
Introduction: Why Explainability Matters in MLOps
Explainability is becoming a cornerstone of modern MLOps. As machine learning models are increasingly used in critical business processes, healthcare, finance, and public services, organizations face growing pressure to ensure that their AI systems are transparent and understandable. Stakeholders—including business leaders, regulators, and end users—want to know not just what a model predicts, but why it makes those predictions.
Explainable AI (XAI) provides methods and tools that help uncover the reasoning behind model outputs. In the MLOps context, explainability is essential for building trust in AI solutions, supporting regulatory compliance, and enabling effective collaboration between technical and non-technical teams. Without explainability, it becomes difficult to detect bias, diagnose errors, or justify automated decisions—risks that can have serious business and ethical consequences.
Moreover, explainability is not just a concern during model development. In production environments, models encounter new data and changing conditions, which can lead to unexpected behaviors. Integrating explainability into MLOps pipelines ensures that explanations are available throughout the model lifecycle, from initial training to real-time predictions. This continuous transparency helps organizations monitor, audit, and improve their AI systems, making explainability a key factor in responsible and sustainable machine learning operations.
Key Concepts of Explainable AI (XAI)
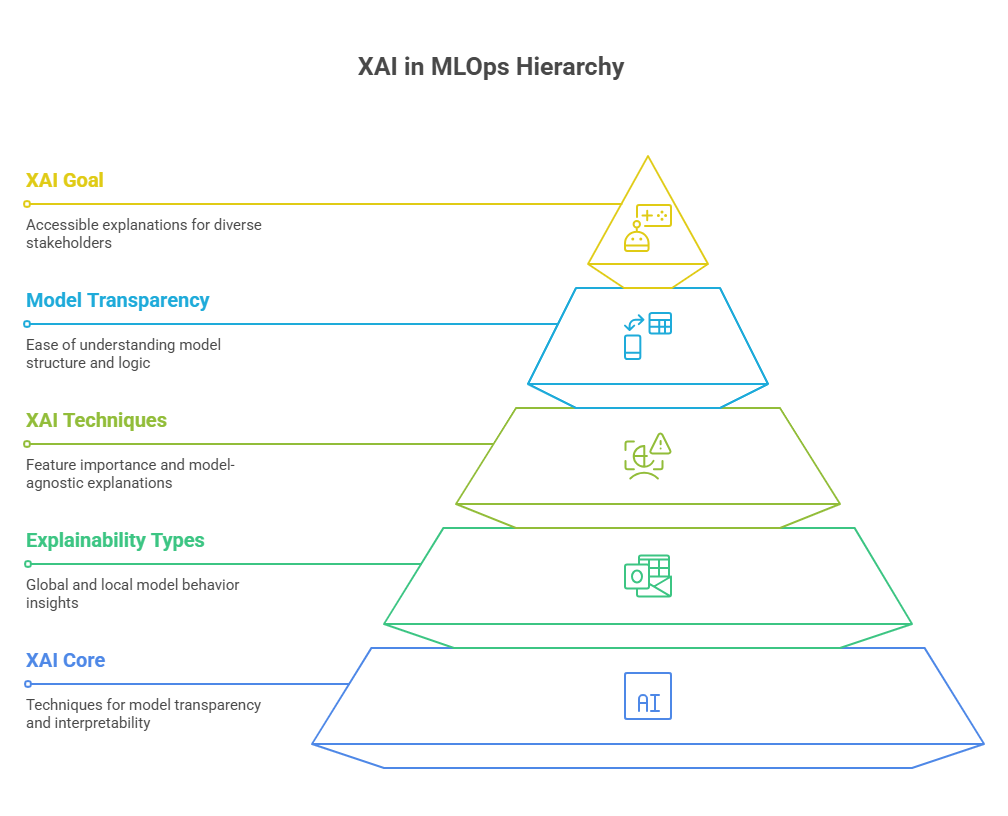
Explainable AI (XAI) encompasses a range of concepts and techniques designed to make machine learning models more transparent and interpretable. At its core, XAI aims to answer questions like: “Why did the model make this prediction?” and “Which features influenced the outcome the most?” Understanding these concepts is crucial for anyone working with MLOps, as explainability directly impacts trust, compliance, and model improvement.
