

Introduction to MLOps in Multi-Cloud Environments
MLOps in multi-cloud environments is rapidly becoming a strategic priority for organizations aiming to scale their machine learning (ML) initiatives while maintaining flexibility, resilience, and cost efficiency. As businesses increasingly adopt cloud-native solutions, the need to operate across multiple cloud providers—such as AWS, Google Cloud, and Azure—has grown. This approach, known as multi-cloud, offers significant advantages but also introduces new complexities, especially in the context of MLOps.
What is MLOps in Multi-Cloud?
MLOps (Machine Learning Operations) refers to the set of practices that automate and streamline the end-to-end ML lifecycle, from data preparation and model training to deployment and monitoring. In a multi-cloud environment, these practices must be adapted to work seamlessly across different cloud platforms, each with its own tools, APIs, and security standards.
Why Multi-Cloud for MLOps?
Organizations choose multi-cloud strategies for several reasons: avoiding vendor lock-in, optimizing costs, leveraging best-in-class services from different providers, and ensuring high availability and disaster recovery. For ML teams, this means the ability to train models on one cloud, deploy them on another, and store data wherever it makes the most sense—without being tied to a single vendor.
Key Benefits of Multi-Cloud MLOps
Multi-cloud MLOps enables greater flexibility in resource allocation, supports compliance with regional data regulations, and allows teams to take advantage of specialized ML services unique to each cloud provider. It also enhances business continuity by reducing the risk of downtime or service disruption from a single provider.
Challenges to Consider
Despite its benefits, multi-cloud MLOps introduces challenges such as increased operational complexity, the need for robust data synchronization, and the requirement to manage security and compliance across multiple environments. Successful multi-cloud MLOps requires careful planning, cloud-agnostic tooling, and a strong focus on automation and monitoring.
SEO Takeaway
For organizations looking to future-proof their ML workflows, understanding the fundamentals of MLOps in multi-cloud environments is essential. By adopting a multi-cloud approach, businesses can maximize flexibility, optimize costs, and ensure their machine learning operations are resilient and scalable.
Key Challenges of Multi-Cloud MLOps
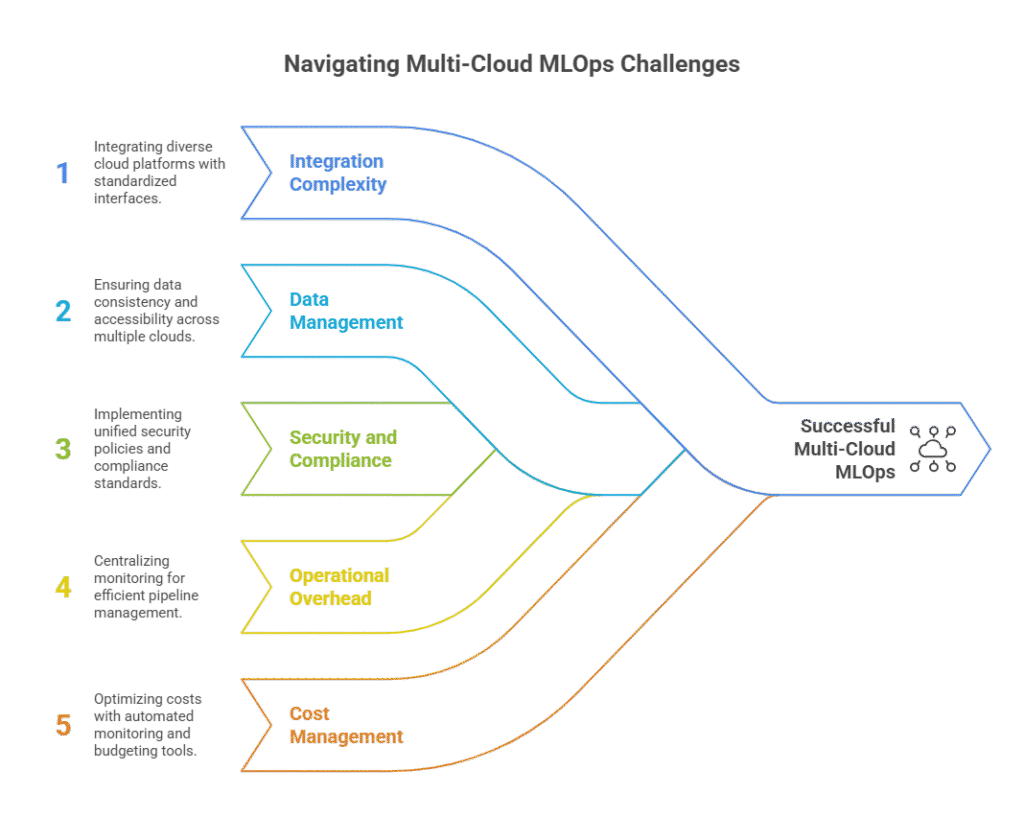
Implementing MLOps in multi-cloud environments brings unique challenges that organizations must address to ensure successful machine learning operations. As more businesses adopt multi-cloud strategies, understanding these obstacles is crucial for building robust, scalable, and cost-effective ML workflows.
