
Introduction: The Importance of Resource Optimization in MLOps
As machine learning becomes an integral part of modern business operations, the scale and complexity of ML workloads continue to grow rapidly. This growth brings significant challenges in managing compute, storage, and networking resources efficiently—especially in cloud environments where costs can escalate quickly without proper oversight. Resource optimization in MLOps is therefore essential for balancing performance, scalability, and cost-effectiveness.
Why Resource Optimization Matters
Machine learning workloads are often resource-intensive, requiring powerful GPUs, large memory, and high-throughput storage. Inefficient resource usage not only inflates cloud bills but can also lead to performance bottlenecks and longer training or inference times. Optimizing resource utilization helps organizations reduce operational costs, improve system responsiveness, and allocate budgets more strategically.
The Role of MLOps in Resource Management
MLOps practices provide the framework and tools to automate and monitor resource usage throughout the ML lifecycle. From data preprocessing and feature engineering to model training, deployment, and monitoring, MLOps pipelines can be designed to dynamically allocate resources based on workload demands. This automation ensures that resources are neither underutilized nor overprovisioned.
Balancing Cost and Performance
Effective resource optimization requires a careful balance. Overly aggressive cost-cutting can degrade model accuracy or increase latency, while excessive resource allocation wastes budget. MLOps teams must continuously monitor performance metrics alongside cost data to make informed decisions about scaling, instance types, and storage options.
Strategic Benefits
Cost Savings: Lower cloud bills through efficient resource allocation and usage.
Improved Performance: Faster training and inference by matching resources to workload needs.
Scalability: Ability to handle growing data volumes and model complexity without exponential cost increases.
Sustainability: Reduced energy consumption and environmental impact through optimized infrastructure.
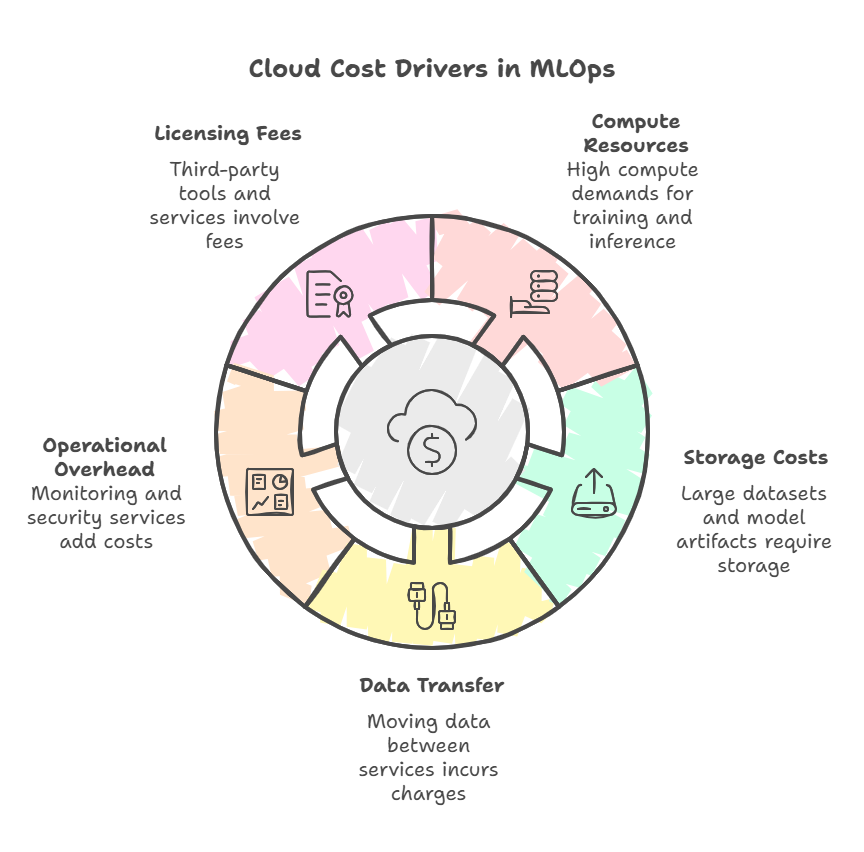
Understanding Cloud Cost Drivers in Machine Learning
Effectively managing costs in machine learning operations requires a deep understanding of the primary cloud cost drivers. Cloud environments offer flexible and scalable resources, but without careful oversight, expenses can quickly escalate. Identifying and controlling these cost factors is essential for building cost-effective MLOps workflows.