There are two main types of explainability: global and local. Global explainability focuses on understanding the overall behavior of a model—how it makes decisions across the entire dataset. Local explainability, on the other hand, provides insights into individual predictions, explaining why the model made a specific decision for a particular input.
Common XAI techniques include feature importance analysis, which ranks the most influential variables in a model, and methods like SHAP (SHapley Additive exPlanations) or LIME (Local Interpretable Model-agnostic Explanations), which generate human-readable explanations for complex models. Some models, such as decision trees or linear regressions, are inherently interpretable, while others—like deep neural networks—require additional tools to make their decisions understandable.
Another important concept is model transparency, which refers to how easily a human can understand the structure and logic of a model. Transparent models are easier to explain but may not always offer the best performance. Balancing accuracy and interpretability is a key challenge in XAI.
Ultimately, the goal of XAI in MLOps is to ensure that explanations are accessible, actionable, and relevant to different stakeholders, from data scientists to business users and regulators. This foundation enables organizations to deploy AI systems that are not only powerful but also trustworthy and accountable.
The Role of Explainability Across the ML Lifecycle
Explainability plays a vital role at every stage of the machine learning lifecycle, from initial data exploration to model deployment and ongoing monitoring. Its presence ensures that models are not only accurate but also transparent, trustworthy, and aligned with business and regulatory requirements.
During data exploration and feature engineering, explainability helps teams understand which features are most relevant and how they influence the target variable. This insight guides better feature selection and engineering, leading to more robust models. When building and training models, explainability allows data scientists to interpret model behavior, diagnose issues such as overfitting or bias, and compare different algorithms beyond just performance metrics.
In the validation and testing phase, explainability supports the identification of edge cases and potential sources of error. It enables teams to communicate model strengths and limitations to stakeholders, making it easier to gain buy-in and address concerns before deployment.
Once a model is in production, explainability becomes even more critical. It allows for real-time monitoring of predictions, helping to detect data drift, unexpected behaviors, or fairness issues as new data flows through the system. Explanations can be surfaced to end users, auditors, or regulators, providing transparency and accountability for automated decisions.
Finally, explainability facilitates continuous improvement. By understanding why a model makes certain predictions, teams can iterate more effectively, retrain models with better data, and ensure that AI systems remain aligned with organizational goals and ethical standards. In this way, explainability is not a one-time task but an ongoing requirement throughout the entire ML lifecycle.
Popular Tools and Libraries for Explainable AI
The growing demand for explainability in machine learning has led to the development of a rich ecosystem of tools and libraries that make it easier to interpret and understand model behavior. These solutions range from open-source Python packages to integrated features in major cloud platforms, supporting both simple and complex models across various use cases.
Among the most widely used open-source libraries are SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations). SHAP provides a unified framework for interpreting predictions by assigning each feature an importance value for a particular prediction, grounded in game theory. LIME, on the other hand, explains individual predictions by approximating the model locally with an interpretable surrogate model. Both tools are model-agnostic, meaning they can be applied to a wide range of algorithms, including black-box models like neural networks and ensemble methods.
For tree-based models, libraries such as ELI5 and TreeExplainer (part of SHAP) offer specialized support, making it easy to visualize feature importances and decision paths. For deep learning, Captum (for PyTorch) and tf-explain (for TensorFlow) provide methods to interpret neural networks, including saliency maps and layer-wise relevance propagation.
In addition to open-source tools, major cloud providers like AWS, Google Cloud, and Azure have integrated explainability features into their machine learning platforms. These services often include built-in dashboards for feature importance, bias detection, and model transparency, making it easier to meet regulatory and business requirements.
The choice of tool depends on the type of model, the complexity of the use case, and the needs of stakeholders. By leveraging these libraries and platforms, teams can embed explainability into their MLOps workflows, ensuring that models are not only high-performing but also transparent and trustworthy.
