

Introduction to Multi-Cloud MLOps
The rapid growth of machine learning in business and research has led organizations to seek more flexible, scalable, and resilient infrastructure solutions. Multi-cloud MLOps—managing machine learning operations across multiple cloud providers—has emerged as a strategic approach to address these needs. Instead of relying on a single cloud vendor, teams can leverage the strengths of different platforms, reduce vendor lock-in, and improve system reliability.
Multi-cloud MLOps involves orchestrating data pipelines, model training, deployment, and monitoring across various cloud environments. This approach enables organizations to select the best tools and services from each provider, optimize costs, and ensure business continuity. As machine learning projects become more complex and global, the ability to scale workflows seamlessly across clouds is becoming a key competitive advantage.
Advantages and Challenges of Multi-Cloud Approaches
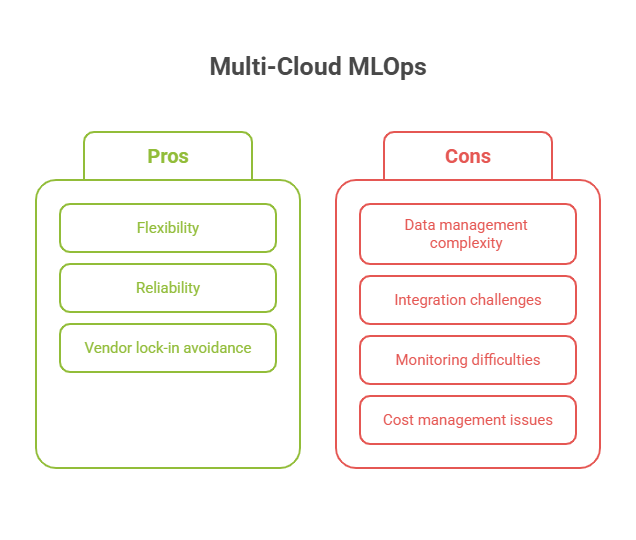
Adopting a multi-cloud strategy for MLOps brings several notable benefits. First, it offers flexibility—teams can choose the most suitable services for specific tasks, such as using one provider’s advanced GPUs for training and another’s robust data storage solutions. This flexibility can lead to better performance and cost savings. Second, multi-cloud setups enhance reliability and availability; if one provider experiences downtime, critical workflows can continue on another platform. Third, multi-cloud architectures help organizations avoid vendor lock-in, making it easier to adapt to changing business needs or negotiate better terms.
However, multi-cloud MLOps also introduces significant challenges. Managing data consistency and security across different platforms can be complex, especially when dealing with sensitive information or strict compliance requirements. Integrating tools and services from multiple providers often requires custom solutions and additional engineering effort. Monitoring, logging, and troubleshooting become more complicated when systems are distributed across clouds. Finally, cost management can be tricky, as it’s easy to lose track of resource usage and spending when operating in multiple environments.
Despite these challenges, the advantages of multi-cloud MLOps are driving more organizations to explore and adopt this approach, especially as the ecosystem of tools and best practices continues to mature.
Designing Scalable Multi-Cloud ML Architectures
Building scalable machine learning architectures in a multi-cloud environment requires careful planning and a modular approach. The goal is to ensure that ML workflows—such as data ingestion, feature engineering, model training, and deployment—can run efficiently across different cloud providers without being tightly coupled to any single platform.
A typical scalable multi-cloud ML architecture separates core components into independent services. For example, data storage might reside in one cloud, while compute resources for model training are provisioned dynamically in another. Containerization technologies like Docker and orchestration platforms such as Kubernetes are often used to abstract away infrastructure differences, making it easier to deploy and manage workloads across clouds. APIs and standardized interfaces play a crucial role in enabling interoperability between services hosted on different platforms.
Another important aspect is automation. Infrastructure as Code (IaC) tools, such as Terraform or Pulumi, help automate the provisioning and configuration of resources in multiple clouds, ensuring consistency and repeatability. By designing for scalability and portability from the start, organizations can respond quickly to changing demands, optimize resource usage, and minimize downtime.
