

Introduction: The Evolving Landscape of Data and ML Operations
In today’s data-driven world, organizations are increasingly relying on both data engineering and machine learning to drive business value. As the volume, velocity, and variety of data continue to grow, so does the complexity of managing data pipelines and machine learning models in production. This has led to the rise of two complementary disciplines: DataOps and MLOps.
DataOps focuses on streamlining and automating the flow of data across the organization. It brings together best practices from DevOps, agile development, and data engineering to ensure that data is high-quality, accessible, and delivered efficiently to downstream consumers—including analytics and machine learning teams.
MLOps, on the other hand, is dedicated to the operationalization of machine learning models. It covers the entire ML lifecycle, from model development and training to deployment, monitoring, and retraining. MLOps ensures that models are reproducible, scalable, and reliable in production environments.
As organizations mature in their use of data and AI, the boundaries between DataOps and MLOps are becoming increasingly blurred. Data pipelines feed machine learning models, and the outputs of those models often become new data sources for further analysis or downstream applications. This interdependence means that a siloed approach to data and ML operations is no longer sustainable.
The Need for Synergy
The synergy between DataOps and MLOps is essential for building robust, end-to-end data and AI workflows. By aligning data management and model management practices, organizations can:
Accelerate the delivery of data and insights to business users
Improve data and model quality through automated validation and monitoring
Ensure compliance and traceability across both data and ML pipelines
Respond quickly to changes in data, business requirements, or regulatory environments
What Is DataOps? Core Principles and Practices
DataOps is a modern approach to data engineering and analytics that applies agile, DevOps, and lean manufacturing principles to the end-to-end data lifecycle. Its primary goal is to deliver high-quality, reliable, and timely data to all stakeholders—data scientists, analysts, business users, and machine learning systems—while minimizing errors, bottlenecks, and manual intervention.
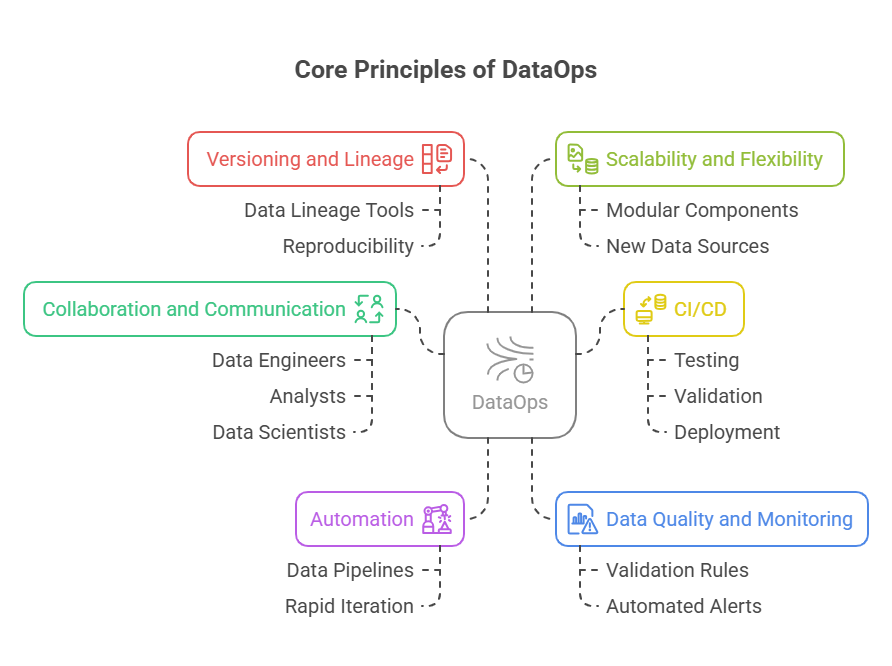
Core Principles of DataOps
Collaboration and Communication:
DataOps breaks down silos between data engineers, analysts, data scientists, and business teams. By fostering collaboration, organizations can align data initiatives with business goals and ensure that everyone has access to the data they need.
