

Introduction to ML Workflow Orchestration
Machine learning workflows are rarely simple, one-off scripts. In real-world projects, they often involve a series of interconnected steps: data ingestion, preprocessing, feature engineering, model training, evaluation, deployment, and monitoring. Orchestrating these steps efficiently is crucial for building robust, scalable, and reproducible ML systems.
ML workflow orchestration refers to the process of automating, scheduling, and managing these interconnected tasks. Instead of running each step manually, orchestration tools allow you to define dependencies, automate execution, handle failures, and monitor progress. This not only saves time but also reduces human error and makes it easier to scale and maintain ML projects as they grow in complexity.
Effective orchestration is especially important in production environments, where workflows need to be reliable, repeatable, and able to handle large volumes of data. It also enables collaboration between data scientists, engineers, and operations teams, ensuring that models can move smoothly from experimentation to deployment and ongoing maintenance.
Overview of Apache Airflow and Kubeflow
Two of the most popular tools for orchestrating ML workflows are Apache Airflow and Kubeflow. Each has its own strengths and is suited to different types of projects and infrastructure.
Apache Airflow is an open-source platform for programmatically authoring, scheduling, and monitoring workflows. It uses Directed Acyclic Graphs (DAGs) to represent workflows, where each node is a task and edges define dependencies. Airflow is highly extensible, supports a wide range of integrations, and is widely used for data engineering and ETL pipelines. In ML projects, Airflow is often used to automate data preprocessing, model training, and batch inference tasks.
Kubeflow, on the other hand, is an open-source machine learning toolkit built on top of Kubernetes. It is designed specifically for deploying, scaling, and managing complex ML workflows in cloud-native environments. Kubeflow Pipelines provide a way to define, deploy, and manage end-to-end ML workflows as reusable components. Kubeflow excels in scenarios where you need to leverage Kubernetes for resource management, scalability, and reproducibility, and it integrates well with other cloud-native tools.
While both tools can orchestrate ML workflows, Airflow is generally preferred for data-centric and ETL-heavy pipelines, while Kubeflow is ideal for ML-centric, containerized, and cloud-native workflows. Many organizations use both, depending on the specific requirements of each project.
Key Differences and Use Cases: Airflow vs. Kubeflow
While both Apache Airflow and Kubeflow are powerful tools for orchestrating machine learning workflows, they are designed with different philosophies and excel in distinct scenarios.
Airflow is a general-purpose workflow orchestrator. It is highly flexible and language-agnostic, making it a popular choice for data engineering, ETL, and batch processing tasks. Airflow’s workflows are defined as Python code using Directed Acyclic Graphs (DAGs), which makes it easy to express complex dependencies and schedule jobs. Airflow integrates well with a wide range of data sources, databases, and cloud services, and is often used to automate data ingestion, transformation, and model training steps in ML pipelines.
Kubeflow, in contrast, is purpose-built for machine learning on Kubernetes. It leverages Kubernetes’ native capabilities for container orchestration, resource management, and scaling. Kubeflow Pipelines allow you to define ML workflows as a series of containerized steps, each encapsulating a specific task (such as data preprocessing, training, or deployment). This approach ensures reproducibility and portability across environments. Kubeflow also provides specialized components for hyperparameter tuning, model serving, and experiment tracking, making it a comprehensive platform for end-to-end ML lifecycle management.
Use cases:
Airflow is ideal when your workflow involves a lot of data movement, ETL, or integration with non-ML systems, and when you want to leverage existing Python code and libraries. Kubeflow shines in cloud-native, containerized environments where you need to scale ML workloads, manage experiments, and deploy models seamlessly on Kubernetes.
In practice, some organizations use Airflow for data engineering and initial ML steps, then hand off to Kubeflow for model training, tuning, and deployment—combining the strengths of both platforms.
