

Introduction to MLOps
MLOps, short for Machine Learning Operations, is rapidly becoming an essential discipline for organizations that want to scale their machine learning (ML) initiatives. As the demand for AI-driven solutions grows, developers are increasingly expected to understand not only how to build models, but also how to deploy, monitor, and maintain them in production environments. This article introduces the fundamentals of MLOps, explores the evolution of machine learning workflows, and explains why MLOps is crucial for modern developers.
1.1 What is MLOps?
MLOps is a set of practices that combines machine learning, software engineering, and DevOps principles to streamline the end-to-end lifecycle of ML models. The goal of MLOps is to automate and standardize processes such as data preparation, model training, deployment, monitoring, and retraining. By applying automation and best practices, MLOps helps teams deliver reliable, scalable, and reproducible machine learning solutions.
At its core, MLOps addresses the unique challenges of ML projects, such as managing large datasets, tracking experiments, handling model versioning, and ensuring that models perform well in production. It bridges the gap between data science and IT operations, enabling seamless collaboration and faster delivery of ML-powered applications.
1.2 The Evolution of Machine Learning Workflows
Traditional machine learning workflows were often ad hoc and manual. Data scientists would experiment with different models on their local machines, and once a promising model was found, it would be handed off to engineers for deployment. This handoff process was slow, error-prone, and difficult to reproduce, leading to issues such as „works on my machine” syndrome and model drift in production.
As organizations began to scale their ML efforts, the need for more robust and automated workflows became clear. The adoption of DevOps in software engineering inspired similar practices in the ML domain, giving rise to MLOps. Modern ML workflows now emphasize automation, collaboration, and continuous integration/continuous delivery (CI/CD) for models. This evolution has enabled teams to iterate faster, reduce operational risks, and maintain high-quality ML systems.
1.3 Why MLOps Matters for Developers
For developers, understanding MLOps is no longer optional—it’s a necessity. As ML models become integral to business operations, developers are expected to contribute to the entire ML lifecycle, from data ingestion to model deployment and monitoring. MLOps empowers developers to:
Collaborate effectively with data scientists and operations teams by using standardized tools and processes.
Automate repetitive tasks, such as model training and deployment, freeing up time for innovation.
Ensure that models are reproducible, auditable, and compliant with organizational and regulatory requirements.
Monitor models in production to detect issues like data drift or performance degradation, enabling timely retraining and updates.
By adopting MLOps practices, developers can help their organizations unlock the full potential of machine learning, delivering reliable and scalable AI solutions that drive real business value.
Example: Simple MLOps Workflow in Python
Below is a basic example of how you might automate a simple ML workflow using Python. This script demonstrates data loading, model training, saving, and loading using scikit-learn and joblib—a foundation for more advanced MLOps pipelines.
python
Copy Code
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import joblib
# Load data
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = pd.Series(iris.target)
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train model
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Save model
joblib.dump(model, 'iris_model.pkl’)
# Load model and predict
loaded_model = joblib.load(’iris_model.pkl’)
predictions = loaded_model.predict(X_test)
# Evaluate
accuracy = accuracy_score(y_test, predictions)
print(f”Model accuracy: {accuracy:.2f}”)
This example can be extended with experiment tracking, automated testing, and deployment scripts as you build more sophisticated MLOps workflows.
Key Concepts and Principles of MLOps
As machine learning becomes a core part of modern software systems, understanding the foundational concepts and principles of MLOps is essential for developers. MLOps is not just about deploying models; it’s about creating robust, scalable, and maintainable workflows that bridge the gap between data science and production engineering. In this section, we’ll explore the differences between DevOps and MLOps, the core principles that guide MLOps practices, and the typical lifecycle of an MLOps project.
2.1 DevOps vs. MLOps
DevOps revolutionized software development by promoting collaboration between development and operations teams, automating deployments, and ensuring continuous integration and delivery (CI/CD). However, machine learning introduces unique challenges that go beyond traditional software engineering.
While DevOps focuses on code, MLOps must also manage data, model artifacts, and experiments. In MLOps, the workflow includes not only building and deploying code, but also handling data versioning, model training, validation, and monitoring. Unlike static software, ML models can degrade over time due to changes in data (data drift) or the environment (concept drift), requiring ongoing monitoring and retraining.
In summary, MLOps extends DevOps by adding processes and tools for managing the entire machine learning lifecycle, from data preparation to model retirement.
2.2 Core Principles of MLOps
MLOps is guided by several key principles that ensure the reliability, scalability, and efficiency of ML systems:
Automation: Automate repetitive tasks such as data preprocessing, model training, testing, and deployment. Automation reduces human error and accelerates the delivery of ML solutions.
Reproducibility: Ensure that experiments, models, and results can be reliably reproduced. This involves tracking code, data, parameters, and environment configurations.
Collaboration: Foster seamless collaboration between data scientists, developers, and operations teams. Shared tools, version control, and clear communication are essential.
Continuous Integration and Delivery (CI/CD): Apply CI/CD practices to ML workflows, enabling frequent and reliable updates to models and pipelines.
Monitoring and Feedback: Continuously monitor models in production for performance, data drift, and anomalies. Use feedback loops to trigger retraining or updates as needed.
Scalability: Design workflows and infrastructure that can scale with growing data volumes, model complexity, and user demand.
These principles help organizations build robust ML systems that can adapt to changing requirements and environments.
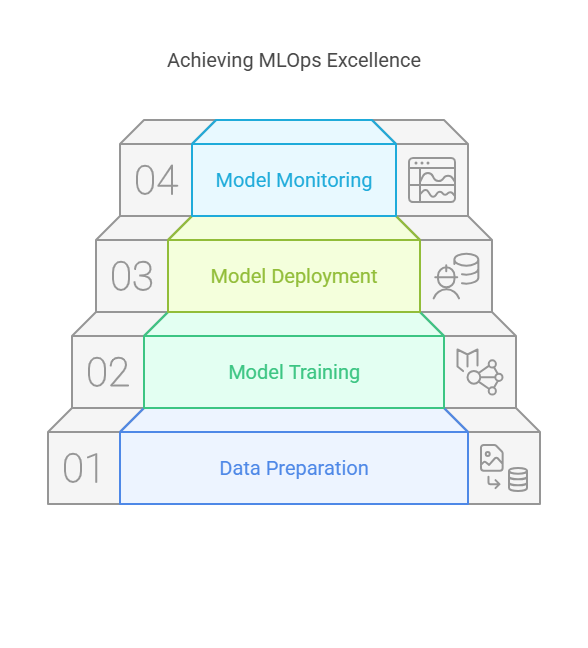
2.3 The MLOps Lifecycle
The MLOps lifecycle encompasses all stages of an ML project, from initial data collection to model retirement. Understanding this lifecycle is crucial for building effective workflows:
Data Collection and Preparation: Gather, clean, and preprocess data. This stage often involves data versioning and validation to ensure quality and consistency.