Automation:
Automation is at the heart of DataOps. Automated data pipelines handle ingestion, transformation, validation, and delivery, reducing manual work and the risk of human error. Automation also enables rapid iteration and faster delivery of new data products.
Continuous Integration and Continuous Delivery (CI/CD):
Just as in software engineering, DataOps uses CI/CD pipelines to test, validate, and deploy changes to data pipelines and infrastructure. This ensures that updates are reliable, repeatable, and can be rolled back if issues arise.
Data Quality and Monitoring:
DataOps emphasizes proactive data quality checks, validation rules, and monitoring. Automated alerts notify teams of anomalies, missing data, or schema changes, enabling quick response and minimizing downstream impact.
Versioning and Lineage:
Every change to data, code, and configuration is versioned and tracked. Data lineage tools provide visibility into where data comes from, how it’s transformed, and where it’s used—supporting reproducibility, compliance, and troubleshooting.
Scalability and Flexibility:
DataOps pipelines are designed to scale with growing data volumes and adapt to changing business requirements. Modular, reusable components make it easy to add new data sources or analytics use cases.
What Is MLOps? Key Concepts and Lifecycle
MLOps (Machine Learning Operations) is a set of practices and tools that streamline and automate the end-to-end lifecycle of machine learning models. It brings together data science, software engineering, and IT operations to ensure that ML models are developed, deployed, monitored, and maintained efficiently and reliably in production environments.
Key Concepts of MLOps
End-to-End Automation:
MLOps automates the entire ML workflow—from data ingestion and feature engineering, through model training and validation, to deployment, monitoring, and retraining. This reduces manual effort, accelerates iteration, and minimizes the risk of human error.
Continuous Integration and Continuous Deployment (CI/CD):
Just as in modern software development, MLOps uses CI/CD pipelines to automate testing, validation, and deployment of models. This ensures that new models or updates are delivered quickly, safely, and reproducibly.
Model Versioning and Registry:
Every model, along with its training data, code, and configuration, is versioned and stored in a model registry. This enables teams to track, reproduce, and roll back models as needed, supporting collaboration and compliance.
Monitoring and Observability:
MLOps emphasizes continuous monitoring of model performance, data drift, and system health in production. Automated alerts and dashboards help teams detect issues early and respond quickly to maintain model quality.
Collaboration and Governance:
MLOps fosters collaboration between data scientists, ML engineers, and DevOps teams. It also enforces governance through access controls, audit trails, and compliance checks, ensuring that models are deployed responsibly and transparently.
Scalability and Portability:
MLOps pipelines are designed to scale across large datasets, multiple models, and distributed environments (on-premises, cloud, or hybrid). Containerization and orchestration tools (like Docker and Kubernetes) enable portability and efficient resource management.
The MLOps Lifecycle
The typical MLOps lifecycle includes the following stages:
Data Preparation: Ingesting, cleaning, and transforming data for modeling.
Model Development: Experimenting with algorithms, features, and hyperparameters.
Model Validation: Testing models for accuracy, fairness, and robustness.
Model Deployment: Packaging and deploying models to production environments.
Monitoring and Maintenance: Tracking model performance, detecting drift, and triggering retraining or rollback as needed.
