
Introduction to Continuous Delivery in MLOps
Continuous Delivery (CD) is a software engineering approach that focuses on automating the process of delivering new code, features, or models to production quickly, safely, and reliably. In the context of MLOps—where machine learning meets DevOps—Continuous Delivery takes on new dimensions, as it must address not only code but also data, models, and the unique challenges of ML workflows.
The main goal of Continuous Delivery in MLOps is to ensure that machine learning models, along with their supporting code and data pipelines, can be updated and deployed to production environments in a repeatable and automated way. This reduces manual intervention, shortens the time from development to deployment, and helps teams respond faster to new data, business requirements, or regulatory changes.
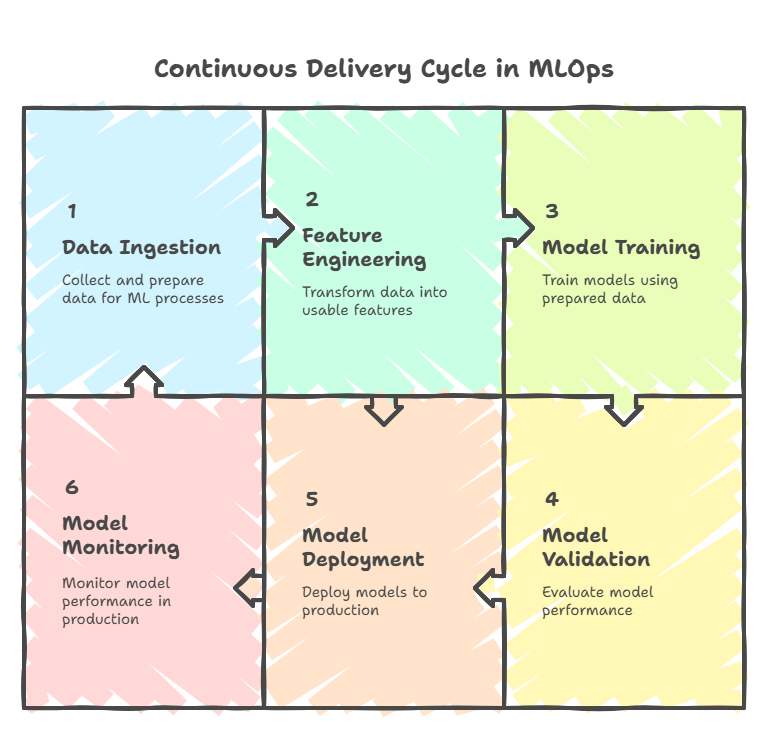
Unlike traditional software, ML systems are dynamic: models can degrade over time due to data drift, and new data can require frequent retraining and redeployment. Continuous Delivery in MLOps addresses these challenges by automating the entire lifecycle—from data ingestion and feature engineering, through model training and validation, to deployment and monitoring.
Key benefits of adopting Continuous Delivery in MLOps include faster innovation, improved model quality, reduced risk of errors, and the ability to quickly roll back or update models as needed. By integrating CD practices into ML workflows, organizations can achieve more reliable, scalable, and maintainable machine learning systems that deliver real business value.
In summary, Continuous Delivery in MLOps is about building robust, automated pipelines that allow teams to move from experimentation to production with confidence, ensuring that ML solutions remain accurate, secure, and aligned with business goals.
Key Differences Between Traditional and ML Continuous Delivery
Continuous Delivery (CD) in traditional software development focuses on automating the process of building, testing, and deploying code changes to production. The pipeline is usually linear: developers write code, automated tests validate it, and the application is deployed if all checks pass. The main artifacts are source code and compiled binaries, and the process is well-understood with mature tools and practices.
In contrast, Continuous Delivery in MLOps introduces several unique challenges and complexities. First, machine learning systems rely not only on code but also on data and models. This means that the pipeline must handle versioning and validation of datasets, feature engineering steps, and trained models, in addition to the application code. Data can change over time, leading to data drift, which can degrade model performance even if the code remains unchanged.
Another key difference is the need for model validation. In traditional CD, automated tests check for correctness and performance of the code. In ML CD, additional steps are required to validate model accuracy, fairness, and robustness. This often involves running experiments, comparing metrics, and sometimes requiring human-in-the-loop approval before deployment.