Model Development: Experiment with different algorithms, features, and hyperparameters. Track experiments and results for reproducibility.
Model Validation: Evaluate model performance using appropriate metrics and validation techniques. Ensure the model meets business and technical requirements.
Model Deployment: Package and deploy the model to production environments. This may involve containerization, API development, and integration with existing systems.
Monitoring and Maintenance: Continuously monitor the model’s performance in production. Detect data drift, performance degradation, or anomalies, and trigger retraining or updates as needed.
Model Retirement: When a model is no longer effective or relevant, retire it from production and archive its artifacts for compliance and auditing.
By following the MLOps lifecycle, teams can deliver machine learning solutions that are reliable, maintainable, and aligned with business goals.
Example: Tracking Experiments and Model Versions in Python
A key principle of MLOps is reproducibility. Tools like MLflow can help you track experiments, parameters, and model versions. Here’s a simple example using MLflow:
python
Copy Code
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load data
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=42)
# Start MLflow experiment
mlflow.set_experiment(„Iris_Classification”)
with mlflow.start_run():
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
# Log parameters and metrics
mlflow.log_param(„n_estimators”, 100)
mlflow.log_metric(„accuracy”, accuracy)
# Log the model
mlflow.sklearn.log_model(model, „model”)
print(f”Logged model with accuracy: {accuracy:.2f}”)
This script logs the model, parameters, and accuracy, making it easy to reproduce and compare experiments—an essential part of any MLOps workflow.
Setting Up Your MLOps Environment
A well-structured MLOps environment is the foundation for building, deploying, and maintaining robust machine learning solutions. For developers, setting up this environment means choosing the right tools, establishing best practices for infrastructure management, and ensuring that both code and data are versioned and reproducible. In this section, we’ll cover the essential components of an MLOps environment, including tools and platforms, infrastructure as code, and version control for both code and data.
3.1 Tools and Platforms Overview
The MLOps ecosystem is rich with tools and platforms designed to streamline every stage of the machine learning lifecycle. Choosing the right stack depends on your team’s needs, project scale, and existing infrastructure. Some of the most popular categories and examples include:
Experiment Tracking: Tools like MLflow, Weights & Biases, and Neptune help track experiments, parameters, and results, making it easier to reproduce and compare models.
Data Versioning: DVC (Data Version Control) and LakeFS enable versioning of datasets, ensuring that data used for training and testing is consistent and auditable.
Model Serving: TensorFlow Serving, TorchServe, and Seldon Core provide scalable ways to deploy and serve models in production.
Pipeline Orchestration: Kubeflow, Airflow, and Prefect help automate and manage complex ML workflows, from data ingestion to model deployment.
Cloud Platforms: AWS SageMaker, Google Vertex AI, and Azure ML offer end-to-end managed services for ML development, deployment, and monitoring.
Selecting and integrating these tools into your workflow is a critical first step in building a reliable MLOps environment.
3.2 Infrastructure as Code
Infrastructure as Code (IaC) is a practice that allows you to define and manage your infrastructure using code, rather than manual processes. This approach brings consistency, repeatability, and scalability to your ML projects. With IaC, you can automate the provisioning of servers, storage, networking, and other resources required for data processing, model training, and deployment.
Popular IaC tools include Terraform, AWS CloudFormation, and Ansible. These tools let you describe your infrastructure in configuration files, which can be versioned, reviewed, and reused across projects and environments.
Example: Simple Terraform Script for AWS EC2 Instance
hcl
Copy Code
provider „aws” {
region = „us-west-2”
}
resource „aws_instance” „ml_server” {
ami = „ami-0abcdef1234567890”
instance_type = „t2.medium”
tags = {
Name = „ML-Server”
}
}
This script defines an EC2 instance for ML workloads. By using IaC, you can quickly spin up or tear down environments as needed, supporting agile experimentation and scaling.
3.3 Version Control for Code and Data
Version control is a cornerstone of modern software development, and it’s equally important in MLOps. For code, Git remains the industry standard, enabling collaboration, branching, and history tracking. However, ML projects also require versioning of data and model artifacts, which can be large and change frequently.
Code Versioning: Use Git to manage source code, configuration files, and scripts. Platforms like GitHub, GitLab, and Bitbucket provide additional collaboration features.
Data Versioning: Tools like DVC or LakeFS integrate with Git to track changes in datasets and model files. This ensures that every experiment can be traced back to the exact data and code used, supporting reproducibility and compliance.
Example: Using DVC for Data Versioning in Python
bash
Copy Code
# Initialize DVC in your project
dvc init
# Add a dataset to DVC tracking
dvc add data/train.csv
# Commit changes to Git
git add data/train.csv.dvc .gitignore
git commit -m „Track training data with DVC”
With DVC, you can version large datasets alongside your code, making it easy to reproduce experiments and collaborate with teammates.
Data Management in MLOps
Effective data management is at the heart of every successful machine learning project. In MLOps, data is not just an input—it is a dynamic asset that must be carefully collected, versioned, validated, and monitored throughout the entire ML lifecycle. Proper data management ensures reproducibility, model reliability, and compliance with organizational and regulatory standards. In this section, we’ll explore the key aspects of data management in MLOps: data collection and ingestion, data versioning and lineage, and data validation and quality assurance.
4.1 Data Collection and Ingestion
The first step in any ML workflow is gathering and ingesting data from various sources. This process can involve structured data from databases, unstructured data from logs or text files, and real-time data streams from sensors or APIs. In MLOps, it’s crucial to automate and document the data ingestion process to ensure consistency and traceability.
Automated data pipelines, built with tools like Apache Airflow or Prefect, can schedule and orchestrate data collection tasks. These pipelines can handle data extraction, transformation, and loading (ETL), making it easier to manage large and complex datasets. By automating data ingestion, teams can reduce manual errors and ensure that models are always trained on up-to-date and reliable data.