Compute Resources
Compute is often the largest cost component in ML workloads. Training complex models, especially deep learning architectures, demands significant CPU, GPU, or TPU resources. The choice of instance types, the duration of training jobs, and the efficiency of resource utilization directly impact costs. Inference workloads also consume compute resources, particularly when serving models at scale or with low latency requirements.
Storage Costs
Storing large datasets, feature stores, model artifacts, and logs can incur substantial expenses. Costs vary depending on storage type—object storage, block storage, or high-performance file systems—and data access patterns. Retaining multiple versions of datasets and models for reproducibility further increases storage needs.
Data Transfer and Networking
Data movement between services, regions, or cloud providers can generate significant egress charges. Frequent data transfers during training, feature extraction, or model serving can add up, especially in multi-cloud or hybrid architectures.
Operational Overhead
Monitoring, logging, orchestration, and security services consume additional resources. While these are critical for reliable MLOps, inefficient configurations or excessive data retention can inflate costs.
Licensing and Third-Party Services
Using managed ML platforms, specialized AI services, or third-party tools may involve licensing fees or usage-based charges that contribute to overall expenses.
Right-Sizing Compute Resources for ML Workloads
Right-sizing compute resources is a fundamental strategy for optimizing costs in MLOps while maintaining performance and scalability. It involves selecting the appropriate type and size of compute instances—whether CPUs, GPUs, or specialized accelerators—based on the specific requirements of your machine learning workloads.
Why Right-Sizing Matters
Over-provisioning resources leads to unnecessary expenses, while under-provisioning can cause performance bottlenecks, longer training times, and increased latency in model serving. Right-sizing ensures that you allocate just enough resources to meet workload demands efficiently, balancing cost and performance.
Factors to Consider
Workload Type:
Training deep learning models typically requires GPUs or TPUs, while simpler models or data preprocessing may run efficiently on CPUs.
Job Duration and Frequency:
Short, frequent jobs may benefit from smaller, faster instances, whereas long-running training tasks might be more cost-effective on larger, high-performance machines.
Scalability Needs:
Consider whether your workload can be parallelized or distributed across multiple instances to reduce time-to-train.
Resource Utilization Metrics:
Monitor CPU/GPU utilization, memory usage, and I/O throughput to identify underused or overburdened resources.
Tools and Techniques
Cloud Provider Recommendations:
Use cloud provider tools that suggest optimal instance types based on historical usage.
Auto-Scaling:
Implement auto-scaling groups or Kubernetes autoscalers to dynamically adjust resources based on demand.
Spot and Preemptible Instances:
For non-critical or batch workloads, leverage discounted spot instances to reduce costs.
Profiling and Benchmarking:
Profile your ML workloads to understand resource requirements and optimize code for better efficiency.
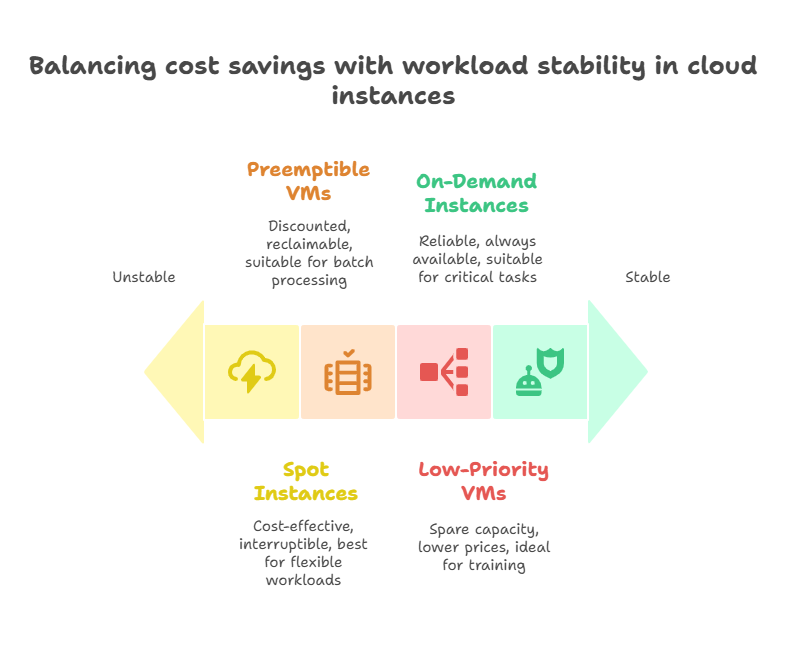
Leveraging Spot and Preemptible Instances for Cost Savings
As machine learning workloads grow in scale and complexity, managing cloud infrastructure costs becomes a critical concern for organizations. One of the most effective strategies for reducing expenses without compromising performance is leveraging spot and preemptible instances offered by major cloud providers. These instances provide access to spare compute capacity at significantly lower prices, enabling cost-efficient training and inference in MLOps workflows.