Designing Modular ML Pipelines
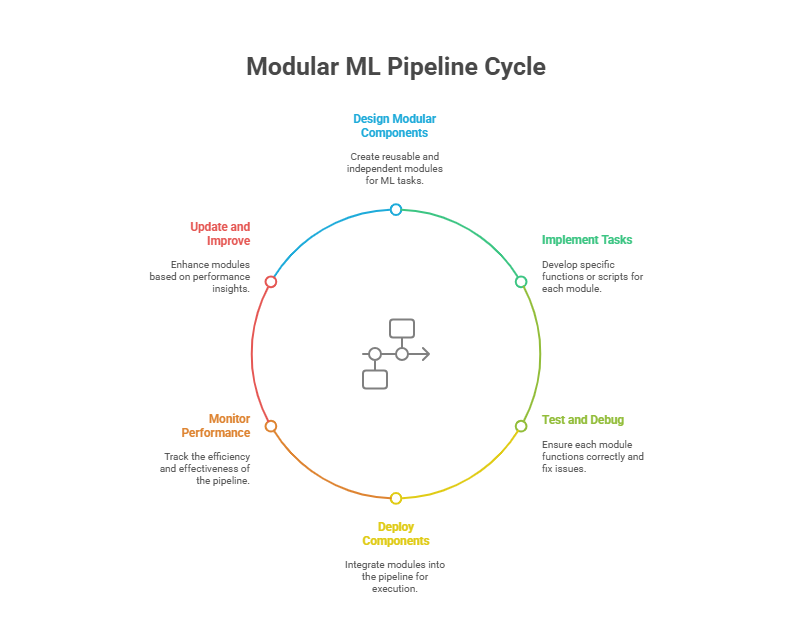
A modular approach to building ML pipelines is essential for scalability, maintainability, and collaboration. Modular pipelines break down the end-to-end ML workflow into discrete, reusable components or steps, each responsible for a specific function—such as data ingestion, feature engineering, model training, evaluation, and deployment.
Benefits of modularity include easier debugging, the ability to reuse components across projects, and the flexibility to update or swap out individual steps without disrupting the entire workflow. This design also supports parallel development, where different team members can work on separate modules simultaneously.
When designing modular pipelines with Airflow, you define each step as a task in a DAG, specifying dependencies and scheduling logic. For example, you might have separate tasks for data extraction, cleaning, feature generation, and model training, each implemented as a Python function or script.
With Kubeflow, each pipeline step is typically a containerized component. You define the pipeline using a Python SDK or YAML, specifying the sequence of steps and how data flows between them. Each component can be developed, tested, and deployed independently, and reused in different pipelines.
Modular design not only improves code quality and reusability but also makes it easier to scale and automate ML workflows, whether you’re using Airflow, Kubeflow, or a combination of both.
Integrating Data Ingestion and Preprocessing
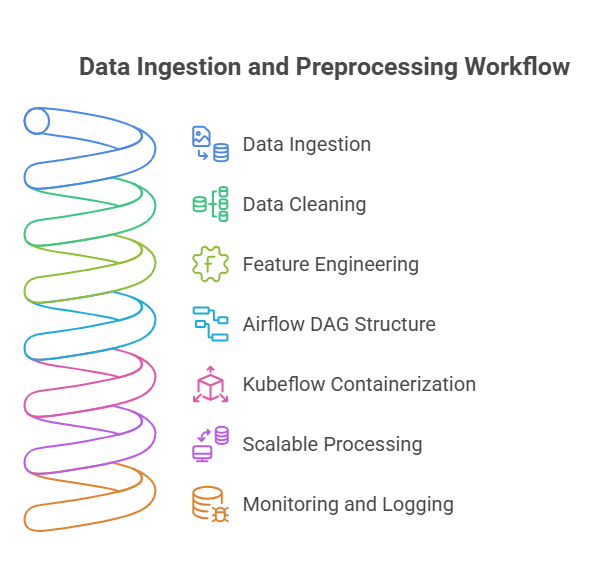
Data ingestion and preprocessing are foundational steps in any machine learning workflow. Efficiently integrating these steps into orchestrated pipelines ensures that models are trained on high-quality, up-to-date data and that the entire process is automated and reproducible.
