

Introduction: The Business Value of MLOps
In today’s competitive landscape, machine learning (ML) has become a critical driver of innovation and business growth. However, the true value of ML is realized only when models are reliably deployed, monitored, and maintained in production environments. This is where MLOps—Machine Learning Operations—plays a pivotal role. By combining best practices from software engineering, data science, and IT operations, MLOps enables organizations to accelerate the delivery of ML solutions while ensuring quality, scalability, and compliance.
For developers, understanding the business value of MLOps is essential. MLOps bridges the gap between model development and real-world impact, transforming experimental models into production-grade systems that drive measurable outcomes. It reduces time-to-market by automating repetitive tasks such as data preprocessing, model training, testing, and deployment. This automation not only speeds up innovation but also minimizes errors and operational risks.
Moreover, MLOps enhances model reliability through continuous monitoring and automated retraining, ensuring that models adapt to changing data and business conditions. This leads to sustained performance and better decision-making, which directly translates into increased revenue, cost savings, and improved customer experiences.
From a strategic perspective, MLOps supports compliance with regulatory requirements by maintaining detailed audit trails, version control, and governance over data and models. This builds trust with stakeholders and reduces legal risks.
The Developer’s Role in Driving MLOps Success
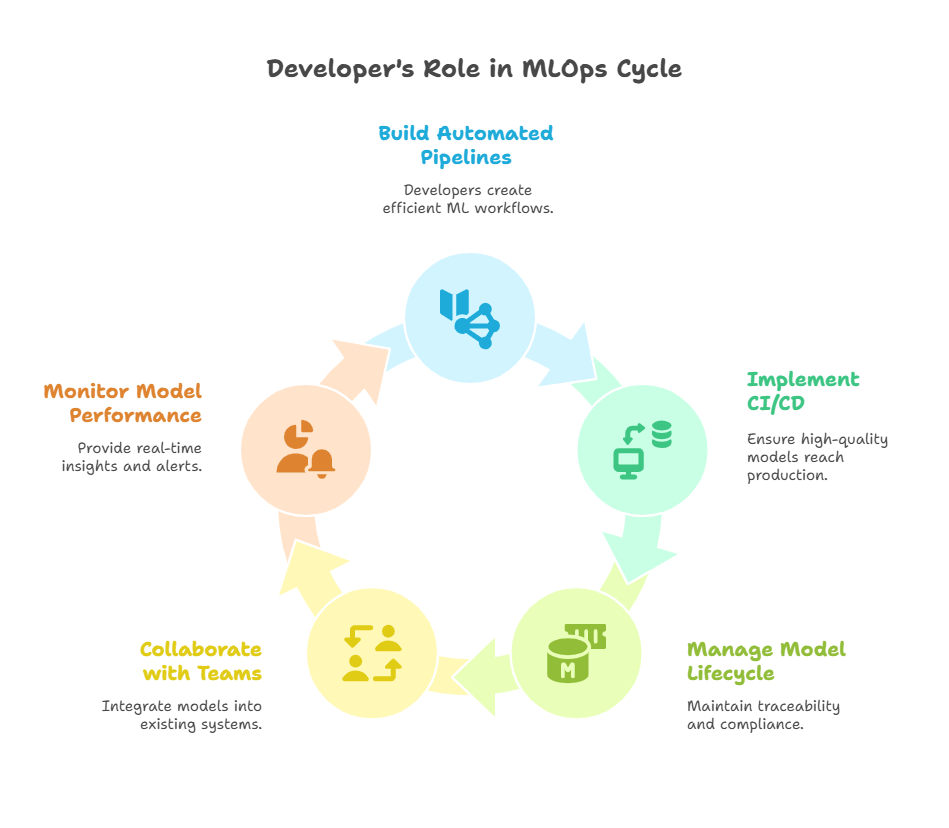
Developers play a crucial role in the success of MLOps initiatives, acting as the bridge between data science innovation and reliable production deployment. Their expertise in software engineering, automation, and system design is essential for transforming machine learning models from experimental prototypes into scalable, maintainable, and impactful business solutions.