Example: Simple Data Ingestion Pipeline in Python
python
Copy Code
import pandas as pd
def fetch_data(source_url):
data = pd.read_csv(source_url)
# Data transformation steps can be added here
return data
data_url = „https://example.com/dataset.csv”
df = fetch_data(data_url)
df.to_csv(„data/raw_data.csv”, index=False)
print(„Data ingested and saved.”)
This script demonstrates a basic automated data ingestion process, which can be extended with scheduling and monitoring for production use.
4.2 Data Versioning and Lineage
As datasets evolve, it’s essential to track changes and maintain a clear lineage of how data has been collected, processed, and used in experiments. Data versioning allows teams to reproduce results, audit data usage, and roll back to previous versions if needed.
Tools like DVC (Data Version Control) and LakeFS integrate with Git to provide version control for large datasets and data pipelines. Data lineage tools, such as OpenLineage or Apache Atlas, help visualize and document the flow of data through various processing stages, ensuring transparency and compliance.
Example: Data Versioning with DVC
bash
Copy Code
# Initialize DVC in your project
dvc init
# Add a new version of your dataset
dvc add data/raw_data.csv
# Commit changes to Git
git add data/raw_data.csv.dvc .gitignore
git commit -m „Add new version of raw data”
With data versioning and lineage tracking, you can always trace which data was used for a specific model or experiment, supporting reproducibility and accountability.
4.3 Data Validation and Quality Assurance
High-quality data is critical for building reliable machine learning models. Data validation involves checking datasets for errors, inconsistencies, missing values, and anomalies before they are used for training or inference. Automated data validation tools, such as Great Expectations or TensorFlow Data Validation, can be integrated into data pipelines to enforce quality standards.
Quality assurance processes may include schema validation, statistical checks, and custom business rules. By catching data issues early, teams can prevent downstream problems and ensure that models are trained on trustworthy data.
Example: Data Validation with Great Expectations
python
Copy Code
import great_expectations as ge
# Load data
df = ge.read_csv(„data/raw_data.csv”)
# Define expectations
df.expect_column_values_to_not_be_null(„age”)
df.expect_column_values_to_be_between(„salary”, min_value=30000, max_value=200000)
# Validate data
results = df.validate()
print(results)
This example shows how to automate data quality checks, making it easier to maintain high standards and avoid costly errors in production.
Model Development Workflows in MLOps
Model development is a core phase in the machine learning lifecycle, where ideas are transformed into working models ready for deployment. In MLOps, this process is not just about building accurate models, but also about ensuring that development is collaborative, reproducible, and automated. This section explores the essential components of modern model development workflows: experiment tracking, collaborative development, and reproducibility with automation.
5.1 Experiment Tracking
Experiment tracking is the process of systematically recording the details of each model training run, including parameters, code versions, data versions, metrics, and results. Without proper tracking, it becomes difficult to reproduce results, compare models, or understand why a particular model performs better than others.
Tools like MLflow, Weights & Biases, and Neptune make experiment tracking easy and efficient. They allow developers to log hyperparameters, metrics, artifacts, and even visualizations for every experiment. This not only improves transparency but also accelerates model selection and optimization.
Example: Tracking Experiments with MLflow in Python
python
Copy Code
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load data
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=42)
# Start MLflow experiment
mlflow.set_experiment(„Iris_Classification”)
with mlflow.start_run():
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
# Log parameters and metrics
mlflow.log_param(„n_estimators”, 100)
mlflow.log_metric(„accuracy”, accuracy)
# Log the model
mlflow.sklearn.log_model(model, „model”)
print(f”Logged model with accuracy: {accuracy:.2f}”)
This script logs all relevant information for each experiment, making it easy to compare and reproduce results.
5.2 Collaborative Development
Machine learning projects often require close collaboration between data scientists, machine learning engineers, and software developers. Collaborative development ensures that everyone can contribute to the project, share insights, and build on each other’s work.
Version control systems like Git are essential for managing code, while tools like DVC or LakeFS help version data and model artifacts. Shared experiment tracking platforms and documentation further enhance collaboration. Code reviews, pair programming, and regular communication are also important practices.
Collaboration is not limited to code and data. It also involves sharing best practices, reusable components, and feedback on model performance. This collective approach leads to higher-quality models and more efficient workflows.
5.3 Reproducibility and Automation
Reproducibility means that anyone can rerun an experiment and obtain the same results, given the same code, data, and environment. Automation ensures that repetitive tasks—such as data preprocessing, model training, and evaluation—are performed consistently and efficiently.
To achieve reproducibility, teams should:
Use version control for code, data, and model artifacts.
Track all dependencies and environment configurations (e.g., using Docker or Conda).
Automate workflows with tools like Make, Airflow, or Kubeflow Pipelines.
Automation not only saves time but also reduces human error and increases reliability. Automated pipelines can handle data ingestion, feature engineering, model training, evaluation, and even deployment, all triggered by code changes or scheduled events.
Example: Automated Model Training Pipeline with Scikit-learn and Joblib
python
Copy Code
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import joblib
# Load data
df = pd.read_csv(„data/train.csv”)
X = df.drop(„target”, axis=1)
y = df[„target”]
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train model
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
# Save model
joblib.dump(model, „models/random_forest.pkl”)
print(„Model trained and saved.”)
This script can be integrated into a larger automated pipeline, ensuring that every step is repeatable and consistent.
Continuous Integration and Continuous Delivery (CI/CD) for Machine Learning
Continuous Integration and Continuous Delivery (CI/CD) are foundational practices in modern software engineering, enabling teams to deliver high-quality software quickly and reliably. In the context of MLOps, CI/CD extends these principles to machine learning workflows, ensuring that models are built, tested, and deployed in a consistent, automated, and repeatable manner. This section explores how to build ML pipelines, automate testing for ML models, and package models for deployment using containerization.
6.1 Building ML Pipelines
An ML pipeline is a series of automated steps that take raw data through preprocessing, feature engineering, model training, evaluation, and deployment. Pipelines help standardize workflows, reduce manual intervention, and make it easier to reproduce results.
Popular tools for building ML pipelines include Apache Airflow, Kubeflow Pipelines, and Prefect. These tools allow you to define, schedule, and monitor complex workflows, ensuring that each step is executed in the correct order and that dependencies are managed automatically.
