

Introduction: The Importance of Real-Time MLOps
In today’s fast-paced digital world, real-time machine learning systems are becoming increasingly vital across industries—from personalized recommendations and fraud detection to autonomous vehicles and predictive maintenance. These systems require not only accurate models but also the ability to process data and deliver predictions with minimal latency. This is where real-time MLOps comes into play, combining the principles of machine learning operations with the stringent demands of low-latency, high-throughput environments.
Real-time MLOps focuses on building, deploying, and managing machine learning models that can operate seamlessly in environments where decisions must be made instantly or within milliseconds. Unlike traditional batch-oriented ML workflows, real-time systems must handle continuous data streams, provide rapid inference, and adapt quickly to changing conditions.
The importance of real-time MLOps lies in its ability to bridge the gap between model development and operational deployment under strict performance constraints. It ensures that models are not only accurate but also reliable, scalable, and responsive. This requires specialized infrastructure, optimized pipelines, and robust monitoring to detect and address issues before they impact users or business outcomes.
For developers, mastering real-time MLOps means understanding the unique challenges of low-latency systems and leveraging tools and techniques that enable efficient data processing, model serving, and automated retraining. It also involves close collaboration with data engineers, DevOps, and business stakeholders to align technical solutions with real-world requirements.
In summary, real-time MLOps is essential for organizations that rely on instant, data-driven decisions. By adopting best practices and advanced technologies, teams can build resilient AI systems that deliver value at the speed of today’s digital economy.
Understanding Low-Latency Requirements in ML Systems
Low latency is a critical requirement for many machine learning applications, especially those operating in real-time environments such as autonomous vehicles, fraud detection, recommendation engines, and financial trading systems. Understanding these requirements is essential for designing and implementing effective real-time MLOps workflows.
What Is Low Latency in ML?
Latency refers to the time delay between receiving input data and producing a prediction or decision. In real-time ML systems, this delay must be minimized to meet user expectations or operational constraints. For example, an autonomous vehicle’s perception system must process sensor data and make driving decisions within milliseconds to ensure safety.
Factors Influencing Latency
Several factors contribute to overall latency in ML systems:
Data Ingestion and Preprocessing: The time taken to collect, clean, and transform raw data before it reaches the model.
Model Inference Time: The computational time required for the model to generate predictions.
Network Overhead: Data transfer times between components, especially in distributed or cloud-based architectures.
System Load and Resource Availability: Compute resource contention or insufficient scaling can increase response times.
Serialization and Deserialization: Converting data formats for transmission or storage can add delays.
Latency Requirements Vary by Use Case
Different applications have varying tolerance levels for latency:
Ultra-Low Latency (<10ms): Autonomous vehicles, high-frequency trading, real-time control systems.
Low Latency (10ms–100ms): Online recommendations, fraud detection, real-time analytics.
Moderate Latency (100ms–1s): Batch scoring, periodic model updates, non-critical alerts.
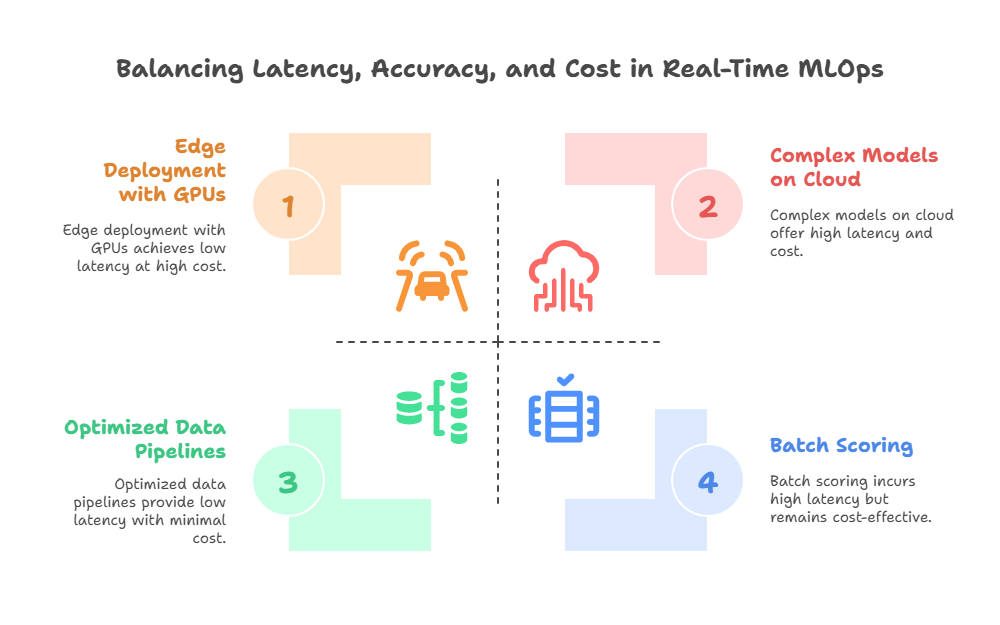
Understanding the specific latency requirements of your application guides architectural decisions, such as whether to deploy models at the edge, use specialized hardware (GPUs, TPUs), or optimize data pipelines.