What Are Spot and Preemptible Instances?
Spot instances (AWS), preemptible VMs (Google Cloud), and low-priority VMs (Azure) are cloud compute resources offered at discounted rates compared to on-demand instances. They are available when cloud providers have excess capacity and can be reclaimed with short notice, typically within minutes. This makes them ideal for fault-tolerant, flexible workloads that can handle interruptions.
Benefits for MLOps
Significant Cost Reduction: Spot and preemptible instances can be up to 70-90% cheaper than regular instances, leading to substantial savings on large-scale training jobs.
Scalability: Access to large pools of discounted resources allows teams to scale training and batch inference workloads cost-effectively.
Resource Efficiency: Using these instances helps optimize cloud resource utilization by leveraging otherwise idle capacity.
Challenges and Considerations
Interruption Handling: Since these instances can be terminated unexpectedly, ML workflows must be designed to handle interruptions gracefully. This includes checkpointing training progress, using distributed training frameworks, and implementing retry logic.
Job Suitability: Spot and preemptible instances are best suited for non-critical, batch, or asynchronous workloads. Real-time inference or latency-sensitive applications may require more stable resources.
Complexity: Managing a mix of on-demand and spot instances adds operational complexity, requiring sophisticated orchestration and monitoring.
Best Practices for Using Spot and Preemptible Instances
Checkpointing: Regularly save model state during training to resume from the last checkpoint after interruptions.
Distributed Training: Use frameworks like Horovod or TensorFlow’s distributed strategies to parallelize training across multiple instances.
Auto-Scaling and Fallback: Combine spot instances with on-demand instances to maintain availability, automatically falling back when spot capacity is unavailable.
Monitoring and Alerts: Implement monitoring to detect instance interruptions and trigger recovery workflows promptly.
Efficient Data Storage and Management Strategies
Efficient data storage and management are critical components of cost-effective and scalable MLOps workflows. As machine learning projects grow, the volume of data—ranging from raw inputs to processed features and model artifacts—can become substantial, leading to increased storage costs and potential performance bottlenecks. Implementing smart storage strategies ensures that data is accessible, secure, and optimized for both cost and performance.
Choosing the Right Storage Solutions
Different types of data require different storage approaches. Raw and historical data may be stored in cost-effective, durable object storage systems like Amazon S3, Google Cloud Storage, or Azure Blob Storage. Processed data and feature sets that require frequent access might be better suited for faster, more expensive storage such as SSD-backed databases or data warehouses.
Data Lifecycle Management
Implementing data lifecycle policies helps manage storage costs by automatically transitioning data between storage tiers based on age, access frequency, or relevance. For example, recent data can reside in high-performance storage, while older data is archived in cold storage solutions like Amazon S3 Glacier or Google Coldline.
Data Compression and Format Optimization
Using efficient data formats such as Parquet or ORC, which support columnar storage and compression, reduces storage size and speeds up data retrieval. Compression algorithms further minimize storage costs and improve network transfer times.
Versioning and Lineage
Maintaining versioned datasets and tracking data lineage are essential for reproducibility and compliance. Tools like DVC, LakeFS, or Delta Lake enable version control for large datasets, allowing teams to track changes, roll back to previous versions, and understand data transformations.
Access Control and Security
Securing data storage with encryption, access controls, and audit logging protects sensitive information and ensures compliance with regulations. Role-based access control (RBAC) and integration with identity management systems help enforce data governance policies.