Integrating Explainability into MLOps Pipelines
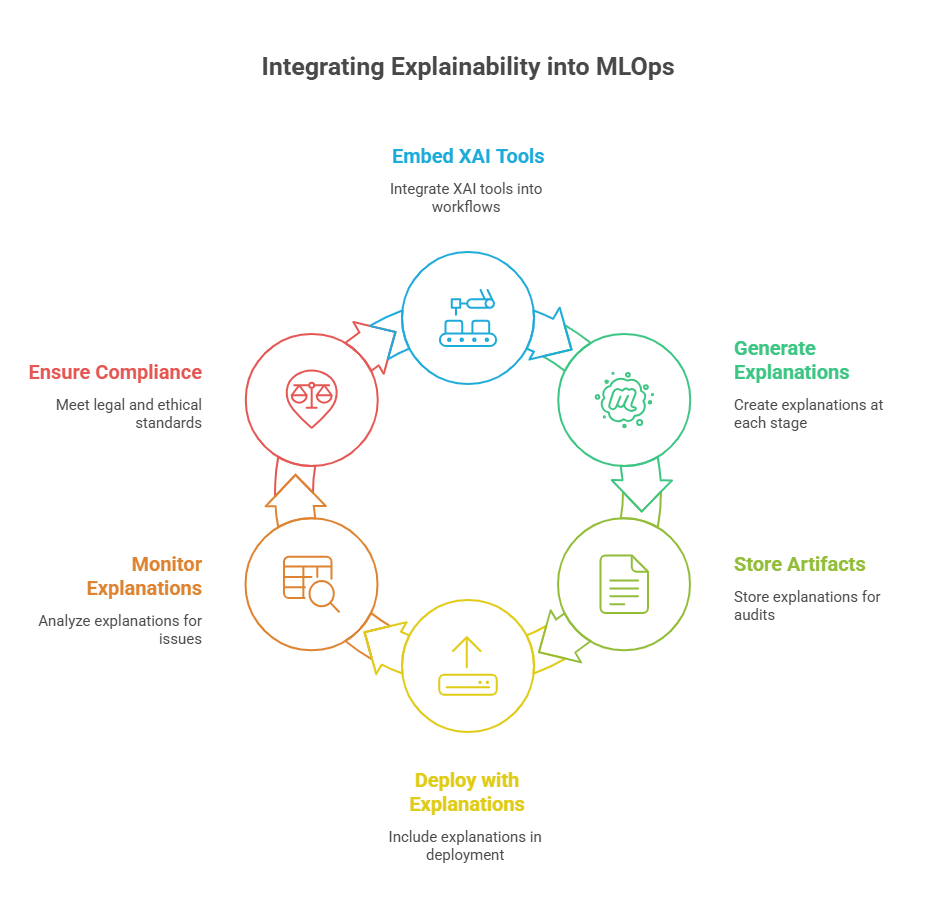
Integrating explainability into MLOps pipelines is essential for building AI systems that are not only accurate but also transparent, auditable, and aligned with organizational values. This integration ensures that explanations are available at every stage of the machine learning lifecycle, from development to deployment and ongoing monitoring.
In practice, explainability can be embedded into automated workflows by incorporating XAI tools and techniques into data preprocessing, model training, and evaluation steps. For example, during model training, pipelines can automatically generate feature importance reports or local explanations for sample predictions using libraries like SHAP or LIME. These artifacts can be stored alongside model versions in a model registry, making them accessible for audits or stakeholder reviews.
When deploying models, explainability components can be included as part of the serving infrastructure. This allows real-time explanations to be generated and delivered alongside predictions, which is especially valuable in regulated industries or applications where users need to understand automated decisions. Some organizations also expose explanation APIs, enabling external systems or users to request justifications for specific predictions.
Monitoring pipelines can leverage explainability to detect issues such as data drift, bias, or unexpected model behavior. By continuously analyzing feature importances and explanation patterns, teams can identify when a model’s reasoning changes, prompting further investigation or retraining.