Moreover, ML pipelines are often more complex and iterative. Retraining, hyperparameter tuning, and model selection are integral parts of the workflow, and these steps must be automated and reproducible. The deployment process may also involve serving models as APIs, batch scoring, or integrating with other systems, each with its own requirements.
Finally, monitoring in ML CD extends beyond application health to include model performance in production. Teams must track metrics like prediction accuracy, data drift, and feature distribution changes, and be prepared to trigger retraining or rollback if issues are detected.
In summary, while traditional Continuous Delivery focuses on code, ML Continuous Delivery must orchestrate code, data, and models, with additional emphasis on validation, monitoring, and automation. This makes MLOps pipelines more complex but also more powerful, enabling organizations to deliver reliable and adaptive machine learning solutions at scale.
Essential Components of an ML Continuous Delivery Pipeline
A robust Continuous Delivery (CD) pipeline for machine learning is more than just a sequence of automated steps—it’s a carefully designed system that ensures every change, from code to data to models, is delivered to production reliably and efficiently. Understanding the essential components of such a pipeline is key to building scalable and maintainable ML solutions.
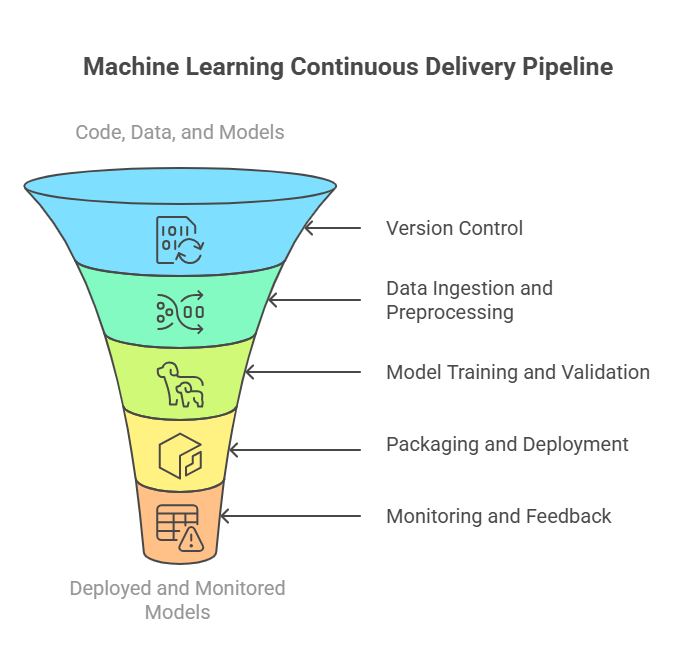
The first core component is version control. In ML projects, this means not only tracking code changes (as in traditional software) but also managing versions of datasets, feature engineering scripts, and trained models. Tools like Git, DVC (Data Version Control), and MLflow help teams keep track of these evolving artifacts, ensuring reproducibility and traceability.
Next is automated data ingestion and preprocessing. The pipeline must be able to fetch new data, validate its quality, and transform it into features suitable for model training. Automation at this stage reduces manual errors and ensures consistency, which is crucial for reliable model performance.
Model training and validation form the heart of the ML CD pipeline. This step involves training models on the latest data, tuning hyperparameters, and evaluating performance using predefined metrics. Automated validation checks—such as accuracy thresholds, fairness assessments, or robustness tests—help prevent underperforming or biased models from reaching production.
Once a model passes validation, the pipeline moves to packaging and deployment. This involves containerizing the model (using tools like Docker), registering it in a model registry, and deploying it to a production environment—whether as a REST API, a batch job, or an embedded component in a larger system. Deployment automation ensures that new models can be rolled out quickly and safely, with minimal downtime.
Monitoring and feedback are also essential. The pipeline should include mechanisms to track model performance in production, detect data drift or anomalies, and trigger alerts or retraining workflows as needed. This closes the loop, allowing teams to respond rapidly to changes in data or business requirements.
Finally, orchestration and workflow management tie all these components together. Tools like Kubeflow, Airflow, or MLflow Pipelines help automate and coordinate the various steps, manage dependencies, and provide visibility into the entire process.
In summary, an effective ML Continuous Delivery pipeline integrates version control, automated data processing, model training and validation, deployment, monitoring, and orchestration. By automating and connecting these components, organizations can deliver high-quality machine learning solutions that adapt quickly to new data and evolving business needs.