Data Management and Feature Sharing Across Clouds
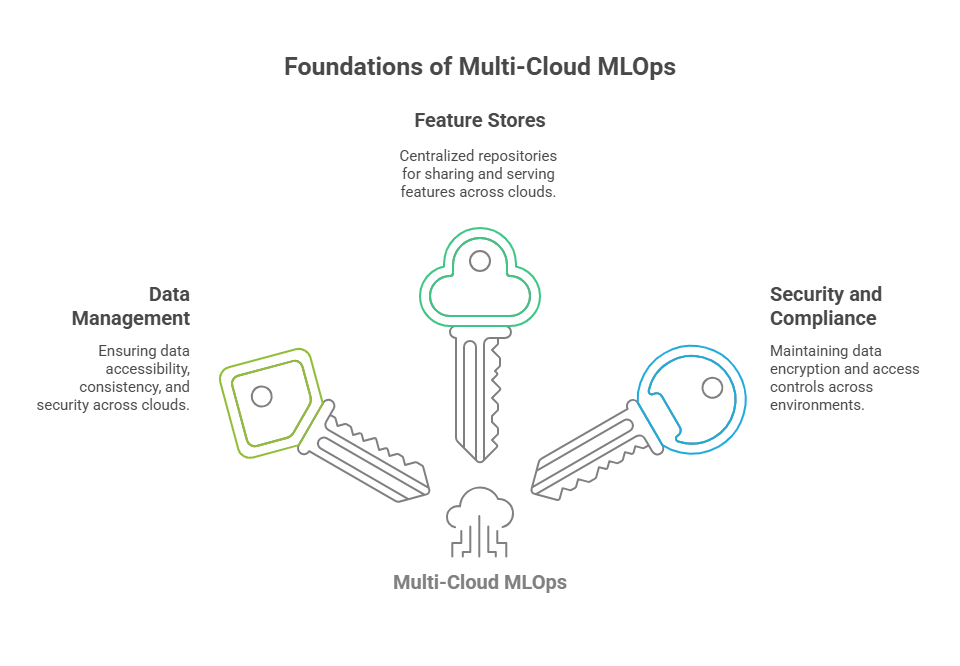
Effective data management is at the heart of successful multi-cloud MLOps. Data must be accessible, consistent, and secure, regardless of where it is stored or processed. This often means implementing data replication or synchronization strategies to ensure that datasets and features are available to ML pipelines running in different clouds.
Feature stores play a key role in this context. A feature store acts as a centralized repository for storing, sharing, and serving features to ML models. In a multi-cloud setup, feature stores need to support cross-cloud access and synchronization, so that features engineered in one environment can be reliably used in another. Some organizations use managed feature store solutions that offer built-in support for multi-cloud deployments, while others build custom synchronization layers on top of open-source tools.
Security and compliance are also critical. Data must be encrypted both in transit and at rest, and access controls should be enforced consistently across all cloud environments. Metadata management, data lineage tracking, and audit logging help maintain transparency and trust in the data used for machine learning. By prioritizing robust data management and feature sharing, organizations can unlock the full potential of multi-cloud MLOps while minimizing risks and inefficiencies.