Finally, integrating explainability into MLOps pipelines supports compliance with legal and ethical standards, such as GDPR or industry-specific regulations. It also fosters collaboration between data scientists, engineers, business stakeholders, and regulators by making model decisions more accessible and understandable.
In summary, explainability should be treated as a first-class citizen in MLOps, with dedicated steps and tools woven into the end-to-end workflow. This approach not only builds trust in AI systems but also enables faster iteration, safer deployments, and more responsible machine learning operations.
Challenges and Limitations of Explainable AI
While explainable AI (XAI) is increasingly recognized as essential for trustworthy machine learning, integrating it into real-world systems comes with several challenges and limitations. Understanding these obstacles is crucial for setting realistic expectations and designing effective MLOps workflows.
One major challenge is the trade-off between model complexity and interpretability. Highly accurate models, such as deep neural networks or ensemble methods, are often “black boxes” that are difficult to explain, while simpler models are more transparent but may not achieve the same level of performance. Striking the right balance between accuracy and explainability is an ongoing struggle, especially in high-stakes applications.
Another limitation is that many XAI techniques provide approximations rather than true explanations. Tools like SHAP and LIME generate useful insights, but their explanations are based on surrogate models or statistical assumptions, which may not always reflect the actual reasoning of the underlying model. This can lead to misleading interpretations if not used carefully.
Scalability is also a concern. Generating explanations for large datasets or in real-time production environments can be computationally expensive, potentially impacting system performance. Organizations must design their pipelines to handle this overhead or selectively generate explanations where they are most needed.
Additionally, explainability is not always straightforward for all stakeholders. Technical explanations may be clear to data scientists but confusing to business users or end customers. Creating explanations that are both accurate and accessible to diverse audiences remains a significant challenge.
Finally, regulatory requirements and ethical considerations are evolving rapidly. Organizations must stay up to date with legal standards for transparency and fairness, which can vary by industry and region. Ensuring that explainability solutions meet these requirements adds another layer of complexity to MLOps processes.
In summary, while XAI is a powerful tool for building trust and accountability in AI systems, it is not a silver bullet. Teams must be aware of its limitations, carefully select appropriate techniques, and continuously adapt their approaches as technology and regulations evolve.
Best Practices for Explainability in MLOps
To maximize the value of explainable AI in production environments, organizations should adopt a set of best practices that ensure explainability is reliable, actionable, and seamlessly integrated into the MLOps lifecycle.
First, treat explainability as a core requirement from the outset—not as an afterthought. This means selecting models and tools with explainability in mind, and designing pipelines that automatically generate and store explanations alongside model artifacts. Early planning helps avoid costly rework and ensures that explanations are available when needed for audits, debugging, or stakeholder communication.
Second, tailor explanations to your audience. Data scientists may need detailed, technical insights, while business users or customers often require simple, intuitive summaries. Providing layered explanations—ranging from high-level overviews to in-depth technical details—can help bridge this gap and foster trust across the organization.
Third, automate the generation and validation of explanations as part of your CI/CD and monitoring workflows. For example, use tools like SHAP or LIME to produce feature importance reports during model training, and set up automated checks to flag unexpected changes in explanation patterns during model updates or retraining. This proactive approach helps catch issues early and supports continuous improvement.
Fourth, document and version all explanation artifacts. Store them in a centralized repository or model registry, linked to specific model versions and datasets. This practice supports traceability, reproducibility, and compliance with regulatory requirements.
Fifth, regularly review and update your explainability strategies. As models, data, and regulations evolve, so should your approach to XAI. Solicit feedback from stakeholders, monitor the effectiveness of explanations in practice, and stay informed about advances in XAI research and tooling.
By following these best practices, organizations can build AI systems that are not only high-performing but also transparent, trustworthy, and aligned with business and ethical standards—ultimately driving better outcomes and greater adoption of machine learning in production.