Example: Simple ML Pipeline with Scikit-learn and Python Functions
python
Copy Code
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
def load_data(path):
return pd.read_csv(path)
def preprocess_data(df):
# Example preprocessing
return df.dropna()
def train_model(X_train, y_train):
model = RandomForestClassifier()
model.fit(X_train, y_train)
return model
def evaluate_model(model, X_test, y_test):
predictions = model.predict(X_test)
return accuracy_score(y_test, predictions)
# Pipeline steps
df = load_data(„data/train.csv”)
df = preprocess_data(df)
X = df.drop(„target”, axis=1)
y = df[„target”]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = train_model(X_train, y_train)
accuracy = evaluate_model(model, X_test, y_test)
print(f”Model accuracy: {accuracy:.2f}”)
This modular approach can be extended and orchestrated using pipeline tools for production environments.
6.2 Automated Testing for ML Models
Testing is a critical part of any CI/CD workflow. For ML models, testing goes beyond traditional unit and integration tests. It includes validating data quality, checking model performance, and ensuring that new models do not introduce regressions.
Automated tests can be implemented to:
Validate input data schemas and distributions.
Check that model metrics (e.g., accuracy, precision, recall) meet predefined thresholds.
Compare new models against baseline models to ensure improvements.
Test model inference speed and resource usage.
Frameworks like pytest can be used for unit testing, while custom scripts or tools like Great Expectations can automate data and model validation.
Example: Automated Model Performance Test with pytest
python
Copy Code
import pytest
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
def test_model_accuracy():
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2)
model = RandomForestClassifier()
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
assert accuracy > 0.9, „Model accuracy is below acceptable threshold”
# Run with: pytest test_model.py
This test ensures that the model meets a minimum accuracy requirement before deployment.
6.3 Model Packaging and Containerization
Once a model is trained and validated, it needs to be packaged for deployment. Containerization, using tools like Docker, allows you to bundle the model, its dependencies, and serving code into a portable unit that can run consistently across different environments.
Containerization simplifies deployment, scaling, and management of ML models in production. It also supports reproducibility and isolation, reducing the risk of environment-related issues.
Example: Dockerfile for Serving a Scikit-learn Model with Flask
dockerfile
Copy Code
FROM python:3.9
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
CMD [„python”, „serve_model.py”]
Example: Simple Flask App to Serve a Model
python
Copy Code
from flask import Flask, request, jsonify
import joblib
app = Flask(__name__)
model = joblib.load(„models/random_forest.pkl”)
@app.route(„/predict”, methods=[„POST”])
def predict():
data = request.get_json()
prediction = model.predict([data[„features”]])
return jsonify({„prediction”: int(prediction[0])})
if __name__ == „__main__”:
app.run(host=”0.0.0.0″, port=5000)
By packaging your model and serving code in a Docker container, you can deploy it to any cloud or on-premises environment with confidence.
Model Deployment Strategies in MLOps
Deploying machine learning models is a critical step in transforming data science prototypes into real-world applications that deliver business value. In MLOps, model deployment is not just about making predictions available—it’s about choosing the right deployment strategy, ensuring reliability, and monitoring models in production. This section explores the main deployment approaches, best practices, and the importance of monitoring and logging in production environments.
7.1 Batch vs. Real-Time Inference
The choice between batch and real-time inference depends on the use case, latency requirements, and system architecture.
Batch Inference involves processing large volumes of data at scheduled intervals. This approach is ideal for scenarios where immediate predictions are not required, such as generating nightly reports, scoring customer segments, or updating recommendation lists. Batch jobs can be orchestrated using tools like Apache Airflow or cloud-based workflows, and results are typically stored in databases or files for later use.
Real-Time Inference delivers predictions instantly in response to user requests or system events. This is essential for applications like fraud detection, chatbots, or personalized recommendations, where low latency is crucial. Real-time inference is often implemented as a REST API or gRPC service, using frameworks like Flask, FastAPI, or cloud-native solutions such as AWS SageMaker Endpoints or Google Vertex AI.
Example: Real-Time Inference with FastAPI
python
Copy Code
from fastapi import FastAPI
import joblib
app = FastAPI()
model = joblib.load(„models/random_forest.pkl”)
@app.post(„/predict”)
def predict(features: list):
prediction = model.predict([features])
return {„prediction”: int(prediction[0])}
This simple API can be containerized and deployed to serve real-time predictions.
7.2 Deployment Patterns and Best Practices
Successful model deployment requires careful planning and adherence to best practices to ensure reliability, scalability, and maintainability.
Common Deployment Patterns:
Blue-Green Deployment: Run two identical environments (blue and green). Deploy the new model to the green environment, test it, and then switch traffic from blue to green. This minimizes downtime and risk.
Canary Deployment: Gradually roll out the new model to a small subset of users or requests. Monitor performance before scaling up to all users. This approach helps catch issues early.
Shadow Deployment: Run the new model in parallel with the current production model, but do not use its predictions in the application. Compare outputs to validate performance before full deployment.
Best Practices:
Automate deployment with CI/CD pipelines to reduce manual errors.
Use containerization (e.g., Docker) for consistent environments.
Version models and APIs to manage updates and rollbacks.
Implement health checks and auto-scaling for high availability.
Document deployment processes and maintain clear communication between teams.
7.3 Monitoring and Logging
Once a model is deployed, continuous monitoring and logging are essential to ensure it performs as expected and to detect issues early.
Monitoring involves tracking key metrics such as prediction latency, error rates, throughput, and resource usage. More advanced monitoring includes detecting data drift (changes in input data distribution) and model drift (degradation in model performance over time). Tools like Prometheus, Grafana, and cloud-native monitoring solutions can be integrated for real-time insights.
Logging captures detailed information about requests, responses, errors, and system events. Logs are invaluable for debugging, auditing, and compliance. Centralized logging solutions like ELK Stack (Elasticsearch, Logstash, Kibana) or cloud logging services help aggregate and analyze logs efficiently.
Example: Simple Logging in a Model API
python
Copy Code
import logging
from flask import Flask, request, jsonify
import joblib
logging.basicConfig(filename=’model_api.log’, level=logging.INFO)
app = Flask(__name__)
model = joblib.load(„models/random_forest.pkl”)
@app.route(„/predict”, methods=[„POST”])
def predict():
data = request.get_json()
prediction = model.predict([data[„features”]])
logging.info(f”Input: {data[’features’]}, Prediction: {prediction[0]}”)
return jsonify({„prediction”: int(prediction[0])})
if __name__ == „__main__”:
app.run(host=”0.0.0.0″, port=5000)
This example logs every prediction request and response, supporting traceability and debugging.
