
Introduction: Why Model Monitoring Matters in 2025
As machine learning becomes a core component of business operations, the importance of monitoring models in production has never been greater. In 2025, organizations rely on AI-driven systems for critical decisions in finance, healthcare, retail, and many other sectors. However, deploying a model is not the end of the journey—real-world data is dynamic, and the environment in which models operate can change rapidly. Without proper monitoring, even the most accurate models can quickly become outdated, leading to poor predictions, lost revenue, or even compliance risks.
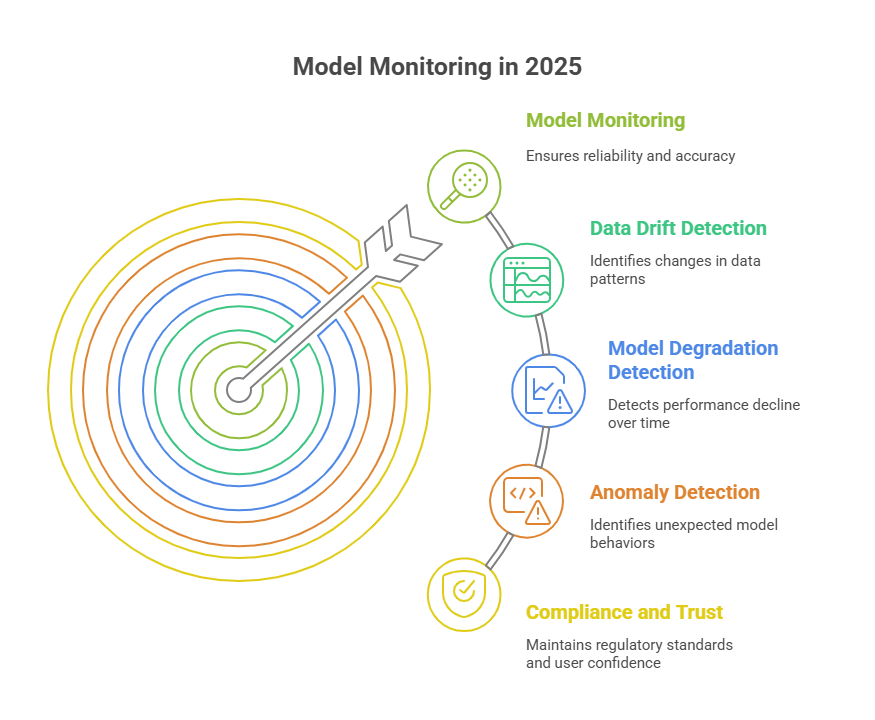
Model monitoring is the process of continuously tracking the performance and behavior of machine learning models after deployment. It ensures that models remain reliable, accurate, and aligned with business objectives. Effective monitoring helps detect issues such as data drift, model degradation, and unexpected anomalies early, allowing teams to take corrective action before problems escalate. In 2025, with the growing complexity of AI systems and stricter regulatory requirements, robust model monitoring is essential for maintaining trust, ensuring compliance, and maximizing the value of machine learning investments.
Key Challenges in Monitoring Machine Learning Models
Monitoring machine learning models in production presents several unique challenges that go beyond traditional software monitoring. One of the main difficulties is data drift, which occurs when the statistical properties of input data change over time. This can cause models to make less accurate predictions, as they were trained on data that no longer reflects the current reality.
Another significant challenge is model degradation. Over time, even well-performing models can lose their predictive power due to changes in user behavior, market conditions, or external factors. Detecting and addressing this degradation quickly is crucial to avoid negative business impacts.
Lack of ground truth is also a common issue. In many real-world scenarios, the true outcomes of predictions are not immediately available, making it hard to measure model accuracy in real time. This delay complicates the process of identifying when a model’s performance is slipping.
Scalability is an additional concern, especially for organizations running multiple models across different products or regions. Monitoring needs to be efficient and scalable to handle large volumes of predictions and data streams without introducing significant latency or overhead.
Finally, regulatory and ethical considerations are becoming more prominent. Organizations must ensure that their models remain fair, transparent, and compliant with evolving regulations. This requires monitoring not just for performance, but also for bias, explainability, and data privacy.
In summary, effective model monitoring in 2025 must address challenges related to data drift, model degradation, delayed feedback, scalability, and compliance. Overcoming these obstacles is key to maintaining reliable and trustworthy AI systems in production.
