

Introduction: Why Workflow Optimization Matters in Advanced MLOps
In the rapidly evolving world of machine learning, the difference between a good ML system and a truly great one often comes down to the efficiency and reliability of its workflows. For experienced practitioners, MLOps is no longer just about getting models into production—it’s about doing so in a way that is scalable, maintainable, and cost-effective. Workflow optimization sits at the heart of this challenge.
The Stakes of Workflow Optimization
As organizations scale their machine learning initiatives, the complexity of their pipelines grows. Data flows from multiple sources, models are retrained frequently, and deployment targets can range from cloud clusters to edge devices. Without optimized workflows, teams face bottlenecks that slow down experimentation, increase operational costs, and introduce risks of errors or inconsistencies.
Optimized workflows enable teams to:
Accelerate Experimentation: By automating repetitive tasks and streamlining handoffs between data scientists, engineers, and operations, teams can iterate on ideas faster and bring innovations to market more quickly.
Reduce Operational Overhead: Efficient pipelines minimize manual interventions, lower the risk of human error, and free up experts to focus on higher-value tasks.
Ensure Consistency and Reproducibility: Well-structured workflows make it easier to track data, code, and model versions, ensuring that results can be reliably reproduced and audited.
Scale with Confidence: As data volumes and model complexity grow, optimized workflows help maintain performance and reliability without a proportional increase in resource consumption or team size.
Key Drivers for Optimization in Advanced MLOps
For expert teams, workflow optimization is driven by several factors:
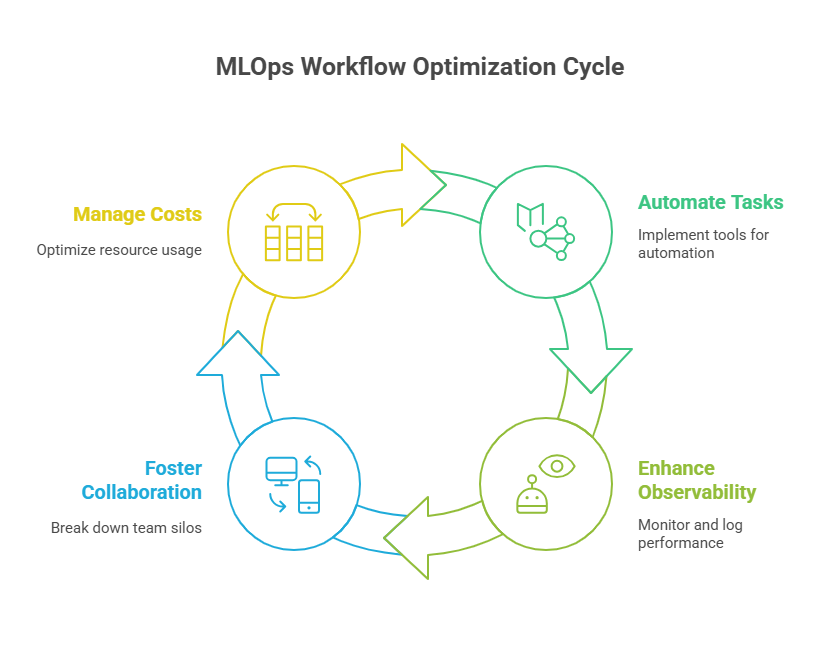
Automation: Leveraging orchestration tools, CI/CD pipelines, and Infrastructure as Code (IaC) to automate everything from data ingestion to model deployment.
Observability: Implementing robust monitoring and logging to quickly detect issues, track performance, and trigger automated responses.
Collaboration: Breaking down silos between roles and teams, often through shared platforms and standardized processes.
Cost Management: Continuously refining workflows to use resources efficiently, avoiding unnecessary compute or storage expenses.
The Path Forward
Optimizing workflows in MLOps is not a one-time effort—it’s an ongoing process of measurement, refinement, and adaptation. As new tools and best practices emerge, expert teams must stay agile, always looking for ways to remove friction and unlock greater value from their ML investments.
In the following sections, we’ll dive deeper into practical strategies, tools, and real-world examples that can help advanced practitioners take their MLOps workflows to the next level.
Identifying Bottlenecks in ML Pipelines
In advanced MLOps, the efficiency of your machine learning pipeline can make or break your ability to deliver value at scale. Bottlenecks—points in the workflow where progress slows or stalls—are common, especially as pipelines grow more complex and data volumes increase. Identifying and addressing these bottlenecks is a critical step toward workflow optimization.
Common Bottlenecks in ML Pipelines
Bottlenecks can occur at any stage of the ML lifecycle. Some of the most frequent pain points include:
Data Ingestion and Preparation: Slow data extraction, transformation, and loading (ETL) processes can delay the entire pipeline. Issues often arise from fragmented data sources, inefficient queries, or manual data cleaning steps.