Balancing Latency with Accuracy and Cost
Achieving low latency often involves trade-offs. Highly complex models may provide better accuracy but require more compute time. Similarly, deploying models closer to data sources reduces latency but can increase operational complexity and cost. Effective real-time MLOps balances these factors to meet business goals.
Key Challenges in Real-Time MLOps
Real-time MLOps presents unique challenges that differ significantly from traditional batch-oriented machine learning workflows. Developers and organizations must address these challenges to build systems that deliver accurate predictions with minimal latency while maintaining reliability and scalability.
Data Velocity and Volume
Real-time systems process continuous streams of data at high velocity and volume. Managing this data flow requires robust ingestion pipelines capable of handling bursts, ensuring data quality, and minimizing delays. Unlike batch processing, real-time pipelines must operate with low latency and high availability.
Low-Latency Model Inference
Achieving low-latency predictions demands optimized model architectures and efficient serving infrastructure. Complex models may need to be compressed or approximated to meet strict response time requirements. Additionally, deploying models closer to data sources—such as on edge devices—can reduce network latency but introduces deployment and management complexity.
Scalability and Resource Management
Real-time workloads can be highly variable, with sudden spikes in traffic. MLOps systems must dynamically scale compute resources to maintain performance without excessive cost. This requires integration with cloud auto-scaling features or on-premises resource schedulers.
Monitoring and Drift Detection
Continuous monitoring is critical to detect data drift, concept drift, or performance degradation in real time. Implementing effective alerting and automated responses—such as retraining or rollback—is more complex in real-time environments due to the need for rapid detection and minimal disruption.
Integration Complexity
Real-time MLOps often involves integrating diverse technologies—streaming platforms (Kafka, Kinesis), feature stores, model serving frameworks, and monitoring tools—across hybrid or multi-cloud environments. Ensuring seamless interoperability and consistent data flow is a significant engineering challenge.
Security and Compliance
Real-time systems must enforce stringent security measures to protect sensitive data in transit and at rest. Compliance with regulations requires auditability and control over data access, which can be more difficult to implement in distributed, real-time architectures.
Summary
Real-time MLOps demands careful consideration of data velocity, low-latency inference, scalability, monitoring, integration, and security. By addressing these challenges with appropriate tools and architectures, developers can build resilient, efficient, and compliant real-time AI systems that meet the demands of modern applications.
Designing Low-Latency Data Pipelines
Designing low-latency data pipelines is a critical aspect of real-time MLOps, enabling machine learning models to process and respond to data with minimal delay. These pipelines must efficiently handle high-velocity data streams, ensure data quality, and deliver features to models in near real-time to support timely decision-making.