One of the primary responsibilities of developers in MLOps is building and maintaining automated pipelines. This includes automating data ingestion, preprocessing, model training, validation, deployment, and monitoring. By creating robust, reusable, and modular pipelines, developers ensure that ML workflows are efficient, consistent, and less prone to errors. Automation accelerates the delivery of new models and updates, enabling organizations to respond quickly to changing business needs.
Developers also implement continuous integration and continuous deployment (CI/CD) practices tailored for machine learning. Unlike traditional software, ML models depend on data and require additional validation steps. Developers design CI/CD pipelines that incorporate automated testing of data quality, model performance, and fairness, ensuring that only high-quality models reach production.
Another critical aspect is model versioning and lifecycle management. Developers integrate model registries and artifact repositories into workflows, enabling traceability, reproducibility, and safe rollbacks. This governance is vital for compliance and operational stability.
Furthermore, developers collaborate closely with data scientists, DevOps, and business teams to ensure seamless integration of ML models into existing systems and applications. They help design scalable serving architectures, optimize resource usage, and implement monitoring and alerting systems that provide real-time insights into model health and performance.
Automating ML Workflows to Boost Productivity
Automation is at the heart of successful MLOps, enabling teams to accelerate machine learning development while maintaining high quality and reliability. For developers, automating ML workflows means reducing manual, repetitive tasks and creating scalable, repeatable pipelines that streamline the entire model lifecycle—from data ingestion to deployment and monitoring.
Why Automate ML Workflows?
Manual processes in ML development are time-consuming and error-prone. Data preprocessing, feature engineering, model training, hyperparameter tuning, validation, and deployment often involve complex, multi-step procedures that can be difficult to manage without automation. By automating these workflows, developers can:
Increase productivity: Automate routine tasks to focus on innovation and problem-solving.
Ensure consistency: Reduce human errors and maintain reproducibility across experiments and deployments.
Accelerate iteration: Quickly test new models and features, shortening the time from development to production.
Scale efficiently: Manage multiple models and datasets across teams and environments with minimal overhead.
Key Areas for Automation
Data Pipelines: Automate data extraction, transformation, and loading (ETL) processes using tools like Apache Airflow, Prefect, or cloud-native services.
Feature Engineering: Use feature stores and automated feature pipelines to standardize and reuse features across models.
Model Training and Tuning: Automate training jobs, hyperparameter optimization, and validation using frameworks like Ray Tune, Optuna, or Kubeflow Pipelines.
Model Deployment: Implement CI/CD pipelines that automatically package, test, and deploy models to staging or production environments.
Monitoring and Retraining: Set up automated monitoring for model performance and data drift, triggering retraining workflows as needed.
Example: Automating a Simple ML Training Pipeline with Python
python
def automate_training_pipeline(data_loader, preprocess, train_model, evaluate_model):
# Load data
data = data_loader()
# Preprocess data
processed_data = preprocess(data)
# Train model
model = train_model(processed_data)
# Evaluate model
metrics = evaluate_model(model, processed_data)
# Log metrics and decide on deployment
print(f"Model accuracy: {metrics['accuracy']:.2f}")
if metrics['accuracy'] > 0.85:
print("Deploying model...")
# Deployment logic here
else:
print("Model did not meet accuracy threshold.")
return model, metrics
# Example usage with dummy functions
def load_data():
print("Loading data...")
return [1, 2, 3]
def preprocess(data):
print("Preprocessing data...")
return [x * 2 for x in data]
def train_model(data):
print("Training model...")
return {"model": "dummy_model"}
def evaluate_model(model, data):
print("Evaluating model...")
return {"accuracy": 0.9}
automate_training_pipeline(load_data, preprocess, train_model, evaluate_model)Implementing Continuous Integration and Deployment (CI/CD)
Continuous Integration and Continuous Deployment (CI/CD) are foundational practices in modern MLOps that enable teams to deliver machine learning models rapidly, reliably, and at scale. By integrating CI/CD into ML workflows, developers can automate testing, validation, and deployment processes—reducing manual errors and accelerating the path from experimentation to production.