Feature Engineering: Manual or poorly automated feature engineering can become a major time sink, especially when dealing with large or frequently changing datasets.
Model Training: Training complex models on large datasets can be computationally expensive and time-consuming, particularly if resources are not properly allocated or parallelization is not used.
Model Validation and Testing: Inadequate automation in validation or slow feedback loops can delay deployment and increase the risk of errors slipping into production.
Deployment and Serving: Bottlenecks here often stem from manual deployment processes, lack of containerization, or inefficient model serving infrastructure.
Monitoring and Retraining: If monitoring is not automated or retraining triggers are not wedefined, models can degrade in production without timely intervention.
Techniques for Identifying Bottlenecks
To optimize your workflow, you first need to pinpoint where delays or inefficiencies occur. Effective techniques include:
Pipeline Profiling: Use profiling tools to measure the time and resources consumed at each stage of the pipeline. This helps highlight slow steps and resource-intensive operations.
Automated Logging and Metrics: Implement detailed logging and collect metrics on data throughput, processing times, and system resource usage. Visualization tools can help spot trends and anomalies.
Feedback from Stakeholders: Regularly gather input from data scientists, engineers, and operations teams to identify pain points that may not be visible in system metrics.
Root Cause Analysis: When a bottleneck is detected, perform a systematic analysis to determine whether the issue is due to code inefficiency, infrastructure limitations, or process gaps.
The Value of Early Detection
Catching bottlenecks early allows teams to address issues before they escalate into major blockers. This proactive approach leads to:
Faster iteration cycles and reduced time-to-market
Lower operational costs by eliminating wasted resources
Improved reliability and scalability of ML systems
Conclusion
Identifying bottlenecks is a foundational skill for MLOps experts. By combining technical tools with collaborative feedback and systematic analysis, teams can continuously refine their pipelines, paving the way for more efficient, scalable, and robust machine learning operations.
Advanced Automation Techniques for Data Ingestion and Preparation
For expert MLOps teams, data ingestion and preparation are not just preliminary steps—they are critical foundations that determine the speed, reliability, and scalability of the entire machine learning workflow. As data sources multiply and datasets grow in size and complexity, manual processes quickly become unsustainable. Advanced automation techniques are essential for maintaining efficiency and consistency at scale.
Automating Data Ingestion
Modern MLOps pipelines rely on robust automation to handle data from diverse sources, such as databases, APIs, streaming platforms, and cloud storage. Key strategies include:
Event-Driven Ingestion: Leveraging event-based architectures (e.g., using tools like Apache Kafka or AWS Lambda) allows pipelines to automatically react to new data arrivals, triggering downstream processing without manual intervention.
Scheduled Batch Processing: For periodic data updates, orchestrators like Apache Airflow or Prefect can automate extraction, transformation, and loading (ETL) tasks on a defined schedule, ensuring data freshness and reliability.
Schema Validation and Data Quality Checks: Automated validation routines can check incoming data for schema consistency, missing values, or anomalies, preventing bad data from propagating through the pipeline.
Automating Data Preparation
Data preparation—cleaning, transforming, and feature engineering—often involves repetitive, error-prone tasks. Automation here not only saves time but also ensures reproducibility and quality. Techniques include:
Reusable Transformation Pipelines: Tools like scikit-learn’s Pipeline, TensorFlow Transform, or Spark MLlib enable the creation of modular, reusable data transformation workflows that can be versioned and shared across projects.
Automated Feature Engineering: Libraries such as Featuretools or custom scripts can automatically generate new features, select relevant ones, and encode categorical variables, reducing manual effort and standardizing feature sets.
Data Versioning: Integrating data versioning tools (e.g., DVC, LakeFS) ensures that every dataset used in training or inference is tracked, making experiments reproducible and auditable.
Example: Automated Data Ingestion and Preparation Pipeline
Here’s a simplified example using Python and Apache Airflow to automate data ingestion and preparation:
python
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
def ingest_data():
# Example: Download data from an API or database
pass
def validate_data():
# Example: Check for missing values or schema mismatches
pass
def prepare_data():
# Example: Clean, transform, and save data for ML
pass
with DAG('ml_data_pipeline', start_date=datetime(2024, 1, 1), schedule_interval='@daily') as dag:
ingest = PythonOperator(task_id='ingest_data', python_callable=ingest_data)
validate = PythonOperator(task_id='validate_data', python_callable=validate_data)
prepare = PythonOperator(task_id='prepare_data', python_callable=prepare_data)
ingest >> validate >> prepareThis pipeline ingests, validates, and prepares data automatically on a daily schedule, reducing manual intervention and ensuring consistency.