Automating Model Validation and Testing
Automating model validation and testing is a cornerstone of effective Continuous Delivery in MLOps. Unlike traditional software, where automated tests focus on code correctness and performance, machine learning systems require a broader and more nuanced approach. Here, validation and testing must ensure not only that the code runs as expected, but also that the model’s predictions are accurate, fair, and robust in the face of changing data.
The first step in automation is unit testing for data pipelines and feature engineering code. These tests check that data transformations work as intended and that edge cases are handled gracefully. Automated data validation tools can also be used to detect missing values, outliers, or schema changes before data reaches the model training stage.
Next comes model validation, which typically involves splitting data into training, validation, and test sets. Automated scripts train the model and evaluate its performance on unseen data, calculating metrics such as accuracy, precision, recall, F1-score, or area under the ROC curve. These metrics are compared against predefined thresholds to determine if the model is good enough for production.
For more advanced scenarios, fairness and bias testing can be automated as well. Tools like Fairlearn or AIF360 can assess whether the model’s predictions are equitable across different groups, helping to prevent unintended discrimination.
Robustness testing is another important aspect. Automated tests can simulate data drift, adversarial examples, or noisy inputs to ensure the model remains reliable under real-world conditions. This helps teams catch potential issues before they impact users.
Finally, integration and end-to-end tests verify that the entire pipeline—from data ingestion to model serving—works as expected. These tests can be triggered automatically whenever new code, data, or models are introduced, providing rapid feedback and reducing the risk of errors reaching production.
By automating model validation and testing, organizations can confidently deploy new models, knowing that they meet quality, fairness, and reliability standards. This not only accelerates the delivery process but also builds trust in machine learning systems, making them more valuable and sustainable in production environments.
Model Packaging and Deployment Strategies
Model packaging and deployment are critical steps in the ML Continuous Delivery pipeline, bridging the gap between model development and real-world application. The goal is to ensure that trained models can be reliably and efficiently delivered to production environments, where they generate value for users and business processes.
Model packaging involves preparing the trained model for deployment. This typically means serializing the model (using formats like Pickle, ONNX, or TensorFlow SavedModel) and bundling it with all necessary dependencies, such as preprocessing scripts, configuration files, and environment specifications. Containerization with Docker has become a standard practice, as it encapsulates the model and its runtime environment, ensuring consistency across development, testing, and production.
Deployment strategies vary depending on the use case and infrastructure. The most common approaches include:
REST API deployment: The model is served as a web service, allowing applications to send data and receive predictions in real time. Frameworks like Flask, FastAPI, or cloud-native solutions such as AWS SageMaker Endpoints and Google AI Platform make this process straightforward and scalable.
Batch deployment: For scenarios where predictions are needed on large datasets at scheduled intervals (e.g., nightly scoring jobs), models are deployed as batch jobs. This approach is common in financial services, marketing, and other data-heavy industries.
Edge deployment: In IoT or mobile applications, models are deployed directly to edge devices, enabling low-latency inference without relying on cloud connectivity. This requires lightweight packaging and careful management of hardware constraints.
Serverless deployment: Leveraging serverless platforms (like AWS Lambda or Google Cloud Functions) allows models to be deployed without managing underlying infrastructure, scaling automatically with demand and optimizing costs.
Blue-green and canary deployments are advanced strategies that minimize risk during model updates. Blue-green deployment runs the new model alongside the old one, switching traffic only when the new version is verified. Canary deployment gradually routes a small percentage of traffic to the new model, monitoring performance before a full rollout.
Regardless of the strategy, automation is key. CI/CD tools and MLOps platforms can automate packaging, testing, and deployment steps, reducing manual errors and accelerating delivery. Integration with model registries ensures that only validated and approved models are deployed, while monitoring tools track performance and trigger rollbacks if issues arise.
In summary, effective model packaging and deployment strategies are essential for operationalizing machine learning. By automating these processes and choosing the right deployment approach, organizations can deliver robust, scalable, and reliable ML solutions that drive real business impact.
Monitoring, Logging, and Feedback Loops
Once a machine learning model is deployed, the work is far from over. In production, continuous monitoring, comprehensive logging, and well-designed feedback loops are essential to ensure that models remain accurate, reliable, and aligned with business goals.