Complexity of Integration
One of the primary challenges in multi-cloud MLOps is integrating diverse cloud platforms. Each provider—such as AWS, Google Cloud, and Azure—offers different APIs, services, and management tools. Ensuring seamless interoperability between these platforms requires cloud-agnostic solutions, standardized interfaces, and often custom integration layers. Without careful planning, integration complexity can lead to increased development time and operational overhead.
Data Management and Synchronization
Managing data across multiple clouds is another significant hurdle. Data may be stored in different formats, locations, or regions, making synchronization and consistency difficult. Ensuring that training, validation, and inference data are up-to-date and accessible across all environments is essential for reliable ML outcomes. Data transfer between clouds can also introduce latency, security risks, and additional costs.
Security and Compliance
Multi-cloud MLOps environments must adhere to varying security standards and compliance requirements. Each cloud provider has its own security protocols, identity management systems, and compliance certifications. Organizations must implement unified security policies, manage access controls, and ensure data privacy across all platforms. This is especially important for industries with strict regulatory requirements, such as healthcare or finance.
Operational Overhead and Monitoring
Operating ML pipelines across multiple clouds increases the complexity of monitoring, logging, and troubleshooting. Teams need centralized observability tools that provide real-time insights into model performance, resource utilization, and system health across all cloud environments. Without unified monitoring, identifying and resolving issues can become time-consuming and error-prone.
Cost Management
Cost optimization is a persistent challenge in multi-cloud MLOps. Different providers have varying pricing models for compute, storage, and data transfer. Without proper cost tracking and optimization strategies, organizations risk overspending or underutilizing resources. Implementing automated cost monitoring and budgeting tools is essential for maintaining financial control.
SEO Takeaway
Addressing the key challenges of multi-cloud MLOps—such as integration complexity, data management, security, operational overhead, and cost control—is vital for organizations aiming to scale their machine learning initiatives. By proactively identifying and mitigating these obstacles, businesses can unlock the full potential of multi-cloud MLOps and drive innovation in their ML workflows.
Designing Cloud-Agnostic ML Pipelines
Designing cloud-agnostic ML pipelines is a foundational step for organizations embracing multi-cloud MLOps. A cloud-agnostic approach ensures that machine learning workflows can run seamlessly across different cloud providers, such as AWS, Google Cloud, and Azure, without being tied to a single vendor’s ecosystem. This flexibility is essential for maximizing resource utilization, avoiding vendor lock-in, and enabling rapid adaptation to changing business needs.
What Does Cloud-Agnostic Mean in MLOps?
Cloud-agnostic ML pipelines are designed to be portable and interoperable, meaning they can be deployed, managed, and scaled across multiple cloud environments with minimal changes. This is achieved by using open-source tools, standardized APIs, and containerization technologies like Docker and Kubernetes. By abstracting away cloud-specific dependencies, teams can focus on building robust ML solutions that are resilient to infrastructure changes.
Key Principles of Cloud-Agnostic Pipeline Design
To build truly cloud-agnostic ML pipelines, organizations should prioritize modularity, portability, and automation. Modularity involves breaking down the ML workflow into independent components—such as data ingestion, preprocessing, model training, and deployment—that can be developed, tested, and deployed separately. Portability is achieved by packaging these components in containers and using orchestration platforms like Kubernetes, which are supported by all major cloud providers. Automation, through tools like CI/CD pipelines, ensures consistent deployment and management of ML models across environments.