Benefits of Advanced Automation
By automating data ingestion and preparation, expert teams achieve:
Faster, more reliable data flows
Reduced risk of human error
Consistent, reproducible datasets for model training
Scalability to handle growing data volumes and sources
Conclusion
Advanced automation in data ingestion and preparation is a cornerstone of optimized MLOps workflows. By investing in robust, modular, and scalable automation, organizations empower their teams to focus on higher-level challenges—ultimately accelerating innovation and improving the quality of machine learning solutions.
Feature Engineering at Scale: Best Practices and Tools
Feature engineering is often described as the “art” of machine learning, but at scale, it becomes a science of process, automation, and collaboration. For advanced MLOps teams, the challenge is not just to create powerful features, but to do so efficiently, reproducibly, and in a way that supports rapid experimentation and robust production deployments.
The Challenges of Feature Engineering at Scale
As organizations grow, so do their data sources, teams, and use cases. This introduces several challenges:
Data Silos: Features are often created in isolation by different teams, leading to duplication and inconsistencies.
Reproducibility: Without standardized processes, it’s difficult to reproduce features across environments or over time.
Performance: Feature computation can become a bottleneck, especially with large datasets or real-time requirements.
Collaboration: Sharing and reusing features across projects and teams is often manual and error-prone.
Best Practices for Scalable Feature Engineering
To address these challenges, expert teams adopt several best practices:
Centralized Feature Store: Implementing a feature store (such as Feast, Tecton, or Vertex AI Feature Store) allows teams to register, discover, and reuse features across projects. This ensures consistency and reduces duplication.
Modular Pipelines: Building feature engineering pipelines as modular, reusable components (using tools like scikit-learn Pipelines, Spark, or Kubeflow) makes it easier to maintain and scale transformations.
Versioning and Lineage: Tracking versions of features and their data lineage ensures that models can be reproduced and audited, which is critical for compliance and debugging.
Automated Testing: Integrating unit and integration tests for feature pipelines helps catch errors early and maintain data quality.
Monitoring Feature Quality: Continuously monitoring feature distributions and statistics in production helps detect data drift or quality issues before they impact model performance.
Tools for Feature Engineering at Scale
Several tools and platforms support scalable feature engineering:
Feast: An open-source feature store that enables teams to manage, serve, and monitor features for both batch and real-time use cases.
Tecton: A managed feature platform that automates feature pipelines, monitoring, and governance.
Spark MLlib: For distributed feature engineering on large datasets.
scikit-learn Pipelines: For modular, reusable feature transformations in Python.
TensorFlow Transform: For scalable, production-ready feature engineering in TensorFlow workflows.
Example: Using Feast for Feature Management
Here’s a simple example of defining and registering features in Feast:
python
from feast import FeatureStore, Entity, FeatureView, Field
from feast.types import Float32
# Define an entity
driver = Entity(name="driver_id", join_keys=["driver_id"])
# Define a feature view
driver_stats_view = FeatureView(
name="driver_stats",
entities=[driver],
schema=[
Field(name="avg_daily_trips", dtype=Float32),
Field(name="rating", dtype=Float32),
],
online=True,
batch_source=...,
tags={"team": "mlops"},
)
# Register the feature view
fs = FeatureStore(repo_path=".")
fs.apply([driver, driver_stats_view])This approach allows features to be defined once and reused across training and serving, ensuring consistency and scalability.
Data Lineage, Versioning, and Governance in Advanced Feature Stores
As machine learning systems mature and scale, the need for transparency, reproducibility, and control over data and features becomes paramount. Data lineage, versioning, and governance are foundational pillars in advanced feature stores, ensuring that every feature used in a model can be traced, audited, and managed throughout its lifecycle.
Why Data Lineage Matters
Data lineage refers to the ability to track the origin, movement, and transformation of data as it flows through the ML pipeline. In the context of feature stores, lineage answers questions like:
Where did this feature come from?
What raw data and transformations produced it?
Which models and predictions depend on it?
Clear lineage is essential for debugging, compliance (e.g., GDPR, HIPAA), and understanding the impact of data changes on downstream models.
Feature and Data Versioning
Versioning is the practice of tracking changes to datasets, features, and even transformation logic over time. In advanced feature stores, this means:
Every feature definition (including transformation code) is versioned, so teams can reproduce past experiments or roll back to previous states.
Data snapshots are stored, allowing models to be trained and evaluated on exactly the same data as before.
Model-to-feature mappings are maintained, so it’s always clear which version of a feature was used in a given model.
Tools like DVC, LakeFS, and built-in versioning in feature stores (e.g., Feast, Tecton) make this process manageable and auditable.
Governance: Policies, Access, and Compliance
Governance in feature stores covers the policies and controls that ensure data is used responsibly and securely. This includes:
Access Control: Defining who can create, modify, or use specific features, often integrated with enterprise identity systems.
Audit Trails: Maintaining logs of all changes, accesses, and usage of features for compliance and security reviews.
Data Quality Policies: Enforcing rules for feature validation, freshness, and deprecation to prevent stale or low-quality data from affecting models.