Why CI/CD Matters in MLOps
Unlike traditional software, ML models depend heavily on data, which can change frequently and impact model performance. CI/CD pipelines for ML must therefore handle not only code changes but also data validation, model training, and performance monitoring. Implementing CI/CD ensures that every change—whether in code, data, or configuration—is automatically tested and validated before deployment, maintaining high quality and consistency.
Key Components of ML CI/CD Pipelines
Automated Testing: Run unit tests on data preprocessing and model code, integration tests on pipeline components, and validation tests on model performance.
Model Training and Validation: Automate training jobs triggered by new data or code changes, with automated evaluation against predefined metrics.
Model Registry Integration: Automatically register new model versions with metadata and performance metrics.
Deployment Automation: Deploy models to staging or production environments using containerization and orchestration tools.
Monitoring and Feedback: Integrate monitoring to track model performance post-deployment and trigger retraining or rollback if necessary.
Example: Simple CI/CD Pipeline with GitHub Actions
yaml
name: ML CI/CD Pipeline
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
test-and-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.9'
- name: Install dependencies
run: |
pip install -r requirements.txt
- name: Run tests
run: |
pytest tests/
- name: Train and validate model
run: |
python train.py --validate
- name: Deploy model
if: success()
run: |
python deploy.pyEnsuring Model Quality with Automated Testing
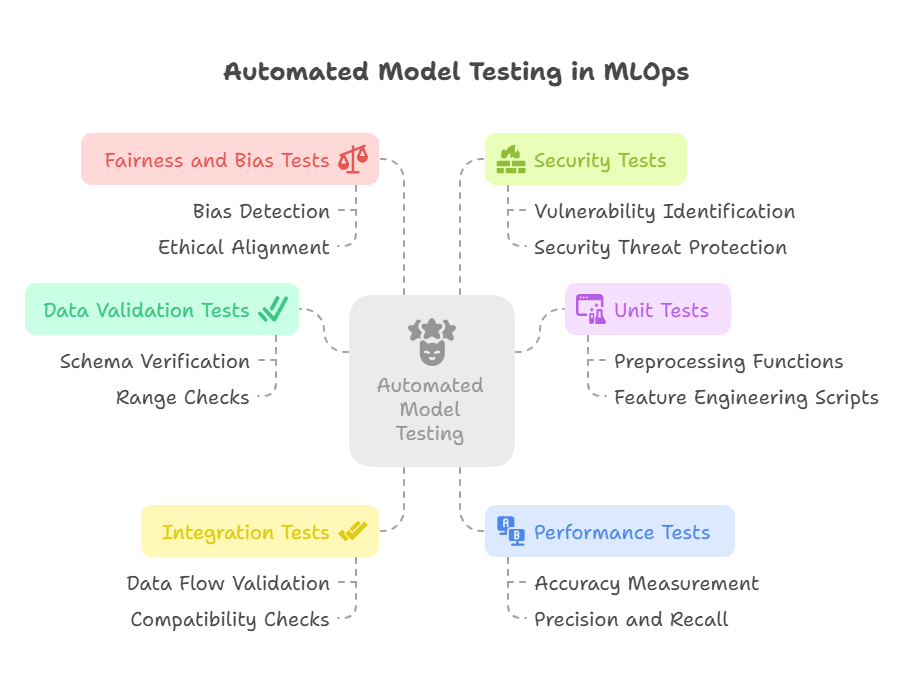
Ensuring model quality through automated testing is a cornerstone of successful MLOps. It’s not enough to simply train a model and deploy it; you need to have confidence that it will perform reliably in production, adapt to changing data, and meet business requirements. Automated testing provides that assurance, catching issues early and preventing costly mistakes.
Automated testing in MLOps goes beyond traditional software testing. It encompasses not only code correctness but also data validation, model performance evaluation, and fairness checks. This multi-faceted approach ensures that every aspect of the ML system is thoroughly tested before deployment.