Model Monitoring and Maintenance in MLOps
Deploying a machine learning model is not the end of the journey—it’s the beginning of a continuous process of monitoring, maintenance, and improvement. In production, models are exposed to real-world data and changing environments, which can lead to performance degradation over time. Effective model monitoring and maintenance are essential to ensure that models remain accurate, reliable, and aligned with business goals. This section covers performance tracking, drift detection and retraining, and the role of feedback loops and human-in-the-loop systems.
8.1 Performance Tracking
Once a model is live, it’s crucial to track its performance in real time. Performance tracking involves monitoring key metrics such as accuracy, precision, recall, F1-score, latency, and throughput. These metrics help teams detect issues early, such as drops in prediction quality or increased response times.
Performance tracking can be implemented using monitoring tools like Prometheus, Grafana, or cloud-native solutions. Metrics should be visualized on dashboards and set up with alerts to notify teams of anomalies or threshold breaches.
Example: Logging Model Performance Metrics in Python
python
Copy Code
import time
from prometheus_client import start_http_server, Summary
# Create a metric to track time spent and requests made
REQUEST_TIME = Summary(’request_processing_seconds’, 'Time spent processing request’)
@REQUEST_TIME.time()
def process_request():
# Simulate model inference
time.sleep(0.5)
if __name__ == '__main__’:
start_http_server(8000)
while True:
process_request()
This example exposes a Prometheus metric for model inference time, which can be visualized and monitored.
8.2 Drift Detection and Retraining
Over time, the data that a model sees in production may change—a phenomenon known as data drift (changes in input data distribution) or concept drift (changes in the relationship between input and output). Drift can cause model performance to degrade, making detection and retraining essential.
Drift Detection involves monitoring input data and model predictions for significant changes. Statistical tests, such as the Kolmogorov-Smirnov test, or specialized tools like Evidently AI, can be used to detect drift.
Retraining is triggered when drift is detected or when performance metrics fall below acceptable thresholds. Retraining pipelines should be automated to fetch new data, retrain the model, validate its performance, and redeploy it if it outperforms the current model.
Example: Simple Data Drift Detection with Python
python
Copy Code
import numpy as np
from scipy.stats import ks_2samp
# Simulated old and new data distributions
old_data = np.random.normal(0, 1, 1000)
new_data = np.random.normal(0.5, 1, 1000)
# Kolmogorov-Smirnov test for drift
stat, p_value = ks_2samp(old_data, new_data)
if p_value < 0.05:
print(„Data drift detected!”)
else:
print(„No significant drift detected.”)
This script checks for significant changes in data distributions, a common approach to drift detection.
8.3 Feedback Loops and Human-in-the-Loop
Feedback loops are mechanisms that use real-world outcomes to improve model performance. In many applications, user feedback or ground truth labels become available after predictions are made. Incorporating this feedback into the training data helps models adapt to changing environments and user needs.
Human-in-the-Loop (HITL) systems involve human experts in the decision-making process, especially for critical or ambiguous cases. HITL can be used for tasks like data labeling, model validation, or handling edge cases where the model’s confidence is low.
Feedback loops and HITL approaches ensure that models remain relevant, accurate, and aligned with business objectives, even as conditions change.
Example: Incorporating User Feedback for Model Retraining
python
Copy Code
import pandas as pd
# Simulate collecting user feedback
new_data = pd.DataFrame({
„feature1”: [0.2, 0.4, 0.6],
„feature2”: [1.1, 0.9, 1.3],
„label”: [1, 0, 1] # User-provided ground truth
})
# Append new data to training set and retrain model
existing_data = pd.read_csv(„data/train.csv”)
updated_data = pd.concat([existing_data, new_data], ignore_index=True)
updated_data.to_csv(„data/train_updated.csv”, index=False)
print(„Training data updated with user feedback.”)
This example demonstrates how new labeled data can be incorporated into the training set for future retraining cycles.
Security and Compliance in MLOps
As machine learning models become integral to business operations, ensuring their security and compliance is more important than ever. MLOps teams must address unique risks associated with data privacy, model integrity, and regulatory requirements. This section explores the key aspects of security and compliance in MLOps: data privacy and governance, secure model deployment, and auditing and compliance.
9.1 Data Privacy and Governance
Machine learning models often rely on sensitive data, such as personal information, financial records, or proprietary business data. Protecting this data is critical to maintaining user trust and meeting legal obligations.
Data Privacy involves implementing measures to prevent unauthorized access, leaks, or misuse of data. This includes encrypting data at rest and in transit, anonymizing or pseudonymizing personal information, and restricting access based on roles and responsibilities.
Data Governance refers to the policies and processes that ensure data is accurate, consistent, and used appropriately. Good governance includes maintaining data lineage, documenting data sources, and enforcing data retention and deletion policies. It also involves complying with regulations such as GDPR, HIPAA, or CCPA, which may require explicit user consent and the ability to delete or export user data on request.
Example: Data Encryption in Python
python
Copy Code
from cryptography.fernet import Fernet
# Generate a key and instantiate a Fernet instance
key = Fernet.generate_key()
cipher_suite = Fernet(key)
# Encrypt data
data = b”Sensitive information”
encrypted_data = cipher_suite.encrypt(data)
# Decrypt data
decrypted_data = cipher_suite.decrypt(encrypted_data)
print(decrypted_data.decode())
This example demonstrates basic encryption and decryption of sensitive data.
9.2 Secure Model Deployment
Deploying machine learning models introduces new security challenges. Attackers may attempt to steal models, manipulate predictions, or exploit vulnerabilities in the deployment infrastructure.
Best practices for secure model deployment include:
Authentication and Authorization: Restrict access to model APIs using authentication tokens, API keys, or OAuth. Ensure only authorized users and systems can interact with the model.
Network Security: Use firewalls, VPNs, and secure communication protocols (e.g., HTTPS) to protect data in transit and prevent unauthorized access.
Model Hardening: Obfuscate or encrypt model files, limit the information returned by APIs, and monitor for unusual access patterns that may indicate model extraction or adversarial attacks.
Environment Isolation: Deploy models in isolated containers or virtual machines to minimize the impact of potential breaches.
