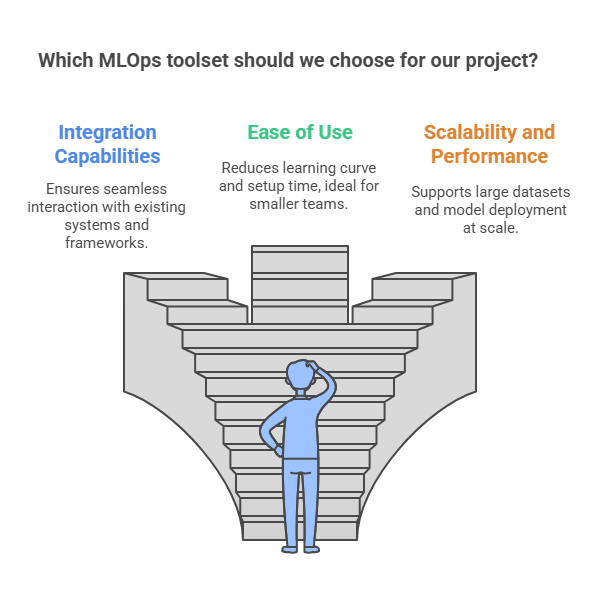
Selecting the right MLOps toolset is a crucial decision that can impact the efficiency, scalability, and maintainability of your machine learning projects. The choice depends on several factors, including the size of your team, the complexity of your workflows, your preferred programming languages and frameworks, and your infrastructure (cloud, on-premises, or hybrid).
First, consider the integration capabilities of the tool. It should work seamlessly with your existing data sources, ML frameworks (such as TensorFlow, PyTorch, or scikit-learn), and deployment environments. Tools that offer flexible APIs and support for popular platforms will be easier to adopt and scale.
Next, evaluate the ease of use and learning curve. Some tools, like Metaflow or MLflow, are designed to be user-friendly and require minimal setup, making them ideal for smaller teams or those new to MLOps. Others, such as Kubeflow or TFX, offer advanced features and scalability but may require more expertise and resources to implement.
Scalability and performance are also key considerations. If you anticipate handling large datasets or deploying models at scale, choose tools that support distributed computing, containerization, and orchestration (e.g., Kubernetes-based solutions like Kubeflow or Seldon Core).
Don’t overlook community support and documentation. Open-source tools with active communities and comprehensive documentation can help you troubleshoot issues and stay up to date with best practices.
Finally, consider your security and compliance requirements. If your models process sensitive data, ensure the tool provides robust access controls, audit trails, and compliance features.
By carefully assessing these factors, you can select an MLOps toolset that aligns with your project’s needs and sets your team up for long-term success.
7. Best Practices for Integrating MLOps Tools
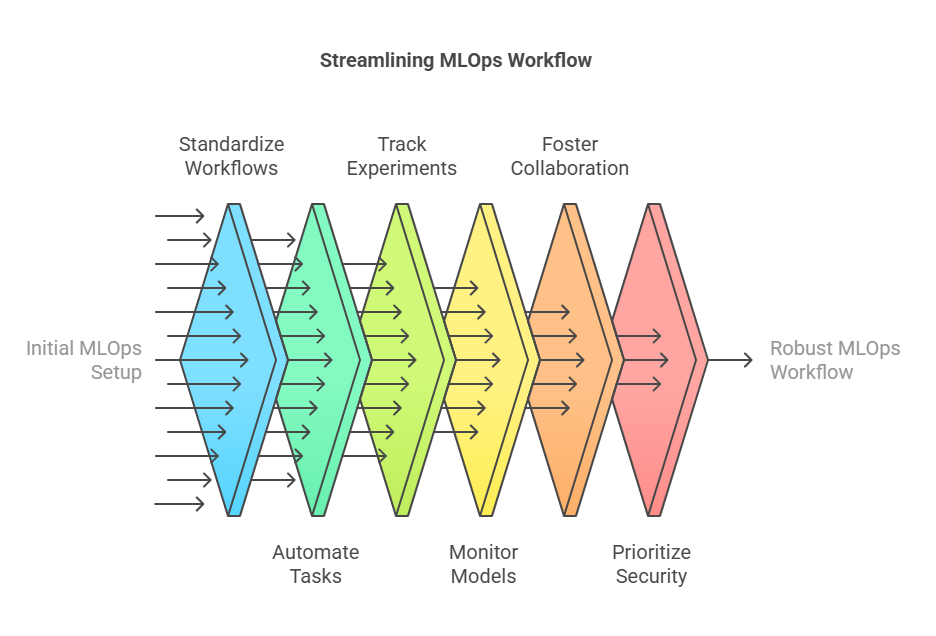
Successfully integrating MLOps tools into your workflow requires more than just installing software—it involves adopting best practices that promote collaboration, automation, and reliability.
Start by standardizing your workflows. Define clear processes for data collection, preprocessing, model training, evaluation, and deployment. Use version control for both code and data to ensure reproducibility and traceability.