Compliance Management: Supporting regulatory requirements by making it easy to trace, audit, and, if necessary, delete data related to individuals or sensitive use cases.
Example: Tracking Lineage and Versioning in Feast
Here’s a conceptual example of how lineage and versioning might be managed in a feature store like Feast:
python
from feast import FeatureStore
fs = FeatureStore(repo_path=".")
# Retrieve feature metadata, including lineage and version info
feature_metadata = fs.get_feature_view("driver_stats").to_proto()
print("Feature View Name:", feature_metadata.spec.name)
print("Source Table:", feature_metadata.spec.batch_source.table)
print("Transformation Logic:", feature_metadata.spec.batch_source.data_source_options)
print("Version:", feature_metadata.meta.created_timestamp)This allows teams to programmatically inspect where features come from, how they’re built, and which version is in use.
The Business Value
Strong lineage, versioning, and governance practices in feature stores deliver:
Reproducibility: Every model can be traced back to the exact data and features used, supporting reliable experimentation and deployment.
Trust and Transparency: Stakeholders can understand and trust the data powering ML models.
Risk Reduction: Compliance and audit requirements are met, reducing legal and operational risks.
Integrating Feature Stores with MLOps Pipelines
Feature stores are most powerful when seamlessly integrated into the broader MLOps pipeline, enabling automation, reproducibility, and collaboration across the machine learning lifecycle. For advanced teams, this integration is not just about connecting tools—it’s about building a unified, automated system where features flow smoothly from raw data to production models.
Why Integration Matters
Without tight integration, feature engineering can become a bottleneck, leading to duplicated work, inconsistent features between training and serving, and slow iteration cycles. Integrating feature stores with MLOps pipelines ensures that:
Features are defined, validated, and served consistently across environments.
Data scientists and engineers can collaborate efficiently, reusing features and sharing best practices.
Automation reduces manual errors and accelerates the path from experimentation to deployment.
Key Integration Points
Automated Data Ingestion:
Feature stores should connect directly to data sources (databases, data lakes, streams) and automate the ingestion and transformation of raw data into features. Orchestration tools like Airflow, Kubeflow Pipelines, or Prefect can schedule and monitor these processes.
Reproducible Feature Engineering:
By versioning feature definitions and transformation logic, feature stores ensure that the same features can be recreated for both training and inference, supporting reproducibility and auditability.
Seamless Model Training:
ML pipelines can pull features directly from the feature store, guaranteeing that the data used for training matches what will be available in production. This eliminates “training-serving skew.”
Automated Model Deployment:
When a model is deployed, the serving infrastructure can fetch features in real time or batch from the feature store, ensuring low-latency and up-to-date predictions.
Monitoring and Feedback Loops:
Integrated monitoring tracks feature freshness, data drift, and quality, triggering alerts or automated retraining when issues are detected.
Example: Integrating Feast with a Kubeflow Pipeline
Here’s a conceptual example of how a feature store (Feast) might be integrated into a Kubeflow pipeline for automated training and deployment:
python
# Pseudocode for a Kubeflow pipeline step using Feast
from feast import FeatureStore
def fetch_features_for_training():
fs = FeatureStore(repo_path=".")
# Pull features for training set
training_df = fs.get_historical_features(
entity_df=...,
features=[
"driver_stats:avg_daily_trips",
"driver_stats:rating"
]
).to_df()
# Save or pass to next pipeline step
training_df.to_csv("/mnt/data/training_features.csv", index=False)# This function would be called as a step in a Kubeflow pipeline
This approach ensures that the same feature logic is used in both training and serving, and that the process is fully automated and reproducible.
Best Practices
Use Orchestration: Automate feature ingestion, transformation, and validation with workflow orchestrators.
Version Everything: Track versions of features, data, and transformation code for full reproducibility.
Monitor Continuously: Integrate monitoring to detect data drift, feature staleness, and quality issues.
Promote Collaboration: Use the feature store as a central hub for sharing and reusing features across teams.
Monitoring, Logging, and Automated Retraining in Production
In modern MLOps, deploying a machine learning model is just the beginning. The real challenge—and value—lies in maintaining, monitoring, and continuously improving models in production. This is where robust monitoring, comprehensive logging, and automated retraining pipelines become essential.
Why Monitoring and Logging Matter
Once a model is live, its environment is dynamic: data distributions can shift, user behavior may change, and external factors can impact predictions. Without proper monitoring, a model’s performance can silently degrade, leading to poor business outcomes or even critical failures.
Monitoring in production typically covers:
Prediction quality: Tracking metrics like accuracy, precision, recall, or business KPIs to ensure the model is delivering value.
Data drift: Detecting when the input data distribution changes compared to the training data, which can signal that the model may no longer be valid.
Concept drift: Identifying when the relationship between input features and the target variable changes over time.