With Airflow, data ingestion tasks can be scheduled to pull data from various sources such as databases, APIs, or cloud storage. These tasks can be chained with preprocessing steps—like cleaning, normalization, or feature engineering—using Python operators or custom scripts. Airflow’s DAG structure allows you to define dependencies, so preprocessing only starts once data ingestion is complete. This approach is especially useful for batch workflows, where data is processed in regular intervals.
Kubeflow takes a containerized approach. Each step—data ingestion, cleaning, transformation—is encapsulated in its own container. These components are connected in a pipeline, ensuring that data flows seamlessly from one step to the next. Kubeflow’s integration with Kubernetes allows for scalable, distributed processing, which is particularly valuable when working with large datasets or real-time data streams.
Both tools support monitoring and logging, making it easy to track data lineage and debug issues. By automating data ingestion and preprocessing, teams can ensure consistency, reduce manual errors, and accelerate the path from raw data to model-ready datasets.
Automating Model Training and Hyperparameter Tuning
Automating model training and hyperparameter tuning is a key advantage of using orchestration tools like Airflow and Kubeflow. This automation not only saves time but also enables systematic experimentation and reproducibility.
In Airflow, model training can be implemented as a task within a DAG. You can schedule training jobs to run on new data, trigger retraining based on specific events, or orchestrate multiple training runs with different parameters. While Airflow itself doesn’t provide built-in hyperparameter tuning, you can integrate it with external libraries (like Optuna or Hyperopt) or custom scripts to automate the search for optimal model parameters.
Kubeflow offers more advanced support for ML-specific tasks. Its Pipelines component allows you to define training steps as containerized components, and its Katib module provides native hyperparameter tuning capabilities. With Katib, you can specify search spaces, optimization algorithms, and objective metrics, and Kubeflow will automatically run multiple training jobs in parallel to find the best configuration. This is especially powerful in cloud environments, where resources can be dynamically allocated and scaled.
Automating these steps ensures that model development is efficient, repeatable, and less prone to human error. It also enables continuous improvement, as models can be retrained and optimized regularly in response to new data or changing requirements.
Model Deployment Strategies with Airflow and Kubeflow
Model deployment is a critical phase where trained models are made available for inference in production environments. Both Airflow and Kubeflow offer different approaches to automate and manage this process.
Airflow excels at orchestrating deployment workflows that involve multiple steps and integrations. You can create DAGs that handle model validation, containerization, deployment to various endpoints (REST APIs, batch processing systems, or cloud services), and post-deployment testing. Airflow’s flexibility allows you to integrate with deployment platforms like Docker, Kubernetes, or cloud-specific services.
Kubeflow provides more native support for ML model deployment through KServe (formerly KFServing), which offers serverless model serving on Kubernetes. Kubeflow Pipelines can seamlessly transition from training to deployment, automatically packaging models and deploying them as scalable services. This approach is particularly powerful for real-time inference scenarios.
Here’s a simple Python example showing how to deploy a model using Airflow:
python
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.operators.bash_operator import BashOperator
from datetime import datetime
import joblib
import requests
def validate_model(**context):
# Load and validate the trained model
model = joblib.load('/models/latest_model.pkl')
# Perform validation checks
if model.score > 0.85:
return True
else:
raise ValueError("Model performance below threshold")
def deploy_to_api(**context):
# Deploy model to REST API endpoint
model_path = '/models/latest_model.pkl'
deployment_config = {
'model_path': model_path,
'endpoint': 'production',
'replicas': 3
}
# Simulate API call to deployment service
response = requests.post('http://deployment-service/deploy', json=deployment_config)
if response.status_code == 200:
print("Model deployed successfully")
else:
raise Exception("Deployment failed")
dag = DAG(
'model_deployment',
start_date=datetime(2024, 1, 1),
schedule_interval=None,
catchup=False
)
validate_task = PythonOperator(
task_id='validate_model',
python_callable=validate_model,
dag=dag
)
deploy_task = PythonOperator(
task_id='deploy_model',
python_callable=deploy_to_api,
dag=dag
)
health_check = BashOperator(
task_id='health_check',
bash_command='curl -f http://api-endpoint/health || exit 1',
dag=dag
)
validate_task >> deploy_task >> health_check
# Created/Modified files during execution:
print("model_deployment_dag.py")Monitoring, Logging, and Error Handling in Orchestrated Pipelines
Effective monitoring, logging, and error handling are essential for maintaining reliable ML pipelines in production. Both Airflow and Kubeflow provide comprehensive capabilities to track pipeline execution, diagnose issues, and ensure system reliability.