The Intersection of DataOps and MLOps: Why Synergy Matters
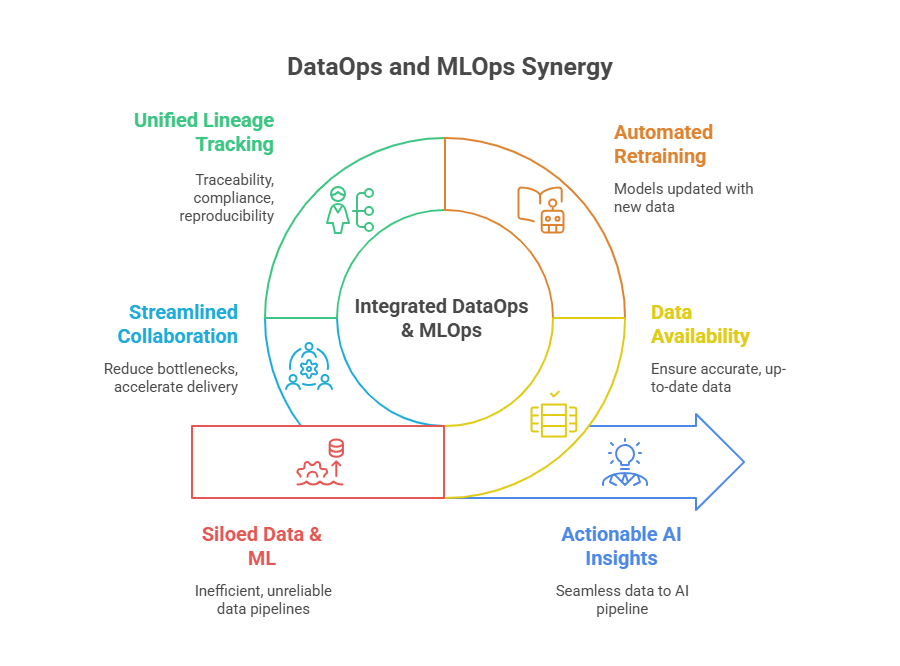
The intersection of DataOps and MLOps is where true value and efficiency are unlocked in modern data-driven organizations. While DataOps focuses on the reliable, automated delivery of high-quality data, MLOps ensures that machine learning models are developed, deployed, and maintained in a robust, scalable, and compliant manner. When these two disciplines work in synergy, they create a seamless pipeline from raw data to actionable AI insights.
Why Synergy Between DataOps and MLOps Is Essential
In practice, machine learning models are only as good as the data they consume. If data pipelines are unreliable, slow, or produce inconsistent results, even the best ML models will underperform or fail in production. Conversely, if ML models are not operationalized with best practices, the value of high-quality data is never fully realized. The synergy between DataOps and MLOps ensures that:
Data is always available, accurate, and up-to-date for model training, validation, and inference.
Models are retrained and updated automatically as new data arrives, keeping predictions relevant and accurate.
Data lineage and model lineage are tracked together, supporting full traceability, compliance, and reproducibility.
Collaboration between data engineers and ML engineers is streamlined, reducing bottlenecks and accelerating delivery.
Building a Unified Data and ML Pipeline
Building a unified data and ML pipeline is at the heart of achieving synergy between DataOps and MLOps. In today’s data-driven organizations, the journey from raw data to actionable machine learning insights is no longer a linear handoff between teams. Instead, it’s a tightly integrated, automated, and collaborative process that spans data engineering, analytics, and machine learning operations.
A unified pipeline begins with the automated ingestion of data from diverse sources—databases, APIs, streaming platforms, and external providers. This data is then subjected to rigorous validation, cleaning, and transformation steps to ensure quality and consistency. DataOps practices ensure that these steps are automated, versioned, and monitored, so that every dataset used for analytics or ML is trustworthy and reproducible.
Once the data is prepared, it flows seamlessly into the machine learning pipeline. Here, features are engineered, selected, and versioned, often using a feature store that serves both DataOps and MLOps needs. The ML pipeline then takes over, orchestrating model training, hyperparameter tuning, and validation. By integrating DataOps and MLOps tools—such as Apache Airflow for orchestration, MLflow for experiment tracking, and DVC for data versioning—teams can automate the entire workflow, from data ingestion to model deployment.
A key advantage of a unified pipeline is the ability to trigger downstream processes based on upstream events. For example, when new data passes validation checks, the pipeline can automatically initiate model retraining, ensuring that predictions remain accurate and relevant. Similarly, if data quality issues or drift are detected in production, the pipeline can alert both data engineers and ML engineers, enabling rapid root cause analysis and remediation.