System health: Monitoring latency, throughput, error rates, and resource usage to ensure the serving infrastructure is reliable.
Logging complements monitoring by capturing detailed records of predictions, input data, errors, and system events. These logs are invaluable for debugging, auditing, and compliance.
Automated Retraining: Closing the Feedback Loop
Even with the best monitoring, models will eventually need to be updated. Automated retraining pipelines help close the feedback loop by:
Regularly evaluating model performance on new data.
Triggering retraining when performance drops below a threshold or when significant data drift is detected.
Validating and testing new models before deployment.
Rolling out updated models with minimal manual intervention.
This approach ensures that models remain accurate and relevant, adapting to changes in the real world.
Example: Monitoring and Automated Retraining Workflow
Here’s a high-level example of how this might look in practice:
Monitoring:
A monitoring system (e.g., Prometheus, Grafana, or cloud-native tools) tracks model performance and data drift in real time. Alerts are triggered if metrics fall outside acceptable ranges.
Logging:
All predictions, input features, and outcomes are logged to a centralized system (e.g., ELK stack, cloud logging services). This data is used for analysis, debugging, and compliance.
Automated Retraining:
A workflow orchestrator (like Airflow, Kubeflow Pipelines, or Prefect) periodically checks logs and monitoring data. If drift or performance degradation is detected, it triggers a retraining pipeline:
New data is ingested and features are engineered (often using a feature store).
The model is retrained, validated, and tested.
If the new model outperforms the old one, it is automatically deployed.
Python Example: Simple Data Drift Detection and Retraining Trigger
Below is a simplified Python example using scikit-learn and pandas to detect data drift and trigger retraining:
python
import pandas as pd
from scipy.stats import ks_2samp
# Load reference (training) and new (production) data
reference_data = pd.read_csv("reference_data.csv")
new_data = pd.read_csv("new_data.csv")
# Compare distributions for a key feature
stat, p_value = ks_2samp(reference_data["feature1"], new_data["feature1"])
# If p-value is low, data drift is detected
if p_value < 0.05:
print("Data drift detected! Triggering retraining pipeline...")
# Here you would call your retraining workflow, e.g., via Airflow or Kubeflow
else:
print("No significant data drift detected.")Best Practices
Automate as much as possible: Manual monitoring and retraining don’t scale. Use orchestration and automation tools.
Monitor both data and model performance: Don’t rely solely on accuracy—track input data, system health, and business metrics.
Log everything relevant: Detailed logs are essential for root cause analysis and compliance.
Test before deploying new models: Always validate retrained models to avoid introducing regressions.
Integrating CI/CD and Infrastructure as Code in MLOps
Continuous Integration and Continuous Deployment (CI/CD) and Infrastructure as Code (IaC) are foundational practices in modern software engineering. When applied to MLOps, they bring automation, repeatability, and reliability to the machine learning lifecycle, enabling teams to deliver models faster and with greater confidence.
Why CI/CD Matters in MLOps
Traditional software CI/CD focuses on automating the process of building, testing, and deploying code. In MLOps, CI/CD extends to include data validation, model training, evaluation, and deployment. This ensures that every change—whether in code, data, or model configuration—is automatically tested and safely promoted to production if it meets quality standards.
Key benefits include:
Faster iteration: Automated pipelines reduce manual steps, allowing teams to experiment and deploy new models quickly.
Consistency: Every deployment follows the same process, reducing the risk of human error.
Traceability: Each model version, along with its data and code, is tracked and auditable.
Infrastructure as Code: Automating the Foundation
IaC is the practice of managing and provisioning infrastructure (servers, storage, networking, etc.) through machine-readable configuration files, rather than manual processes. Tools like Terraform, AWS CloudFormation, and Kubernetes manifests allow teams to:
Version control infrastructure: Changes to infrastructure are tracked just like code, enabling rollbacks and collaboration.
Automate environment setup: Reproducible environments for development, testing, and production can be spun up or down as needed.
Scale efficiently: Resources can be provisioned or decommissioned automatically based on workload.
How CI/CD and IaC Work Together in MLOps
A typical MLOps workflow might look like this:
Code and Data Changes:
A data scientist pushes new code or updated data to a version control system (e.g., Git).
CI Pipeline:
Automated tests validate the code, check data quality, and run unit/integration tests on model training scripts.
Model Training and Validation:
If tests pass, the pipeline triggers model training. The resulting model is evaluated against validation data, and metrics are logged.
Model Registry and Deployment:
Successful models are registered (e.g., in MLflow or SageMaker Model Registry). Deployment scripts, defined as code, are executed to update the production environment.
IaC for Environments:
Infrastructure for serving the model (e.g., Kubernetes clusters, serverless endpoints) is provisioned or updated using IaC tools, ensuring consistency and scalability.