Automating Resource Scaling and Scheduling
Automating resource scaling and scheduling is essential for optimizing performance and controlling costs in MLOps workflows. As machine learning workloads can be highly variable—ranging from intensive training jobs to lightweight inference requests—dynamic allocation of compute resources ensures efficient utilization without overprovisioning.
Why Automate Scaling and Scheduling?
Manual resource management is inefficient and error-prone, especially at scale. Automated scaling adjusts resources based on workload demand, ensuring that ML tasks have sufficient compute power when needed and that idle resources are minimized. Scheduling allows workloads to run at optimal times, such as during off-peak hours or when cheaper resources are available.
Key Techniques
Horizontal Scaling: Adding or removing compute instances (e.g., Kubernetes pods) based on metrics like CPU usage or request rates.
Vertical Scaling: Adjusting the size or power of individual instances to match workload requirements.
Job Scheduling: Using tools like Apache Airflow or Kubernetes CronJobs to run batch training or data processing jobs at scheduled intervals.
Spot Instance Utilization: Scheduling non-critical jobs on discounted spot or preemptible instances to reduce costs.
Example: Python Script for Simple Autoscaling Decision
Below is a simplified Python example that decides whether to scale up or down based on CPU utilization:
python
def autoscale(current_cpu_usage, scale_up_threshold=70, scale_down_threshold=30, current_instances=3):
if current_cpu_usage > scale_up_threshold:
new_instances = current_instances + 1
print(f"CPU usage {current_cpu_usage}% > {scale_up_threshold}%, scaling up to {new_instances} instances.")
elif current_cpu_usage < scale_down_threshold and current_instances > 1:
new_instances = current_instances - 1
print(f"CPU usage {current_cpu_usage}% < {scale_down_threshold}%, scaling down to {new_instances} instances.")
else:
new_instances = current_instances
print(f"CPU usage {current_cpu_usage}%, no scaling action needed. Instances remain at {new_instances}.")
return new_instances
# Example usage
current_instances = 3
cpu_usages = [25, 35, 80, 65, 20]
for usage in cpu_usages:
current_instances = autoscale(usage, current_instances=current_instances)Cost-Aware Model Training and Hyperparameter Tuning
Cost-aware model training and hyperparameter tuning are essential strategies in MLOps to balance model performance with resource efficiency. As machine learning workloads grow in complexity and scale, optimizing the use of compute resources during training and tuning can significantly reduce operational costs without compromising model quality.
Why Cost-Aware Training Matters
Training large models or running extensive hyperparameter searches can be expensive, especially when using cloud-based GPUs or TPUs. Cost-aware strategies help teams make informed decisions about resource allocation, experiment design, and scheduling to maximize return on investment.
Key Approaches
Early Stopping:
Automatically terminate training runs that show poor performance early, saving compute time and costs.
Adaptive Hyperparameter Search:
Use efficient search algorithms like Bayesian optimization or Hyperband that focus resources on promising configurations.
Resource-Aware Scheduling:
Schedule training jobs during off-peak hours or on discounted spot/preemptible instances to reduce costs.
Model Size Optimization:
Train smaller or compressed models when appropriate to reduce training time and resource usage.
Parallel and Distributed Training:
Optimize parallelism to balance speed and cost, avoiding over-provisioning.
Example: Simple Python Early Stopping Implementation
python
def early_stopping(validation_losses, patience=3):
"""
Simple early stopping logic.
Stops training if validation loss does not improve for 'patience' epochs.