Airflow offers built-in logging for each task, web-based monitoring dashboards, and configurable alerting mechanisms. You can set up email notifications, Slack alerts, or custom callbacks when tasks fail or succeed. Airflow also supports retry logic, timeout handling, and dependency management to make pipelines more resilient.
Kubeflow leverages Kubernetes’ native monitoring and logging capabilities, integrating with tools like Prometheus, Grafana, and centralized logging systems. Kubeflow Pipelines provide detailed execution logs, metrics tracking, and visualization of pipeline runs, making it easier to identify bottlenecks and failures.
Here’s a Python example demonstrating comprehensive error handling and logging in an Airflow pipeline:
python
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.utils.email import send_email
from datetime import datetime, timedelta
import logging
import traceback
def setup_logging():
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
return logging.getLogger(__name__)
def train_model_with_monitoring(**context):
logger = setup_logging()
try:
logger.info("Starting model training process")
# Simulate model training with monitoring
import time
import random
for epoch in range(5):
# Simulate training step
time.sleep(1)
accuracy = random.uniform(0.7, 0.95)
loss = random.uniform(0.1, 0.5)
logger.info(f"Epoch {epoch+1}: Accuracy={accuracy:.3f}, Loss={loss:.3f}")
# Monitor for anomalies
if accuracy < 0.75:
logger.warning(f"Low accuracy detected: {accuracy:.3f}")
# Simulate potential failure
if random.random() < 0.1: # 10% chance of failure
raise Exception("Training failed due to resource constraints")
logger.info("Model training completed successfully")
return {"status": "success", "final_accuracy": accuracy}
except Exception as e:
logger.error(f"Training failed: {str(e)}")
logger.error(f"Traceback: {traceback.format_exc()}")
# Send alert notification
send_alert_notification(str(e), context)
raise
def send_alert_notification(error_message, context):
"""Send notification when pipeline fails"""
subject = f"ML Pipeline Failure: {context['dag'].dag_id}"
body = f"""
Pipeline: {context['dag'].dag_id}
Task: {context['task'].task_id}
Execution Date: {context['execution_date']}
Error: {error_message}
Please check the logs for more details.
"""
# In production, you would send actual email/Slack notification
print(f"ALERT: {subject}")
print(body)
def on_failure_callback(context):
"""Callback function executed when task fails"""
logger = setup_logging()
logger.error(f"Task {context['task_instance'].task_id} failed")
send_alert_notification("Task execution failed", context)
def on_success_callback(context):
"""Callback function executed when task succeeds"""
logger = setup_logging()
logger.info(f"Task {context['task_instance'].task_id} completed successfully")
default_args = {
'owner': 'ml-team',
'depends_on_past': False,
'start_date': datetime(2024, 1, 1),
'email_on_failure': True,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minutes=5),
'on_failure_callback': on_failure_callback,
'on_success_callback': on_success_callback
}
dag = DAG(
'ml_pipeline_with_monitoring',
default_args=default_args,
description='ML pipeline with comprehensive monitoring',
schedule_interval=timedelta(hours=6),
catchup=False
)
training_task = PythonOperator(
task_id='train_model',
python_callable=train_model_with_monitoring,
dag=dag
)
# Created/Modified files during execution:
print("ml_monitoring_pipeline.py")This approach ensures that your ML pipelines are not only automated but also observable and resilient, with proper error handling and alerting mechanisms in place to maintain production reliability.
Versioning and Reproducibility in Orchestrated ML Pipelines
Versioning and reproducibility are fundamental for trustworthy machine learning, especially in production environments where models and data evolve over time. Proper versioning ensures that every experiment, dataset, feature, and model can be traced, audited, and reproduced—critical for debugging, compliance, and collaboration.
