

Introduction: MLOps in the Enterprise Context
In today’s data-driven world, enterprises are increasingly leveraging machine learning (ML) to gain a competitive edge, improve decision-making, and drive innovation. However, deploying and managing ML models at scale in an enterprise environment presents unique challenges that go beyond the scope of traditional data science projects.
MLOps, or Machine Learning Operations, is an emerging discipline that addresses these challenges by applying DevOps principles to the entire ML lifecycle. MLOps enables enterprises to streamline the development, deployment, and maintenance of ML models, ensuring that they are reliable, scalable, and aligned with business goals.
For developers working in enterprise settings, understanding MLOps is becoming essential. This article provides a comprehensive overview of MLOps practices tailored to the needs of enterprise developers, covering topics such as data governance, security, automation, compliance, and scalability.
Understanding Enterprise Requirements for MLOps
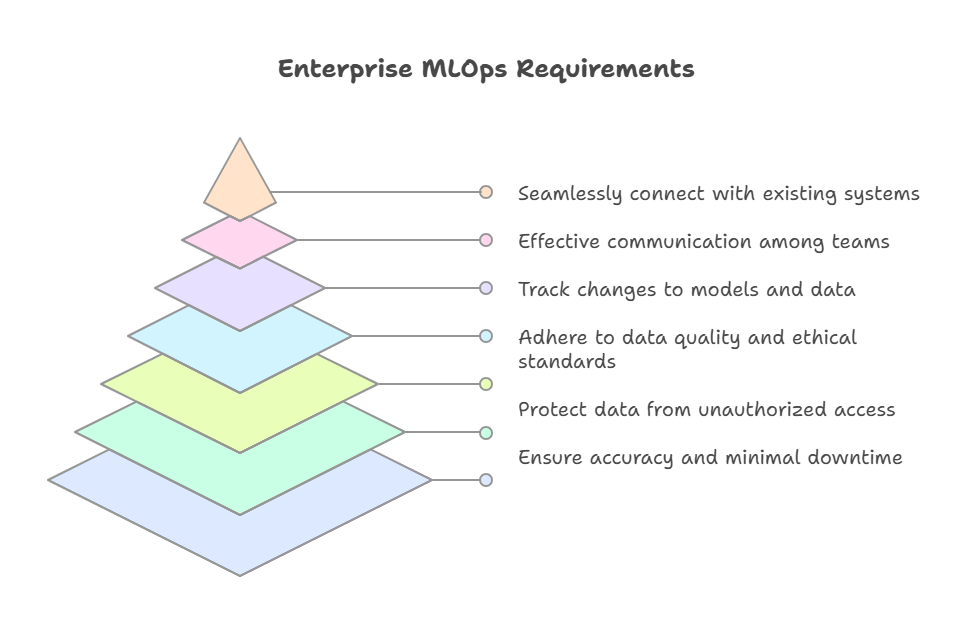
Before diving into specific MLOps practices, it’s important to understand the unique requirements that enterprises face when deploying and managing ML models. These requirements often include:
Scalability: Enterprise ML systems must be able to handle large volumes of data and high levels of user traffic without sacrificing performance.
Reliability: Enterprise ML models must be reliable and accurate, with minimal downtime and consistent performance.
Security: Enterprise ML systems must be secure, protecting sensitive data from unauthorized access and ensuring compliance with regulatory requirements.
Governance: Enterprise ML projects must adhere to strict data governance policies, ensuring data quality, lineage, and compliance with legal and ethical standards.
Auditability: Enterprise ML systems must be auditable, allowing stakeholders to track changes to models, data, and configurations over time.
Collaboration: Enterprise ML projects often involve multiple teams and stakeholders, requiring effective collaboration and communication.
Integration: Enterprise ML systems must integrate seamlessly with existing IT infrastructure and business processes.
By understanding these enterprise requirements, developers can design and implement MLOps practices that meet the specific needs of their organizations and ensure the success of their ML projects.
