

Introduction: Why Cloud Matters for MLOps
In recent years, the adoption of machine learning (ML) has accelerated across industries, driving innovation and transforming business processes. However, deploying and managing ML models at scale presents unique challenges that require robust operational practices—this is where MLOps (Machine Learning Operations) comes into play. MLOps combines principles from DevOps, data engineering, and ML to streamline the entire ML lifecycle, from data preparation and model training to deployment and monitoring.
The cloud has become a critical enabler for effective MLOps. Cloud platforms offer scalable, flexible, and cost-efficient infrastructure that supports the complex workflows and resource demands of machine learning projects. Here are several reasons why the cloud matters for MLOps:
- Scalability and Flexibility
Machine learning workloads can vary dramatically in size and complexity. Training large models or processing massive datasets requires significant compute power, which can be provisioned elastically in the cloud. This flexibility allows teams to scale resources up or down based on demand, avoiding costly overprovisioning or bottlenecks.
- Access to Managed Services and Tools
Leading cloud providers offer a rich ecosystem of managed MLOps tools and services, including data labeling, feature stores, automated model training, deployment platforms, and monitoring solutions. These services reduce the operational burden on teams, accelerate development cycles, and promote best practices.
- Collaboration and Reproducibility
Cloud environments facilitate collaboration among data scientists, engineers, and business stakeholders by providing centralized repositories for code, data, and models. Version control, experiment tracking, and shared pipelines improve reproducibility and transparency, which are essential for reliable ML systems.
- Integration with Enterprise Systems
Many organizations already rely on cloud infrastructure for their IT needs. Integrating MLOps workflows with existing cloud-based data lakes, databases, and applications simplifies data access and operational workflows, enabling seamless end-to-end ML solutions.
- Cost Efficiency
Cloud platforms offer pay-as-you-go pricing models, allowing organizations to optimize costs by paying only for the resources they use. This is particularly beneficial for ML projects, where resource needs can be unpredictable and bursty.
- Security and Compliance
Cloud providers invest heavily in security, compliance certifications, and governance tools. Leveraging these capabilities helps organizations protect sensitive data, meet regulatory requirements, and implement robust access controls within their MLOps pipelines.
- Innovation and Future-Proofing
Cloud platforms continuously innovate, introducing new AI and ML capabilities such as AutoML, explainability tools, and edge deployment options. Using cloud-based MLOps ensures access to the latest technologies without heavy upfront investments.
Key Cloud Providers for MLOps
When it comes to implementing MLOps in the cloud, choosing the right cloud provider is a critical decision that can significantly impact the efficiency, scalability, and cost-effectiveness of your machine learning workflows. The three major cloud providers—Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP)—offer comprehensive MLOps ecosystems with a wide range of tools and services designed to support every stage of the ML lifecycle. Below is an overview of these key players and what they bring to the table for MLOps practitioners.
- Amazon Web Services (AWS)
AWS is one of the most mature and widely adopted cloud platforms, offering a rich set of services tailored for machine learning and MLOps:
Amazon SageMaker: A fully managed service that covers the entire ML lifecycle, including data labeling, model building, training, tuning, deployment, and monitoring. SageMaker provides built-in algorithms, AutoML capabilities, and integration with popular frameworks like TensorFlow and PyTorch.
SageMaker Pipelines: Enables building, automating, and managing end-to-end ML workflows with CI/CD capabilities.
Amazon S3: Scalable object storage for datasets and model artifacts.
AWS Lambda and Step Functions: Serverless compute and orchestration services to automate ML workflows.
Amazon CloudWatch: Monitoring and alerting for deployed models and infrastructure.
Security and Compliance: AWS offers extensive security features, including IAM roles, encryption, and compliance certifications (e.g., HIPAA, GDPR).
AWS’s broad ecosystem and global infrastructure make it a strong choice for enterprises needing scalable and secure MLOps solutions.
Microsoft Azure
Azure provides a robust platform for MLOps with deep integration into enterprise environments, especially for organizations already using Microsoft products:
Azure Machine Learning (Azure ML): A cloud service for building, training, and deploying ML models. Azure ML supports automated ML, drag-and-drop pipelines, and integration with popular ML frameworks.
Azure DevOps: Provides CI/CD pipelines that can be integrated with Azure ML for automated model deployment and testing.
Azure Data Lake and Blob Storage: Scalable storage solutions for large datasets.
Azure Monitor: Comprehensive monitoring and diagnostics for ML models and infrastructure.
Security and Compliance: Azure emphasizes enterprise-grade security, identity management, and compliance with standards like ISO, SOC, and GDPR.