Key components of automated model testing include:
Data Validation Tests: These tests verify that incoming data meets predefined schemas, falls within expected ranges, and maintains consistency with historical patterns. They catch data quality issues early, preventing them from corrupting model training or inference.
Unit Tests: Unit tests focus on individual components of the ML pipeline, such as data preprocessing functions, feature engineering scripts, or custom loss functions. They ensure that each unit of code behaves as expected and handles edge cases gracefully.
Integration Tests: Integration tests validate that different components of the ML workflow work together correctly. This includes checking that data flows smoothly from ingestion to feature engineering, that models can be trained and evaluated with the expected data formats, and that outputs from one stage are compatible with the next.
Performance Tests: Performance tests measure model accuracy, precision, recall, and other relevant metrics on holdout datasets. They ensure that the model meets predefined quality gates and performs as expected in a production-like environment.
Fairness and Bias Tests: These tests evaluate models for unintended bias or discrimination against certain demographic groups. They help ensure that models are fair, equitable, and aligned with ethical standards.
Security Tests: Security tests identify potential vulnerabilities in model code, dependencies, and deployment configurations. They help protect against adversarial attacks, data breaches, and other security threats.
By automating these tests and integrating them into CI/CD pipelines, organizations can ensure that every model version is thoroughly validated before deployment. This reduces the risk of production incidents, improves model reliability, and builds trust with stakeholders.
Monitoring Models for Performance and Reliability
Monitoring machine learning models for performance and reliability is a critical component of successful MLOps. Once a model is deployed into production, its environment becomes dynamic—data distributions shift, user behaviors evolve, and external factors change. Without continuous monitoring, these changes can degrade model performance, leading to inaccurate predictions, poor user experiences, and ultimately, business losses.
Why Monitoring Matters
Monitoring provides real-time insights into how models behave in production. It helps detect issues such as data drift, concept drift, model staleness, and infrastructure problems before they impact end users. By tracking key performance metrics and system health indicators, organizations can maintain high-quality, reliable AI services.
Key Metrics to Monitor
Model Performance Metrics: Accuracy, precision, recall, F1-score, AUC, and business-specific KPIs should be tracked continuously to detect performance degradation.
Data Quality Metrics: Monitor input data for missing values, outliers, distribution shifts, and schema changes to catch data drift early.
Prediction Metrics: Track prediction confidence, distribution, and error rates to identify anomalies or unexpected behavior.
Latency and Throughput: Measure response times and request volumes to ensure models meet service-level agreements (SLAs).
Resource Utilization: Monitor CPU, GPU, memory, and network usage to optimize infrastructure and prevent bottlenecks.
Implementing Effective Monitoring
Automate Metric Collection: Use tools like Prometheus, Grafana, or cloud-native monitoring services to collect and visualize metrics in real time.
Set Up Alerts: Configure automated alerts for critical thresholds or sudden changes in metrics to enable rapid response.
Integrate with Model Registry and CI/CD: Link monitoring data with model versions and deployment pipelines for full traceability.
Use Explainability Tools: Incorporate explainability metrics to understand changes in model behavior and build trust.
Regularly Review and Update: Continuously refine monitoring strategies as models and business needs evolve.
Benefits of Robust Monitoring
Effective monitoring reduces downtime, improves user trust, and enables proactive maintenance. It supports compliance by providing audit trails and helps data science teams prioritize retraining or model improvements based on real-world performance.
Enhancing Collaboration Between Data Science and Engineering
Effective collaboration between data science and engineering teams is a cornerstone of successful MLOps. As machine learning projects grow in complexity and scale, bridging the gap between these disciplines becomes essential to accelerate development, improve model quality, and ensure smooth deployment and maintenance.
Why Collaboration Matters
Data scientists focus on developing models, experimenting with algorithms, and analyzing data, while engineers build scalable pipelines, manage infrastructure, and deploy models into production. Without strong collaboration, projects can suffer from misaligned goals, duplicated efforts, and deployment bottlenecks. MLOps fosters a culture where both teams work together seamlessly, sharing tools, processes, and responsibilities.