Essential Metrics for Production Model Monitoring
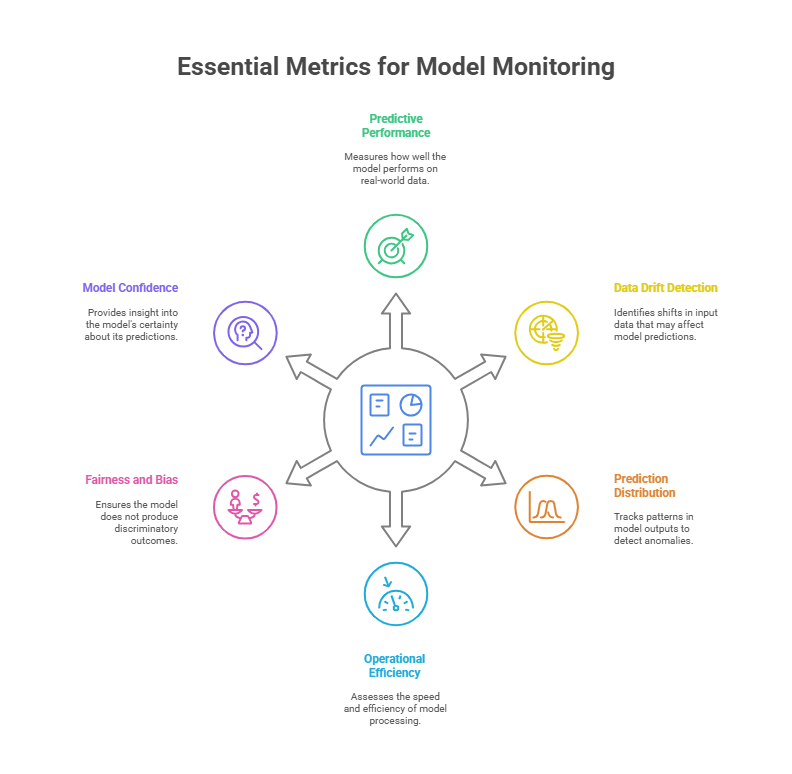
Monitoring machine learning models in production requires tracking a variety of metrics to ensure ongoing performance, reliability, and compliance. The most fundamental metrics are those that measure model accuracy and predictive quality, such as accuracy, precision, recall, F1-score for classification tasks, or mean squared error and mean absolute error for regression. These metrics help teams understand how well the model is performing on real-world data compared to its performance during training and validation.
Another crucial aspect is data drift detection. This involves monitoring the statistical properties of incoming data and comparing them to the data used during model training. Metrics such as population stability index (PSI), Kullback-Leibler divergence, or Kolmogorov-Smirnov test results can signal when the input data distribution has shifted, potentially impacting model predictions.
Prediction distribution monitoring is also important. By tracking the distribution of model outputs over time, teams can spot unusual patterns or anomalies that may indicate issues with the data pipeline or model logic. For example, a sudden spike in a particular class prediction or a narrowing of output ranges could be a red flag.
Latency and throughput are operational metrics that measure how quickly and efficiently the model processes requests. High latency or reduced throughput can affect user experience and may signal infrastructure or scaling issues.
In regulated industries, fairness and bias metrics are increasingly monitored to ensure that models do not produce discriminatory outcomes. Metrics such as disparate impact ratio or equal opportunity difference help organizations maintain ethical standards and comply with legal requirements.
Finally, model confidence and uncertainty estimates provide insight into how certain the model is about its predictions. Monitoring these values can help identify cases where the model is less reliable and may require human review or additional safeguards.
In summary, essential metrics for production model monitoring include predictive performance, data drift indicators, prediction distributions, operational efficiency, fairness, and model confidence. Tracking these metrics enables organizations to maintain high-quality, trustworthy AI systems.
Overview of Leading Model Monitoring Tools
The growing importance of model monitoring has led to the development of a wide range of specialized tools, each offering unique features to address the challenges of production AI. In 2025, several platforms stand out for their capabilities and adoption in the industry.
Evidently AI is a popular open-source tool designed specifically for monitoring data and model drift. It provides interactive dashboards, automated reports, and supports integration with various MLOps pipelines, making it a favorite among data science teams looking for transparency and ease of use.
Fiddler AI offers a comprehensive platform for model monitoring, explainability, and bias detection. Its real-time monitoring capabilities and advanced analytics help organizations quickly identify and address issues related to performance, fairness, and compliance.
Arize AI is another leading solution focused on large-scale model monitoring. It excels at tracking prediction quality, data drift, and feature importance across multiple models and environments. Arize’s intuitive interface and robust alerting system make it suitable for enterprises with complex AI deployments.