Unified pipelines also support end-to-end lineage and traceability. Every step—from data extraction and transformation to model training and deployment—is logged and versioned. This makes it possible to reproduce any result, audit the entire process for compliance, and quickly roll back to previous states if issues arise.
Collaboration is another major benefit. With a unified pipeline, data engineers, data scientists, and ML engineers work from a shared source of truth. They can see how changes in data impact model performance, and vice versa. This transparency fosters a culture of shared responsibility and accelerates the delivery of new data products and AI solutions.
In production, unified pipelines enable continuous monitoring and feedback loops. Data quality metrics, model performance, and business KPIs are tracked in real time, with automated alerts and dashboards providing visibility to all stakeholders. This ensures that both data and models remain reliable, scalable, and aligned with business goals.
Data Quality, Validation, and Governance in DataOps and MLOps
Data quality, validation, and governance form the foundation of any successful DataOps and MLOps implementation. Without high-quality, well-governed data, even the most sophisticated machine learning models will produce unreliable results. The synergy between DataOps and MLOps ensures that data quality is maintained throughout the entire pipeline, from ingestion to model inference.
Data quality encompasses multiple dimensions: accuracy, completeness, consistency, timeliness, and validity. In a unified DataOps and MLOps workflow, automated validation checks are embedded at every stage of the pipeline. These checks verify that incoming data meets predefined schemas, falls within expected ranges, and maintains consistency with historical patterns. When data quality issues are detected, the pipeline can automatically halt processing, alert relevant teams, and prevent poor-quality data from reaching downstream models.
Validation in this context goes beyond simple data checks. It includes validating feature distributions, model inputs, and prediction outputs. For example, if a model expects certain features to have specific statistical properties, automated validation can detect when these properties change, potentially indicating data drift or upstream pipeline issues.
Governance ensures that data usage complies with organizational policies, regulatory requirements, and ethical standards. This includes managing data access permissions, maintaining audit trails, and ensuring that sensitive data is handled appropriately. In a unified pipeline, governance policies are enforced automatically, reducing the risk of compliance violations and data misuse.
Here’s a simple Python example demonstrating automated data validation:
python
import pandas as pd
def validate_data(df, schema):
"""Simple data validation function"""
errors = []
# Check required columns
missing_cols = set(schema['required_columns']) - set(df.columns)
if missing_cols:
errors.append(f"Missing columns: {missing_cols}")
# Check data types and ranges
for col, rules in schema['validation_rules'].items():
if col in df.columns:
if 'min_value' in rules and df[col].min() < rules['min_value']:
errors.append(f"{col} below minimum: {df[col].min()}")
if 'max_value' in rules and df[col].max() > rules['max_value']:
errors.append(f"{col} above maximum: {df[col].max()}")
return len(errors) == 0, errors
# Example usage
schema = {
'required_columns': ['age', 'income'],
'validation_rules': {
'age': {'min_value': 0, 'max_value': 120},
'income': {'min_value': 0, 'max_value': 1000000}
}
}
data = pd.DataFrame({'age': [25, 30, 150], 'income': [50000, 75000, 60000]})
is_valid, errors = validate_data(data, schema)
print(f"Data valid: {is_valid}")
if errors:
print(f"Errors: {errors}")The integration of data quality, validation, and governance across DataOps and MLOps creates a robust framework for maintaining trust in both data and models. Automated validation prevents poor-quality data from corrupting model training, while governance ensures that all data usage is compliant and auditable. This foundation enables organizations to scale their data and AI initiatives with confidence, knowing that quality and compliance are built into every step of the process.