Choosing the Right Tools and Frameworks
Selecting cloud-agnostic tools is critical for success. Popular choices include MLflow for experiment tracking and model management, Kubeflow for orchestrating ML workflows, and Apache Airflow for scheduling and automation. These tools are open-source and designed to work across different cloud platforms, making them ideal for multi-cloud MLOps. Additionally, using infrastructure-as-code solutions like Terraform allows teams to provision and manage resources in a consistent, repeatable manner.
Best Practices for Cloud-Agnostic ML Pipelines
To ensure smooth operation, it’s important to standardize data formats, use version control for both code and data, and implement robust monitoring and logging. Teams should also design for failure by building in redundancy and automated recovery mechanisms. Regular testing across different cloud environments helps identify compatibility issues early and ensures that pipelines remain portable as cloud services evolve.
Integration Strategies for Multi-Cloud ML Workflows
Integrating machine learning workflows across multiple cloud platforms is a key challenge and opportunity for organizations pursuing multi-cloud MLOps. Effective integration strategies enable seamless collaboration, efficient resource utilization, and consistent model performance, regardless of the underlying cloud infrastructure. In this article, we’ll explore proven approaches to integrating ML workflows in multi-cloud environments and highlight best practices for success.
Why Integration Matters in Multi-Cloud MLOps
Multi-cloud integration ensures that data, models, and ML processes can move smoothly between different cloud providers such as AWS, Google Cloud, and Azure. This flexibility is crucial for organizations that want to leverage specialized services, optimize costs, or comply with regional data regulations. Without robust integration, ML teams risk data silos, inconsistent model performance, and increased operational complexity.
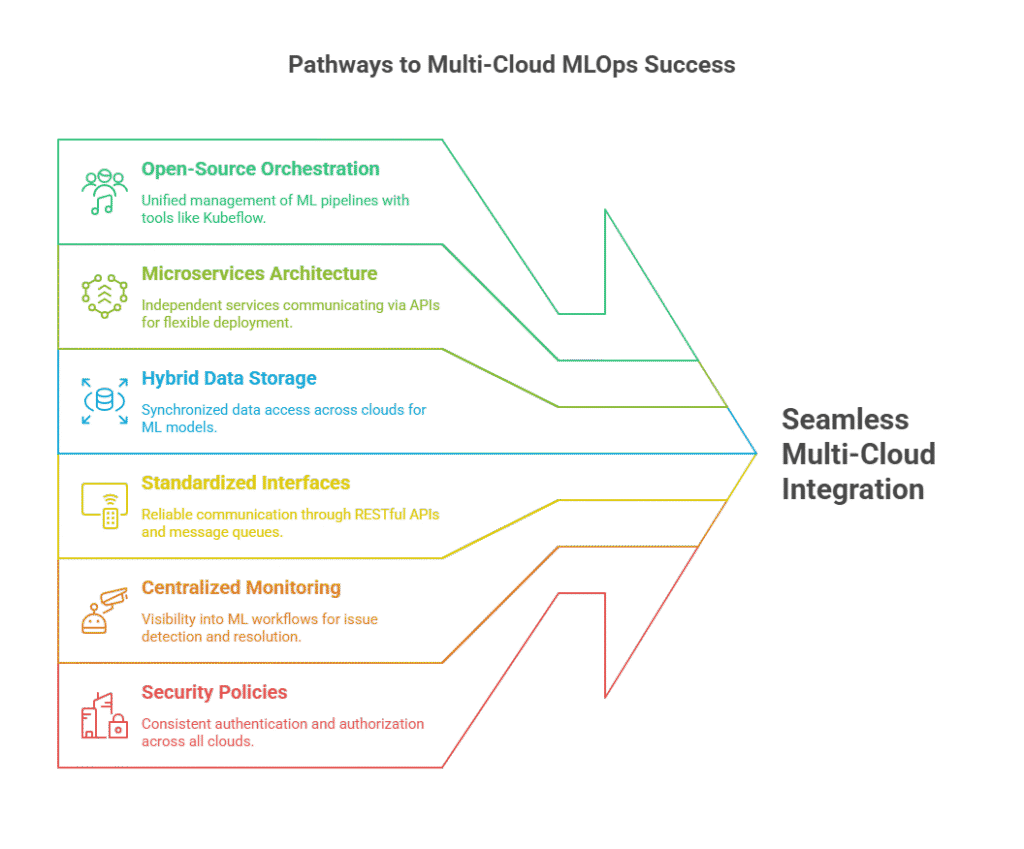
Approaches to Multi-Cloud Integration
There are several strategies for integrating ML workflows across clouds. One common approach is to use open-source orchestration tools like Kubeflow or Apache Airflow, which provide a unified interface for managing ML pipelines regardless of the underlying cloud. These tools support containerized workloads, making it easier to deploy and scale ML components across different environments.