Example: Securing a Flask API with an API Key
python
Copy Code
from flask import Flask, request, jsonify, abort
app = Flask(__name__)
API_KEY = „your_secret_api_key”
@app.route(„/predict”, methods=[„POST”])
def predict():
if request.headers.get(„x-api-key”) != API_KEY:
abort(401)
# Model prediction logic here
return jsonify({„prediction”: 1})
if __name__ == „__main__”:
app.run()
This example restricts access to the prediction endpoint using a simple API key.
9.3 Auditing and Compliance
Auditing and compliance are essential for demonstrating that your ML systems meet legal, regulatory, and organizational standards. Auditing involves maintaining detailed logs of data access, model training, deployment, and prediction activities. These logs support investigations, incident response, and compliance reporting.
Compliance requires documenting processes, maintaining records of data usage and model decisions, and ensuring that all activities align with relevant regulations. Automated tools can help generate audit trails, monitor compliance, and alert teams to potential violations.
Example: Logging Access and Predictions for Auditing
python
Copy Code
import logging
from flask import Flask, request, jsonify
logging.basicConfig(filename=’audit.log’, level=logging.INFO)
app = Flask(__name__)
@app.route(„/predict”, methods=[„POST”])
def predict():
user = request.headers.get(„user-id”, „unknown”)
data = request.get_json()
# Model prediction logic here
prediction = 1
logging.info(f”User: {user}, Input: {data}, Prediction: {prediction}”)
return jsonify({„prediction”: prediction})
if __name__ == „__main__”:
app.run()
This example logs every prediction request, including user information and input data, supporting traceability and compliance.
Scaling MLOps in Production
As machine learning initiatives grow, organizations face new challenges in scaling their MLOps practices. Scaling is not just about handling more data or deploying more models—it’s about orchestrating complex workflows, managing multiple models efficiently, and optimizing costs while maintaining reliability and performance. This section explores orchestration and automation, managing multiple models, and cost optimization in production MLOps environments.
10.1 Orchestration and Automation
Orchestration and automation are essential for managing the complexity of large-scale ML systems. Orchestration tools coordinate the execution of various tasks—such as data ingestion, preprocessing, model training, evaluation, and deployment—across distributed environments.
Popular orchestration tools include:
Apache Airflow: Widely used for scheduling and managing data pipelines.
Kubeflow Pipelines: Designed specifically for ML workflows on Kubernetes.
Prefect: Flexible workflow orchestration for data and ML tasks.
Automation ensures that repetitive and error-prone tasks are handled consistently, freeing up teams to focus on innovation. Automated pipelines can be triggered by events (like new data arrival), scheduled runs, or code changes, ensuring that models are always up-to-date and reliable.
Example: Orchestrating a Simple ML Pipeline with Airflow (Python DAG)
python
Copy Code
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
def preprocess():
print(„Preprocessing data…”)
def train():
print(„Training model…”)
def deploy():
print(„Deploying model…”)
with DAG(’mlops_pipeline’, start_date=datetime(2024, 1, 1), schedule_interval=’@daily’, catchup=False) as dag:
preprocess_task = PythonOperator(task_id=’preprocess’, python_callable=preprocess)
train_task = PythonOperator(task_id=’train’, python_callable=train)
deploy_task = PythonOperator(task_id=’deploy’, python_callable=deploy)
preprocess_task >> train_task >> deploy_task
This example shows a daily scheduled pipeline with three automated steps.
10.2 Managing Multiple Models
In production, organizations often need to manage dozens or even hundreds of models, each serving different business needs or customer segments. Efficient model management involves:
Model Registry: Centralized repositories (like MLflow Model Registry or Sagemaker Model Registry) to track model versions, metadata, and deployment status.
Model Lifecycle Management: Automating the promotion, rollback, and retirement of models based on performance and business requirements.
A/B Testing and Multi-Model Serving: Running experiments with multiple models in parallel to compare performance or serve different user groups.
Example: Registering and Promoting Models with MLflow
python
Copy Code
import mlflow
import mlflow.sklearn
# Log and register a model
with mlflow.start_run():
# … train model …
mlflow.sklearn.log_model(model, „model”, registered_model_name=”CustomerChurnModel”)
mlflow.register_model(„runs:/<run_id>/model”, „CustomerChurnModel”)
This code logs a model and registers it for tracking and promotion in a model registry.
10.3 Cost Optimization
Scaling ML systems can quickly become expensive, especially with large datasets, complex models, and high infrastructure demands. Cost optimization is about balancing performance, reliability, and budget constraints.
Strategies for cost optimization include:
Resource Autoscaling: Use cloud services that automatically scale compute resources up or down based on demand.
Spot and Preemptible Instances: Leverage discounted compute resources for non-critical or batch workloads.
Efficient Data Storage: Archive or compress old data, and use tiered storage solutions to reduce costs.
Monitoring and Alerts: Track resource usage and set up alerts for unexpected spikes or underutilization.
Example: Autoscaling a Kubernetes Deployment (YAML)
yaml
Copy Code
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: ml-model-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ml-model-deployment
minReplicas: 2
maxReplicas: 10
metrics:
– type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
This configuration automatically scales the number of model-serving pods based on CPU usage.
Case Studies and Real-World Examples in MLOps
Understanding how MLOps is applied in real-world scenarios helps bridge the gap between theory and practice. Organizations of all sizes—from startups to large enterprises—are leveraging MLOps to streamline their machine learning workflows, improve collaboration, and deliver business value. In this section, we’ll explore case studies and lessons learned from startups, large enterprises, and practical experiences in the field.
11.1 MLOps in Startups
Startups often operate with limited resources and need to move quickly from idea to production. MLOps enables startups to automate repetitive tasks, iterate rapidly, and maintain agility as they scale.
Case Example:
A fintech startup wanted to deploy a credit scoring model. By adopting MLOps practices, they automated data ingestion, model training, and deployment using open-source tools like MLflow and DVC. This allowed the team to quickly retrain models as new data arrived, track experiments, and ensure reproducibility. Automated CI/CD pipelines reduced deployment time from days to hours, enabling the startup to respond rapidly to market changes.
Key Takeaways:
Automation and version control are critical for agility.
Open-source MLOps tools can provide enterprise-grade capabilities without high costs.
Early investment in reproducibility pays off as the team grows.