Versioning and Lineage: Tracking Data and Model Changes
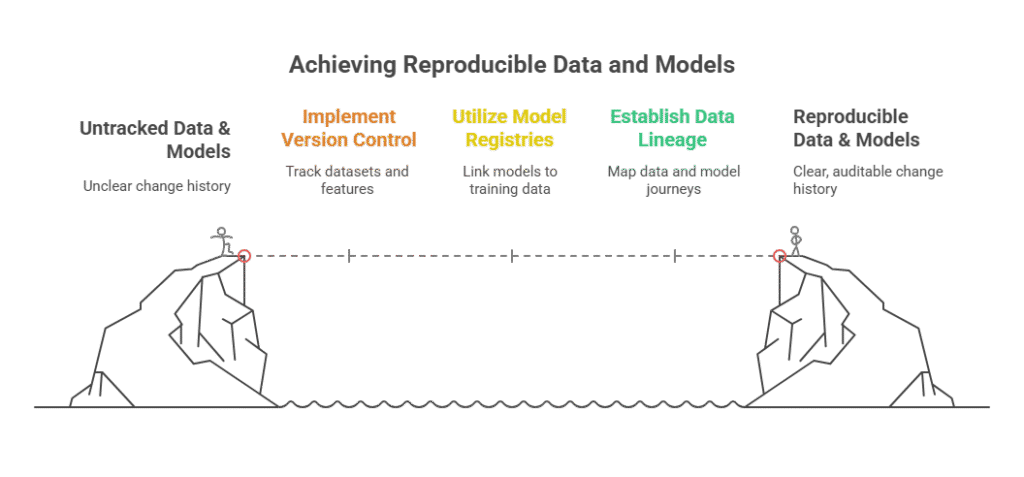
Versioning and lineage are fundamental to building trust, reproducibility, and compliance in modern DataOps and MLOps workflows. As data and models evolve, tracking every change—along with its context and dependencies—ensures that teams can reproduce results, debug issues, and meet regulatory requirements.
Why Versioning Matters
In both data and machine learning pipelines, versioning means keeping a detailed record of every change to datasets, features, code, and models. This allows teams to:
Reproduce experiments and results, even months or years later
Roll back to previous versions if errors or regressions are detected
Audit the full history of data and model changes for compliance
Data Versioning in DataOps
Data versioning tools like DVC, LakeFS, and Delta Lake enable teams to track changes to raw and processed datasets, just as Git tracks code. Every transformation, cleaning step, or feature engineering process is logged and linked to a specific data version. This makes it possible to trace the lineage of any data point used in analytics or model training.
Model Versioning in MLOps
Model registries (such as MLflow, SageMaker Model Registry, or Azure ML) provide version control for machine learning models. Each model version is linked to the exact data, code, hyperparameters, and environment used for training. This ensures that every model in production can be traced back to its origin, supporting reproducibility and safe rollback.
Lineage: The Full Story
Lineage goes beyond versioning by mapping the entire journey of data and models through the pipeline. It answers questions like:
Where did this data come from?
What transformations were applied?
Which model was trained on which data version?
How did a prediction reach its final form?
Lineage tracking tools and metadata catalogs (e.g., Amundsen, DataHub) visualize these relationships, making it easier to debug, audit, and optimize workflows.
Automation and Orchestration: Tools and Frameworks
Automation and orchestration are the engines that drive efficient DataOps and MLOps workflows. By automating repetitive tasks and orchestrating complex dependencies across data and ML pipelines, organizations can accelerate delivery, reduce errors, and scale their operations effectively.
The Role of Automation
Automation in DataOps and MLOps eliminates manual intervention in routine tasks such as data ingestion, validation, transformation, model training, and deployment. This not only speeds up workflows but also ensures consistency and reduces the risk of human error. Automated pipelines can run on schedules, be triggered by events (like new data arrival), or respond to performance thresholds.
Orchestration: Managing Complex Workflows
Orchestration tools manage the execution order, dependencies, and resource allocation across multiple pipeline components. They ensure that data processing steps complete before model training begins, that validation passes before deployment, and that failures are handled gracefully with appropriate retries or rollbacks.
Popular Tools and Frameworks
Apache Airflow: A widely-used open-source platform for orchestrating complex workflows with rich scheduling, monitoring, and dependency management capabilities.