WhyLabs provides cloud-native monitoring for data and models, emphasizing scalability and automation. Its platform supports continuous monitoring, anomaly detection, and integrates seamlessly with popular MLOps tools, making it a strong choice for organizations operating at scale.
Major cloud providers have also integrated monitoring features into their MLOps offerings. Amazon SageMaker Model Monitor, Azure Machine Learning Monitoring, and Google Vertex AI Model Monitoring provide built-in tools for tracking model performance, detecting drift, and generating alerts. These solutions are particularly convenient for organizations already using these cloud ecosystems, as they offer tight integration with other services and infrastructure.
In addition to these specialized tools, general-purpose observability platforms like Prometheus and Grafana are often used to monitor operational metrics such as latency and throughput, complementing dedicated model monitoring solutions.
In summary, the leading model monitoring tools in 2025—such as Evidently AI, Fiddler AI, Arize AI, WhyLabs, and cloud-native solutions—offer a range of features to help organizations track performance, detect drift, and ensure compliance. The choice of tool depends on factors like scale, integration needs, and regulatory requirements, but all play a crucial role in maintaining robust AI systems in production.
Strategies for Detecting Data Drift and Model Degradation
Detecting data drift and model degradation is a central challenge in maintaining reliable machine learning systems in production. Data drift occurs when the statistical properties of input data change over time, while model degradation refers to the gradual decline in a model’s predictive performance. Both phenomena can lead to inaccurate predictions and business risks if not addressed promptly.
One effective strategy for detecting data drift is to continuously compare the distribution of incoming data with the data used during model training. Techniques such as the Population Stability Index (PSI), Kullback-Leibler (KL) divergence, and Kolmogorov-Smirnov (KS) tests are commonly used to quantify differences between distributions. These statistical tests can be automated to run on a regular schedule, triggering alerts when significant drift is detected.
Monitoring feature importance over time is another valuable approach. If the importance of certain features changes significantly, it may indicate that the relationships in the data have shifted, potentially impacting model performance. Tools that track feature importance can help teams identify which variables are contributing to drift or degradation.
For model degradation, tracking performance metrics such as accuracy, precision, recall, or mean squared error on recent data is essential. When ground truth labels are delayed, proxy metrics—like monitoring the distribution of predictions or the rate of outliers—can provide early warning signs. In some cases, organizations use shadow models or champion-challenger setups, where a new model runs in parallel with the production model to compare performance before making a switch.
Automated retraining pipelines are increasingly used to address both drift and degradation. When monitoring systems detect significant changes, they can trigger retraining workflows that update the model with fresh data, ensuring it remains accurate and relevant. However, it’s important to validate retrained models thoroughly before deployment to avoid introducing new issues.
In summary, effective strategies for detecting data drift and model degradation include statistical tests for distribution changes, monitoring feature importance, tracking performance metrics, using proxy indicators, and implementing automated retraining pipelines. These approaches help organizations maintain high-quality, trustworthy AI systems in dynamic environments.
Real-Time vs. Batch Monitoring: Pros and Cons
When designing a model monitoring system, organizations must choose between real-time and batch monitoring approaches, each with its own advantages and trade-offs.
