

Introduction to MLOps and Containerization
In recent years, the field of machine learning (ML) has rapidly evolved, moving from experimental research to widespread production use across industries. This shift has created new challenges around managing the lifecycle of ML models—from development and training to deployment and monitoring. MLOps, short for Machine Learning Operations, has emerged as a set of practices and tools designed to streamline and automate these processes, ensuring reliable, scalable, and maintainable ML systems.
At its core, MLOps combines principles from software engineering, DevOps, and data science to address the unique complexities of ML workflows. Unlike traditional software, ML models depend heavily on data, require continuous retraining, and often involve complex dependencies. MLOps aims to bridge the gap between data scientists who build models and engineers who deploy and maintain them in production.
Containerization plays a crucial role in enabling effective MLOps. Containers are lightweight, portable units that package an application along with its dependencies and environment, ensuring consistent behavior across different computing environments. Technologies like Docker and Kubernetes have revolutionized how software is developed, tested, and deployed, and their benefits extend naturally to ML workloads.
By containerizing ML models, teams can isolate the model and its runtime environment from the underlying infrastructure, making deployments more predictable and reproducible. Containers also facilitate scalability and resource management, which are essential for handling varying workloads in production.
In summary, the combination of MLOps practices and containerization technologies provides a powerful framework for deploying ML models efficiently and reliably. This foundation enables organizations to accelerate innovation, reduce operational risks, and deliver AI-powered solutions at scale.

Benefits of Using Containers for ML Models
Containerization offers numerous advantages when it comes to deploying machine learning (ML) models in production environments. These benefits address many of the challenges that arise from the complexity and variability of ML workflows.
Portability
Containers encapsulate the ML model along with all its dependencies, libraries, and runtime environment. This means the containerized model can run consistently across different platforms—whether it’s a developer’s laptop, a testing server, or a cloud production cluster—without worrying about environment mismatches.
Scalability
Containers are lightweight and start quickly, making it easy to scale ML models horizontally by running multiple container instances. Orchestration tools like Kubernetes can automatically manage scaling based on demand, ensuring that the model can handle varying workloads efficiently.
Reproducibility
Because containers package the entire environment, they help ensure that the model behaves the same way regardless of where or when it is deployed. This reproducibility is critical for debugging, testing, and compliance, especially in regulated industries.
Isolation
Containers provide process and resource isolation, which means multiple ML models or services can run on the same host without interfering with each other. This isolation improves security and stability by containing faults within individual containers.
Simplified Deployment and Maintenance
With containers, deploying an ML model becomes a matter of running a standardized image, reducing the complexity of installation and configuration. Updates and rollbacks are also easier to manage, as new container versions can replace old ones seamlessly.
Resource Efficiency
Compared to traditional virtual machines, containers use fewer resources because they share the host operating system kernel. This efficiency allows for higher density of ML workloads on the same hardware, optimizing infrastructure costs.
In essence, containerization empowers ML teams to deliver models faster, with greater reliability and flexibility. It forms a key pillar of modern MLOps strategies, enabling smooth transitions from development to production.
Popular Container Technologies in MLOps
In the realm of MLOps, several container technologies have become essential tools for packaging, deploying, and managing machine learning models efficiently. Understanding these technologies helps teams choose the right solutions for their specific needs.
Docker
Docker is the most widely used container platform. It allows developers to create lightweight, portable containers that bundle ML models with all necessary dependencies and runtime environments. Docker images are easy to build, share, and deploy, making Docker the foundation for most containerized ML workflows. Its simplicity and extensive ecosystem have made it the de facto standard for containerization.
Kubernetes
While Docker handles container creation and running individual containers, Kubernetes is a powerful container orchestration system designed to manage large-scale deployments. Kubernetes automates the deployment, scaling, and management of containerized applications, including ML models. It provides features like load balancing, self-healing, rolling updates, and resource scheduling, which are critical for production-grade ML systems that require high availability and scalability.