Kubeflow Pipelines: Designed specifically for ML workflows on Kubernetes, offering containerized, scalable pipeline execution.
Prefect: A modern workflow orchestration tool with dynamic task generation and robust error handling.
Cloud-native solutions: AWS Step Functions, Azure Data Factory, and Google Cloud Composer provide managed orchestration services.
Integration Benefits
When DataOps and MLOps share orchestration platforms, teams can create end-to-end workflows that seamlessly transition from data preparation to model deployment. This unified approach enables better resource utilization, simplified monitoring, and faster troubleshooting.
Here’s a simple Python example using a basic orchestration pattern:
python
def orchestrate_pipeline():
"""Simple pipeline orchestration example"""
try:
# Step 1: Data validation
print("Step 1: Validating data...")
data_valid = validate_data()
if not data_valid:
raise Exception("Data validation failed")
# Step 2: Feature engineering
print("Step 2: Engineering features...")
features = engineer_features()
# Step 3: Model training
print("Step 3: Training model...")
model = train_model(features)
# Step 4: Model validation
print("Step 4: Validating model...")
if model.accuracy > 0.85:
deploy_model(model)
print("Pipeline completed successfully!")
else:
print("Model accuracy too low, not deploying")
except Exception as e:
print(f"Pipeline failed: {e}")
# Trigger alerts or rollback procedures
def validate_data():
return True # Simplified validation
def engineer_features():
return {"feature_count": 10}
def train_model(features):
class Model:
accuracy = 0.87
return Model()
def deploy_model(model):
print(f"Deploying model with accuracy: {model.accuracy}")
# Run pipeline
orchestrate_pipeline()Monitoring, Observability, and Incident Response
Monitoring, observability, and incident response are essential for maintaining reliable, scalable, and trustworthy DataOps and MLOps workflows. As data pipelines and machine learning models move into production, the ability to detect, diagnose, and resolve issues quickly becomes a critical success factor.
Monitoring in DataOps and MLOps
Monitoring involves tracking key metrics and system health indicators across the entire data and ML lifecycle. For data pipelines, this includes data freshness, ingestion rates, validation errors, and pipeline latency. For ML models, monitor performance metrics (accuracy, precision, recall), prediction latency, drift scores, and resource utilization.
Observability: Beyond Basic Monitoring
Observability provides a deeper, holistic view of your systems by combining metrics, logs, and traces. This enables teams to:
Correlate data and model issues with infrastructure events
Trace the flow of data and predictions through complex pipelines
Identify root causes of failures or performance drops
Unified dashboards (using tools like Grafana, Kibana, or cloud-native solutions) help visualize trends, spot anomalies, and provide actionable insights for both data and ML teams.
Incident Response: Rapid Detection and Resolution
When issues arise—such as data drift, model degradation, or pipeline failures—rapid incident response is crucial. Best practices include:
Automated alerts: Trigger notifications for anomalies, threshold breaches, or system errors.
Runbooks and playbooks: Provide step-by-step guides for common incidents, enabling faster triage and resolution.
Rollback and recovery: Maintain the ability to quickly revert to previous data or model versions if a deployment causes problems.
Post-incident reviews: Conduct blameless postmortems to identify root causes, improve processes, and prevent recurrence.
Security, Compliance, and Auditability Across Data and ML Workflows
Security, compliance, and auditability are non-negotiable requirements for any organization running data and machine learning workflows in production. As data pipelines and ML models become more deeply integrated into business operations, ensuring that these systems are secure, compliant, and fully auditable is essential for protecting sensitive information, meeting regulatory obligations, and building trust with stakeholders.
Security in DataOps and MLOps
Access Control: Implement role-based access control (RBAC) and least-privilege principles for all data and model assets. Use centralized identity management (SSO, LDAP, OAuth) to manage user permissions across data pipelines, feature stores, and model registries.
Encryption: Encrypt data at rest and in transit using industry-standard protocols. Ensure that all sensitive data, including logs and model artifacts, is protected from unauthorized access.