11.2 MLOps in Large Enterprises
Large enterprises face unique challenges, such as managing multiple teams, ensuring compliance, and scaling across departments and geographies. MLOps provides the structure and governance needed to manage these complexities.
Case Example:
A global retailer implemented MLOps to support hundreds of models for demand forecasting, inventory optimization, and personalized marketing. They used cloud-based platforms (e.g., AWS SageMaker, Azure ML) for centralized model management, automated pipelines for retraining, and robust monitoring for performance and drift detection. Strict access controls and audit trails ensured compliance with data privacy regulations.
Key Takeaways:
Centralized model registries and monitoring are essential for managing many models.
Automated retraining and drift detection maintain model accuracy at scale.
Compliance and security must be integrated into every stage of the ML lifecycle.
11.3 Lessons Learned
Real-world MLOps projects reveal valuable lessons that can guide future initiatives:
Start Simple, Scale Gradually: Begin with basic automation and tracking, then add complexity as needs grow.
Cross-Functional Collaboration: Success requires close cooperation between data scientists, engineers, and operations teams.
Monitor Everything: Continuous monitoring of data, models, and infrastructure helps catch issues early and maintain reliability.
Document and Communicate: Clear documentation and communication prevent knowledge silos and support onboarding.
Invest in Reproducibility: Being able to reproduce results is crucial for debugging, compliance, and scaling.
Example: End-to-End MLOps Workflow in Python
Below is a simplified example of an end-to-end workflow that could be adapted by teams of any size:
python
Copy Code
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import joblib
import mlflow
# Data ingestion
df = pd.read_csv(„data/train.csv”)
X = df.drop(„target”, axis=1)
y = df[„target”]
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Experiment tracking
mlflow.set_experiment(„EndToEnd_MLOps”)
with mlflow.start_run():
model = RandomForestClassifier()
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
mlflow.log_metric(„accuracy”, accuracy)
mlflow.sklearn.log_model(model, „model”)
joblib.dump(model, „models/model.pkl”)
print(f”Model trained and logged with accuracy: {accuracy:.2f}”)
Future Trends in MLOps
MLOps is a rapidly evolving field, shaped by advances in technology, changing business needs, and the growing maturity of machine learning in production. As organizations continue to scale their AI initiatives, new trends and innovations are emerging that will define the next generation of MLOps. In this section, we explore the most significant future trends: emerging tools and technologies, the role of generative AI in MLOps, and the road ahead for practitioners and organizations.
12.1 Emerging Tools and Technologies
The MLOps ecosystem is expanding with new tools and platforms designed to address the increasing complexity of machine learning workflows. Some of the most promising developments include:
Automated Machine Learning (AutoML): Tools like Google AutoML, H2O.ai, and DataRobot are making it easier to automate model selection, hyperparameter tuning, and feature engineering, reducing the need for manual intervention and accelerating experimentation.
Feature Stores: Centralized repositories for storing, sharing, and reusing features across projects (e.g., Feast, Tecton) are becoming standard, improving consistency and collaboration.
Model Monitoring and Explainability: Advanced monitoring tools (e.g., Evidently AI, Fiddler) and explainability frameworks (e.g., SHAP, LIME) are helping teams understand model behavior, detect drift, and ensure fairness and transparency.
Serverless and Edge Deployment: Serverless platforms (e.g., AWS Lambda, Google Cloud Functions) and edge AI solutions are enabling lightweight, scalable, and cost-effective model deployment closer to data sources and end users.
These innovations are making MLOps more accessible, scalable, and robust, empowering teams to deliver value faster and with greater confidence.
12.2 The Role of Generative AI in MLOps
Generative AI, powered by large language models (LLMs) and diffusion models, is transforming both the capabilities of machine learning and the way MLOps is practiced.
AI-Assisted Development: LLMs like GPT-4 can generate code, write documentation, and even design ML pipelines, reducing development time and lowering the barrier to entry for new practitioners.
Synthetic Data Generation: Generative models can create realistic synthetic datasets for training, testing, and privacy-preserving analytics, addressing data scarcity and privacy concerns.
Automated Monitoring and Remediation: Generative AI can analyze logs, detect anomalies, and suggest or even implement fixes, making monitoring and maintenance more proactive and intelligent.
Enhanced Collaboration: AI-powered tools can facilitate communication between data scientists, engineers, and business stakeholders by summarizing experiments, generating reports, and translating technical results into business insights.
As generative AI becomes more integrated into MLOps workflows, it will drive greater automation, efficiency, and innovation across the ML lifecycle.
12.3 The Road Ahead
The future of MLOps is bright, but it also presents new challenges and opportunities for organizations and practitioners:
Standardization and Best Practices: As the field matures, we can expect more standardized frameworks, benchmarks, and best practices to emerge, making it easier to adopt and scale MLOps.
Focus on Responsible AI: Ethical considerations, fairness, transparency, and regulatory compliance will become central to MLOps, requiring new tools and processes for responsible AI development and deployment.
Democratization of MLOps: With the rise of no-code/low-code platforms and AI-assisted tools, MLOps will become accessible to a broader range of users, enabling more teams to leverage machine learning.
Integration with Business Processes: MLOps will increasingly be integrated with broader business operations, supporting real-time decision-making, automation, and continuous improvement.
Example: Using Generative AI for Automated Documentation in Python
python
Copy Code
from transformers import pipeline
# Load a summarization pipeline (requires transformers library and a model)
summarizer = pipeline(„summarization”)
text = „””
This script loads data, trains a RandomForest model, evaluates accuracy, and saves the model.
It demonstrates a simple end-to-end MLOps workflow in Python.
„””
summary = summarizer(text, max_length=30, min_length=10, do_sample=False)
print(„Summary:”, summary[0][’summary_text’])
This example shows how generative AI can be used to automatically generate documentation or summaries for ML workflows.
Resources and Further Reading for MLOps
Continuous learning is essential in the fast-evolving world of MLOps. Whether you’re just starting your journey or looking to deepen your expertise, a wealth of resources is available to help you stay up to date with best practices, new tools, and real-world case studies. In this section, you’ll find recommended books and articles, online courses and communities, and open source projects that can accelerate your MLOps learning and practice.
13.1 Recommended Books and Articles
Books and in-depth articles provide foundational knowledge and practical insights from industry experts. Some of the most valuable resources include:
Books:
“Practical MLOps: How to Get Ready for Production with Machine Learning Systems” by Noah Gift, Alfredo Deza
A hands-on guide to building production-ready ML systems, covering automation, monitoring, and scaling.