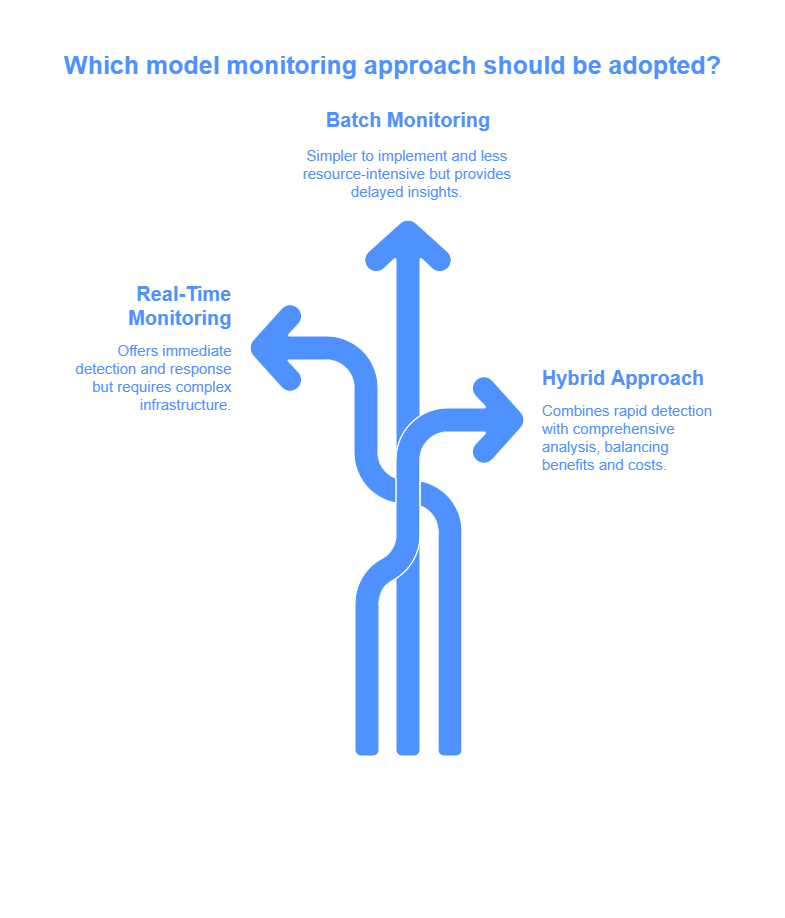
Real-time monitoring involves continuously tracking model inputs, outputs, and performance metrics as predictions are made. This approach enables immediate detection of anomalies, data drift, or operational issues, allowing teams to respond quickly to emerging problems. Real-time monitoring is especially valuable in applications where rapid intervention is critical, such as fraud detection, healthcare, or financial trading. However, it requires robust infrastructure to handle high data throughput and low-latency processing, which can increase complexity and operational costs.
Batch monitoring, on the other hand, aggregates and analyzes data at regular intervals—such as hourly, daily, or weekly. This approach is often simpler to implement and less resource-intensive, making it suitable for scenarios where immediate response is not required. Batch monitoring allows for more comprehensive analysis, as larger data samples can be processed together, providing a clearer picture of trends and long-term changes. The main drawback is the delay in detecting issues, which could result in slower response times to critical problems.
In practice, many organizations adopt a hybrid approach, using real-time monitoring for key metrics and alerts, while relying on batch analysis for deeper insights and periodic reviews. The choice between real-time and batch monitoring depends on the specific use case, business requirements, and available resources.
In summary, real-time monitoring offers rapid detection and response but requires more complex infrastructure, while batch monitoring is easier to manage and provides broader analysis at the cost of delayed insights. Balancing these approaches allows organizations to build effective and efficient model monitoring systems tailored to their needs.
Integrating Monitoring with MLOps Pipelines
Integrating model monitoring into MLOps pipelines is essential for maintaining the health and reliability of machine learning systems in production. In 2025, organizations increasingly view monitoring not as a separate activity, but as a core component of the end-to-end machine learning lifecycle.
A well-integrated monitoring system begins with automated data and model validation steps during the deployment process. As new models are trained and evaluated, monitoring hooks can be embedded to track key metrics from the very first predictions. This ensures that any issues—such as data drift, performance drops, or unexpected anomalies—are detected early, even before full-scale deployment.
Modern MLOps platforms often provide built-in support for monitoring, allowing teams to define custom metrics, set up alerting rules, and visualize trends directly within their workflow tools. For example, platforms like Amazon SageMaker, Azure Machine Learning, and Google Vertex AI offer seamless integration between model training, deployment, and monitoring, making it easier to automate the entire process.
Continuous integration and continuous deployment (CI/CD) pipelines can be extended to include monitoring checks as part of the release process. This means that every time a new model version is deployed, automated tests validate its performance and monitor its behavior in real time. If any metric falls outside predefined thresholds, the pipeline can trigger rollbacks, retraining, or human review, ensuring that only high-quality models remain in production.
Integrating monitoring with MLOps pipelines also facilitates collaboration between data scientists, engineers, and operations teams. Shared dashboards, automated reports, and centralized alerting help everyone stay informed and respond quickly to emerging issues. This collaborative approach reduces silos and accelerates the feedback loop, leading to more robust and reliable AI systems.
In summary, embedding monitoring into MLOps pipelines ensures that model performance, data quality, and operational health are continuously tracked and managed. This integration supports rapid detection of issues, automated responses, and effective collaboration, all of which are critical for successful machine learning operations in production.
Case Studies: Effective Model Monitoring in Practice
Real-world case studies highlight the tangible benefits of effective model monitoring and demonstrate how organizations can address common challenges in production AI.