Other Orchestration Tools
Besides Kubernetes, there are other orchestration platforms such as Docker Swarm and Apache Mesos. However, Kubernetes has become the dominant choice due to its rich feature set and strong community support.
Specialized ML Container Platforms
Some platforms extend container technologies specifically for ML workloads. For example, Kubeflow builds on Kubernetes to provide end-to-end ML pipelines, including training, tuning, and serving models. Similarly, tools like MLflow and Seldon Core integrate with containers to simplify model deployment and lifecycle management.
Container Registries
Container images are stored and distributed via container registries. Popular registries include Docker Hub, Google Container Registry (GCR), and Amazon Elastic Container Registry (ECR). These registries enable version control, access management, and easy sharing of container images across teams and environments.
Preparing ML Models for Containerization
Before deploying machine learning models using containers, it is essential to properly prepare the models and their environments to ensure smooth and reliable operation. This preparation involves several key steps that help package the model along with all necessary components.
Packaging the Model
The first step is to save the trained ML model in a format that can be easily loaded during inference. Common formats include Pickle files for Python models, ONNX for interoperable models, or framework-specific formats like TensorFlow SavedModel or PyTorch’s TorchScript. It’s important to include any preprocessing or postprocessing logic that the model requires.
Defining Dependencies
ML models often rely on specific versions of libraries, frameworks, and system packages. To avoid compatibility issues, all dependencies should be explicitly defined, typically in files like requirements.txt for Python or environment.yml for Conda environments. This ensures that the container image includes the exact software stack needed to run the model.
Creating a Runtime Environment
The container needs a runtime environment that supports the model’s execution. This includes the operating system base image (e.g., Ubuntu, Alpine), language runtimes (e.g., Python), and ML frameworks (e.g., TensorFlow, PyTorch). Choosing a minimal base image helps reduce the container size and attack surface.
Implementing a Serving Interface
To make the model accessible in production, it should be wrapped in a serving application that exposes an API (usually REST or gRPC). Frameworks like FastAPI, Flask, or TensorFlow Serving can be used to build this interface. The serving layer handles incoming requests, runs inference, and returns predictions.
Testing Locally
Before containerizing, it’s crucial to test the model and serving code locally to verify correctness and performance. This step helps catch issues early and ensures that the model behaves as expected.
Writing a Dockerfile
The Dockerfile is a script that defines how to build the container image. It specifies the base image, copies the model and code, installs dependencies, and sets the command to start the serving application. Writing a clear and efficient Dockerfile is key to creating reproducible and maintainable containers.
Best Practices for Containerizing ML Models
Successfully containerizing machine learning models requires following best practices that ensure reliability, maintainability, and scalability in production environments.
Keep Images Lightweight
Use minimal base images and only include necessary dependencies to reduce container size. Smaller images lead to faster builds, quicker deployments, and lower resource consumption.
Version Control Your Containers
Tag container images with meaningful version numbers or commit hashes. This practice enables easy rollback to previous versions and helps track changes over time.
Separate Model and Code
Store the model artifacts separately from the serving code when possible. This separation allows updating models without rebuilding the entire container image, speeding up deployment cycles.
Use Environment Variables
Configure runtime parameters (e.g., model paths, API ports) via environment variables instead of hardcoding them. This approach increases flexibility and makes containers easier to configure across environments.
Implement Health Checks
Add health check endpoints to the serving application so orchestration tools like Kubernetes can monitor container health and restart unhealthy instances automatically.
Log and Monitor
Ensure the containerized service logs important events and metrics. Integrate with monitoring systems to track model performance, latency, and errors in real time.
Secure Your Containers
Follow security best practices such as running containers with non-root users, regularly updating base images, and scanning images for vulnerabilities.
Automate Builds and Deployments
Use CI/CD pipelines to automate container image building, testing, and deployment. Automation reduces human error and accelerates delivery.