Another effective strategy is to adopt a microservices architecture, where each stage of the ML workflow—such as data ingestion, feature engineering, model training, and inference—is encapsulated as an independent service. These services communicate via APIs, allowing them to be deployed and managed on any cloud platform. This modular approach enhances flexibility and simplifies integration.
Organizations can also leverage hybrid data storage solutions that synchronize data across clouds, ensuring that ML models always have access to the latest information. Data virtualization tools and cloud-agnostic databases help abstract away the complexities of managing data in a distributed environment.
Best Practices for Seamless Integration
To achieve seamless integration, it’s important to standardize interfaces and protocols across all ML components. Using RESTful APIs, gRPC, or message queues ensures reliable communication between services, regardless of where they are hosted. Implementing centralized monitoring and logging provides visibility into the entire ML workflow, making it easier to detect and resolve issues.
Security is another critical consideration. Organizations should enforce consistent authentication and authorization policies across all clouds, using identity federation and role-based access controls. Automated testing and continuous integration (CI) pipelines help maintain workflow integrity as changes are deployed across multiple environments.
SEO Takeaway
Adopting effective integration strategies for multi-cloud ML workflows is essential for organizations seeking agility, scalability, and resilience in their machine learning operations. By leveraging open-source orchestration tools, microservices architectures, and standardized interfaces, businesses can unlock the full potential of multi-cloud MLOps and drive innovation across their data science teams.
Data Management and Synchronization Across Clouds
In the era of multi-cloud MLOps, data management and synchronization across different cloud providers is both a major challenge and a critical success factor for machine learning projects. Data is the foundation of every ML model, and its availability, consistency, and security directly impact the quality of results and operational efficiency.
Why is data management in multi-cloud environments difficult?
In multi-cloud setups, data is often distributed across various cloud providers, geographic regions, and storage formats. This leads to challenges such as data silos, duplication, latency in access, and format incompatibility. Additionally, each cloud provider may have its own tools and security policies, making it harder to manage permissions and audit access consistently.
Strategies for effective data management
To manage data effectively in a multi-cloud environment, organizations should adopt cloud-agnostic solutions such as open file formats (like Parquet or ORC), data orchestration tools (such as Apache Airflow or Apache NiFi), and platforms for metadata management and data cataloging. Implementing automated ETL/ELT processes is crucial to ensure data consistency and freshness across all clouds.
Another important aspect is real-time or near-real-time data synchronization. This can be achieved using data replication services, distributed databases, or data virtualization tools that abstract the underlying storage and provide a unified view of data. Monitoring tools should be in place to track data flows, detect synchronization issues, and alert teams to potential problems.
Best practices for multi-cloud data management
Establishing clear data governance policies is essential. This includes defining data ownership, access controls, and compliance requirements for each dataset. Regular audits and automated monitoring help maintain data quality and security. It’s also important to document data flows and dependencies, making it easier to troubleshoot issues and onboard new team members.
Model Deployment and Serving in Multi-Cloud Setups
Deploying and serving machine learning models in a multi-cloud environment is a powerful way to increase reliability, reduce vendor lock-in, and optimize for cost and latency. However, it introduces challenges related to portability, orchestration, and monitoring. Below, you’ll find an overview of best practices and a simple Python example using FastAPI and Docker, which are both cloud-agnostic and widely supported.
Key Concepts and Best Practices
Model deployment in multi-cloud setups typically relies on containerization (e.g., Docker) to ensure that models run consistently across different cloud providers. Orchestration tools like Kubernetes (K8s) help manage scaling, failover, and rolling updates. For serving, lightweight APIs (such as FastAPI or Flask) are commonly used to expose model predictions as web services.
To streamline deployment:
Use a model registry (like MLflow or Sagemaker Model Registry) to track versions and artifacts.
Automate CI/CD pipelines for building, testing, and deploying containers to multiple clouds.
Implement health checks and monitoring for each deployment.
Use load balancers or API gateways to route traffic intelligently between clouds.
