

Introduction to Feature Stores
In modern machine learning (ML) systems, the process of preparing and managing features—the individual measurable properties or characteristics used as input for models—is both critical and complex. As organizations scale their ML efforts, the need for a centralized, reliable, and efficient way to handle features becomes paramount. This is where feature stores come into play.
A feature store is a specialized data management system designed to simplify the creation, storage, and serving of features for machine learning models. It acts as a centralized repository that enables data scientists and engineers to share, reuse, and maintain features consistently across different projects and environments.
The concept of feature stores emerged to address several challenges commonly faced in ML workflows. Traditionally, feature engineering was often done in an ad hoc manner, with teams creating features independently, leading to duplicated efforts, inconsistent feature definitions, and difficulties in reproducing results. Moreover, discrepancies between how features are computed during model training and inference—known as training-serving skew—can degrade model performance in production.
Feature stores solve these problems by providing a unified platform that ensures features are defined once, stored centrally, and served consistently both during training and real-time inference. They support both batch and real-time feature computation, enabling models to leverage fresh data and respond dynamically to changing conditions.
Beyond technical benefits, feature stores also promote collaboration and governance. By cataloging features with metadata such as descriptions, data lineage, and ownership, they help teams understand and trust the data feeding their models. This transparency is increasingly important for compliance with data regulations and for maintaining ethical AI practices.
In summary, feature stores are foundational components in large-scale ML systems. They streamline feature management, improve model reliability, and accelerate development cycles, making them indispensable for organizations aiming to operationalize machine learning effectively and at scale.
Importance of Feature Stores in Large-Scale Machine Learning
As machine learning (ML) systems scale within organizations, managing features—the individual measurable properties used as inputs to models—becomes increasingly complex and critical. Feature stores have emerged as a foundational component in large-scale ML, addressing key challenges related to feature consistency, reuse, and operational efficiency.
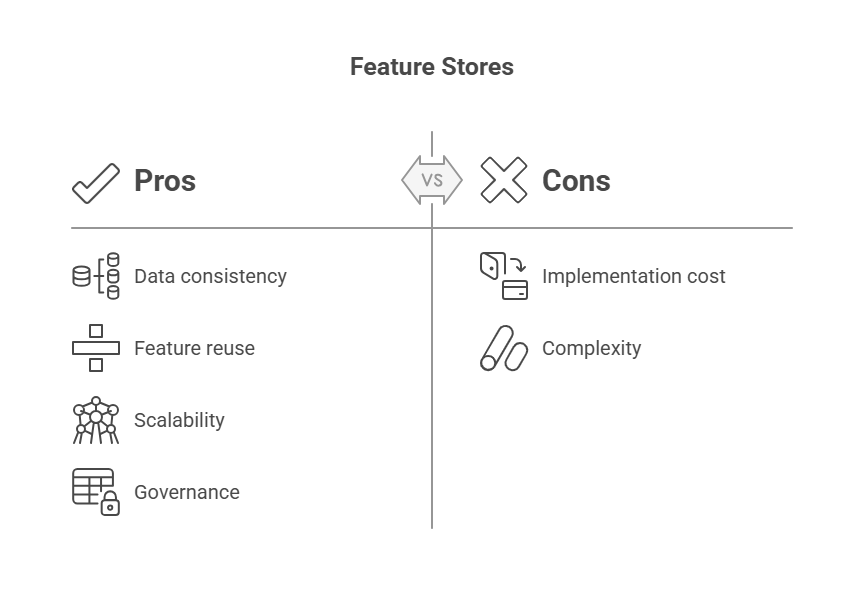
One of the primary benefits of feature stores is ensuring data consistency. In large organizations, multiple teams often work on different ML projects, sometimes using overlapping datasets. Without a centralized system, feature definitions and computations can vary, leading to discrepancies between training and inference data. Feature stores provide a single source of truth for feature engineering, guaranteeing that the same feature values are used during both model training and real-time serving. This consistency reduces errors and improves model reliability.
Feature stores also promote feature reuse and collaboration. By cataloging features with metadata such as descriptions, data lineage, and ownership, they enable data scientists and engineers to discover and leverage existing features rather than recreating them. This accelerates development cycles and fosters knowledge sharing across teams.
Scalability is another critical advantage. Feature stores are designed to handle large volumes of data and support both batch and real-time feature computation. This capability is essential for production ML systems that require low-latency access to fresh data for inference, as well as efficient batch processing for model training.