“Machine Learning Engineering” by Andriy Burkov
A concise overview of the end-to-end ML engineering process, including MLOps best practices.
“Introducing MLOps” by Mark Treveil and Alok Shukla
A practical introduction to MLOps concepts, tools, and real-world applications.
“Building Machine Learning Powered Applications” by Emmanuel Ameisen
Focuses on the full lifecycle of ML projects, from prototyping to production.
Articles:
Hidden Technical Debt in Machine Learning Systems
A seminal paper on the challenges of maintaining ML systems in production.
Google Cloud’s MLOps: Continuous delivery and automation pipelines in machine learning
A comprehensive guide to implementing MLOps on Google Cloud.
13.2 Online Courses and Communities
Online courses and active communities are invaluable for hands-on learning, networking, and staying current with the latest trends.
Courses:
Coursera: MLOps (Machine Learning Operations) Specialization
A multi-course program covering the fundamentals and advanced topics in MLOps.
Udemy: MLOps – Deploy Machine Learning & Data Science Projects
Practical deployment-focused course for ML practitioners.
DataCamp: MLOps for Engineers
Focuses on engineering aspects of MLOps, including pipelines and automation.
Communities:
MLOps Community
A global community for sharing knowledge, events, and best practices.
r/MLOps on Reddit
A forum for discussions, questions, and news about MLOps.
Stack Overflow: MLOps Tag
A place to ask technical questions and find solutions.
13.3 Open Source Projects
Open source tools are the backbone of many MLOps workflows. Exploring and contributing to these projects can deepen your understanding and help you build practical skills.
Experiment Tracking and Model Management:
MLflow
An open source platform for managing the ML lifecycle, including experiment tracking, model packaging, and deployment.
Weights & Biases
A popular tool for experiment tracking and collaboration.
Data Versioning and Pipelines:
DVC (Data Version Control)
A tool for versioning datasets and managing ML pipelines.
Kubeflow
A Kubernetes-native platform for building, deploying, and managing ML workflows.
Monitoring and Validation:
Evidently AI
Open source tools for monitoring data and model quality in production.
Great Expectations
A framework for data validation and documentation.
Example: Getting Started with MLflow in Python
python
Copy Code
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load data
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=42)
# Start MLflow experiment
mlflow.set_experiment(„Iris_Classification”)
with mlflow.start_run():
model = RandomForestClassifier()
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
mlflow.log_metric(„accuracy”, accuracy)
mlflow.sklearn.log_model(model, „model”)
print(f”Model trained and logged with accuracy: {accuracy:.2f}”)
This example demonstrates how to use MLflow for experiment tracking and model management.
Appendix
The appendix provides additional resources to support your MLOps journey. Here, you’ll find a glossary of essential terms, a sample MLOps project template, and useful checklists and templates to help you implement best practices in your machine learning workflows.
14.1 Glossary of Terms
Understanding the language of MLOps is crucial for effective communication and collaboration. Here are some key terms:
MLOps: A set of practices that combines machine learning, software engineering, and DevOps to automate and manage the ML lifecycle.
CI/CD: Continuous Integration and Continuous Delivery/Deployment; practices that automate the building, testing, and deployment of code and models.
Model Drift: The degradation of model performance due to changes in data or the environment.
Data Versioning: Tracking and managing changes to datasets over time.
Model Registry: A centralized repository for storing, versioning, and managing ML models.
Feature Store: A system for storing, sharing, and reusing features across ML projects.
Pipeline Orchestration: Automating and managing the sequence of tasks in an ML workflow.
Experiment Tracking: Recording parameters, code, data, and results for each model training run.
Human-in-the-Loop (HITL): Involving human feedback or intervention in the ML process, especially for validation or labeling.
Drift Detection: Monitoring for changes in data or model performance that may require retraining.
14.2 Sample MLOps Project Template
A well-structured project template helps teams collaborate efficiently and maintain reproducibility. Below is a basic directory structure for an MLOps project:
mlops-project/
│
├── data/ # Raw and processed datasets
│ ├── raw/
│ └── processed/
│
├── notebooks/ # Jupyter notebooks for exploration and prototyping
│
├── src/ # Source code for data processing, training, and inference
│ ├── data_ingestion.py
│ ├── train.py
│ └── predict.py
│
├── models/ # Saved and versioned model artifacts
│
├── pipelines/ # Pipeline definitions (e.g., Airflow, Kubeflow)
│
├── tests/ # Unit and integration tests
│
├── requirements.txt # Python dependencies
├── dvc.yaml # DVC pipeline configuration (if using DVC)
├── Dockerfile # Containerization setup
├── README.md # Project documentation
└── .gitignore # Files and directories to ignore in version control
Example: Simple Data Ingestion Script (src/data_ingestion.py)
python
Copy Code
import pandas as pd
def ingest_data(source_url, output_path):
df = pd.read_csv(source_url)
df.to_csv(output_path, index=False)
print(f”Data saved to {output_path}”)
if __name__ == „__main__”:
ingest_data(„https://example.com/data.csv”, „data/raw/data.csv”)
14.3 Useful Checklists and Templates
Checklists and templates help ensure that best practices are followed throughout the ML lifecycle. Here are some examples:
MLOps Readiness Checklist:
Data is versioned and documented.
Code is under version control (e.g., Git).
Experiments are tracked (e.g., MLflow, Weights & Biases).
Models are stored in a registry with versioning.
Automated tests are in place for data, code, and models.
CI/CD pipelines are configured for training and deployment.
Monitoring and alerting are set up for production models.
Security and compliance requirements are addressed.
Documentation is up to date.
Model Deployment Template (Python Flask Example):
python
Copy Code
from flask import Flask, request, jsonify
import joblib
app = Flask(__name__)
model = joblib.load(„models/model.pkl”)
@app.route(„/predict”, methods=[„POST”])
def predict():
data = request.get_json()
prediction = model.predict([data[„features”]])
return jsonify({„prediction”: int(prediction[0])})
if __name__ == „__main__”:
app.run(host=”0.0.0.0″, port=5000)
Tools and Technologies in MLOps for FMCG: A Technical Guide for Developers
Leveraging MLOps in the FMCG Industry: Key Benefits, Tools, and Practical Examples