Example: Deploying a Model with FastAPI and Docker
Below is a simple example of how you might serve a trained model using FastAPI. This approach works on any cloud that supports Docker containers.
python
# app.py
from fastapi import FastAPI
import pickle
from pydantic import BaseModel
app = FastAPI()
# Load your trained model (e.g., a scikit-learn model)
with open("model.pkl", "rb") as f:
model = pickle.load(f)
class InputData(BaseModel):
feature1: float
feature2: float
@app.post("/predict")
def predict(data: InputData):
# Prepare input for the model
X = [[data.feature1, data.feature2]]
prediction = model.predict(X)
return {"prediction": prediction[0]}Dockerfile for Containerization
dockerfile
# Dockerfile
FROM python:3.10-slim
WORKDIR /app
COPY app.py model.pkl ./
RUN pip install fastapi uvicorn scikit-learn pydantic
EXPOSE 8000
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "8000"]
How to Deploy Across Clouds
Build your Docker image:
docker build -t mymodel:latest .Push the image to a container registry accessible by your cloud providers (e.g., Docker Hub, AWS ECR, Google Container Registry).
Deploy the container using your cloud’s orchestration service (e.g., AWS ECS, Google Cloud Run, Azure Container Instances, or Kubernetes clusters running in any cloud).
Set up API gateways or load balancers to route requests to the appropriate cloud endpoint.
Monitoring and Observability in Multi-Cloud MLOps
Monitoring and observability are essential components of any robust MLOps pipeline, especially in multi-cloud environments. When your machine learning models and data pipelines are distributed across different cloud providers, ensuring their health, performance, and reliability becomes more complex—but also more critical.
Why is monitoring in multi-cloud challenging?
Each cloud provider offers its own monitoring tools and dashboards (like AWS CloudWatch, Google Cloud Monitoring, or Azure Monitor), but these tools are often siloed and may not provide a unified view of your entire system. This fragmentation can make it difficult to detect issues, correlate events, and maintain consistent performance and security standards across all deployments.
Best practices for multi-cloud monitoring
To achieve effective observability, organizations often use cloud-agnostic monitoring solutions such as Prometheus, Grafana, or Datadog. These tools can aggregate metrics, logs, and traces from multiple sources, providing a single pane of glass for your operations team. Key metrics to monitor include model latency, error rates, resource utilization, and data drift. Setting up automated alerts and dashboards helps teams respond quickly to anomalies or failures.
Example: Monitoring a FastAPI Model with Prometheus
Below is a simple Python example that shows how to expose custom metrics from a FastAPI model server, which can then be scraped by Prometheus and visualized in Grafana. This approach works in any cloud environment.
python
# monitoring_app.py
from fastapi import FastAPI
from prometheus_client import Counter, generate_latest, CONTENT_TYPE_LATEST
from starlette.responses import Response
app = FastAPI()
# Define a Prometheus counter for prediction requests
PREDICTION_COUNTER = Counter("prediction_requests_total", "Total number of prediction requests")
@app.get("/metrics")
def metrics():
return Response(generate_latest(), media_type=CONTENT_TYPE_LATEST)
@app.get("/predict")
def predict():
PREDICTION_COUNTER.inc()
# Dummy prediction logic
return {"prediction": 42}How it works:
This FastAPI app exposes a /metrics endpoint, which Prometheus can scrape to collect metrics. The PREDICTION_COUNTER tracks the number of prediction requests. You can add more metrics (like latency or error counts) as needed.
Deployment tips:
Deploy this containerized app in each cloud environment. Configure your Prometheus server to scrape metrics from all deployments, regardless of cloud provider. Use Grafana to create unified dashboards and set up alerts for key metrics.
Migration of ML Workloads Between Cloud Providers
Migrating machine learning (ML) workloads between cloud providers is becoming increasingly common as organizations seek to optimize costs, leverage best-in-class services, and avoid vendor lock-in. However, successful migration requires careful planning, robust automation, and a deep understanding of both technical and business implications. In this article, we’ll explore the key steps, challenges, and best practices for seamless ML workload migration in multi-cloud MLOps environments.
Why Migrate ML Workloads Between Clouds?
There are several reasons why companies move ML workloads from one cloud to another:
Cost optimization: Taking advantage of better pricing models or discounts.
Performance: Leveraging specialized hardware (e.g., TPUs, GPUs) or data locality.
Compliance: Meeting regional data residency or regulatory requirements.