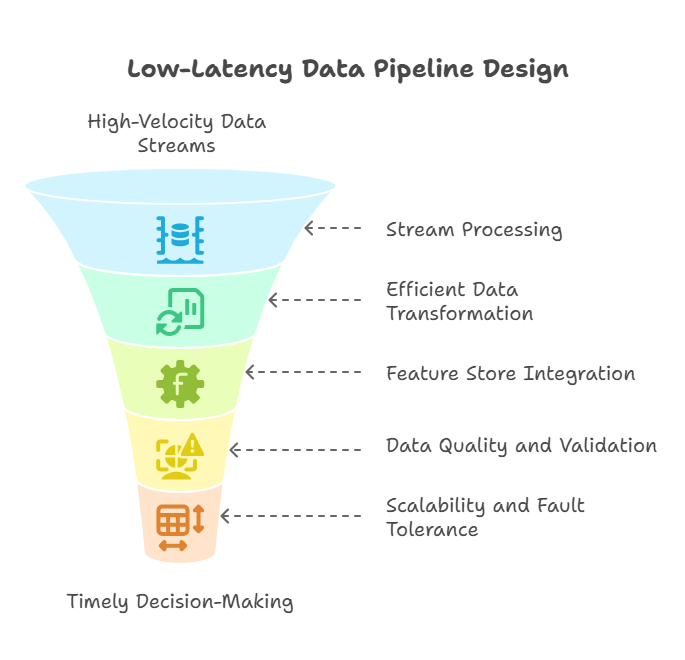
Key Principles of Low-Latency Pipeline Design
Stream Processing:
Utilize stream processing frameworks like Apache Kafka, Apache Flink, or AWS Kinesis to ingest and process data continuously. Stream processing reduces batch delays and enables real-time feature computation.
Efficient Data Transformation:
Implement lightweight, optimized transformations that minimize processing time. Avoid complex or resource-intensive operations in the critical path; instead, precompute or cache features when possible.
Feature Store Integration:
Use feature stores that support real-time feature serving, ensuring that models receive up-to-date and consistent feature values with low latency.
Data Quality and Validation:
Incorporate automated data validation checks within the pipeline to detect anomalies or missing data early, preventing corrupted inputs from affecting model predictions.
Scalability and Fault Tolerance:
Design pipelines to scale elastically with data volume and to recover gracefully from failures, using techniques like partitioning, replication, and checkpointing.
Architectural Considerations
Edge vs. Cloud Processing:
Processing data closer to its source (edge computing) can reduce latency but may require specialized hardware and deployment strategies. Cloud-based pipelines offer scalability but must be optimized to minimize network delays.
Asynchronous vs. Synchronous Processing:
Asynchronous pipelines decouple data ingestion from model inference, improving throughput but potentially increasing end-to-end latency. Synchronous pipelines prioritize minimal latency but may be more complex to scale.
Data Serialization and Transport:
Use efficient serialization formats (e.g., Avro, Protobuf) and optimized network protocols to reduce data transfer times.
Model Optimization Techniques for Real-Time Inference
Achieving low latency in real-time machine learning systems requires more than just fast data pipelines—it demands optimized models that can deliver predictions quickly without sacrificing accuracy. Model optimization techniques are essential for reducing inference time, minimizing resource consumption, and ensuring responsive AI applications.
Key Model Optimization Strategies
Model Compression:
Techniques such as pruning, quantization, and weight sharing reduce the size and complexity of models. Pruning removes redundant or less important connections, while quantization reduces the precision of weights and activations, both leading to faster inference and lower memory usage.
Knowledge Distillation:
This approach trains a smaller, faster “student” model to mimic the behavior of a larger, more accurate “teacher” model. The student model achieves comparable performance with significantly reduced computational requirements.
Efficient Architectures:
Designing or selecting models optimized for speed—such as MobileNet, EfficientNet, or transformer variants tailored for inference—can dramatically reduce latency, especially on edge devices.
Batching and Parallelism:
Grouping multiple inference requests into batches and leveraging parallel processing on GPUs or specialized hardware accelerates throughput without increasing per-request latency significantly.
Hardware Acceleration:
Utilizing GPUs, TPUs, FPGAs, or dedicated AI accelerators can speed up inference. Optimizing models to leverage these hardware capabilities is crucial for real-time performance.
Caching and Approximation:
Caching frequent predictions or using approximate computing techniques can reduce the need for repeated inference, improving response times.
Balancing Accuracy and Latency
Optimization often involves trade-offs between model complexity and speed. It’s important to evaluate the impact of each technique on model accuracy and business outcomes. Automated tools and frameworks can help explore this trade-off space efficiently.
Summary
Model optimization is a critical enabler of real-time MLOps. By applying compression, distillation, efficient architectures, and hardware acceleration, developers can build models that deliver fast, accurate predictions—meeting the stringent latency requirements of modern AI applications.