Case Study: Implementing Explainable AI in a Real-World MLOps Pipeline
To illustrate how explainable AI can be integrated into a production MLOps pipeline, let’s look at a practical case study from the financial sector—specifically, a bank deploying a credit risk scoring model.
The bank’s data science team developed a high-performing gradient boosting model to predict the likelihood of loan default. However, regulatory requirements and internal policies demanded that every automated decision be explainable to both auditors and customers. To address this, the team embedded SHAP-based explainability into their MLOps workflow.
During model training, the pipeline automatically generated global feature importance reports and local explanations for a sample of predictions. These artifacts were versioned and stored alongside the trained model in the model registry. When the model was deployed to production, the serving infrastructure was extended to include a SHAP explainer service. This service generated real-time explanations for each prediction, which were then attached to API responses and made available in the bank’s customer portal.
For monitoring, the MLOps pipeline included automated checks that compared feature importance distributions over time. If significant drift or unexpected changes were detected, alerts were triggered for further investigation. This helped the team quickly identify issues such as data drift or model degradation, ensuring ongoing compliance and model reliability.
The bank also tailored explanations for different audiences. Customers received simple, human-readable summaries explaining the main factors influencing their credit decisions, while auditors and risk managers had access to detailed breakdowns and visualizations.
This case study demonstrates that, with the right tools and pipeline design, explainable AI can be seamlessly integrated into MLOps workflows. The result is a system that not only delivers accurate predictions but also meets regulatory standards, builds user trust, and supports transparent, responsible AI deployment in high-stakes environments.
Future Directions in Explainable AI and Feature Stores
The landscape of explainable AI (XAI) and feature stores is evolving rapidly, driven by advances in machine learning, growing regulatory demands, and the need for greater transparency in AI systems. Looking ahead, several key trends are shaping the future of these domains.
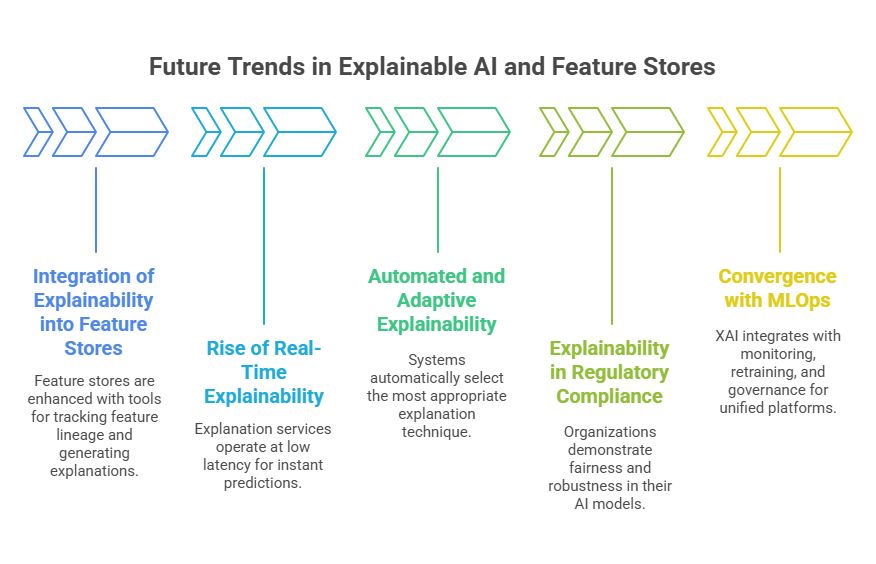
One major direction is the deeper integration of explainability into feature stores themselves. As feature stores become central hubs for managing and serving features, they are increasingly being enhanced with built-in tools for tracking feature lineage, monitoring feature drift, and generating explanations for how features contribute to model predictions. This tight integration will make it easier for organizations to trace decisions back to specific data sources and transformations, supporting both compliance and debugging.
Another trend is the rise of real-time, on-demand explainability. As more applications require instant predictions—such as fraud detection or personalized recommendations—there is a growing need for explanation services that can operate at low latency and scale. Future MLOps platforms are likely to offer native support for real-time explanation APIs, making it possible to deliver transparent AI even in high-throughput environments.