Resilience: Reducing risk by avoiding reliance on a single cloud provider.
Key Steps in ML Workload Migration
Assessment and Planning:
Start by auditing your current ML infrastructure, data pipelines, and dependencies. Identify which models, datasets, and services need to be migrated, and evaluate compatibility with the target cloud.
Data Migration and Synchronization:
Move datasets using secure, efficient transfer tools. Consider data format compatibility (e.g., Parquet, TFRecord), and ensure data integrity with checksums or validation scripts. For large datasets, use cloud-native transfer services or third-party solutions to minimize downtime.
Model Portability:
Package models using open standards (ONNX, PMML) or containers (Docker) to ensure they run consistently across clouds. Use model registries that support multi-cloud access for version control and traceability.
Pipeline and Workflow Adaptation:
Refactor or reconfigure ML pipelines to use cloud-agnostic orchestration tools (e.g., Kubeflow, Airflow) and update integrations with storage, compute, and monitoring services in the new environment.
Testing and Validation:
Before going live, test the migrated workloads for performance, accuracy, and reliability. Run shadow deployments or A/B tests to compare results with the original environment.
Deployment and Monitoring:
Deploy models using cloud-native or open-source serving solutions. Set up unified monitoring and logging to track performance, resource usage, and costs in the new cloud.
Common Challenges and How to Overcome Them
Data transfer costs and latency: Minimize by compressing data, transferring only what’s needed, and scheduling transfers during off-peak hours.
Dependency mismatches: Use containers and environment management tools to ensure consistency.
Security and compliance: Maintain encryption, access controls, and audit trails throughout the migration.
Downtime and rollback: Plan for staged migrations and have rollback procedures in place in case of issues.
Example: Migrating a Model with Docker
Here’s a simple example of packaging a trained model for migration using Docker, making it portable across cloud providers:
python
# Save your trained model
import pickle
with open("model.pkl", "wb") as f:
pickle.dump(trained_model, f)dockerfile
# Dockerfile for model serving
FROM python:3.10-slim
WORKDIR /app
COPY model.pkl serve.py ./
RUN pip install fastapi uvicorn scikit-learn
EXPOSE 8000
CMD ["uvicorn", "serve:app", "--host", "0.0.0.0", "--port", "8000"]This container can be pushed to any cloud container registry and deployed using Kubernetes, ECS, or other orchestration tools.
Monitoring and Observability in Distributed Cloud Environments
Monitoring and observability are critical for maintaining reliable, high-performing machine learning systems in distributed, multi-cloud environments. As ML workloads and data pipelines span multiple cloud providers, gaining unified visibility into system health, performance, and security becomes both more challenging and more important.
Why Monitoring and Observability Matter in Multi-Cloud MLOps
In distributed cloud environments, issues like latency spikes, resource bottlenecks, data drift, or model performance degradation can occur in any part of the pipeline—often outside the scope of a single cloud provider’s native tools. Without centralized monitoring and observability, these issues may go undetected, leading to downtime, inaccurate predictions, or increased operational costs.