Moreover, feature stores enhance data governance and compliance. They provide mechanisms to track feature provenance, enforce access controls, and maintain audit logs, helping organizations meet regulatory requirements and maintain ethical standards.
In summary, feature stores are indispensable in large-scale ML systems. They improve data consistency, enable collaboration, support scalability, and strengthen governance—ultimately driving more efficient and reliable machine learning operations. Organizations that invest in feature store infrastructure are better equipped to scale their AI initiatives and deliver sustained business value.
Key Components of a Feature Store
A feature store is a specialized system designed to manage the lifecycle of machine learning features efficiently and reliably. Understanding its key components helps clarify how it supports large-scale ML workflows. The main components of a feature store typically include:
Feature Engineering Pipeline
This is the process and code responsible for transforming raw data into meaningful features. It involves data cleaning, aggregation, normalization, and other transformations needed to prepare features for model consumption. The pipeline ensures that feature computations are reproducible and consistent across training and serving environments.
Storage Layer
Feature stores use dedicated storage systems to hold feature data. This usually includes two types of storage: offline and online. Offline storage handles large-scale batch data used during model training, often stored in data lakes or warehouses. Online storage supports low-latency, real-time access to features for inference, typically using fast key-value stores or databases.
Metadata Store
This component maintains detailed information about each feature, such as its definition, data type, source, owner, and update frequency. Metadata helps users discover, understand, and trust features. It also supports governance by tracking feature lineage and versioning.
Feature Serving Layer
The serving layer provides APIs or interfaces that allow models and applications to retrieve feature values during training and inference. It ensures that features are served with low latency and high availability, supporting both batch and real-time use cases.
Monitoring and Validation
Some feature stores include tools to monitor feature quality and detect anomalies, such as data drift or missing values. Validation mechanisms help maintain data integrity and alert teams to potential issues that could impact model performance.
Together, these components form an integrated platform that streamlines feature management, reduces duplication of effort, and ensures consistency and reliability in machine learning pipelines. By centralizing feature engineering, storage, and serving, feature stores enable organizations to scale their ML operations effectively.
Types of Feature Stores
Feature stores come in various forms, each designed to meet different organizational needs and technical requirements. Understanding the types of feature stores helps teams choose the right solution for their machine learning workflows. The main categories include:
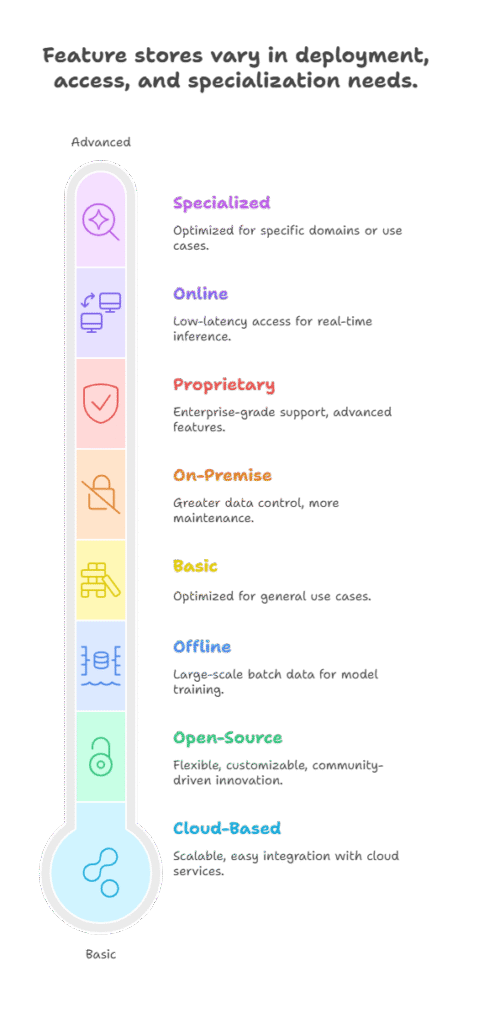
Cloud-Based vs. On-Premise Feature Stores
Cloud-based feature stores are managed services provided by cloud vendors such as AWS, Google Cloud, and Azure. They offer scalability, ease of integration with other cloud services, and reduced operational overhead. On-premise feature stores, on the other hand, are deployed within an organization’s own infrastructure, providing greater control over data security and customization but requiring more maintenance and management effort.