Automated and adaptive explainability is also on the horizon. Emerging research is focused on systems that can automatically select the most appropriate explanation technique based on the model, data, and user context. This will help ensure that explanations are both accurate and accessible, regardless of the underlying complexity.
In addition, explainability is expected to play a larger role in regulatory compliance and ethical AI. As laws and standards evolve, organizations will need to demonstrate not only that their models are fair and unbiased, but also that their explanations are robust, consistent, and understandable to non-technical stakeholders.
Finally, the convergence of XAI with other aspects of MLOps—such as monitoring, retraining, and governance—will lead to more unified, end-to-end platforms. These platforms will enable organizations to manage the entire machine learning lifecycle with transparency and accountability at every step.
In summary, the future of explainable AI and feature stores is one of deeper integration, greater automation, and broader impact—empowering organizations to build AI systems that are not only powerful, but also trustworthy, transparent, and aligned with societal values.
Conclusion: Building Transparent and Trustworthy ML Systems
As machine learning becomes increasingly embedded in critical business processes and societal systems, the need for transparency and trustworthiness has never been more important. Throughout this exploration of explainable AI in MLOps, we’ve seen how organizations can build systems that are not only accurate and scalable, but also interpretable and accountable.
The key to success lies in treating explainability as a first-class citizen in the MLOps lifecycle—not as an afterthought, but as an integral component of model development, deployment, and monitoring. By integrating tools like SHAP, LIME, and feature stores with built-in lineage tracking, organizations can create pipelines that automatically generate, validate, and serve explanations alongside predictions.
The benefits extend far beyond regulatory compliance. Transparent ML systems foster trust among stakeholders, enable faster debugging and model improvement, support better decision-making, and ultimately drive greater adoption of AI across the organization. As we’ve seen in real-world case studies, these benefits are achievable with the right combination of tools, processes, and organizational commitment.
Looking forward, the convergence of explainable AI with other MLOps capabilities—monitoring, governance, and automation—will create even more powerful platforms for responsible AI deployment. Organizations that invest in these capabilities today will be better positioned to navigate the evolving regulatory landscape and build AI systems that deliver lasting value.
Here’s a practical Python example that demonstrates how to build a complete explainable ML pipeline with monitoring and feature tracking:
python
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import shap
import mlflow
import mlflow.sklearn
from datetime import datetime
import warnings
warnings.filterwarnings('ignore')
class ExplainableMLPipeline:
def __init__(self, experiment_name="explainable_ml_pipeline"):
self.model = None
self.explainer = None
self.feature_names = None
mlflow.set_experiment(experiment_name)
def prepare_data(self, data_path=None):
"""Simulate data preparation with feature tracking"""
# Generate sample data (in practice, load from feature store)
np.random.seed(42)
n_samples = 1000
# Create synthetic features with business meaning
data = {
'credit_score': np.random.normal(650, 100, n_samples),
'income': np.random.exponential(50000, n_samples),
'debt_ratio': np.random.beta(2, 5, n_samples),
'employment_years': np.random.poisson(5, n_samples),
'age': np.random.normal(40, 12, n_samples)
}
df = pd.DataFrame(data)
# Create target variable with realistic relationships
risk_score = (
-0.01 * df['credit_score'] +
-0.00001 * df['income'] +
2.0 * df['debt_ratio'] +
-0.1 * df['employment_years'] +
-0.02 * df['age'] +
np.random.normal(0, 0.5, n_samples)
)
df['default_risk'] = (risk_score > np.percentile(risk_score, 70)).astype(int)
self.feature_names = [col for col in df.columns if col != 'default_risk']