Integration with Microsoft Ecosystem: Seamless connectivity with tools like Power BI, Azure Synapse Analytics, and Microsoft 365.
Azure is particularly appealing for organizations invested in the Microsoft ecosystem seeking integrated MLOps capabilities.
Google Cloud Platform (GCP)
GCP is known for its strong AI and data analytics capabilities, making it a popular choice for data-driven MLOps:
Vertex AI: Google’s unified ML platform that simplifies building, deploying, and scaling ML models. It offers AutoML, custom training, feature stores, and model monitoring.
BigQuery: A serverless, highly scalable data warehouse ideal for large-scale data analytics and feature engineering.
Cloud Storage: Durable and scalable object storage for datasets and models.
Cloud Functions and Cloud Run: Serverless compute options for deploying ML inference and orchestrating workflows.
Cloud Monitoring and Logging: Tools for tracking model performance and operational metrics.
Security and Compliance: GCP provides strong security controls, encryption, and compliance certifications such as FedRAMP and HIPAA.
Open Source and AI Research Leadership: GCP integrates well with TensorFlow and other open-source ML tools, benefiting from Google’s AI research advancements.
GCP’s focus on AI innovation and data analytics makes it a compelling platform for organizations prioritizing cutting-edge ML capabilities.
Other Cloud Providers and Hybrid Solutions
While AWS, Azure, and GCP dominate the market, other providers and hybrid cloud solutions also play a role in MLOps:
IBM Cloud: Offers Watson Studio and other AI services with a focus on enterprise AI and hybrid cloud deployments.
Oracle Cloud: Provides AI and ML services integrated with Oracle’s database and enterprise applications.
Hybrid and Multi-Cloud: Tools like Kubeflow and MLflow enable MLOps workflows that can run across multiple cloud providers or on-premises infrastructure, offering flexibility and avoiding vendor lock-in.
Building Scalable ML Pipelines in the Cloud
Building scalable machine learning (ML) pipelines is a cornerstone of successful MLOps, especially when leveraging cloud infrastructure. Scalable pipelines enable organizations to handle growing data volumes, increasing model complexity, and more frequent updates without sacrificing reliability or performance. The cloud offers unique advantages for designing and automating these pipelines, providing elasticity, managed services, and integration capabilities that simplify the ML lifecycle.
What Is an ML Pipeline?
An ML pipeline is a sequence of automated steps that process raw data into actionable machine learning models. Typical stages include data ingestion, preprocessing, feature engineering, model training, evaluation, deployment, and monitoring. Automating these steps ensures consistency, reproducibility, and faster iteration cycles.
Why Scalability Matters
As organizations scale their ML efforts, pipelines must handle:
Large and Growing Datasets: Data volumes can increase rapidly, requiring pipelines to process data efficiently without bottlenecks.
Multiple Models and Experiments: Teams often train many models in parallel, necessitating resource management and orchestration.
Frequent Retraining: Models may need regular updates to maintain accuracy, demanding automated retraining workflows.
Real-Time or Near-Real-Time Processing: Some applications require low-latency predictions, influencing pipeline design.
Scalable pipelines ensure that these demands are met without manual intervention or system failures.
Key Strategies for Building Scalable ML Pipelines in the Cloud
Leverage Cloud-Native Services
Use managed services for data storage (e.g., Amazon S3, Azure Blob Storage, Google Cloud Storage), compute (e.g., AWS SageMaker, Azure ML, Google Vertex AI), and orchestration (e.g., AWS Step Functions, Azure Data Factory, Google Cloud Composer). These services automatically scale and reduce operational overhead.
Modular and Reusable Components
Design pipelines as modular components or microservices that can be independently developed, tested, and reused. This approach improves maintainability and allows teams to update parts of the pipeline without disrupting the whole system.
Automate Orchestration and Scheduling
Use workflow orchestration tools like Apache Airflow, Kubeflow Pipelines, or cloud-native schedulers to automate task execution, handle dependencies, and retry failed steps. Automation ensures pipelines run reliably and on schedule.
Implement Parallelism and Distributed Computing
Exploit parallel processing for data preprocessing and model training using distributed frameworks like Apache Spark or cloud-managed ML training clusters. Parallelism accelerates pipeline execution and handles large-scale workloads.
Use Feature Stores for Consistency
Centralize feature storage and management with feature stores (e.g., Feast, AWS SageMaker Feature Store) to ensure consistent feature computation across training and serving environments, improving model reliability.
Incorporate Continuous Integration and Continuous Deployment (CI/CD)
Integrate CI/CD practices to automate testing, validation, and deployment of models and pipeline code. Tools like Jenkins, GitHub Actions, or cloud-native CI/CD services help maintain quality and accelerate delivery.