"""
best_loss = float('inf')
epochs_no_improve = 0
for epoch, loss in enumerate(validation_losses):
if loss < best_loss:
best_loss = loss
epochs_no_improve = 0
else:
epochs_no_improve += 1
if epochs_no_improve >= patience:
print(f"Early stopping triggered at epoch {epoch}")
return True
return False
# Example usage
val_losses = [0.5, 0.4, 0.35, 0.36, 0.37, 0.38]
early_stopping(val_losses)Monitoring and Analyzing Cloud Spend in MLOps
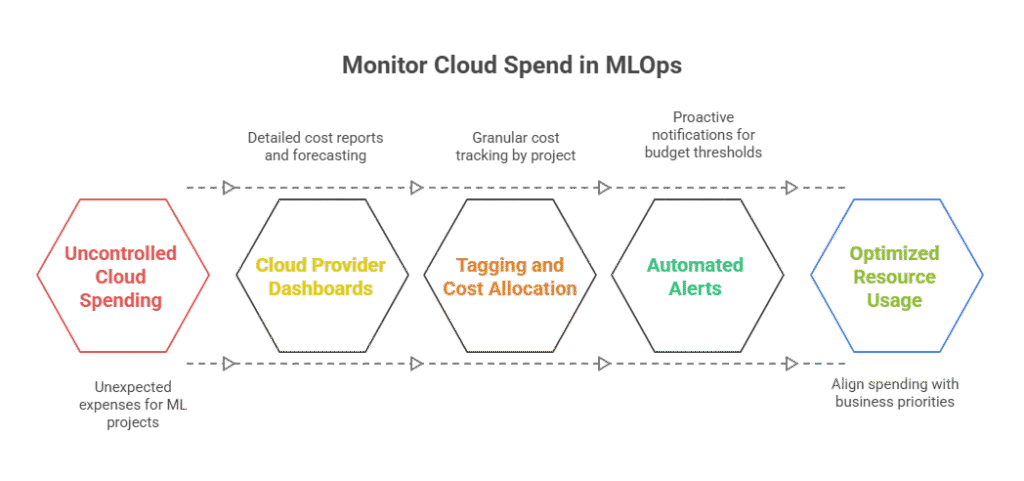
As machine learning workloads scale in cloud environments, monitoring and analyzing cloud spend becomes crucial for maintaining cost efficiency and operational sustainability. Without proper oversight, ML projects can quickly incur unexpected expenses due to resource overprovisioning, inefficient workflows, or data transfer costs. Effective cost monitoring enables teams to optimize resource usage, forecast budgets, and align spending with business priorities.
Why Monitor Cloud Spend in MLOps?
Cloud providers offer flexible, on-demand resources, but this flexibility can lead to cost unpredictability. ML workloads often involve compute-intensive training, large-scale data storage, and frequent data movement—all of which contribute to cloud bills. Monitoring spend in real time helps identify cost drivers, detect anomalies, and prevent budget overruns.
Key Metrics to Track
Compute Costs: Expenses related to CPU, GPU, and TPU usage during training and inference.
Storage Costs: Charges for storing raw data, features, models, and logs.
Data Transfer Fees: Costs incurred from moving data between regions, services, or clouds.
Idle Resource Costs: Expenses from underutilized or orphaned resources.
Service-Specific Charges: Fees for managed services like orchestration, monitoring, or model hosting.
Tools and Techniques
Cloud Provider Dashboards: AWS Cost Explorer, Google Cloud Billing, and Azure Cost Management provide detailed cost reports and forecasting.
Tagging and Cost Allocation: Assign tags to resources by project, team, or environment to enable granular cost tracking.
Third-Party Platforms: Tools like CloudHealth, Spot.io, or Apptio offer advanced cost analytics and optimization recommendations.
Automated Alerts: Set up budget thresholds and anomaly detection to receive proactive notifications.
Best Practices
Implement consistent resource tagging across all ML assets.
Regularly review cost reports and identify optimization opportunities.
Automate shutdown of idle or unused resources.
Optimize data storage tiers and minimize unnecessary data transfers.
Educate teams on cost implications of their ML workflows.
Multi-Cloud and Hybrid Cloud Cost Optimization
As organizations increasingly adopt multi-cloud and hybrid cloud strategies for their machine learning workloads, optimizing costs across diverse environments becomes both more complex and more critical. Multi-cloud architectures offer flexibility and resilience but can lead to fragmented resource usage and unpredictable expenses if not managed carefully.
Challenges in Multi-Cloud Cost Management
Managing costs across multiple cloud providers involves dealing with different pricing models, billing cycles, and resource types. Data transfer fees between clouds, inconsistent tagging, and lack of centralized visibility can result in overspending and inefficiencies. Hybrid environments, combining on-premises and cloud resources, add further complexity in tracking and optimizing costs.
Strategies for Cost Optimization
Centralized Cost Monitoring:
Use multi-cloud cost management platforms that aggregate billing data from all providers, providing unified dashboards and reports.
Consistent Resource Tagging:
Implement standardized tagging policies across clouds and on-premises infrastructure to enable accurate cost allocation and accountability.
Data Transfer Minimization:
Design architectures to reduce cross-cloud data movement, such as colocating compute and storage or using edge caching.