Open-Source vs. Proprietary Feature Stores
Open-source feature stores like Feast and Hopsworks provide flexibility, transparency, and community-driven innovation. They allow organizations to customize and extend functionality according to their needs. Proprietary feature stores, such as Tecton or cloud vendor offerings, often come with enterprise-grade support, advanced features, and seamless integration with specific platforms, but may involve licensing costs.
Online vs. Offline Feature Stores
Feature stores typically separate storage and serving into online and offline components. Offline feature stores handle large-scale batch data used for model training and historical analysis, often stored in data lakes or warehouses. Online feature stores provide low-latency access to features for real-time inference, using fast key-value stores or databases. Some feature stores integrate both to ensure consistency and support hybrid use cases.
Specialized Feature Stores
Certain feature stores are optimized for specific domains or use cases, such as streaming data, time-series features, or complex feature transformations. These specialized stores may offer unique capabilities tailored to the demands of particular industries or applications.
By understanding these types, organizations can select feature store solutions that align with their scale, security, integration, and operational preferences, ensuring efficient and reliable feature management in their ML pipelines.
Choosing the Right Feature Store
Selecting the appropriate feature store is a critical decision that can significantly impact the efficiency and success of machine learning projects, especially at scale. When evaluating feature store options, several factors should be considered to ensure the solution aligns with organizational needs and technical requirements.
Scalability and Performance
The feature store must handle the volume, velocity, and variety of data your ML applications require. It should support both batch processing for training and low-latency online serving for real-time inference without bottlenecks.
Integration with Existing Infrastructure
Compatibility with your current data sources, ML frameworks, and deployment platforms is essential. A feature store that integrates smoothly with your data lakes, pipelines, and model serving environments reduces complexity and accelerates adoption.
Feature Engineering Capabilities
Look for support for complex feature transformations, versioning, and reproducibility. Automation features, such as scheduled feature computation and monitoring, can improve reliability and reduce manual effort.
Data Governance and Security
Ensure the feature store provides robust metadata management, access controls, and audit trails. These capabilities are vital for compliance with data privacy regulations and for maintaining trust in your ML systems.
Cost and Operational Overhead
Consider the total cost of ownership, including licensing, infrastructure, and maintenance. Managed cloud services may reduce operational burden but could be more expensive, while open-source solutions offer flexibility but require in-house expertise.
Community and Support
A strong user community, active development, and vendor support can be invaluable for troubleshooting, feature requests, and staying up to date with best practices.
Popular Feature Store Solutions
There are several feature store solutions available today, ranging from open-source projects to fully managed cloud services. Choosing the right one depends on your organization’s requirements, existing infrastructure, and scale. Below are some of the most popular feature store solutions used in large-scale machine learning systems:
Feast
Feast (Feature Store) is an open-source feature store designed to simplify feature management. It supports both batch and real-time feature serving and integrates well with popular ML frameworks. Feast allows you to define features, ingest data, and serve features consistently during training and inference.
AWS SageMaker Feature Store
A fully managed feature store service by Amazon Web Services, integrated with the SageMaker ecosystem. It supports secure, scalable storage and real-time feature retrieval, with built-in monitoring and governance.
Google Cloud Vertex AI Feature Store
Google’s managed feature store service, part of the Vertex AI platform. It offers seamless integration with Google Cloud data services and supports both online and offline feature serving.
Azure Machine Learning Feature Store
Microsoft Azure provides a feature store as part of its ML platform, enabling feature management with strong integration into Azure data and compute services.
Hopsworks
An open-source feature store platform with a focus on data governance, security, and collaboration. It supports feature lineage tracking and real-time feature serving.
Tecton
A commercial feature store platform designed for enterprise-scale ML, offering advanced automation, monitoring, and governance features.
Example: Using Feast to Define and Retrieve Features in Python
Let’s walk through a simple example of how to define and retrieve features using Feast, one of the most popular open-source feature stores.
Step 1: Define your feature set
python
from feast import FeatureStore, Entity, Feature, ValueType, FeatureView
from feast.data_source import FileSource
from datetime import timedelta
# Define an entity (e.g., customer)
customer = Entity(name="customer_id", value_type=ValueType.INT64, description="Customer ID")
# Define a data source (e.g., a CSV file with feature data)
customer_source = FileSource(
path="data/customer_features.parquet",
event_timestamp_column="event_timestamp"
)
# Define features
features = [
Feature(name="total_transactions", dtype=ValueType.INT64),
Feature(name="avg_transaction_value", dtype=ValueType.FLOAT)
]
# Create a FeatureView
customer_feature_view = FeatureView(
name="customer_features",
entities=["customer_id"],
ttl=timedelta(days=7),
features=features,
online=True,
input=customer_source
)Step 2: Register the feature store and apply the feature definitions
python
store = FeatureStore(repo_path=".")