Airflow supports reproducibility by allowing you to parameterize DAGs and log all inputs, outputs, and configurations for each run. You can integrate Airflow with version control systems (like Git) to track code changes, and with data versioning tools (such as DVC or LakeFS) to manage datasets and features. By storing model artifacts with unique version tags (for example, using MLflow or a model registry), you can always retrieve the exact model used in any deployment or experiment.
Kubeflow takes reproducibility further by leveraging containerization. Each pipeline step runs in a container with a fixed environment, ensuring that code, dependencies, and configurations are consistent across runs. Kubeflow Pipelines natively track pipeline versions, parameters, and artifacts, while integrations with MLflow, DVC, or S3-compatible storage make it easy to manage data and model versions.
Here’s a short Python example using MLflow to log and retrieve model versions, which you can integrate into Airflow or Kubeflow steps:
python
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# Start an MLflow run
with mlflow.start_run(run_name="rf_experiment_v1"):
data = load_iris()
X, y = data.data, data.target
model = RandomForestClassifier(n_estimators=100)
model.fit(X, y)
# Log model and parameters
mlflow.sklearn.log_model(model, "rf_model")
mlflow.log_param("n_estimators", 100)
mlflow.log_metric("accuracy", model.score(X, y))
# Register the model version
result = mlflow.register_model(
"runs:/{}/rf_model".format(mlflow.active_run().info.run_id),
"IrisRandomForest"
)
print(f"Registered model version: {result.version}")
# Retrieve a specific model version for reproducibility
model_uri = "models:/IrisRandomForest/1"
loaded_model = mlflow.sklearn.load_model(model_uri)
print("Loaded model for reproducibility.")This approach ensures that every model, dataset, and experiment is versioned and can be reproduced exactly, supporting robust ML operations.
Security and Access Control in ML Workflow Orchestration
Security and access control are essential in orchestrated ML pipelines, especially when handling sensitive data, proprietary models, or operating in regulated industries. Proper controls help prevent unauthorized access, data leaks, and ensure compliance with organizational and legal requirements.
Airflow provides several mechanisms for securing workflows. You can configure role-based access control (RBAC) to restrict who can view, edit, or trigger DAGs. Airflow supports integration with authentication providers (like LDAP, OAuth, or SAML) and allows you to encrypt connections and sensitive variables. You can also use Airflow’s logging and audit trails to monitor user actions and detect suspicious activity.
Kubeflow leverages Kubernetes’ security features, including namespaces, service accounts, and RBAC, to isolate workloads and control access to resources. Kubeflow can integrate with identity providers for single sign-on (SSO) and supports fine-grained permissions for pipelines, data, and model artifacts. Network policies and secrets management (using Kubernetes Secrets or HashiCorp Vault) further enhance security.
Here’s a short Python example showing how to use Airflow’s Variable encryption and RBAC to securely access a database credential in a task:
python
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.models import Variable
from datetime import datetime
import psycopg2
def secure_db_access():
# Retrieve encrypted credentials from Airflow Variables
db_user = Variable.get("DB_USER", deserialize_json=False)
db_pass = Variable.get("DB_PASS", deserialize_json=False)
db_host = Variable.get("DB_HOST", deserialize_json=False)
db_name = Variable.get("DB_NAME", deserialize_json=False)
# Connect securely to the database
conn = psycopg2.connect(
dbname=db_name,
user=db_user,
password=db_pass,
host=db_host
)
cur = conn.cursor()
cur.execute("SELECT COUNT(*) FROM sensitive_table;")
result = cur.fetchone()
print(f"Row count: {result[0]}")
cur.close()
conn.close()
dag = DAG(
'secure_db_access',
start_date=datetime(2024, 1, 1),
schedule_interval=None,
catchup=False
)
secure_task = PythonOperator(
task_id='access_db_securely',
python_callable=secure_db_access,
dag=dag
)
# Created/Modified files during execution:
print("secure_db_access_dag.py")By combining orchestration tools’ built-in security features with best practices for secrets management and access control, you can protect your ML workflows and data throughout the entire pipeline.
Monitoring Models in Production – Tools and Strategies for 2025
Advanced feature stores: Architecture, monitoring, and cost optimization