Key Strategies to Enhance Collaboration
Shared Tools and Platforms:
Use integrated platforms that support both data science and engineering workflows, such as MLflow for experiment tracking and model registry, or Kubeflow for pipeline orchestration. This ensures transparency and reduces handoff friction.
Version Control for Code and Data:
Implement unified versioning systems (e.g., Git for code, DVC for data) accessible to both teams. This enables reproducibility and easier debugging.
Clear Communication and Documentation:
Maintain comprehensive documentation of data schemas, model assumptions, pipeline steps, and deployment processes. Regular cross-team meetings and shared communication channels (Slack, Confluence) foster alignment.
Automated Testing and Validation:
Develop automated tests that cover both data transformations and model logic. This ensures that changes by one team do not break the work of the other.
Define Roles and Responsibilities:
Clearly delineate ownership of data pipelines, model development, deployment, and monitoring. Establish escalation paths for issues and collaborative decision-making processes.
Continuous Feedback Loops:
Use monitoring and observability data to provide feedback to data scientists about model performance in production, enabling iterative improvements.
Benefits of Strong Collaboration
When data science and engineering teams collaborate effectively, organizations benefit from faster development cycles, higher model quality, more reliable deployments, and better alignment with business objectives. This synergy also improves team morale and reduces operational risks.
Managing Model Versions and Lifecycle Effectively
Effective management of model versions and their lifecycle is a critical aspect of enterprise MLOps. As machine learning models evolve through continuous training, tuning, and deployment, organizations need robust strategies to track, control, and govern these changes to ensure reliability, reproducibility, and compliance.
The Importance of Model Versioning
Model versioning involves maintaining a detailed history of every iteration of a machine learning model, including the code, training data, hyperparameters, and evaluation metrics used. This enables teams to reproduce results, compare different versions, and understand the impact of changes over time. Without proper versioning, it becomes challenging to debug issues, audit model decisions, or roll back to previous stable versions when necessary.
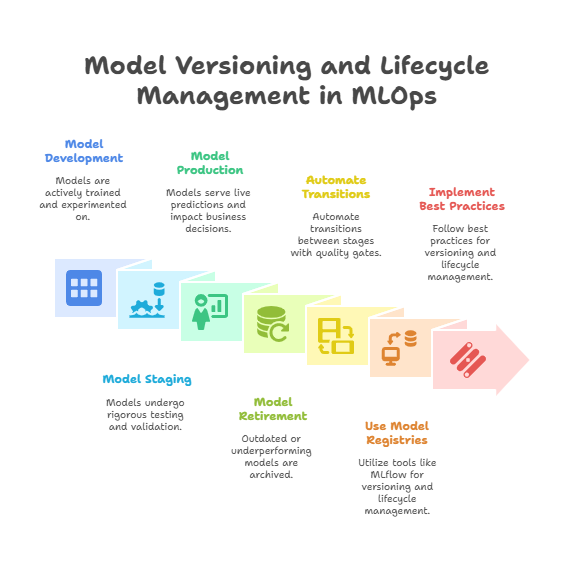
Lifecycle Management Stages
Managing the model lifecycle means overseeing the progression of models through various stages such as development, staging, production, and retirement. Each stage has specific criteria and controls:
Development: Models are actively trained and experimented on.
Staging: Models undergo rigorous testing and validation in a production-like environment.
Production: Models serve live predictions and impact business decisions.
Retirement: Outdated or underperforming models are archived or decommissioned.
Automating transitions between these stages with clear quality gates and approval workflows ensures that only validated models reach production, reducing risk and improving trust.
Tools and Practices
Model registries like MLflow, SageMaker Model Registry, or Azure ML provide centralized platforms for versioning and lifecycle management. They support metadata tracking, stage transitions, and integration with CI/CD pipelines. Using these tools, teams can automate model registration, promotion, rollback, and retirement processes.
Best Practices
Automate versioning and lifecycle transitions to reduce manual errors.
Define clear quality gates and approval processes for model promotion.
Maintain comprehensive metadata and audit logs for compliance and traceability.