store.apply([customer, customer_feature_view])Step 3: Retrieve features for model training or inference
python
import pandas as pd
# Example entity dataframe for which we want features
entity_df = pd.DataFrame({
"customer_id": [1001, 1002, 1003],
"event_timestamp": pd.to_datetime(["2025-06-01", "2025-06-01", "2025-06-01"])
})
# Retrieve features from the feature store
feature_data = store.get_historical_features(
entity_df=entity_df,
features=[
"customer_features:total_transactions",
"customer_features:avg_transaction_value"
]
).to_df()
print(feature_data)Example Workflow Using a Feature Store
Implementing a feature store in a machine learning project involves several key steps that streamline feature management and ensure consistency across training and inference. Below is a typical workflow illustrating how a feature store fits into the ML lifecycle:
Feature Definition
Data scientists and engineers begin by defining features in a standardized way. This includes specifying the data sources, transformations, and metadata such as feature names, types, and update frequencies. Defining features centrally ensures that everyone uses the same feature definitions.
Data Ingestion and Feature Engineering
Raw data is ingested from various sources—databases, event streams, or files—and processed through feature engineering pipelines. These pipelines transform raw data into meaningful features, applying cleaning, aggregation, normalization, and other operations. The processed features are then stored in the feature store’s offline and/or online storage.
Feature Registration
Once features are engineered, they are registered in the feature store along with metadata. This registration makes features discoverable and reusable by other teams and projects, promoting collaboration and reducing duplication.
Model Training
During model training, the feature store is queried to retrieve historical feature values corresponding to training examples. This ensures that the training data is consistent and reproducible, as the same feature computations are used as in production.
Model Deployment
After training, the model is deployed to a serving environment. The feature store’s online serving layer provides low-latency access to the latest feature values needed for real-time inference.
Inference and Monitoring
At inference time, the model requests feature values from the feature store to make predictions. The feature store ensures that features are served consistently and efficiently. Additionally, monitoring tools track feature distributions and data quality to detect anomalies or drift that could impact model performance.
Simplified Python Example: Retrieving Features for Training and Inference with Feast
python
from feast import FeatureStore
import pandas as pd
# Initialize the feature store
store = FeatureStore(repo_path=".")
# Prepare entity dataframe for training
training_entities = pd.DataFrame({
"customer_id": [101, 102, 103],
"event_timestamp": pd.to_datetime(["2025-05-01", "2025-05-01", "2025-05-01"])
})
# Retrieve historical features for training
training_features = store.get_historical_features(
entity_df=training_entities,
features=[
"customer_features:total_transactions",
"customer_features:avg_transaction_value"
]
).to_df()
print("Training features:")
print(training_features)
# Prepare entity dataframe for inference
inference_entities = pd.DataFrame({
"customer_id": [101, 104],
"event_timestamp": pd.to_datetime(["2025-06-05", "2025-06-05"])
})
# Retrieve online features for inference
inference_features = store.get_online_features(
features=[
"customer_features:total_transactions",
"customer_features:avg_transaction_value"
],
entity_rows=inference_entities.to_dict(orient="records")
).to_df()
print("Inference features:")
print(inference_features)Challenges and Best Practices
While feature stores offer significant benefits for managing features in large-scale machine learning systems, implementing and maintaining them comes with its own set of challenges. Understanding these challenges and following best practices can help organizations maximize the value of their feature store investments.
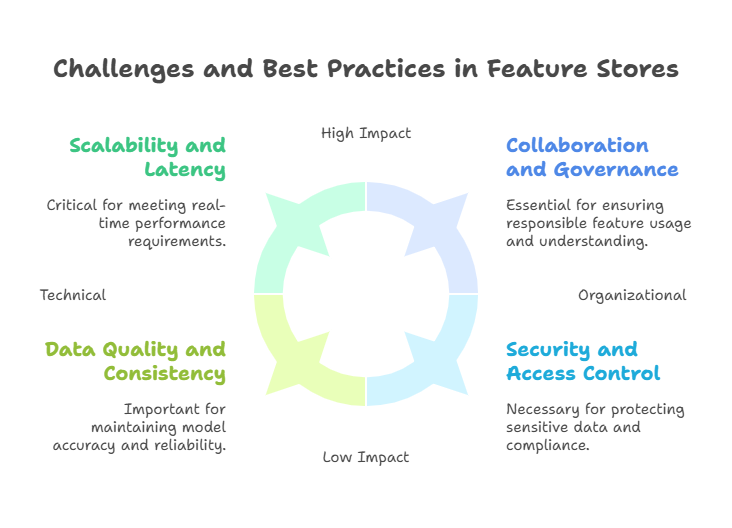
Data Quality and Consistency
Ensuring high-quality, consistent feature data is critical. Poor data quality can lead to inaccurate models and degraded performance. It’s important to implement validation checks, monitor feature distributions, and detect anomalies such as missing values or unexpected shifts in data.