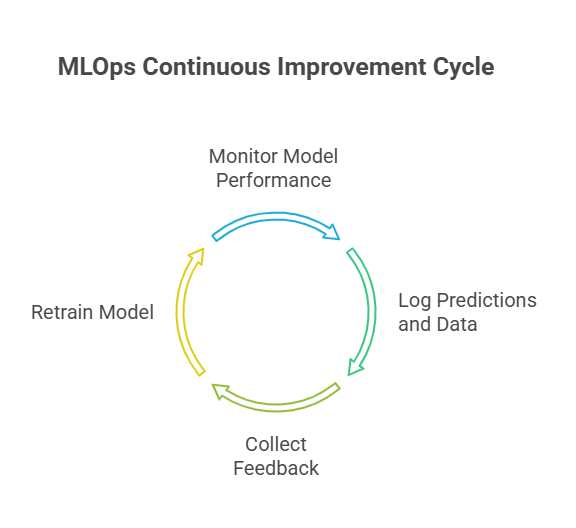
Monitoring in MLOps goes beyond traditional application monitoring. It involves tracking both system-level metrics (like latency, throughput, and resource usage) and model-specific metrics (such as prediction accuracy, data drift, and feature distributions). Automated monitoring tools can detect anomalies in input data, shifts in model performance, or unexpected spikes in prediction errors. For example, if a model’s accuracy drops below a certain threshold, the system can trigger alerts or even initiate automated retraining workflows.
Logging is equally important. Detailed logs capture every prediction, input data, and model version used, creating a transparent record of model behavior. This is crucial for debugging, auditing, and compliance—especially in regulated industries. Logs can also help identify edge cases or rare events that the model may not handle well, providing valuable insights for future improvements.
Feedback loops close the cycle by connecting production outcomes back to the development process. For instance, user interactions or corrections can be logged and used to retrain or fine-tune the model, ensuring it adapts to changing conditions and user needs. Automated feedback mechanisms can flag problematic predictions, collect labeled data, and trigger model updates, making the system more robust and responsive over time.
Modern MLOps platforms often provide integrated solutions for monitoring, logging, and feedback. Tools like Prometheus, Grafana, MLflow, and cloud-native monitoring services enable teams to visualize metrics, set up alerts, and automate responses to issues. By combining these practices, organizations can maintain high model quality, quickly detect and resolve problems, and continuously improve their ML systems in production.
In summary, effective monitoring, logging, and feedback loops are the backbone of reliable machine learning operations. They ensure that models deliver consistent value, adapt to new data, and remain trustworthy throughout their lifecycle.
Security and Compliance in ML Pipelines
Security and compliance are critical considerations in any production ML pipeline, especially as machine learning systems increasingly handle sensitive data and drive key business decisions. Neglecting these aspects can lead to data breaches, regulatory penalties, and loss of trust.
Security in ML pipelines starts with data protection. This means encrypting data at rest and in transit, controlling access to datasets, and ensuring that only authorized users can view or modify sensitive information. Role-based access control (RBAC) and audit trails are standard practices for tracking who accessed what and when. Additionally, secrets management tools (like HashiCorp Vault or cloud-native solutions) help safeguard API keys, credentials, and other sensitive configuration details.
Another important aspect is model security. Models themselves can be targets for attacks, such as model inversion (where attackers try to reconstruct training data) or adversarial attacks (where inputs are crafted to fool the model). To mitigate these risks, teams should monitor for unusual prediction patterns, validate inputs, and consider techniques like adversarial training or differential privacy.
Compliance is especially relevant in regulated industries like finance, healthcare, and insurance. Organizations must ensure that their ML pipelines adhere to legal requirements such as GDPR, HIPAA, or industry-specific standards. This involves maintaining detailed records of data provenance, model versions, and decision logic. Automated logging and documentation tools can help generate the necessary audit trails and reports.
Automated validation and approval workflows are also essential. Before deploying a new model, automated checks can verify that it meets security and compliance criteria—such as data anonymization, fairness, and explainability. Only models that pass these checks should be promoted to production.
Finally, continuous monitoring for security and compliance is crucial. This includes real-time alerts for unauthorized access, data leaks, or compliance violations, as well as regular reviews and updates to policies as regulations evolve.
In summary, integrating security and compliance into every stage of the ML pipeline is not just a best practice—it’s a necessity. By automating protections, maintaining transparency, and staying up to date with regulations, organizations can build trustworthy, resilient, and legally compliant machine learning systems.
Scaling and Optimizing ML Pipelines
As machine learning adoption grows within organizations, the need to scale and optimize ML pipelines becomes increasingly important. Scaling isn’t just about handling more data or serving more predictions—it’s about ensuring that the entire ML workflow remains efficient, reliable, and cost-effective as demand increases.