Model Training and Deployment Strategies
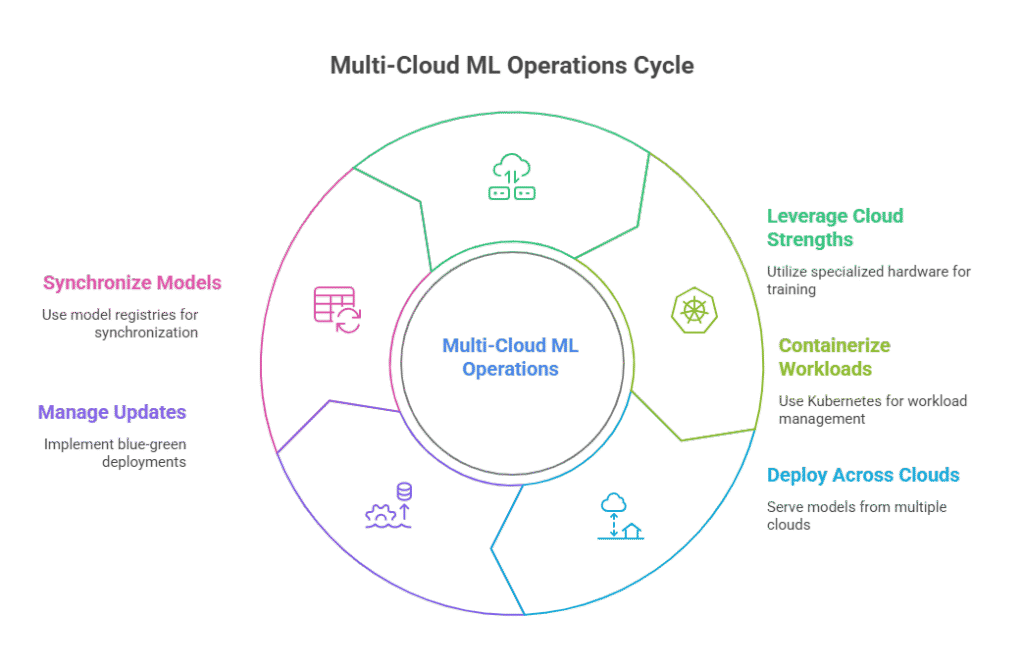
Training and deploying machine learning models in a multi-cloud environment requires strategies that balance performance, cost, and operational complexity. One common approach is to leverage the unique strengths of each cloud provider. For example, an organization might use one cloud’s specialized hardware (such as TPUs or high-end GPUs) for intensive model training, while another cloud is chosen for its robust deployment and serving infrastructure.
To enable seamless model training across clouds, teams often rely on containerization and orchestration tools like Kubernetes, which allow workloads to be scheduled and managed independently of the underlying cloud. This abstraction makes it easier to move training jobs between providers or run them in parallel, depending on resource availability and cost considerations.
For deployment, models can be served from multiple clouds to ensure high availability and low latency for users in different regions. Techniques such as blue-green deployments, canary releases, and automated rollback mechanisms help manage updates and minimize downtime. Model registries that support multi-cloud synchronization ensure that the latest, validated models are available wherever they are needed. By designing training and deployment workflows with portability and redundancy in mind, organizations can achieve both flexibility and resilience in their ML operations.
Pipeline Orchestration in Multi-Cloud Environments
Orchestrating machine learning pipelines across multiple clouds introduces new layers of complexity, but also opens up opportunities for optimization and innovation. Pipeline orchestration involves automating the sequence of tasks—such as data preprocessing, feature engineering, model training, evaluation, and deployment—so that they run reliably and efficiently, even when distributed across different cloud platforms.
Modern orchestration tools like Kubeflow, Apache Airflow, and MLflow can be configured to manage workflows that span multiple clouds. These tools help coordinate dependencies, manage resource allocation, and monitor the status of each pipeline stage. They also provide mechanisms for retrying failed tasks, scaling resources dynamically, and integrating with cloud-native services.
A key challenge is ensuring that data and artifacts produced in one cloud are accessible to subsequent pipeline steps running elsewhere. This often requires setting up secure, high-throughput data transfer mechanisms and maintaining consistent metadata and state across environments. By investing in robust pipeline orchestration, organizations can automate complex ML workflows, reduce manual intervention, and accelerate the delivery of machine learning solutions at scale.
Monitoring, Logging, and Security Considerations
Monitoring and logging in multi-cloud MLOps environments require a unified approach to track performance, detect issues, and maintain security across different platforms. Each cloud provider offers its own monitoring tools, but relying solely on native solutions can lead to fragmented visibility and inconsistent alerting. A centralized monitoring strategy helps teams maintain a holistic view of their ML operations.
Security considerations become more complex in multi-cloud setups. Data encryption, identity and access management (IAM), and network security must be consistently implemented across all environments. Organizations need to establish clear security policies, implement zero-trust architectures, and regularly audit access patterns to prevent unauthorized data access or model tampering.