Automate repetitive tasks wherever possible. Leverage pipeline orchestration tools like Airflow or Kubeflow to automate data ingestion, model training, testing, and deployment. Automation reduces manual errors and accelerates the development cycle.
Implement robust experiment tracking. Use tools such as MLflow or Weights & Biases to log parameters, metrics, and artifacts for every experiment. This makes it easier to compare results, reproduce successful runs, and share insights with your team.
Monitor models in production continuously. Set up monitoring tools to track model performance, detect data drift, and trigger alerts or retraining workflows when necessary. This ensures your models remain accurate and reliable over time.
Foster collaboration by encouraging shared ownership of pipelines, documentation, and experiment results. Use platforms that support team-based access and provide dashboards for transparency.
Finally, prioritize security and compliance. Regularly review access controls, audit logs, and data handling practices to protect sensitive information and meet regulatory requirements.
By following these best practices, you can maximize the value of your MLOps tools, streamline your machine learning operations, and deliver robust, production-ready models efficiently.
8. Example: Building a Simple MLOps Pipeline in Python
To illustrate how MLOps tools can streamline the machine learning workflow, let’s walk through a simple example of building and tracking a machine learning pipeline using Python and MLflow.
Suppose you want to train a classification model on the popular Iris dataset, track your experiments, and save the best model for deployment. With MLflow, you can easily log parameters, metrics, and artifacts for each run.
Here’s a sample Python code demonstrating this process:
import mlflow import mlflow.sklearn from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score
Load data
iris = load_iris() X_train, X_test, y_train, y_test = train_test_split( iris.data, iris.target, test_size=0.2, random_state=42 )
Start MLflow experiment
mlflow.set_experiment(„Iris_Classification”)
with mlflow.start_run(): # Model parameters n_estimators = 100 max_depth = 3
# Train modelclf = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth, random_state=42)clf.fit(X_train, y_train)y_pred = clf.predict(X_test)acc = accuracy_score(y_test, y_pred)# Log parameters and metricsmlflow.log_param("n_estimators", n_estimators)mlflow.log_param("max_depth", max_depth)mlflow.log_metric("accuracy", acc)# Log modelmlflow.sklearn.log_model(clf, "model")print(f"Model accuracy: {acc:.2f}")With this pipeline, every experiment is automatically tracked in MLflow, making it easy to compare results, reproduce runs, and deploy the best model. This approach can be extended with more advanced tools like DVC for data versioning, Airflow for pipeline orchestration, or Seldon Core for scalable model serving.
9. Conclusion: Accelerating ML Projects with MLOps
MLOps has become an essential discipline for any team aiming to deliver reliable, scalable, and maintainable machine learning solutions. By leveraging the right tools and best practices, developers can automate repetitive tasks, ensure reproducibility, and bridge the gap between experimentation and production.
The adoption of MLOps tools such as MLflow, Kubeflow, DVC, TFX, Metaflow, Weights & Biases, Seldon Core, and Airflow empowers teams to collaborate more effectively, monitor models in real time, and respond quickly to changes in data or business requirements. As a result, machine learning projects become more robust, efficient, and impactful.
In summary, investing in MLOps is not just about technology—it’s about building a culture of continuous improvement, transparency, and operational excellence in machine learning. By following the strategies and examples outlined in this guide, developers can confidently take their models from code to production and unlock the full potential of AI in their organizations.
10. Further Resources and References
To deepen your understanding of MLOps and explore the tools discussed in this article, here are some valuable resources and references:
- MLflow Documentation: https://www.mlflow.org/docs/latest/index.html – Official documentation for MLflow, covering experiment tracking, model management, and deployment.
- Kubeflow Documentation: https://www.kubeflow.org/docs/ – Comprehensive guide to Kubeflow, including installation, pipeline creation, and component development.
- DVC (Data Version Control) Documentation: https://dvc.org/doc – Detailed documentation for DVC, explaining how to version control data and models.
- TensorFlow Extended (TFX) Documentation: https://www.tensorflow.org/tfx – Official documentation for TFX, covering the end-to-end machine learning pipeline.
- Metaflow Documentation: https://metaflow.org/ – User guide and API reference for Metaflow, a human-friendly framework for data science projects.
- Weights & Biases Documentation: https://docs.wandb.ai/ – Documentation for Weights & Biases, a platform for experiment tracking and model management.
- Seldon Core Documentation: https://docs.seldon.io/projects/seldon-core/en/latest/ – Guide to Seldon Core, an open-source platform for deploying machine learning models on Kubernetes.
- Apache Airflow Documentation: https://airflow.apache.org/docs/ – Official documentation for Apache Airflow, a workflow orchestration tool.
- These resources will help you stay informed about the latest developments in MLOps and implement best practices in your machine learning projects.
MLOps in Practice – How to Automate the Machine Learning Model Lifecycle
MLOps for Developers – A Guide to Modern Workflows
Understanding MLOps: Transforming Business Operations Through Machine Learning