Key MLOps Practices for Enterprise Developers
To meet the stringent requirements of enterprise environments, developers need to adopt specific MLOps practices that streamline the ML lifecycle and ensure the reliability, scalability, and security of ML systems. Here are some key practices:
Version Control: Use version control systems like Git to track changes to code, data, and model configurations. This enables reproducibility, collaboration, and easy rollback to previous versions.
Automated Testing: Implement automated testing frameworks to validate model performance, data quality, and system functionality. This helps catch errors early in the development cycle and ensures that models meet quality standards.
Continuous Integration/Continuous Deployment (CI/CD): Automate the build, test, and deployment of ML models using CI/CD pipelines. This enables rapid iteration, frequent releases, and reduced deployment risk.
Infrastructure as Code (IaC): Manage infrastructure resources using code, enabling reproducible and scalable deployments. Tools like Terraform and CloudFormation can be used to automate infrastructure provisioning and configuration.
Model Monitoring: Implement robust monitoring systems to track model performance, detect data drift, and ensure system health in production. This enables proactive identification and resolution of issues.
Collaboration and Communication: Foster collaboration and communication between data scientists, engineers, and operations teams. Use shared tools and platforms to facilitate knowledge sharing and coordination.
Implementing Robust Data Governance and Security
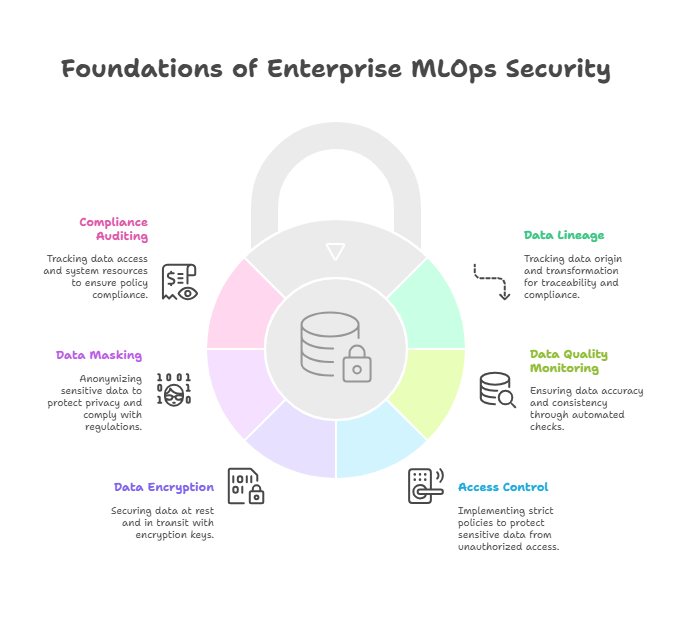
Data governance and security are paramount in enterprise MLOps. Developers must implement robust practices to ensure data quality, protect sensitive information, and comply with regulatory requirements. Here are some key considerations:
Data Lineage: Track the origin and transformation of data throughout the ML lifecycle. This enables traceability, auditability, and compliance with data governance policies.
Data Quality Monitoring: Implement data quality checks to ensure that data is accurate, complete, and consistent. Use automated tools to detect anomalies and data drift.
Access Control: Implement strict access control policies to protect sensitive data from unauthorized access. Use role-based access control (RBAC) to grant permissions based on job function.
Data Encryption: Encrypt data at rest and in transit to protect it from unauthorized access. Use encryption keys and certificates to secure data and communications.
Data Masking: Mask or anonymize sensitive data to protect privacy and comply with data protection regulations. Use data masking techniques to replace sensitive data with realistic but non-identifiable values.
Compliance Auditing: Implement audit logging and reporting to track access to data and system resources. Use audit trails to monitor compliance with data governance and security policies.
By implementing these data governance and security practices, developers can build enterprise MLOps systems that are reliable, secure, and compliant with regulatory requirements.
Automating Model Deployment and Monitoring at Scale
Enterprise environments demand repeatable, hands-off releases and 24/7 observability. A robust deployment stack should include:
Immutable artefacts – Train → package → push a single, versioned image.
CI/CD pipelines – Git push triggers build, test, security scan, and rollout.