Infrastructure Choices for Low-Latency Deployments
Choosing the right infrastructure is critical for achieving low-latency deployments in real-time machine learning systems. The infrastructure must support fast data processing, efficient model inference, and seamless scaling to meet the demands of real-time applications. Developers need to balance performance, cost, and operational complexity when selecting infrastructure components.
Key Infrastructure Options
Edge Devices:
Deploying models directly on edge devices (e.g., IoT sensors, mobile phones, embedded systems) minimizes latency by processing data locally. This approach reduces network overhead and enables real-time decision-making even with limited connectivity.
On-Premises Servers:
For applications requiring strict data privacy or low latency within a controlled environment, on-premises servers provide dedicated resources and direct access to local data sources.
Cloud-Based Serving:
Cloud providers offer managed services (e.g., AWS SageMaker, Google Vertex AI, Azure ML) that support scalable, low-latency model serving. Using containerized deployments with Kubernetes or serverless functions can optimize resource usage and response times.
Hybrid Architectures:
Combining edge, on-premises, and cloud resources allows organizations to optimize latency and cost based on workload characteristics and data locality.
Infrastructure Considerations
Network Latency:
Minimize data transfer times by colocating compute resources near data sources or users.
Resource Allocation:
Use autoscaling and load balancing to handle variable traffic without overprovisioning.
Hardware Acceleration:
Leverage GPUs, TPUs, or specialized AI accelerators to speed up inference.
Fault Tolerance:
Design for high availability with failover mechanisms and redundancy.
Example: Simple Python Script to Measure Inference Latency
Here’s a basic example demonstrating how to measure model inference latency, which can help evaluate infrastructure performance:
python
import time
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# Load sample data and train a model
data = load_iris()
X, y = data.data, data.target
model = RandomForestClassifier()
model.fit(X, y)
# Prepare a single sample for prediction
sample = X[0].reshape(1, -1)
# Measure inference latency
start_time = time.time()
prediction = model.predict(sample)
end_time = time.time()
latency_ms = (end_time - start_time) * 1000
print(f"Inference latency: {latency_ms:.2f} ms")Summary
Selecting the right infrastructure for low-latency ML deployments involves balancing edge, on-premises, and cloud resources to meet performance and cost goals. Measuring inference latency and optimizing resource allocation are key steps in building responsive, scalable real-time AI systems.
Real-Time Monitoring and Alerting Strategies
Real-time monitoring and alerting are essential components of effective MLOps, especially for systems that require low latency and high availability. These strategies enable teams to detect performance issues, data drift, or infrastructure problems as they happen, allowing for rapid response and minimizing business impact.
Key Elements of Real-Time Monitoring
Performance Metrics: Continuously track model accuracy, precision, recall, latency, and throughput to ensure models meet service-level objectives.
Data Quality Checks: Monitor input data for anomalies, missing values, or distribution shifts that could affect model predictions.
Infrastructure Health: Keep an eye on resource utilization, error rates, and system availability to prevent bottlenecks or failures.
Explainability Metrics: Track changes in feature importance or prediction explanations to detect subtle model behavior shifts.
Alerting Best Practices
Define Clear Thresholds: Set actionable thresholds for key metrics to avoid alert fatigue.
Multi-Channel Notifications: Use email, SMS, Slack, or incident management tools like PagerDuty to ensure alerts reach the right teams promptly.
Automated Responses: Integrate alerts with automated workflows that can trigger retraining, rollback, or scaling actions.
Regular Review: Continuously evaluate alert effectiveness and adjust thresholds or channels as needed.
Example: Simple Python Alert for Latency Spike
python
def send_alert(message):
# Placeholder for alerting logic (email, Slack, etc.)
print(f"ALERT: {message}")
def monitor_latency(current_latency, threshold=100):
if current_latency > threshold:
send_alert(f"Prediction latency spike detected: {current_latency} ms (threshold: {threshold} ms)")
else:
print(f"Latency is within acceptable range: {current_latency} ms")
# Example usage
monitor_latency(120)Automated Retraining in Real-Time Environments
Automated retraining in real-time environments is a critical capability for maintaining the accuracy and relevance of machine learning models as data evolves. In dynamic settings where data streams continuously and decisions must be made instantly, models can quickly become outdated due to data drift, concept drift, or changing user behavior. Automated retraining pipelines ensure that models adapt promptly without manual intervention, sustaining high performance and business value.