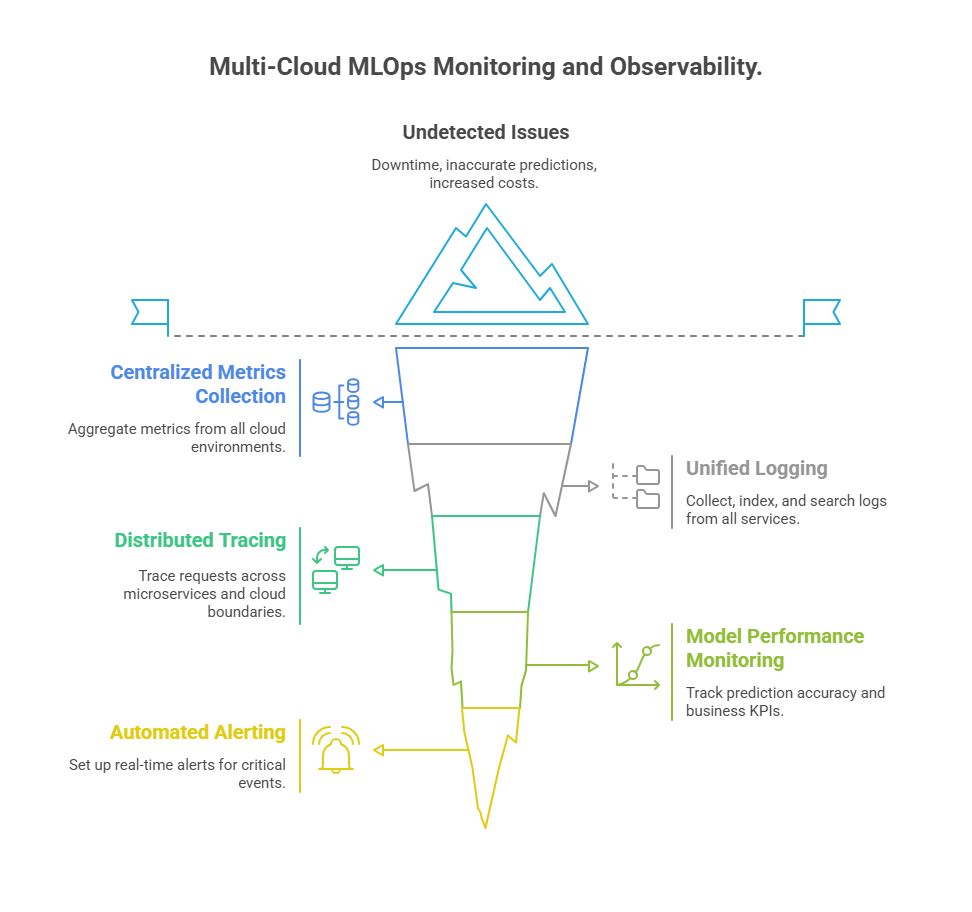
Key Components of Multi-Cloud Monitoring
Centralized Metrics Collection: Use cloud-agnostic tools like Prometheus, Grafana, or Datadog to aggregate metrics (CPU, memory, latency, throughput) from all cloud environments into unified dashboards.
Unified Logging: Implement log aggregation solutions (e.g., ELK Stack, Fluentd) to collect, index, and search logs from all services, regardless of where they run.
Distributed Tracing: Use tools like Jaeger or OpenTelemetry to trace requests and data flows across microservices and cloud boundaries, helping pinpoint bottlenecks and failures.
Model Performance Monitoring: Continuously track prediction accuracy, drift, and business KPIs across all deployed models, with automated alerts for anomalies.
Automated Alerting: Set up real-time alerts for critical events (e.g., resource exhaustion, failed jobs, data drift) to enable rapid response and minimize business impact.
Best Practices for Observability in Multi-Cloud MLOps
Standardize Metrics and Logs: Use consistent naming conventions and formats across all clouds to simplify analysis and troubleshooting.
Automate Dashboards and Reports: Provide stakeholders with up-to-date, actionable insights into system health and model performance.
Integrate Security Monitoring: Track access, authentication, and compliance events alongside operational metrics.
Test Monitoring Pipelines: Regularly simulate failures and drift scenarios to ensure monitoring and alerting systems work as expected.
Example: Unified Monitoring with Prometheus and Grafana
Deploy Prometheus agents in each cloud environment to scrape metrics from ML services and infrastructure. Use a central Grafana instance to visualize and correlate metrics from all clouds, enabling a single-pane-of-glass view for your operations team.
Cost Management and Optimization Techniques
Cost management is a top priority for organizations running machine learning workloads in multi-cloud environments. Without a clear strategy, expenses for compute, storage, data transfer, and third-party services can quickly spiral out of control. Here are proven cost management and optimization techniques for MLOps teams operating across multiple clouds.
1. Resource Tagging and Cost Attribution
Start by tagging all cloud resources (VMs, storage buckets, databases, ML endpoints) by project, team, or business unit. This enables granular cost tracking and helps identify which workloads or teams are driving expenses. Most cloud providers offer built-in cost attribution and reporting tools that leverage these tags.
2. Automated Cost Monitoring and Alerts
Set up automated monitoring for cloud spend using tools like AWS Cost Explorer, Google Cloud Billing, or third-party platforms such as CloudHealth or Spot.io. Configure alerts for budget thresholds, unusual spikes, or forecast overruns to catch issues early.
3. Optimize Compute and Storage Usage
Right-size compute resources by regularly reviewing instance types, scaling policies, and utilization metrics. Use auto-scaling and serverless options where possible. For storage, implement data retention policies, compress data, and move infrequently accessed data to lower-cost storage tiers (e.g., AWS S3 Glacier, Google Coldline).