Here’s a Python example for implementing unified monitoring across multiple clouds:
python
import boto3
import logging
from azure.monitor.query import LogsQueryClient
from google.cloud import monitoring_v3
from datetime import datetime, timedelta
class MultiCloudMonitor:
def __init__(self):
self.aws_client = boto3.client('cloudwatch')
self.azure_client = LogsQueryClient()
self.gcp_client = monitoring_v3.MetricServiceClient()
def check_model_performance(self, model_name, threshold=0.85):
"""Monitor model performance across clouds"""
alerts = []
# AWS CloudWatch metrics
try:
aws_response = self.aws_client.get_metric_statistics(
Namespace='MLOps/Models',
MetricName='Accuracy',
Dimensions=[{'Name': 'ModelName', 'Value': model_name}],
StartTime=datetime.utcnow() - timedelta(hours=1),
EndTime=datetime.utcnow(),
Period=3600,
Statistics=['Average']
)
if aws_response['Datapoints']:
accuracy = aws_response['Datapoints'][-1]['Average']
if accuracy < threshold:
alerts.append(f"AWS: Model {model_name} accuracy below threshold: {accuracy}")
except Exception as e:
logging.error(f"AWS monitoring error: {e}")
return alerts
def log_security_event(self, event_type, details):
"""Log security events across all clouds"""
timestamp = datetime.utcnow().isoformat()
security_log = {
'timestamp': timestamp,
'event_type': event_type,
'details': details,
'severity': 'HIGH' if 'unauthorized' in event_type.lower() else 'MEDIUM'
}
# Send to centralized logging system
logging.warning(f"Security Event: {security_log}")
return security_log
# Usage example
monitor = MultiCloudMonitor()
alerts = monitor.check_model_performance('fraud_detection_v2')
if alerts:
for alert in alerts:
print(f"ALERT: {alert}")Cost Management and Optimization
Cost management in multi-cloud MLOps requires continuous monitoring and optimization strategies to prevent unexpected expenses and maximize resource efficiency. Different cloud providers have varying pricing models for compute, storage, and data transfer, making it essential to understand and track costs across all platforms.
Effective cost optimization involves several strategies: using spot instances or preemptible VMs for non-critical workloads, implementing auto-scaling to match resource usage with demand, and choosing the most cost-effective storage tiers for different types of data. Regular cost analysis helps identify opportunities for savings, such as moving infrequently accessed data to cheaper storage options or consolidating workloads in regions with lower pricing.
Here’s a Python example for multi-cloud cost tracking and optimization:
python
import boto3
import json
from datetime import datetime, timedelta
from azure.mgmt.consumption import ConsumptionManagementClient
from google.cloud import billing
class MultiCloudCostManager:
def __init__(self):
self.aws_client = boto3.client('ce') # Cost Explorer
self.cost_threshold = 1000 # Monthly threshold in USD
def get_monthly_costs(self):
"""Get costs from all cloud providers"""
costs = {}
# AWS Cost Explorer
try:
start_date = (datetime.now() - timedelta(days=30)).strftime('%Y-%m-%d')
end_date = datetime.now().strftime('%Y-%m-%d')
aws_response = self.aws_client.get_cost_and_usage(
TimePeriod={'Start': start_date, 'End': end_date},
Granularity='MONTHLY',
Metrics=['BlendedCost'],
GroupBy=[{'Type': 'DIMENSION', 'Key': 'SERVICE'}]
)
aws_total = 0
for result in aws_response['ResultsByTime']:
for group in result['Groups']:
service_cost = float(group['Metrics']['BlendedCost']['Amount'])
aws_total += service_cost
costs['aws'] = aws_total
except Exception as e:
print(f"AWS cost retrieval error: {e}")
costs['aws'] = 0
return costs
def optimize_resources(self, costs):
"""Suggest cost optimization strategies"""
recommendations = []
total_cost = sum(costs.values())
if total_cost > self.cost_threshold:
recommendations.append("Consider using spot instances for training workloads")
recommendations.append("Review storage classes and move old data to cheaper tiers")
recommendations.append("Implement auto-scaling for inference endpoints")
# Check for cost anomalies
for provider, cost in costs.items():
if cost > self.cost_threshold * 0.6: # 60% of threshold per provider
recommendations.append(f"High costs detected in {provider}: ${cost:.2f}")