Why Automated Retraining Matters in Real-Time
Real-time ML systems face constant changes in input data distributions and operational contexts. Without automated retraining, models risk degradation, leading to inaccurate predictions and potential business losses. Automated retraining pipelines monitor model performance and data quality metrics continuously, triggering retraining workflows when predefined thresholds are breached.
Key Components of Automated Retraining Pipelines
Continuous Monitoring: Track model accuracy, prediction confidence, and data drift in real time.
Triggering Mechanisms: Define clear criteria—such as performance drops or drift scores—that automatically initiate retraining.
Data Validation: Ensure new training data meets quality standards before retraining.
Model Training and Evaluation: Automate training jobs with updated data and validate new models against holdout sets.
Deployment Automation: Seamlessly deploy validated models to production, with rollback options if needed.
Challenges and Considerations
Latency Constraints: Retraining must be efficient to avoid long downtimes.
Resource Management: Balance compute costs with retraining frequency.
Data Labeling: Ensure timely availability of labeled data for supervised retraining.
Monitoring Accuracy: Avoid false positives in drift detection to prevent unnecessary retraining.
Edge Computing and On-Device ML for Reduced Latency
Edge computing and on-device machine learning (ML) are revolutionizing how real-time AI applications are deployed and managed. By processing data and running models directly on edge devices—such as smartphones, IoT sensors, or autonomous vehicles—organizations can achieve ultra-low latency, reduce bandwidth usage, and enhance privacy. This shift presents unique opportunities and challenges for MLOps teams aiming to deliver responsive, scalable, and secure AI solutions.
Benefits of Edge and On-Device ML
Reduced Latency: Processing data locally eliminates network delays, enabling real-time or near-real-time decision-making critical for applications like autonomous driving or industrial automation.
Bandwidth Efficiency: By minimizing data transfer to central servers, edge ML reduces network congestion and operational costs.
Enhanced Privacy: Sensitive data can be processed on-device without leaving the user’s environment, supporting compliance with data protection regulations.
Resilience: Edge devices can continue operating independently even with intermittent connectivity.
Challenges for MLOps
Resource Constraints: Edge devices often have limited compute power, memory, and energy, requiring optimized, lightweight models.
Deployment Complexity: Managing model updates, versioning, and rollback across potentially millions of distributed devices is complex.
Monitoring and Feedback: Collecting performance metrics and feedback from edge devices in real time requires efficient, secure communication channels.
Security: Ensuring model and data security on potentially vulnerable edge devices is critical.
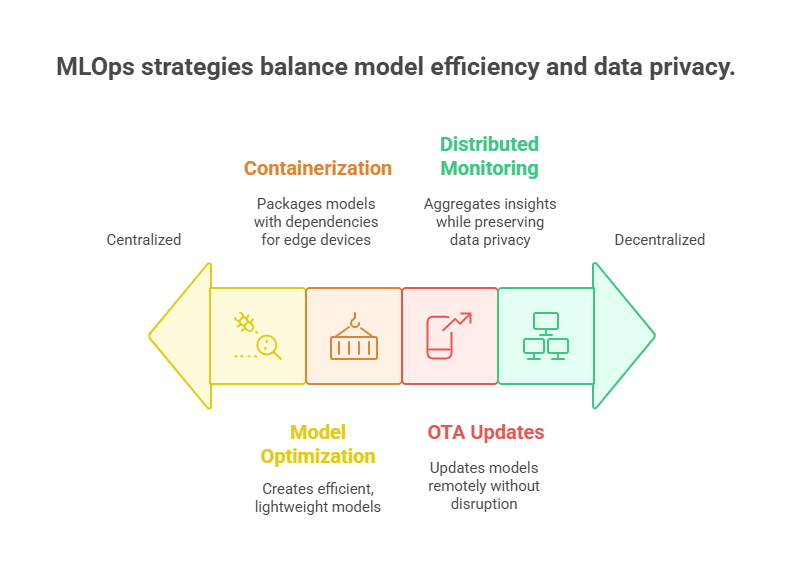
MLOps Strategies for Edge ML
Model Optimization: Use techniques like quantization, pruning, and knowledge distillation to create efficient models suitable for edge deployment.