Deploying Containers in Production Environments
Deploying containerized machine learning models in production requires strategies that ensure minimal downtime, reliability, and smooth transitions between model versions. Common deployment strategies include rolling updates, blue-green deployments, and canary releases. Each approach helps manage risk and maintain service availability during updates.
Rolling Updates
Rolling updates gradually replace old container instances with new ones. This approach updates a few containers at a time, allowing the system to continue serving requests without interruption. If a problem occurs, the update can be paused or rolled back. Kubernetes supports rolling updates natively, making it a popular choice for ML model deployments.
Blue-Green Deployments
In blue-green deployments, two identical environments (blue and green) run in parallel. The current production environment (blue) serves all traffic, while the new version (green) is deployed and tested. Once verified, traffic is switched from blue to green, minimizing downtime and risk. This method allows quick rollback by switching back to the blue environment if issues arise.
Canary Releases
Canary releases deploy the new model version to a small subset of users or traffic initially. This limited exposure helps detect issues early without impacting all users. If the canary performs well, the deployment gradually expands to more users until full rollout. This strategy is effective for testing model performance and stability in real-world conditions.
Example: Simple Python Script to Trigger a Rolling Update on Kubernetes
Below is a Python example using the Kubernetes Python client to trigger a rolling update by updating the image of a deployment running an ML model.
python
from kubernetes import client, config
def rolling_update_deployment(deployment_name, namespace, new_image):
# Load kubeconfig and initialize API client
config.load_kube_config()
api_instance = client.AppsV1Api()
# Retrieve the current deployment
deployment = api_instance.read_namespaced_deployment(deployment_name, namespace)
# Update the container image
deployment.spec.template.spec.containers[0].image = new_image
# Apply the update
api_response = api_instance.patch_namespaced_deployment(
name=deployment_name,
namespace=namespace,
body=deployment
)
print(f"Deployment '{deployment_name}' updated to image '{new_image}'.")
if __name__ == "__main__":
deployment_name = "ml-model-deployment"
namespace = "default"
new_image = "myregistry/ml-model:2.0"
rolling_update_deployment(deployment_name, namespace, new_image)This script connects to a Kubernetes cluster, fetches the specified deployment, updates the container image to a new version, and triggers a rolling update. It assumes you have access to the cluster and the Kubernetes Python client installed (pip install kubernetes).
Scaling ML Models with Container Orchestration
Scaling machine learning models in production is crucial to handle varying workloads, ensure high availability, and maintain low latency. Container orchestration platforms like Kubernetes provide powerful tools to automate scaling and manage resources efficiently.
Horizontal Scaling
Horizontal scaling involves adding or removing container instances (pods) based on demand. Kubernetes supports this through the Horizontal Pod Autoscaler (HPA), which monitors metrics such as CPU usage, memory, or custom application metrics to automatically adjust the number of pods running the ML model. This ensures the system can handle traffic spikes without manual intervention.
Vertical Scaling
Vertical scaling means increasing the resources (CPU, memory) allocated to individual containers. While Kubernetes allows resource requests and limits to be set, vertical scaling is less dynamic and often requires pod restarts. It is typically used to optimize performance for resource-intensive models.
Load Balancing
Kubernetes services provide built-in load balancing to distribute incoming requests evenly across available pods. This prevents any single instance from becoming a bottleneck and improves fault tolerance.
Multi-Cluster and Hybrid Deployments
For large-scale or geographically distributed applications, Kubernetes supports multi-cluster deployments. This setup can improve latency by serving users from the nearest cluster and increase resilience by isolating failures.
Resource Quotas and Limits
To prevent resource contention, Kubernetes allows setting quotas and limits on CPU and memory usage per namespace or pod. This helps maintain cluster stability and ensures fair resource allocation among different teams or applications.
Using Custom Metrics for Autoscaling
Beyond standard CPU and memory metrics, Kubernetes can autoscale based on custom metrics such as request latency, queue length, or model-specific performance indicators. This fine-tuned scaling helps maintain service quality under diverse conditions.