Vulnerability Management: Regularly scan for vulnerabilities in code, dependencies, and infrastructure. Automate patching and updates to minimize exposure to threats.
Network Security: Use private endpoints, VPNs, and firewalls to restrict access to critical data and ML services.
Compliance in DataOps and MLOps
Data Residency and Retention: Store and process data in compliance with regional regulations (e.g., GDPR, HIPAA). Implement automated data retention and deletion policies to meet legal requirements.
Audit Trails: Maintain detailed, immutable logs of all data access, pipeline executions, model deployments, and user actions. This is crucial for regulatory audits and incident investigations.
Explainability and Fairness: Integrate explainability tools and bias detection frameworks to ensure that models are transparent, fair, and compliant with ethical and legal standards.
Real-World Case Studies: DataOps and MLOps in Action
Real-world case studies provide the most compelling evidence of how DataOps and MLOps synergy can transform data and machine learning operations. By examining how leading organizations have implemented unified data and ML pipelines, we can extract practical lessons and best practices for success.
Case Study 1: Global Retailer – Unified Data and ML Pipeline for Personalization
A global retailer wanted to deliver personalized product recommendations to millions of users across multiple regions. Their challenge was to manage diverse data sources, ensure data quality, and rapidly deploy new ML models as customer behavior changed.
Solution:
The company implemented a unified pipeline using Apache Airflow for orchestration, DVC for data versioning, and MLflow for model tracking and registry. DataOps teams automated data ingestion, validation, and feature engineering, while MLOps teams managed model training, validation, and deployment. Automated data quality checks triggered model retraining when new data arrived or drift was detected.
Results:
Reduced time-to-market for new models from weeks to days
Improved recommendation accuracy and customer engagement
Full traceability and auditability for compliance
Case Study 2: Financial Services – Compliance and Auditability at Scale
A financial institution needed to comply with strict regulations for credit risk modeling. They faced challenges in tracking data lineage, managing model versions, and ensuring that only approved models were deployed.
Solution:
The team adopted a hybrid approach, using cloud-native data pipelines for scalability and on-premises model registries for compliance. DataOps practices ensured that every dataset was versioned and validated, while MLOps workflows enforced approval gates and audit logging for all model transitions. Automated monitoring and alerting provided early detection of data drift and model performance issues.
Results:
Passed regulatory audits with minimal manual effort
Reduced risk of unauthorized model changes
Improved collaboration between data, risk, and compliance teams
Case Study 3: Healthcare – Data Quality and Model Reliability for Patient Safety
A healthcare analytics company developed ML models for patient risk prediction. Ensuring data quality and model reliability was critical for patient safety and regulatory compliance.
Solution:
The company implemented end-to-end DataOps and MLOps pipelines using open source tools (Great Expectations for data validation, MLflow for model management) and cloud-based monitoring. Data quality checks were embedded at every stage, and model performance was continuously monitored in production. Incident response playbooks enabled rapid rollback if issues were detected.
Results:
Improved model reliability and patient safety
Faster response to data or model issues
Enhanced trust with clinicians and regulators
Lessons Learned
Automate everything: From data validation to model deployment, automation reduces errors and accelerates delivery.
Centralize metadata and lineage: Unified tracking of data and models is essential for reproducibility and compliance.
Integrate monitoring and alerting: Real-time observability enables rapid incident response and continuous improvement.
Foster cross-team collaboration: Success depends on close cooperation between data engineers, data scientists, and compliance teams.
Best Practices for Achieving Synergy
Achieving true synergy between DataOps and MLOps is the key to building robust, scalable, and trustworthy data and machine learning workflows. When these disciplines work together, organizations can accelerate innovation, improve data and model quality, and ensure compliance and operational efficiency. Here are the best practices for making this synergy a reality:
1. Build Unified, Modular Pipelines
Design your data and ML workflows as modular, reusable components that can be orchestrated end-to-end. Use workflow orchestration tools (like Apache Airflow, Kubeflow, or cloud-native solutions) to automate the entire journey from data ingestion to model deployment and monitoring.