CD Pipeline:
The new model is deployed to production, and monitoring is set up automatically.
Example: Simple CI/CD Pipeline for ML with GitHub Actions
Here’s a basic example of a GitHub Actions workflow for training and deploying a model:
yaml
name: ML CI/CD Pipeline
on:
push:
branches: [ main ]
jobs:
build-train-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.9'
- name: Install dependencies
run: pip install -r requirements.txt
- name: Run tests
run: pytest tests/
- name: Train model
run: python train.py
- name: Deploy model
run: python deploy.pyFor IaC, you might use a Terraform script to provision a cloud environment for model serving, which can be triggered as part of the pipeline.
Best Practices
Automate everything: From testing to deployment and infrastructure provisioning, automation reduces errors and accelerates delivery.
Use version control for all assets: Code, data schemas, model artifacts, and infrastructure definitions should all be tracked.
Integrate monitoring and rollback: Ensure that deployments are monitored and can be rolled back automatically if issues are detected.
Collaborate across teams: MLOps, DevOps, and data teams should work together to design robust, scalable pipelines.
Cost Optimization and Resource Management
As machine learning operations scale, so do the associated costs—compute, storage, data transfer, and human resources can quickly add up, especially in cloud environments. Effective cost optimization and resource management are therefore essential for sustainable, enterprise-grade MLOps.
Why Cost Optimization Matters in MLOps
Machine learning workloads are often resource-intensive. Training large models, running experiments, storing vast datasets, and serving predictions at scale can lead to significant expenses. Without careful management, organizations risk budget overruns, inefficient resource usage, and even project delays or cancellations.
Cost optimization in MLOps is not just about saving money—it’s about maximizing the value delivered by every dollar spent, ensuring that resources are allocated where they have the greatest impact.
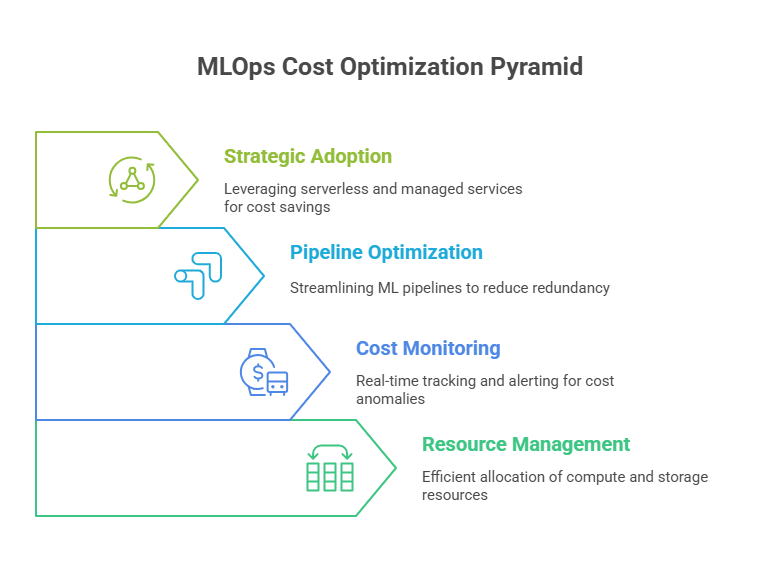
Key Strategies for Cost Optimization
Right-Sizing Compute Resources:
Select appropriate instance types and sizes for training and inference. Avoid over-provisioning by matching resources to workload requirements. Use autoscaling to dynamically adjust resources based on demand.
Spot and Preemptible Instances:
Leverage discounted compute options (like AWS Spot Instances or Google Preemptible VMs) for non-critical or batch workloads. This can significantly reduce training costs, though it requires handling potential interruptions.
Efficient Data Storage:
Store data in cost-effective formats and tiers. Archive infrequently accessed data and use data versioning to avoid unnecessary duplication. Clean up unused datasets and artifacts regularly.
Pipeline Optimization:
Streamline ML pipelines to eliminate redundant steps and minimize unnecessary computations. Cache intermediate results and reuse features or models where possible.
Monitoring and Alerting:
Implement cost monitoring tools (e.g., AWS Cost Explorer, GCP Billing, Azure Cost Management) and set up alerts for unusual spending patterns. Regularly review usage reports to identify optimization opportunities.
Resource Quotas and Governance:
Set quotas and policies to prevent runaway costs, especially in shared or multi-tenant environments. Enforce tagging and labeling for better cost attribution and accountability.
Serverless and Managed Services:
Adopt serverless ML services or managed platforms that automatically scale resources and charge only for actual usage, reducing idle costs.
Example: Autoscaling and Cost Monitoring in Practice
Suppose you’re deploying a model on Kubernetes in the cloud. You can use Kubernetes’ Horizontal Pod Autoscaler to automatically adjust the number of pods based on CPU or memory usage, ensuring you only pay for what you need. At the same time, you can integrate cloud billing APIs to track costs in real time and trigger alerts if spending exceeds a set threshold.