Orchestration – Kubernetes (with KServe/Seldon Core) or cloud-native services for autoscaling and A/B canary roll-outs.
Real-time monitoring – Application health (HTTP, CPU/RAM), business KPIs, and ML-specific metrics (latency, drift, accuracy).
Feedback loops – Alerts that can kick off retraining pipelines when performance degrades.
Example – containerised FastAPI service with Prometheus metrics
python
# serve.py – production-grade inference + monitoring
from fastapi import FastAPI, HTTPException
from prometheus_client import Counter, Histogram, start_http_server
import mlflow.pyfunc, time, numpy as np, os
# Start Prometheus exporter on a side port
start_http_server(9000) # prometheus scrapes :9000/metrics
REQUEST_COUNT = Counter("inference_requests_total", "Number of prediction calls")
REQUEST_LATENCY = Histogram("inference_latency_seconds", "Latency per request")
MODEL_URI = os.getenv("MODEL_URI", "models:/customer_churn/Production")
model = mlflow.pyfunc.load_model(MODEL_URI)
app = FastAPI(title="Churn Predictor")
@app.post("/predict")
def predict(payload: list[list[float]]):
REQUEST_COUNT.inc()
start = time.perf_counter()
try:
preds = model.predict(np.array(payload)).tolist()
except Exception as err:
raise HTTPException(status_code=400, detail=str(err))
REQUEST_LATENCY.observe(time.perf_counter() - start)
return {"predictions": preds}A GitHub Actions workflow might:
yaml
# .github/workflows/deploy.yml
on: [push]
jobs:
build-and-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: docker/build-push-action@v5
with:
push: true
tags: ghcr.io/org/churn-api:${{ github.sha }}
- name: Helm rollout
run: helm upgrade --install churn-api ./charts/churn \
--set image.tag=${{ github.sha }}Prometheus + Grafana dashboards now expose request rate, latency, and custom model metrics, enabling SREs to react long before customers notice an issue.
Ensuring Compliance and Auditability in MLOps
Large organisations operate under GDPR, HIPAA, PCI-DSS, SOX, or internal audit mandates. An MLOps platform must therefore provide:
Requirement Practical Mechanism
Traceable lineage Log every dataset, config, code commit, and model hash.
Immutable artefacts Store signed binaries in a write-once registry (e.g., ECR w/ KMS).
Role-based access Enforce RBAC & IAM across notebooks, registries, and clusters.
Reproducible builds Deterministic Dockerfiles + lockfiles (requirements.txt, Conda).
Automated evidence Continuous export of logs, metrics, and approvals to auditors.
Example – “signed” MLflow registration script
python
"""
register_model.py
Registers a model in MLflow with compliance metadata and a SHA-256 signature.
"""
import mlflow, hashlib, json, pathlib, datetime
MODEL_PATH = "artifacts/model.pkl"
ARTIFACT_NAME = "enterprise_churn_model"
def sha256(path: str) -> str:
return hashlib.sha256(pathlib.Path(path).read_bytes()).hexdigest()
with mlflow.start_run() as run:
# log artefact and compute hash
mlflow.log_artifact(MODEL_PATH, artifact_path="model")
digest = sha256(MODEL_PATH)
# attach compliance tags
mlflow.set_tags({
"gdpr_pii_removed" : "true",
"sox_fin_model" : "true",
"sha256" : digest,
"training_data_version": "2024-06-01",
"owner" : "ml-team@corp.com",
"approval_status" : "pending_review"
})
# store supplemental metadata for auditors
doc = {
"created_at": datetime.datetime.utcnow().isoformat(timespec="seconds"),
"data_schema": {
"features": ["age", "contract_length", "monthly_spend"],
"target" : "churn"
}
}
mlflow.log_text(json.dumps(doc, indent=2), "model/metadata.json")
# register the model
mlflow.register_model(
f"runs:/{run.info.run_id}/model",
ARTIFACT_NAME
)
print("Model logged, tagged, and awaiting compliance approval.")Key take-aways:
Cryptographic hashes guarantee artefact integrity.