Containerization and Packaging: Package models with necessary dependencies using lightweight containers or specialized formats for edge devices.
Over-the-Air (OTA) Updates: Implement secure, automated mechanisms to update models remotely without disrupting device operation.
Distributed Monitoring: Use federated learning and decentralized monitoring to aggregate insights while preserving data privacy.
Case Studies: Real-Time MLOps in Action
Real-time MLOps is transforming industries by enabling machine learning models to operate reliably and efficiently in dynamic, low-latency environments. Examining real-world case studies provides valuable insights into how organizations overcome challenges and implement best practices to deliver impactful AI solutions.
Case Study 1: Autonomous Vehicles
A leading automotive company developed an autonomous driving system that relies on real-time sensor data processing and decision-making. Their MLOps pipeline integrates edge computing with cloud-based orchestration, enabling models to be updated and retrained continuously based on live data. Real-time monitoring detects data drift and model performance degradation, triggering automated retraining and deployment. This approach ensures safety-critical decisions are made with up-to-date, accurate models, reducing latency and improving reliability.
Case Study 2: Financial Fraud Detection
A global bank implemented a real-time fraud detection system that processes millions of transactions per second. Their MLOps framework uses streaming data pipelines with Apache Kafka and Flink, combined with automated model retraining triggered by drift detection. Continuous monitoring and alerting enable rapid response to emerging fraud patterns. The system’s ability to adapt in real time has significantly reduced false positives and financial losses.
Case Study 3: E-commerce Personalization
An e-commerce platform uses real-time MLOps to deliver personalized recommendations to millions of users. Their pipeline automates data ingestion, feature engineering, model training, and deployment with minimal latency. Monitoring dashboards track model accuracy, latency, and user engagement metrics, while automated alerts trigger retraining or rollback when performance drops. This has led to increased conversion rates and customer satisfaction.
Lessons Learned
Automation is key: Automating data pipelines, model training, deployment, and monitoring enables rapid iteration and scalability.
Real-time monitoring: Continuous tracking of performance and data quality is essential for maintaining model accuracy.
Robust infrastructure: Combining edge and cloud resources optimizes latency and reliability.
Collaboration: Cross-functional teams ensure alignment between data science, engineering, and business goals.
Future Trends and Best Practices for Real-Time MLOps
As real-time machine learning systems become increasingly critical across industries, the field of real-time MLOps is evolving rapidly. Developers and organizations must stay ahead of emerging trends and adopt best practices to build resilient, scalable, and efficient AI solutions that meet the demands of low-latency environments.
Emerging Trends
AI-Driven Automation:
Future real-time MLOps platforms will leverage AI to automate anomaly detection, root cause analysis, and even self-healing actions such as automated retraining or rollback, reducing manual intervention and downtime.
Edge and Federated Learning Integration:
With the rise of edge computing and federated learning, MLOps tools will support distributed model training, deployment, and monitoring across decentralized devices and data sources, ensuring privacy and low latency.
Unified Observability:
Next-generation observability platforms will provide comprehensive, real-time insights by combining metrics, logs, traces, and explainability across hybrid and multi-cloud environments.
Explainability and Responsible AI:
Real-time explainability and fairness monitoring will become standard, helping organizations meet regulatory requirements and build trust in AI systems.
Serverless and Event-Driven Architectures:
Serverless computing and event-driven pipelines will enable highly scalable, cost-efficient real-time ML workflows that dynamically respond to data and user interactions.
Best Practices
Design for Scalability and Resilience:
Build pipelines that can handle variable workloads and recover gracefully from failures.
Automate End-to-End Workflows:
Integrate data ingestion, model training, deployment, monitoring, and retraining into seamless automated pipelines.
Implement Robust Monitoring and Alerting:
Continuously track performance, data quality, and system health with real-time alerts.
Prioritize Security and Compliance:
Embed security controls, audit logging, and compliance checks throughout the ML lifecycle.
Foster Cross-Functional Collaboration:
Encourage communication and shared ownership among data scientists, engineers, and business stakeholders.
Monitoring Models in Production – Tools and Strategies for 2025