Best Practices
Automate resource management: Use orchestration tools to dynamically allocate and deallocate resources as needed.
Regularly review and optimize: Make cost reviews a routine part of your MLOps workflow.
Educate teams: Ensure everyone understands the cost implications of their choices, from data storage to model complexity.
Balance cost and performance: Don’t sacrifice model quality for savings—find the optimal trade-off for your business goals.
Security, Compliance, and Governance in Optimized Workflows
As machine learning systems become more deeply integrated into business operations, the importance of security, compliance, and governance in MLOps workflows grows dramatically. Optimized workflows must not only be efficient and cost-effective but also robust against threats, compliant with regulations, and transparent for auditability.
Why Security and Compliance Matter in MLOps
ML models often process sensitive data—personal information, financial records, or proprietary business data. A breach or misuse can lead to severe legal, financial, and reputational consequences. Additionally, regulations like GDPR, HIPAA, and industry-specific standards require strict controls over data handling, model transparency, and audit trails.
Governance ensures that all processes, from data ingestion to model deployment, are controlled, documented, and aligned with organizational policies and external regulations.
Key Areas of Focus
1. Data Security:
Protect data at rest and in transit using encryption. Implement strict access controls and audit logs to track who accesses or modifies data. Use anonymization or pseudonymization where possible, especially for personally identifiable information (PII).
2. Model Security:
Secure model artifacts against unauthorized access or tampering. Use model versioning and checksums to detect changes. Protect endpoints from adversarial attacks, such as model inversion or data extraction.
3. Compliance Automation:
Automate compliance checks within CI/CD pipelines. Validate that data usage, storage, and model outputs meet regulatory requirements before deployment. Maintain detailed logs for audits.
4. Governance and Auditability:
Track the lineage of data and models—who created them, how they were trained, and what data was used. Use tools that support lineage tracking and provide dashboards for governance oversight.
5. Role-Based Access Control (RBAC):
Implement RBAC for all MLOps tools and platforms, ensuring that only authorized users can perform sensitive actions, such as deploying models or accessing production data.
6. Monitoring and Incident Response:
Continuously monitor for security incidents, data breaches, or compliance violations. Set up automated alerts and have clear incident response procedures in place.
Example: Integrating Security and Compliance in MLOps Pipelines
A robust MLOps pipeline might include:
Automated data validation and anonymization steps before data enters the training pipeline.
Encryption of all data storage and communication channels.
Automated compliance checks (e.g., verifying that no PII is present in training data).
Model artifact signing and verification before deployment.
Detailed logging of all actions for audit purposes.
Best Practices
Shift security and compliance left: Integrate checks early in the ML lifecycle, not just at deployment.
Automate governance: Use tools that provide automated lineage tracking, policy enforcement, and compliance reporting.
Educate teams: Ensure all team members understand security and compliance requirements relevant to their roles.
Review regularly: Update policies and controls as regulations and threats evolve.
Case Study: Cost-Optimized MLOps in a Global E-Commerce Company
To illustrate how cost optimization and resource management can be successfully implemented in practice, let’s look at a real-world scenario: a global e-commerce company deploying large-scale recommendation models in the cloud.
The Challenge
The company’s data science team needed to deliver personalized product recommendations to millions of users worldwide. Their ML pipelines processed terabytes of data daily, trained complex models, and served predictions in real time. As usage grew, so did cloud costs—compute, storage, and data transfer expenses began to threaten the project’s sustainability.
The Solution
1. Right-Sizing and Autoscaling:
The team analyzed their workloads and switched from always-on, large compute clusters to autoscaling groups. For model training, they used spot instances for non-urgent jobs, reducing compute costs by up to 70%. For real-time inference, Kubernetes Horizontal Pod Autoscaler dynamically adjusted the number of serving pods based on traffic.
2. Data Storage Optimization:
They moved infrequently accessed historical data to cheaper storage tiers (e.g., AWS S3 Glacier) and implemented data retention policies to automatically delete obsolete logs and intermediate files. Feature data was versioned and deduplicated to avoid unnecessary storage.
3. Pipeline Efficiency:
The ML pipelines were refactored to cache intermediate results and reuse precomputed features. Redundant steps were eliminated, and batch processing was scheduled during off-peak hours to take advantage of lower cloud rates.
4. Cost Monitoring and Governance:
The company integrated cloud billing APIs with their internal dashboards, providing real-time visibility into costs by project, team, and workflow. Automated alerts notified teams of unusual spending spikes. Resource quotas and tagging policies ensured accountability and prevented runaway costs.
5. Serverless and Managed Services:
Where possible, the team migrated to serverless ML services (like AWS Lambda for lightweight inference tasks) and managed platforms (such as SageMaker for training), paying only for actual usage and reducing operational overhead.