print(f"Dataset prepared with {len(df)} samples and {len(self.feature_names)} features")
print(f"Feature names: {self.feature_names}")
print(f"Target distribution: {df['default_risk'].value_counts().to_dict()}")
return df
def train_model(self, df):
"""Train model with explainability tracking"""
with mlflow.start_run():
# Split data
X = df[self.feature_names]
y = df['default_risk']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Train model
self.model = RandomForestClassifier(
n_estimators=100,
random_state=42,
max_depth=10
)
self.model.fit(X_train, y_train)
# Evaluate model
y_pred = self.model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
# Log metrics
mlflow.log_metric("accuracy", accuracy)
mlflow.log_param("n_estimators", 100)
mlflow.log_param("max_depth", 10)
# Create SHAP explainer
self.explainer = shap.TreeExplainer(self.model)
shap_values = self.explainer.shap_values(X_test)
# Log feature importance
feature_importance = pd.DataFrame({
'feature': self.feature_names,
'importance': self.model.feature_importances_
}).sort_values('importance', ascending=False)
print("Model Performance:")
print(f"Accuracy: {accuracy:.4f}")
print("\nFeature Importance:")
print(feature_importance)
# Log model
mlflow.sklearn.log_model(self.model, "model")
# Store test data for monitoring
self.X_test = X_test
self.y_test = y_test
self.shap_values = shap_values[1] if len(shap_values) == 2 else shap_values
return accuracy
def generate_explanations(self, sample_data=None, n_samples=5):
"""Generate explanations for sample predictions"""
if sample_data is None:
sample_data = self.X_test.head(n_samples)
predictions = self.model.predict(sample_data)
probabilities = self.model.predict_proba(sample_data)
# Generate SHAP explanations
shap_values = self.explainer.shap_values(sample_data)
if len(shap_values) == 2:
shap_values = shap_values[1] # For binary classification
explanations = []
for i in range(len(sample_data)):
explanation = {
'prediction': int(predictions[i]),
'probability': float(probabilities[i][1]),
'features': {},
'top_factors': []
}
# Feature contributions
for j, feature in enumerate(self.feature_names):
explanation['features'][feature] = {
'value': float(sample_data.iloc[i][feature]),
'contribution': float(shap_values[i][j])
}
# Top contributing factors
feature_contributions = [(feature, float(shap_values[i][j]))
for j, feature in enumerate(self.feature_names)]
feature_contributions.sort(key=lambda x: abs(x[1]), reverse=True)
explanation['top_factors'] = feature_contributions[:3]
explanations.append(explanation)
return explanations
def monitor_feature_drift(self, new_data):
"""Monitor for feature drift using statistical tests"""
from scipy import stats
drift_results = {}
for feature in self.feature_names:
# Kolmogorov-Smirnov test for distribution drift
statistic, p_value = stats.ks_2samp(
self.X_test[feature],
new_data[feature]
)
drift_detected = p_value < 0.05
drift_results[feature] = {
'ks_statistic': float(statistic),
'p_value': float(p_value),
'drift_detected': drift_detected,
'severity': 'high' if p_value < 0.01 else 'medium' if p_value < 0.05 else 'low'
}
print("Feature Drift Monitoring Results:")
for feature, result in drift_results.items():
status = "DRIFT DETECTED" if result['drift_detected'] else "OK"
print(f"{feature}: {status} (p-value: {result['p_value']:.4f})")
return drift_results
def generate_explanation_report(self):
"""Generate comprehensive explanation report"""
if self.model is None or self.explainer is None:
raise ValueError("Model must be trained first")
# Global feature importance
global_importance = pd.DataFrame({
'feature': self.feature_names,
'importance': self.model.feature_importances_
}).sort_values('importance', ascending=False)
# SHAP summary statistics
shap_mean_abs = np.mean(np.abs(self.shap_values), axis=0)
shap_importance = pd.DataFrame({
'feature': self.feature_names,
'shap_importance': shap_mean_abs
}).sort_values('shap_importance', ascending=False)
report = {
'timestamp': datetime.now().isoformat(),
'model_type': type(self.model).__name__,
'n_features': len(self.feature_names),
'global_importance': global_importance.to_dict('records'),
'shap_importance': shap_importance.to_dict('records'),
'explanation_coverage': {
'samples_explained': len(self.X_test),
'features_tracked': len(self.feature_names)