One example comes from the financial sector, where a large bank deployed a credit risk model to assess loan applications. By integrating real-time monitoring into their MLOps pipeline, the bank was able to detect data drift caused by sudden changes in customer behavior during an economic downturn. Automated alerts prompted the data science team to retrain the model with recent data, restoring predictive accuracy and reducing the risk of bad loans.
In e-commerce, a leading retailer used batch monitoring to track the performance of its recommendation engine. By analyzing prediction distributions and customer engagement metrics on a daily basis, the team identified a gradual decline in model effectiveness due to seasonal changes in shopping patterns. This insight led to targeted model updates and improved personalization, resulting in higher conversion rates and customer satisfaction.
Healthcare organizations have also benefited from robust monitoring systems. For instance, a hospital network implemented both real-time and batch monitoring for its diagnostic AI tools. Real-time alerts flagged unusual prediction patterns that could indicate data quality issues or model errors, while batch analysis provided deeper insights into long-term trends and potential biases. This dual approach helped maintain high standards of patient care and regulatory compliance.
These case studies illustrate that effective model monitoring—whether real-time, batch, or hybrid—enables organizations to quickly detect and address issues, adapt to changing environments, and maximize the value of their AI investments. By learning from practical examples, teams can design monitoring strategies that are both proactive and responsive, ensuring the ongoing success of machine learning in production.
Future Trends in Model Monitoring
The field of model monitoring is evolving rapidly, driven by the increasing complexity of machine learning systems and the growing expectations for reliability, transparency, and compliance. In 2025, several key trends are shaping the future of model monitoring.
One major trend is the adoption of AI-powered monitoring. Modern monitoring tools are beginning to use machine learning algorithms themselves to detect subtle patterns of drift, anomalies, or performance degradation that might be missed by traditional statistical methods. These intelligent systems can adapt thresholds dynamically, prioritize alerts based on business impact, and even suggest corrective actions, making monitoring more proactive and less reliant on manual oversight.
Another important development is the integration of monitoring with explainability and fairness analysis. As regulations and public scrutiny around AI increase, organizations are expected to monitor not only for accuracy and drift but also for bias, fairness, and transparency. Future monitoring platforms will provide built-in tools for tracking fairness metrics, generating explanations for predictions, and ensuring compliance with ethical standards.
Unified observability platforms are also on the rise. Instead of using separate tools for infrastructure, application, and model monitoring, organizations are moving toward integrated solutions that provide a holistic view of system health. This convergence allows teams to correlate model performance with infrastructure events, user behavior, or external factors, leading to faster root cause analysis and more effective incident response.
The trend toward real-time, streaming data monitoring is accelerating, especially in industries where rapid response is critical. Advances in cloud computing and edge AI are enabling organizations to monitor models at scale, across distributed environments, and with minimal latency.
Finally, automation and self-healing systems are becoming more common. Monitoring platforms are increasingly capable of triggering automated retraining, rolling back to previous model versions, or escalating issues to human operators when necessary. This reduces downtime, minimizes risk, and ensures that models remain robust in changing environments.
In summary, the future of model monitoring will be defined by AI-driven intelligence, integrated fairness and explainability, unified observability, real-time capabilities, and greater automation. Organizations that embrace these trends will be better equipped to maintain trustworthy, high-performing AI systems in production.
Conclusion: Building a Robust Monitoring Framework for 2025
As machine learning continues to transform industries, building a robust monitoring framework is essential for ensuring the long-term success and reliability of AI systems. In 2025, effective model monitoring goes far beyond tracking basic performance metrics—it encompasses data drift detection, fairness and compliance checks, operational health, and the ability to respond rapidly to emerging issues.
A strong monitoring framework should be seamlessly integrated with the organization’s MLOps pipelines, enabling automated validation, real-time and batch analysis, and collaborative workflows. By leveraging modern tools and adopting best practices, teams can detect problems early, adapt to changing data and business conditions, and maintain high standards of quality and trust.
Looking ahead, the most successful organizations will be those that treat monitoring as a continuous, strategic process rather than a one-time task. By staying informed about new trends—such as AI-powered monitoring, unified observability, and automation—teams can future-proof their AI operations and deliver sustained value from their machine learning investments.
In conclusion, robust model monitoring is not just a technical necessity but a foundation for responsible, effective, and innovative AI in production. By prioritizing monitoring and embracing the latest advancements, organizations can confidently scale their AI initiatives and meet the challenges of an ever-changing world.
The Future of MLOps: Trends and Innovations in Machine Learning Operations
MLOps: from data science to business value
The best MLOps tools of 2025 – comparison and recommendations