Rich tags & metadata satisfy auditors without manual spreadsheets.
Promotion gates (e.g., MLflow Model Registry stages or GitOps PR approvals) ensure that only vetted models reach production.
By automating deployment pipelines and embedding compliance artefacts directly into the workflow, enterprises achieve both agility and rigorous governance—turning MLOps from a liability buffer into a competitive advantage.
Scaling MLOps Across Multiple Teams and Projects
As enterprises mature in their adoption of MLOps, they often face the challenge of scaling these practices across multiple teams and projects. This requires a standardized approach that promotes consistency, collaboration, and reuse. Here are some key strategies for scaling MLOps:
Establish a Central MLOps Platform: Create a centralized platform that provides shared tools, services, and infrastructure for all ML teams. This reduces duplication of effort, promotes standardization, and simplifies governance.
Define Standardized Workflows: Develop standardized workflows for common MLOps tasks, such as data preparation, model training, deployment, and monitoring. This ensures consistency across projects and reduces the risk of errors.
Create Reusable Components: Build reusable components, such as data pipelines, model templates, and deployment scripts, that can be shared across teams and projects. This accelerates development and reduces the need to reinvent the wheel.
Implement a Centralized Model Registry: Use a centralized model registry to track and manage all ML models across the enterprise. This provides a single source of truth for model metadata, lineage, and versioning.
Foster a Culture of Collaboration: Encourage collaboration and knowledge sharing between teams. Create communities of practice where developers can share best practices, discuss challenges, and learn from each other.
Provide Training and Support: Offer training and support to help developers adopt MLOps practices. This ensures that everyone has the skills and knowledge needed to contribute to successful ML projects.
Choosing the Right Tools and Technologies for Enterprise MLOps
Selecting the right tools and technologies is crucial for building a successful enterprise MLOps platform. Here are some key considerations when choosing MLOps tools:
Scalability: Choose tools that can scale to handle large volumes of data and high levels of user traffic.
Integration: Select tools that integrate seamlessly with existing IT infrastructure and business processes.
Security: Prioritize tools that offer robust security features, such as access control, data encryption, and audit logging.
Open Source: Consider open-source tools that offer flexibility, transparency, and community support.
Cloud-Native: Leverage cloud-native technologies, such as containers, Kubernetes, and serverless functions, to build scalable and resilient MLOps systems.
Managed Services: Consider managed services that provide pre-built MLOps capabilities, such as model deployment, monitoring, and governance.
Vendor Support: Choose tools from vendors that offer reliable support, documentation, and training.
By carefully evaluating these factors, developers can select the right tools and technologies to build an enterprise MLOps platform that meets their organization’s specific needs and requirements.
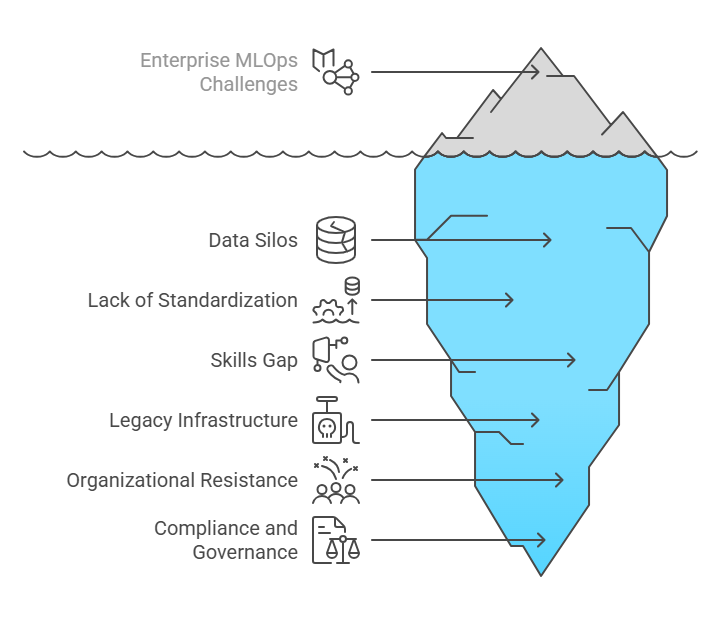
Overcoming Common Challenges in Enterprise MLOps
Implementing MLOps in an enterprise setting is not without its challenges. Here are some common hurdles and strategies to overcome them:
Data Silos: Data is often scattered across different departments and systems, making it difficult to access and integrate. Solution: Implement a data lake or data warehouse to centralize data and provide a unified view.