The Results
Cloud costs were reduced by over 50% within six months, with no loss in model performance or user experience.
Resource utilization improved, with compute and storage resources closely matching actual demand.
Operational efficiency increased, as automation and monitoring freed up engineers to focus on innovation rather than firefighting.
Governance and transparency were enhanced, making it easier to track spending and justify investments to stakeholders.
Lessons Learned
Cost optimization is an ongoing process, not a one-time project.
Collaboration between data science, engineering, and finance teams is crucial for success.
Automation, monitoring, and clear policies are key to sustainable, large-scale MLOps.
Conclusion
This case study demonstrates that with the right strategies—autoscaling, storage optimization, pipeline efficiency, cost monitoring, and managed services—organizations can scale their ML operations globally while keeping costs under control. The result is a robust, agile, and financially sustainable MLOps practice that delivers real business value.
Future Directions: Innovations in Cost-Effective and Scalable Feature Stores
As machine learning adoption accelerates and data volumes continue to grow, the future of feature stores will be shaped by the need for even greater scalability, efficiency, and cost-effectiveness. Here’s what’s on the horizon for advanced feature stores in large-scale ML systems:
1. Serverless and Cloud-Native Architectures
Feature stores are increasingly moving toward serverless and fully managed cloud-native solutions. This shift allows organizations to scale seamlessly with demand, pay only for what they use, and offload infrastructure management to cloud providers. Expect more feature stores to offer elastic scaling, automatic failover, and zero-downtime upgrades as standard.
2. Real-Time and Hybrid Processing
The demand for real-time ML applications—such as fraud detection, personalized recommendations, and IoT analytics—will drive innovation in real-time feature serving. Future feature stores will offer hybrid architectures that efficiently support both batch and streaming data, with intelligent synchronization and low-latency access.
3. Advanced Cost Optimization
Next-generation feature stores will integrate built-in cost monitoring, predictive analytics for resource usage, and automated optimization strategies. Features like dynamic tiering (moving data between hot, warm, and cold storage based on access patterns) and intelligent caching will help organizations minimize storage and compute expenses without sacrificing performance.
4. Enhanced Data Governance and Security
With stricter data privacy regulations and growing security threats, feature stores will evolve to provide more granular access controls, automated compliance checks, and end-to-end data lineage. Expect tighter integration with enterprise identity management and audit systems, making it easier to track and control feature usage.
5. Interoperability and Open Standards
To avoid vendor lock-in and promote collaboration, the future will see more open-source feature stores and support for industry standards. This will enable seamless integration with diverse ML platforms, data lakes, and orchestration tools, fostering a more flexible and modular MLOps ecosystem.
6. AI-Driven Automation
AI will increasingly be used to automate feature engineering, quality monitoring, and drift detection within feature stores. Automated recommendations for feature selection, transformation, and storage optimization will help teams focus on innovation rather than maintenance.
Conclusion
The future of feature stores is bright, with rapid innovation focused on scalability, efficiency, and cost control. As organizations demand more from their ML infrastructure, feature stores will become smarter, more automated, and deeply integrated with the broader MLOps landscape. By staying ahead of these trends, teams can ensure their ML systems remain robust, agile, and cost-effective—ready to meet the challenges of tomorrow’s data-driven world.
Conclusion: Building Advanced, Cost-Optimized Feature Stores for Modern ML
Feature stores have become a cornerstone of scalable, reliable, and efficient machine learning operations. As organizations deploy increasingly complex ML systems, the demands on feature stores—regarding architecture, monitoring, governance, and cost—have grown dramatically.
The journey toward advanced feature stores is defined by several key principles:
Architectural Flexibility: Modern feature stores must support both batch and real-time data, integrate seamlessly with diverse data sources, and scale elastically to meet changing workloads.
Robust Monitoring and Governance: Ensuring feature quality, tracking data lineage, and maintaining compliance are essential for trust and transparency in ML workflows.
Cost Optimization: Proactive strategies—such as right-sizing resources, leveraging serverless and managed services, and automating storage tiering—are vital for keeping operations sustainable as data volumes and model complexity grow.
Security and Compliance: Embedding security and regulatory controls into every layer of the feature store protects sensitive data and ensures organizational and legal requirements are met.
Continuous Innovation: The future of feature stores lies in automation, AI-driven optimization, and open standards, enabling teams to focus on delivering business value rather than managing infrastructure.
By embracing these principles, organizations can build feature store solutions that not only meet today’s needs but are also ready for tomorrow’s challenges. The result is a robust, cost-effective, and future-proof foundation for machine learning at scale—empowering teams to innovate faster, deploy models more reliably, and maximize the impact of their data-driven initiatives.
Monitoring Models in Production – Tools and Strategies for 2025
The best MLOps tools of 2025 – comparison and recommendations