4. Leverage Spot and Preemptible Instances
For non-critical or batch ML workloads, use spot (AWS), preemptible (GCP), or low-priority (Azure) instances to take advantage of significant discounts. Automate job scheduling to maximize use of these cost-effective resources.
5. Minimize Data Transfer and Egress Fees
Co-locate data storage and compute resources within the same cloud region to reduce data transfer costs. Use edge caching and regional replicas to serve data closer to users and minimize cross-region egress.
6. Automate Idle Resource Cleanup
Implement scripts or use cloud-native tools to automatically shut down or deallocate idle VMs, endpoints, and storage volumes. Regularly audit for orphaned resources left over from experiments or failed jobs.
7. Regular Cost Reviews and Optimization Sprints
Schedule monthly or quarterly cost reviews with engineering and finance teams. Analyze cost reports, identify optimization opportunities, and set actionable goals for the next period.
Example: Python Script for Cloud Cost Analysis
Here’s a simple Python script to aggregate and report cloud costs by resource tag:
python
# cloud_cost_report.py
def report_cloud_costs(cost_data):
print("Cloud Cost Report by Project:")
total = 0
for project, cost in cost_data.items():
print(f" {project}: ${cost:.2f}")
total += cost
print(f"Total Cloud Spend: ${total:.2f}")
# Example usage
cost_data = {
"mlops-pipeline": 1200.50,
"feature-store": 850.75,
"data-ingestion": 430.20,
"monitoring": 210.00
}
report_cloud_costs(cost_data)Case Studies and Best Practices for Multi-Cloud MLOps
Adopting multi-cloud MLOps can unlock flexibility, resilience, and cost savings—but only if implemented with proven strategies and lessons learned from real-world deployments. Here are key case studies and best practices that illustrate how leading organizations succeed with multi-cloud machine learning operations.
Case Study 1: Global Retailer Unifies ML Across Clouds
A global retailer needed to run ML models for demand forecasting and personalization in both North America (AWS) and Europe (Azure) to comply with data residency laws. By containerizing their models with Docker and orchestrating deployments using Kubernetes, they achieved seamless portability. They used a cloud-agnostic model registry and automated CI/CD pipelines to ensure consistent model versioning and deployment across both clouds. The result: faster time-to-market and improved compliance.
Case Study 2: Fintech Optimizes Costs with Multi-Cloud Training
A fintech company leveraged Google Cloud’s TPUs for cost-effective model training and AWS for real-time model serving. Data pipelines were orchestrated with Apache Airflow, and data was synchronized using cloud storage replication. By monitoring resource usage and automating the migration of workloads based on cost and performance, the company reduced training costs by 30% while maintaining high availability.
Case Study 3: Healthcare Provider Ensures Compliance and Security
A healthcare provider used Azure for secure data storage and Google Cloud for advanced ML analytics. They implemented unified identity and access management, encrypted data in transit and at rest, and maintained detailed audit logs across both clouds. Automated monitoring and alerting ensured that any compliance or security issues were detected and addressed immediately.
Best Practices for Multi-Cloud MLOps
Containerize Everything: Use Docker and Kubernetes to ensure portability and consistency across clouds.
Adopt Cloud-Agnostic Tools: Choose orchestration, monitoring, and model registry tools that work across providers (e.g., Kubeflow, MLflow, Airflow).
Automate Data Synchronization: Use ETL pipelines and cloud storage replication to keep data consistent and up-to-date.
Centralize Monitoring and Logging: Aggregate metrics and logs from all clouds into unified dashboards for real-time observability.
Implement Robust Security and Compliance: Use unified IAM, encryption, and audit trails to protect data and models everywhere.
Optimize for Cost and Performance: Regularly review resource usage, leverage spot/preemptible instances, and automate workload migration.
Standardize APIs and Interfaces: Use RESTful APIs and open standards to simplify integration and reduce vendor lock-in.
Test and Validate Across Clouds: Run integration and performance tests in all target environments before production rollout.
Document Everything: Maintain clear documentation of data flows, model versions, and deployment processes for transparency and troubleshooting.
Foster Cross-Cloud Collaboration: Encourage communication and shared ownership between teams working in different cloud environments.
MLOps in the Era of Generative Artificial Intelligence: New Challenges and Opportunities
MLOps: from data science to business value
The best MLOps tools of 2025 – comparison and recommendations