}
}
return report
# Example usage
def main():
# Initialize pipeline
pipeline = ExplainableMLPipeline("credit_risk_explainable")
# Prepare data
df = pipeline.prepare_data()
# Train model
accuracy = pipeline.train_model(df)
# Generate explanations for sample predictions
explanations = pipeline.generate_explanations(n_samples=3)
print("\nSample Explanations:")
for i, exp in enumerate(explanations):
print(f"\nPrediction {i+1}:")
print(f" Risk Level: {'High' if exp['prediction'] == 1 else 'Low'}")
print(f" Probability: {exp['probability']:.3f}")
print(" Top Contributing Factors:")
for factor, contribution in exp['top_factors']:
direction = "increases" if contribution > 0 else "decreases"
print(f" - {factor}: {direction} risk by {abs(contribution):.3f}")
# Simulate new data for drift monitoring
new_data = pipeline.prepare_data()
drift_results = pipeline.monitor_feature_drift(new_data[pipeline.feature_names])
# Generate comprehensive report
report = pipeline.generate_explanation_report()
print(f"\nExplanation Report Generated: {report['timestamp']}")
print(f"Model Type: {report['model_type']}")
print(f"Features Tracked: {report['n_features']}")
if __name__ == "__main__":
main()
# Created/Modified files during execution:
print("explainable_ml_pipeline.py")Additional Resources and Tools for Explainable AI in MLOps
For teams and individuals looking to deepen their expertise in explainable AI (XAI) and its integration with MLOps, a wealth of resources and tools are available. Here’s a curated overview to help you get started or advance your practice:
Open-Source Libraries and Frameworks:
Some of the most widely used libraries for model explainability include SHAP (SHapley Additive exPlanations), LIME (Local Interpretable Model-agnostic Explanations), and ELI5. These tools support a variety of models and provide both global and local explanations, making them suitable for integration into MLOps pipelines. For deep learning models, Captum (for PyTorch) and tf-explain (for TensorFlow) offer specialized explainability methods.
Feature Store Platforms:
Modern feature stores such as Feast, Tecton, and Hopsworks are increasingly adding support for feature lineage, monitoring, and explainability. These platforms help track how features are created, transformed, and used in production, which is essential for both transparency and compliance.
MLOps Platforms with Built-in Explainability:
Major cloud providers—AWS SageMaker, Google Vertex AI, and Azure Machine Learning—offer built-in explainability features, including automatic feature importance, bias detection, and model monitoring. These platforms make it easier to operationalize XAI at scale and ensure explanations are available for both technical and business stakeholders.
Educational Resources:
There are excellent books, courses, and online tutorials for learning about XAI and MLOps. Notable books include Interpretable Machine Learning by Christoph Molnar and Responsible Machine Learning by Patrick Hall and James Curtis. Online courses from Coursera, DataCamp, and Udacity cover both the theory and practical implementation of explainable AI.
Community and Research:
The XAI and MLOps communities are active and growing. Participating in forums like MLOps.community, reading blogs (e.g., Towards Data Science, Google AI Blog), and following conferences such as NeurIPS, ICML, and the Responsible AI track at major cloud summits can help you stay up to date with the latest trends and best practices.
Sample Python Code for Integrating SHAP in MLOps:
python
import shap
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# Example: Integrating SHAP into a simple MLOps workflow
df = pd.read_csv("your_data.csv")
X = df.drop("target", axis=1)
y = df["target"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = RandomForestClassifier().fit(X_train, y_train)
# Create SHAP explainer and calculate SHAP values
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
# Save SHAP values for monitoring or audit
pd.DataFrame(shap_values[1], columns=X.columns).to_csv("shap_values_test.csv", index=False)
# Visualize feature importance
shap.summary_plot(shap_values[1], X_test)MLOps: Enterprise Practices for Developers
MLOps in Practice: Automation and Scaling of the Machine Learning Lifecycle