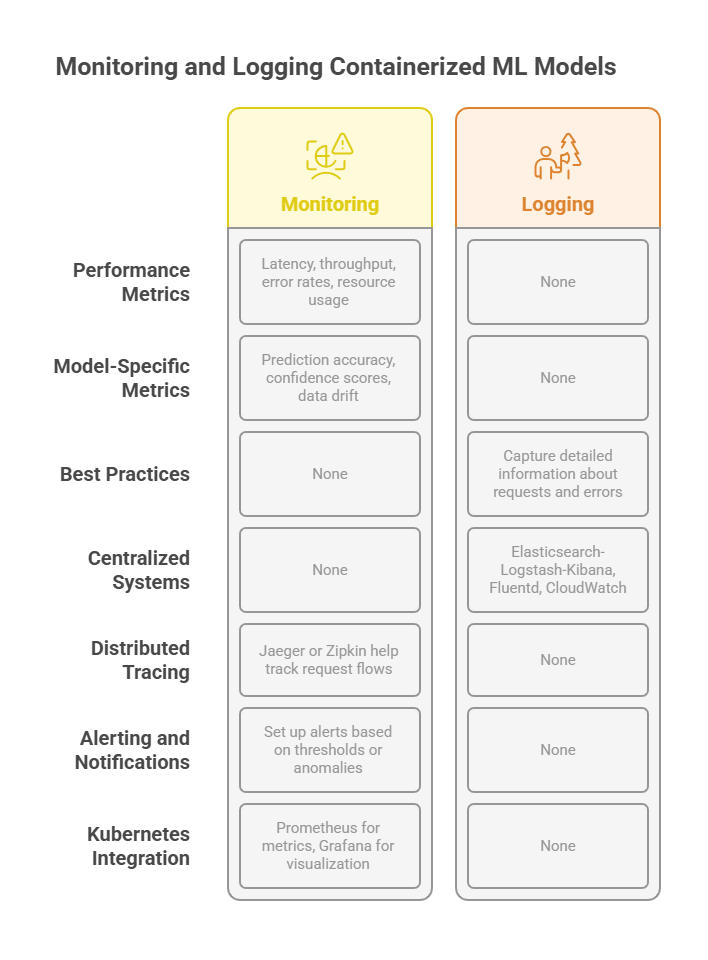
Monitoring and Logging Containerized ML Models
Effective monitoring and logging are essential for maintaining the performance, reliability, and health of containerized machine learning models in production. They help detect issues early, understand model behavior, and support troubleshooting.
Monitoring Performance Metrics
Track key performance indicators such as latency, throughput, error rates, and resource usage (CPU, memory, GPU). Monitoring these metrics helps ensure the model meets service-level objectives and identifies bottlenecks or degradation.
Model-Specific Metrics
Beyond infrastructure metrics, monitor model-specific indicators like prediction accuracy, confidence scores, data drift, and input feature distributions. These metrics provide insights into model quality and help detect when retraining or updates are needed.
Logging Best Practices
Implement structured logging to capture detailed information about requests, responses, errors, and system events. Logs should include timestamps, request IDs, and contextual data to facilitate root cause analysis.
Centralized Logging Systems
Use centralized logging solutions such as Elasticsearch-Logstash-Kibana (ELK), Fluentd, or cloud services like AWS CloudWatch or Google Cloud Logging. Centralization enables efficient searching, filtering, and visualization of logs from multiple containers and services.
Distributed Tracing
For complex ML pipelines involving multiple microservices, distributed tracing tools like Jaeger or Zipkin help track request flows and latency across components, making it easier to pinpoint performance issues.
Alerting and Notifications
Set up alerts based on thresholds or anomaly detection for critical metrics. Automated notifications via email, Slack, or PagerDuty ensure rapid response to incidents.