Lack of Standardization: Different teams may use different tools and processes, leading to inconsistencies and inefficiencies. Solution: Establish standardized workflows, tools, and platforms for MLOps.
Skills Gap: Developers may lack the skills and knowledge needed to implement MLOps practices. Solution: Provide training and support to help developers adopt MLOps and upskill their capabilities.
Legacy Infrastructure: Existing IT infrastructure may not be well-suited for MLOps. Solution: Modernize infrastructure by adopting cloud-native technologies and automating deployment processes.
Organizational Resistance: Some teams may resist adopting MLOps practices due to concerns about job security or loss of control. Solution: Communicate the benefits of MLOps, involve stakeholders in the decision-making process, and provide incentives for adoption.
Compliance and Governance: Meeting regulatory requirements and ensuring data governance can be complex and time-consuming. Solution: Implement robust data governance policies, automate compliance checks, and provide training on regulatory requirements.
The Future of Enterprise MLOps: Trends and Innovations
The field of MLOps is constantly evolving, with new trends and innovations emerging all the time. Here are some key areas to watch in the future of enterprise MLOps:
AI-Powered MLOps: AI will be used to automate and optimize various aspects of the MLOps pipeline, including model selection, hyperparameter tuning, and anomaly detection.
Explainable AI (XAI): Techniques for understanding and explaining how machine learning models make decisions will become more important, especially in regulated industries.
Federated Learning: Approaches for training models on decentralized data sources without sharing sensitive information will gain traction, enabling new applications in healthcare and finance.
Edge MLOps: Deploying and managing machine learning models on edge devices will become more common, enabling real-time inference and reduced latency in IoT and autonomous systems.
MLOps as a Service: Cloud providers will offer more comprehensive MLOps as a Service (MLaaS) solutions, providing pre-built capabilities for model deployment, monitoring, and governance.
Low-Code/No-Code MLOps: Tools that enable non-technical users to build and deploy ML models without writing code will become more prevalent, democratizing access to AI.
By staying informed about these trends and innovations, developers can position themselves at the forefront of the MLOps revolution and help their organizations build more innovative and impactful AI solutions.
Conclusion: Embracing MLOps for Enterprise Success
In today’s competitive landscape, enterprises are increasingly relying on machine learning to drive innovation, improve decision-making, and gain a competitive edge. However, deploying and managing ML models at scale in an enterprise environment requires more than just data science expertise—it demands robust engineering practices and seamless collaboration between teams.
MLOps provides the framework and tools needed to streamline the entire ML lifecycle, from data preparation to model deployment and monitoring. By adopting MLOps practices, enterprises can accelerate model deployment, ensure reproducibility, and maintain high-quality AI systems at scale.
For developers working in enterprise settings, understanding MLOps is becoming essential. By implementing the practices outlined in this article, developers can build reliable, scalable, and secure ML systems that meet the stringent requirements of enterprise environments.
As the field of MLOps continues to evolve, it’s crucial for developers to stay informed about new trends and innovations. By embracing a mindset of continuous learning and experimentation, developers can position themselves at the forefront of the MLOps revolution and help their organizations unlock the full potential of AI.
In conclusion, MLOps is not just a set of tools or processes; it’s a cultural shift that transforms how enterprises approach machine learning. By embracing MLOps, enterprises can build more innovative, impactful, and successful AI solutions that drive business value and create lasting competitive advantage.
Monitoring ML models in production: tools, challenges, and best practices
MLOps in the Era of Generative Artificial Intelligence: New Challenges and Opportunities
The Future of MLOps: Trends and Innovations in Machine Learning Operations