2. Automate Data and Model Validation
Embed automated validation checks at every stage of the pipeline. Validate data quality, schema, and feature distributions before model training. Validate model performance, fairness, and drift before deployment. Automation reduces manual errors and ensures only high-quality data and models reach production.
3. Version Everything
Version control is essential for both data and models. Use tools like DVC, LakeFS, or Delta Lake for data versioning, and MLflow or cloud-native registries for model versioning. Link data, code, and model versions for full reproducibility and traceability.
4. Centralize Metadata and Lineage Tracking
Maintain a unified metadata catalog that tracks the lineage of data and models across the entire workflow. This supports debugging, compliance, and auditability, and makes it easier to onboard new team members.
5. Integrate Monitoring and Observability
Set up real-time monitoring and alerting for both data pipelines and ML models. Use dashboards to visualize key metrics, and automate alerts for anomalies, drift, or performance drops. Integrate explainability tools to provide transparency into model decisions.
6. Enforce Security, Compliance, and Access Control
Implement role-based access control (RBAC), encryption, and audit logging across all data and ML assets. Automate compliance checks and maintain detailed audit trails to meet regulatory requirements.
7. Foster Collaboration and Communication
Break down silos between data engineering, data science, and operations teams. Use shared tools, documentation, and regular cross-team reviews to ensure alignment and knowledge sharing.
8. Start Simple, Scale Gradually
Begin with a minimal, working pipeline and add complexity as needed. Avoid over-engineering; focus on solving immediate business problems and iteratively improving your workflows.
9. Document Everything
Maintain clear, up-to-date documentation for all pipelines, validation rules, monitoring setups, and incident response procedures. Good documentation accelerates troubleshooting and supports compliance.
10. Continuously Review and Improve
Regularly review pipeline performance, incident reports, and new technology trends. Encourage a culture of experimentation and learning to keep your DataOps and MLOps practices up to date.
Future Trends in Data and ML Operations
The future of DataOps and MLOps is being shaped by rapid advances in automation, cloud technology, and AI-driven tooling. As organizations strive for greater agility, scalability, and trust in their data and machine learning workflows, several key trends are emerging that will define the next generation of data and ML operations.
1. Deeper Integration of DataOps and MLOps
The boundaries between DataOps and MLOps will continue to blur, with unified platforms and tools supporting seamless end-to-end workflows. Expect to see more solutions that manage data pipelines, feature stores, model registries, and monitoring in a single, integrated environment.
2. AI-Driven Automation and Self-Healing Pipelines
AI and machine learning will increasingly be used to automate pipeline orchestration, data validation, drift detection, and incident response. Self-healing pipelines will automatically detect and resolve issues, retrain models, or roll back to previous states without human intervention.
3. Real-Time and Streaming Data Workflows
As businesses demand faster insights, real-time and streaming data pipelines will become the norm. DataOps and MLOps tools will evolve to support low-latency data ingestion, real-time feature engineering, and continuous model retraining.
4. Edge and Federated ML Operations
With the rise of IoT and edge computing, data and ML operations will extend beyond the cloud and data center. Tools will be needed to manage, monitor, and update models running on distributed edge devices, while ensuring data privacy and compliance through federated learning.
5. Enhanced Observability and Explainability
Future platforms will offer deeper observability, combining metrics, logs, traces, and explainability into unified dashboards. Automated root cause analysis, bias detection, and compliance reporting will become standard features.
6. Privacy, Security, and Compliance by Design
As regulations tighten and data privacy becomes a competitive differentiator, DataOps and MLOps workflows will embed security, access control, and compliance checks at every stage. Automated audit trails and policy enforcement will be essential.
7. Cost Optimization and Sustainability
With growing focus on cloud costs and environmental impact, future tools will provide real-time insights into resource usage, carbon footprint, and cost optimization opportunities—helping organizations balance performance, compliance, and sustainability.