Integration with Kubernetes
Leverage Kubernetes-native monitoring tools such as Prometheus for metrics collection and Grafana for visualization. These tools integrate well with containerized environments and support custom dashboards tailored to ML workloads.
Security Considerations in Containerized MLOps
Security is a critical aspect of containerized MLOps, encompassing the protection of container images, runtime environments, and sensitive data. Ensuring robust security helps prevent unauthorized access, data breaches, and service disruptions.
Secure Container Images
Use trusted base images from official repositories and regularly update them to patch vulnerabilities. Scan images with tools like Clair, Trivy, or Aqua Security to detect and fix security issues before deployment.
Least Privilege Principle
Run containers with the minimum necessary permissions. Avoid running containers as root and use Kubernetes Pod Security Policies or Open Policy Agent (OPA) to enforce security constraints.
Network Security
Implement network policies to restrict communication between pods and services to only what is necessary. Use service meshes like Istio or Linkerd to enforce secure, encrypted communication and provide fine-grained access control.
Secrets Management
Store sensitive information such as API keys, credentials, and certificates securely using Kubernetes Secrets or external vaults like HashiCorp Vault. Avoid hardcoding secrets in images or code.
Data Privacy and Compliance
Ensure that data used for training and inference complies with privacy regulations (e.g., GDPR, HIPAA). Encrypt data at rest and in transit, and implement access controls to protect sensitive information.
Runtime Security
Monitor container behavior for anomalies using tools like Falco or Sysdig. Detect and respond to suspicious activities such as unexpected process execution or file system changes.
Automated Security Testing
Integrate security checks into CI/CD pipelines to automate vulnerability scanning, compliance checks, and policy enforcement before deployment.
Example: Python Script to Create a Kubernetes Secret for Storing API Keys Securely
python
from kubernetes import client, config
import base64
def create_k8s_secret(secret_name, namespace, data_dict):
# Load kubeconfig and initialize API client
config.load_kube_config()
v1 = client.CoreV1Api()
# Encode data to base64 as required by Kubernetes
encoded_data = {key: base64.b64encode(value.encode()).decode() for key, value in data_dict.items()}
secret = client.V1Secret(
metadata=client.V1ObjectMeta(name=secret_name),
data=encoded_data,
type="Opaque"
)
try:
v1.create_namespaced_secret(namespace=namespace, body=secret)
print(f"Secret '{secret_name}' created in namespace '{namespace}'.")
except client.exceptions.ApiException as e:
if e.status == 409:
print(f"Secret '{secret_name}' already exists.")
else:
print(f"Exception when creating secret: {e}")
if __name__ == "__main__":
secret_name = "ml-api-keys"
namespace = "default"
data = {
"API_KEY": "your_api_key_here",
"ANOTHER_SECRET": "another_secret_value"
}
create_k8s_secret(secret_name, namespace, data)Automating CI/CD Pipelines for Containerized ML Models
Automating Continuous Integration and Continuous Deployment (CI/CD) pipelines is essential for efficient, reliable, and repeatable delivery of containerized machine learning models. CI/CD pipelines help integrate code changes, build container images, run tests, and deploy models to production with minimal manual intervention.
Key Components of CI/CD for ML Models
A typical CI/CD pipeline for containerized ML models includes stages such as code validation, model training or retraining, container image building, automated testing, and deployment to staging or production environments.
Container Image Builds
Automate the building of Docker images whenever model code or dependencies change. Use tools like Dockerfile, BuildKit, or cloud-native build services (e.g., Google Cloud Build, AWS CodeBuild).
Testing and Validation
Incorporate unit tests, integration tests, and model validation tests to ensure code quality and model performance. Automated tests can include data validation, accuracy checks, and performance benchmarks.
Deployment Automation
Use infrastructure-as-code tools (e.g., Helm, Kustomize) and Kubernetes APIs to automate deployment. Pipelines can trigger rolling updates, blue-green deployments, or canary releases based on test results.