Workload Placement Optimization:
Analyze cost-performance trade-offs to place workloads in the most cost-effective environment, leveraging spot instances or reserved capacity where appropriate.
Automated Scaling and Scheduling:
Use automation to scale resources dynamically and schedule non-critical workloads during off-peak hours or on cheaper platforms.
Best Practices
Establish governance frameworks for multi-cloud cost management.
Regularly audit and reconcile cloud bills to detect anomalies.
Educate teams on cost implications of multi-cloud deployments.
Leverage cloud provider tools alongside third-party solutions for comprehensive insights.
Best Practices for Budgeting and Cost Governance in MLOps
Effective budgeting and cost governance are essential for managing the financial aspects of machine learning operations, especially as organizations scale their AI initiatives. Without clear policies and oversight, ML projects can quickly exceed budgets, leading to wasted resources and reduced return on investment. Implementing best practices in budgeting and cost governance helps organizations align spending with business priorities while maintaining operational efficiency.
Establish Clear Budgeting Processes
Start by defining budgets for ML projects, teams, or business units. Use historical data and forecasts to set realistic spending limits. Involve finance, data science, and engineering stakeholders to ensure budgets reflect both technical needs and business goals.
Implement Resource Tagging and Cost Allocation
Consistently tag all cloud and on-premises resources related to ML workflows. This enables granular cost tracking and accountability, allowing teams to understand where and how resources are consumed.
Use Automated Cost Monitoring and Alerts
Leverage cloud-native tools and third-party platforms to monitor spending in real time. Set up automated alerts for budget thresholds, unusual spikes, or forecast overruns to enable proactive management.
Optimize Resource Usage
Encourage teams to right-size compute instances, use spot or preemptible instances for non-critical workloads, and implement data lifecycle policies to reduce storage costs. Regularly review resource utilization reports to identify inefficiencies.
Governance and Policy Enforcement
Define and enforce policies for resource provisioning, usage, and decommissioning. Use infrastructure-as-code and automated workflows to ensure compliance with cost governance rules.
Regular Reporting and Review
Generate regular cost reports for stakeholders, highlighting trends, savings opportunities, and areas of concern. Conduct periodic reviews to adjust budgets and policies based on evolving needs.
Case Studies: Successful Cost Optimization in MLOps
Cost optimization is a critical concern for organizations scaling their machine learning operations. Real-world case studies demonstrate how companies have effectively managed and reduced their MLOps expenses while maintaining performance and scalability.
Case Study 1: Tech Startup Reduces Cloud Costs with Spot Instances
A fast-growing tech startup leveraged AWS Spot Instances to run their model training workloads at a fraction of the cost of on-demand instances. By designing their training pipelines to be fault-tolerant and capable of checkpointing, they could safely use spot instances despite potential interruptions. This strategy reduced their cloud compute costs by over 60%, enabling them to allocate more budget to innovation and experimentation.
Case Study 2: Financial Services Firm Implements Resource Right-Sizing
A financial services company conducted a comprehensive audit of their ML infrastructure and discovered significant overprovisioning of compute resources. By implementing automated monitoring and right-sizing policies, they adjusted instance types and scaled resources dynamically based on workload demands. This optimization led to a 30% reduction in monthly cloud expenses without impacting model performance or availability.
Case Study 3: E-commerce Platform Optimizes Data Storage
An e-commerce platform optimized their data storage costs by implementing tiered storage policies. Frequently accessed data and features were stored in high-performance storage, while older, less frequently used data was moved to cost-effective cold storage solutions. Additionally, they adopted efficient data formats and compression techniques. These changes resulted in a 40% reduction in storage costs and improved data retrieval times.
Lessons Learned
Design for Cost Efficiency: Build pipelines and models that can leverage discounted or lower-cost resources without compromising quality.
Automate Monitoring and Scaling: Use automated tools to continuously monitor resource usage and adjust allocations dynamically.
Optimize Data Management: Implement data lifecycle policies and use efficient storage formats to reduce costs.
Collaborate Across Teams: Align data science, engineering, and finance teams to balance performance and budget goals.
MLOps in the Era of Generative Artificial Intelligence: New Challenges and Opportunities
Real-Time Monitoring Strategies for LLMs in MLOps Pipelines
Understanding Machine Learning Operations: A Comprehensive Guide