Scalability in ML pipelines starts with modular design. Breaking down the pipeline into reusable, independent components (such as data ingestion, preprocessing, training, validation, and deployment) allows teams to scale each part independently. Orchestration tools like Kubeflow, Apache Airflow, or cloud-native solutions help automate and manage these workflows, making it easier to parallelize tasks and handle large-scale workloads.
Distributed computing is often essential for training models on massive datasets or running hyperparameter searches. Leveraging frameworks like Apache Spark, Ray, or cloud-based managed services enables teams to distribute computation across multiple nodes, significantly reducing training time and increasing throughput.
Resource optimization is another key factor. This involves selecting the right compute resources (CPUs, GPUs, TPUs) for each pipeline stage, using autoscaling to match resource allocation with workload demands, and monitoring utilization to avoid over-provisioning. Containerization and Kubernetes can help manage resources efficiently, ensuring that workloads are isolated, portable, and easy to scale.
Data management also plays a crucial role. Efficient data storage, caching, and retrieval strategies—such as using data lakes, feature stores, and partitioned datasets—help minimize bottlenecks and speed up pipeline execution. Data versioning ensures that experiments are reproducible and that teams can roll back to previous states if needed.
Cost optimization goes hand in hand with scaling. By monitoring resource usage, automating shutdown of idle resources, and leveraging spot or preemptible instances in the cloud, organizations can keep operational costs under control while scaling up their ML efforts.
Finally, continuous monitoring and feedback ensure that scaling doesn’t compromise model quality or reliability. Automated alerts, performance dashboards, and regular reviews help teams quickly identify and address issues as pipelines grow in complexity.
In summary, scaling and optimizing ML pipelines is about more than just adding hardware—it’s about smart architecture, automation, and resource management. By adopting best practices and leveraging modern tools, organizations can build robust, scalable ML systems that deliver consistent value as they grow.
Security and Compliance Considerations
Security and compliance are foundational to any advanced feature store, especially in enterprise environments where sensitive data and strict regulations are the norm. Feature stores often handle personally identifiable information (PII), financial records, or healthcare data, making robust security controls essential.
Key security considerations include encrypting data at rest and in transit, implementing fine-grained access controls, and maintaining detailed audit logs of all data access and feature usage. Role-based access control (RBAC) ensures that only authorized users can create, modify, or retrieve features. Secrets management tools help protect credentials and API keys used in data pipelines.
Compliance requirements—such as GDPR, HIPAA, or industry-specific standards—demand transparent data lineage, versioning, and the ability to trace every feature back to its source. Automated logging and documentation are critical for audits and regulatory reporting. Additionally, organizations should regularly review and update their security policies to address evolving threats and regulatory changes.
Integrating security and compliance checks into CI/CD pipelines for feature engineering and deployment helps catch issues early. Automated validation can ensure that only compliant features are promoted to production, reducing the risk of data leaks or regulatory violations.
In summary, treating security and compliance as first-class citizens in feature store design and operations is non-negotiable. Proactive measures protect sensitive data, maintain user trust, and ensure that organizations can scale their ML initiatives without running afoul of regulations.
Best Practices and Future Directions
To maximize the value of advanced feature stores, organizations should adopt a set of best practices that ensure reliability, scalability, and cost-effectiveness. These include designing modular and reusable feature pipelines, enforcing strict version control for both data and features, and automating testing and validation at every stage of the ML lifecycle.
Collaboration between data scientists, engineers, and compliance teams is crucial. Shared documentation, clear ownership of features, and regular reviews help prevent duplication and ensure that features are well understood and maintained. Monitoring feature quality and data drift should be automated, with alerts and dashboards to quickly identify and address issues.
Looking ahead, the future of feature stores will likely involve deeper integration with real-time data sources, more sophisticated monitoring and explainability tools, and greater support for multi-cloud and hybrid environments. Advances in privacy-preserving technologies, such as federated learning and differential privacy, will also shape how feature stores handle sensitive data.
Ultimately, the organizations that succeed with feature stores will be those that combine strong technical foundations with a culture of continuous improvement, collaboration, and compliance. By staying ahead of emerging trends and adopting proven best practices, they’ll be well positioned to unlock the full potential of machine learning at scale.
MLOps: Automated Anomaly Detection in Live Data