Implement rollback mechanisms to quickly revert to previous model versions if issues arise.
Regularly review and clean up old model versions to optimize storage and reduce complexity.
Cost Optimization Strategies in MLOps
As machine learning operations scale within enterprises, managing and optimizing costs becomes a critical concern. MLOps workflows often involve substantial compute, storage, and data transfer expenses, especially when models are trained and deployed across multiple environments or cloud providers. Implementing effective cost optimization strategies ensures that organizations can maximize the value of their AI investments while maintaining operational efficiency.
Understanding Cost Drivers
The primary cost drivers in MLOps include compute resources (CPUs, GPUs, TPUs), storage for datasets and model artifacts, data transfer between services or regions, and operational overhead such as monitoring and orchestration. Without careful management, these costs can escalate rapidly, especially during large-scale training or real-time inference workloads.
Key Cost Optimization Techniques
Resource Right-Sizing:
Continuously monitor resource utilization and adjust instance types, cluster sizes, and scaling policies to match workload demands without over-provisioning.
Spot and Preemptible Instances:
Use discounted compute options like AWS Spot Instances or Google Preemptible VMs for non-critical or batch training jobs to significantly reduce costs.
Efficient Data Storage:
Implement data lifecycle policies that move infrequently accessed data to cheaper storage tiers (e.g., AWS Glacier, Google Coldline) and use compressed, efficient data formats.
Batch vs. Real-Time Processing:
Where possible, prefer batch processing over real-time inference to reduce the need for always-on, expensive compute resources.
Automated Shutdown of Idle Resources:
Detect and terminate unused or idle resources such as development clusters, training jobs, or model endpoints to avoid unnecessary charges.
Cost-Aware Scheduling:
Schedule heavy workloads during off-peak hours or in regions with lower pricing to optimize expenses.
Monitoring and Reporting
Implement cost monitoring dashboards and alerts to track spending by project, team, or environment. Use tagging and cost allocation tools to attribute expenses accurately and promote accountability.
Real-World Success Stories: Developers Creating Business Impact with MLOps
Real-world success stories demonstrate how developers leveraging MLOps practices can significantly increase business value by delivering reliable, scalable, and impactful machine learning solutions. These examples highlight the transformative power of MLOps in accelerating innovation, improving operational efficiency, and driving measurable outcomes.
Case Study 1: Retail Giant Boosts Sales with Personalized Recommendations
A leading retail company implemented an MLOps pipeline that automated data ingestion, model training, deployment, and monitoring for their recommendation engine. Developers integrated CI/CD workflows with model registries and real-time monitoring, enabling rapid iteration and continuous improvement. As a result, the company saw a 15% increase in conversion rates and a 10% boost in average order value, directly impacting revenue.
Case Study 2: Financial Services Enhances Fraud Detection
A financial institution used MLOps to deploy and manage multiple fraud detection models across different regions. Developers built automated retraining pipelines triggered by data drift detection, ensuring models adapted quickly to emerging fraud patterns. The robust monitoring and alerting system reduced false positives by 20% and improved detection accuracy, saving millions in potential losses.
Case Study 3: Healthcare Provider Improves Patient Outcomes
A healthcare analytics firm adopted MLOps to manage predictive models for patient risk assessment. Developers implemented explainability tools and compliance monitoring within their MLOps framework, ensuring transparency and regulatory adherence. Automated testing and deployment pipelines accelerated model updates, leading to more timely interventions and improved patient outcomes.
Key Takeaways for Developers
Automation accelerates delivery: Automating the ML lifecycle reduces manual errors and speeds up time-to-market.
Monitoring ensures reliability: Continuous monitoring and alerting help maintain model performance and trust.
Collaboration drives success: Integrating MLOps tools fosters better teamwork between data scientists, engineers, and business stakeholders.
Business impact is measurable: Effective MLOps translates directly into improved KPIs and competitive advantage.
MLOps: Enterprise Practices for Developers
Unlocking the Power of MLOps: A Developer’s Perspective
From Code to Production: The Best MLOps Tools for Developers