Training-Serving Skew
A common challenge is avoiding discrepancies between how features are computed during training and inference. Feature stores help mitigate this by centralizing feature definitions, but teams must rigorously test and validate that the same logic is applied in both environments.
Feature Versioning and Lineage
As features evolve over time, tracking versions and lineage becomes essential for reproducibility and debugging. Maintaining clear metadata about feature changes, dependencies, and ownership supports auditability and compliance.
Scalability and Latency
Feature stores must handle large volumes of data and provide low-latency access for real-time inference. Designing scalable storage and serving architectures, and optimizing feature computation pipelines, are key to meeting performance requirements.
Security and Access Control
Protecting sensitive data and enforcing access controls is vital, especially in regulated industries. Feature stores should integrate with organizational security policies, support role-based access, and maintain audit logs.
Collaboration and Governance
Feature stores are most effective when they foster collaboration between data scientists, engineers, and business stakeholders. Establishing clear governance processes, documentation standards, and communication channels helps ensure features are well-understood and responsibly used.
Future Trends in Feature Stores
As machine learning continues to evolve and become more integral to business operations, feature stores are also advancing to meet new demands and challenges. Here are some key trends shaping the future of feature stores in large-scale ML systems:
Increased Automation and AutoML Integration
Feature stores are expected to incorporate more automation, including automated feature generation, selection, and monitoring. Integration with AutoML tools will help accelerate feature engineering and reduce manual effort, enabling faster experimentation and deployment.
Real-Time and Streaming Feature Computation
The demand for real-time, low-latency predictions is driving feature stores to enhance their support for streaming data and on-the-fly feature computation. This enables models to react instantly to new information, improving responsiveness in applications like fraud detection and personalized recommendations.
Unified Observability and Monitoring
Future feature stores will offer more comprehensive observability, combining feature monitoring with model performance tracking, data drift detection, and alerting. This holistic view helps teams quickly identify and address issues affecting model accuracy and reliability.
Enhanced Feature Governance and Compliance
With growing regulatory scrutiny around data privacy and AI ethics, feature stores will strengthen governance capabilities. This includes improved lineage tracking, explainability, access controls, and audit trails to ensure responsible and compliant use of features.
Support for Complex and Multimodal Features
As ML models increasingly leverage diverse data types—such as images, text, and sensor data—feature stores will evolve to handle complex, high-dimensional, and multimodal features, including embeddings and representations from foundation models.
Integration with MLOps and Data Mesh Architectures
Feature stores will become more tightly integrated with broader MLOps pipelines and emerging data mesh architectures, enabling seamless collaboration across data, ML, and operations teams while supporting decentralized data ownership.
Conclusion
Feature stores have become a cornerstone of modern, large-scale machine learning systems. By centralizing the management of features—from their definition and engineering to storage and serving—they address many of the challenges that arise as organizations scale their AI initiatives. Feature stores ensure consistency between training and inference, promote collaboration and reuse, improve operational efficiency, and support governance and compliance.
As machine learning continues to mature, the role of feature stores will only grow in importance. They enable teams to build more reliable, scalable, and maintainable ML pipelines, reducing errors and accelerating time to market. Moreover, emerging trends such as real-time feature computation, enhanced automation, and stronger governance will further enhance their value.
For organizations aiming to succeed in deploying machine learning at scale, investing in a robust feature store infrastructure is essential. It not only streamlines feature management but also lays the foundation for responsible, efficient, and impactful AI solutions that deliver sustained business value.
In summary, feature stores are not just a technical convenience—they are a strategic asset that empowers organizations to unlock the full potential of their machine learning efforts.
MLOps in Practice: Automation and Scaling of the Machine Learning Lifecycle
MLOps in the Era of Generative Artificial Intelligence: New Challenges and Opportunities
The Future of MLOps: Trends and Innovations in Machine Learning Operations