return recommendations
def generate_cost_report(self):
"""Generate comprehensive cost report"""
costs = self.get_monthly_costs()
recommendations = self.optimize_resources(costs)
report = {
'timestamp': datetime.now().isoformat(),
'monthly_costs': costs,
'total_cost': sum(costs.values()),
'recommendations': recommendations,
'status': 'ALERT' if sum(costs.values()) > self.cost_threshold else 'OK'
}
return report
# Usage example
cost_manager = MultiCloudCostManager()
report = cost_manager.generate_cost_report()
print("=== Multi-Cloud Cost Report ===")
print(f"Total Monthly Cost: ${report['total_cost']:.2f}")
print(f"Status: {report['status']}")
if report['recommendations']:
print("\nCost Optimization Recommendations:")
for rec in report['recommendations']:
print(f"• {rec}")
# Created/Modified files during execution:
print("cost_report.json")Case Study: Multi-Cloud Feature Store Implementation
Implementing a feature store in a multi-cloud environment is a practical way to ensure that ML teams can access, share, and reuse features regardless of where their workloads run. In a typical enterprise scenario, data scientists might develop features in one cloud (e.g., Google Cloud Platform) while production models are deployed in another (e.g., AWS). A multi-cloud feature store bridges this gap, enabling seamless collaboration and consistent feature availability.
A successful implementation often involves deploying a managed or open-source feature store (such as Feast) with storage backends and APIs accessible from multiple clouds. Data synchronization is handled through scheduled jobs or event-driven pipelines, ensuring that feature values are up-to-date across environments. Security and access controls are enforced using cloud-native IAM and encryption mechanisms.
Here’s a short Python example using Feast to register and retrieve features in a multi-cloud setup:
python
from feast import FeatureStore
# Assume the feature store config points to a cloud-agnostic backend (e.g., GCS, S3, or Azure Blob)
store = FeatureStore(repo_path=".")
# Register a new feature view (already defined in feature_repo)
store.apply([my_feature_view])
# Retrieve features for an entity (e.g., user_id) from any cloud
entity_rows = [{"user_id": 1234}]
features = store.get_online_features(
features=["user_features:age", "user_features:activity_score"],
entity_rows=entity_rows
).to_dict()
print("Retrieved features:", features)This approach allows teams to develop, test, and serve features across clouds, supporting both batch and real-time use cases. The key is to ensure that the feature store’s metadata and data layers are consistently synchronized and accessible from all relevant environments.
Lessons Learned and Best Practices
Multi-cloud MLOps projects reveal several important lessons and best practices. First, automation is essential—manual processes quickly become unmanageable as complexity grows. Infrastructure as Code, automated CI/CD pipelines, and robust monitoring are foundational for success. Second, standardization across clouds (in terms of APIs, data formats, and security policies) reduces friction and simplifies troubleshooting.
Another lesson is the importance of observability. Centralized logging, unified monitoring dashboards, and automated alerting help teams detect and resolve issues quickly, regardless of where they occur. Security must be treated as a first-class concern, with consistent encryption, access controls, and regular audits across all clouds.
Here’s a short Python snippet illustrating automated alerting for feature drift in a multi-cloud feature store:
python
import numpy as np
def detect_feature_drift(reference_data, new_data, threshold=0.1):
"""Simple drift detection using mean difference"""
drift = abs(np.mean(reference_data) - np.mean(new_data))
if drift > threshold:
print(f"ALERT: Feature drift detected! Drift value: {drift:.3f}")
else:
print("No significant feature drift detected.")
# Example usage
reference = [0.5, 0.6, 0.55, 0.52]
new = [0.8, 0.85, 0.82, 0.81]
detect_feature_drift(reference, new)MLOps in Practice: Automation and Scaling of the Machine Learning Lifecycle
MLOps in the Era of Generative Artificial Intelligence: New Challenges and Opportunities