Pipeline Orchestration Tools
Popular CI/CD platforms like Jenkins, GitLab CI, GitHub Actions, and Argo CD support containerized ML workflows. They provide integration with container registries, Kubernetes clusters, and monitoring tools.
Versioning and Rollbacks
Maintain version control for code, models, and container images. Automate rollback procedures in case of deployment failures to minimize downtime.
Example: Python Script to Trigger a CI/CD Pipeline via GitHub Actions API
This example demonstrates how to trigger a GitHub Actions workflow that builds and deploys a containerized ML model.
python
import requests
def trigger_github_workflow(owner, repo, workflow_id, github_token, ref="main", inputs=None):
url = f"https://api.github.com/repos/{owner}/{repo}/actions/workflows/{workflow_id}/dispatches"
headers = {
"Authorization": f"token {github_token}",
"Accept": "application/vnd.github.v3+json"
}
data = {
"ref": ref,
"inputs": inputs or {}
}
response = requests.post(url, json=data, headers=headers)
if response.status_code == 204:
print("Workflow triggered successfully.")
else:
print(f"Failed to trigger workflow: {response.status_code} - {response.text}")
if __name__ == "__main__":
owner = "your-github-username"
repo = "your-ml-repo"
workflow_id = "ci-cd-pipeline.yml" # workflow file name or ID
github_token = "your_github_personal_access_token"
ref = "main"
inputs = {
"model_version": "v2.0"
}
trigger_github_workflow(owner, repo, workflow_id, github_token, ref, inputs)This script uses the GitHub API to dispatch a workflow run, which can include building Docker images, running tests, and deploying the ML model.
Case Studies and Best Practices: Real-World Examples of Successful Containerized ML Model Deployments
Containerization has become a cornerstone of modern MLOps, enabling organizations to deploy machine learning models reliably, scalably, and efficiently. Real-world case studies highlight how companies across industries leverage containerized ML deployments to accelerate innovation, improve operational resilience, and deliver business value.
Case Study 1: E-commerce Personalization at Scale
A leading e-commerce platform adopted containerization to deploy hundreds of recommendation models across multiple regions. By packaging models in Docker containers and orchestrating them with Kubernetes, the company achieved consistent environments from development to production. This approach enabled rapid scaling during peak shopping seasons and simplified rollback procedures. Monitoring integrated with container orchestration allowed real-time performance tracking, reducing downtime and improving customer experience.
Case Study 2: Financial Services Fraud Detection
A global bank implemented containerized ML models for fraud detection, using Docker and Kubernetes to manage deployments across hybrid cloud environments. Automated CI/CD pipelines built, tested, and deployed container images, ensuring reproducibility and compliance. The bank leveraged canary deployments to gradually roll out new models, minimizing risk. Centralized logging and monitoring provided visibility into model performance and infrastructure health, enabling proactive incident response.
Case Study 3: Healthcare Predictive Analytics
A healthcare analytics company containerized their patient risk prediction models to meet strict regulatory requirements. Containers encapsulated models along with preprocessing code and dependencies, ensuring consistent execution across on-premises and cloud environments. The company used feature stores and automated retraining pipelines integrated with container orchestration to maintain model accuracy. Explainability tools were embedded in the deployment to support transparency and auditability.
Best Practices from Real-World Deployments
Standardize Container Builds: Use consistent base images and dependency management to ensure portability.
Automate CI/CD: Integrate container builds, testing, and deployments into automated pipelines.
Implement Progressive Deployments: Use rolling updates, blue-green, or canary strategies to reduce risk.
Centralize Monitoring and Logging: Aggregate metrics and logs from containers for comprehensive observability.
Enforce Security and Compliance: Apply access controls, encryption, and audit logging throughout the pipeline.
Foster Cross-Team Collaboration: Align data science, engineering, and operations teams around shared tools and processes.
Feature Stores in Large-Scale ML Systems