Monitor and Log Pipeline Performance
Implement monitoring for pipeline health, data quality, and model performance using tools like Prometheus, Grafana, or cloud monitoring services. Early detection of issues prevents pipeline failures and model degradation.
Optimize for Cost and Resource Efficiency
Use autoscaling, spot instances, and resource tagging to optimize cloud costs. Monitor resource usage and adjust pipeline configurations to balance performance and budget.
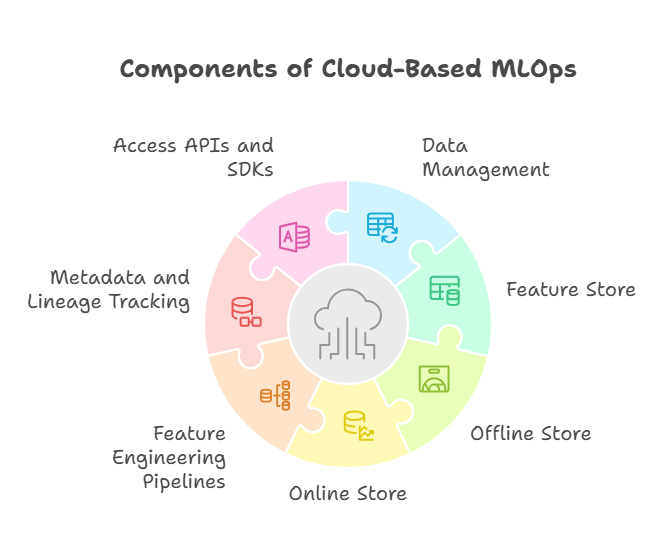
Data Management and Feature Stores in Cloud MLOps
Effective data management is fundamental to successful machine learning operations (MLOps), especially in cloud environments where data volumes and complexity can grow rapidly. Feature stores have emerged as a critical component in modern MLOps architectures, providing a centralized platform to manage, store, and serve features consistently across training and inference workflows. This article explores the role of data management and feature stores in cloud-based MLOps, highlighting their importance, key components, and best practices.
The Importance of Data Management in MLOps
Data is the foundation of any machine learning model. Managing data effectively involves:
Data Ingestion and Storage: Collecting raw data from various sources and storing it securely and scalably in cloud storage solutions such as Amazon S3, Azure Blob Storage, or Google Cloud Storage.
Data Versioning: Keeping track of different versions of datasets to ensure reproducibility and auditability.
Data Quality and Validation: Implementing checks to detect anomalies, missing values, or inconsistencies that could degrade model performance.
Data Access and Governance: Controlling who can access data and ensuring compliance with privacy regulations like GDPR or HIPAA.
Cloud platforms provide scalable and secure infrastructure to handle these data management tasks, enabling teams to focus on building and deploying models.
What Is a Feature Store?
A feature store is a centralized system that manages the lifecycle of features used in machine learning models. It acts as a bridge between raw data and ML models by providing:
Feature Engineering and Transformation: Tools to create, compute, and transform raw data into meaningful features.
Feature Storage: A repository to store features in a consistent, versioned, and accessible manner.
Feature Serving: APIs or services to serve features in real-time or batch mode for model training and inference.
Feature Monitoring: Tracking feature distributions and detecting drift or anomalies over time.
By centralizing feature management, feature stores help ensure consistency between training and serving environments, reduce duplication of work, and improve collaboration across teams.
Key Components of Cloud-Based Feature Stores
Offline Store
Stores historical feature data used for training models. Typically implemented using cloud data warehouses or data lakes such as Amazon Redshift, Google BigQuery, or Azure Synapse.
Online Store
Provides low-latency access to features for real-time model inference. Often built on fast key-value stores like Amazon DynamoDB, Google Cloud Bigtable, or Azure Cosmos DB.
Feature Engineering Pipelines
Automated workflows that compute and update features regularly, using tools like Apache Spark, AWS Glue, or cloud-native data processing services.
Metadata and Lineage Tracking
Keeps records of feature definitions, versions, and data lineage to support governance and reproducibility.
Access APIs and SDKs
Interfaces that allow data scientists and applications to retrieve features seamlessly during training and serving.
Popular Cloud Feature Store Solutions
AWS SageMaker Feature Store: Fully managed feature store integrated with SageMaker, supporting both online and offline feature storage.
Google Cloud Vertex AI Feature Store: Provides centralized feature management with integration into Vertex AI pipelines.
Feast (Open Source): A popular open-source feature store that can be deployed on various cloud platforms, offering flexibility and extensibility.
Azure Feature Store (Preview): Microsoft’s feature store solution integrated with Azure ML for feature management.
Best Practices for Data Management and Feature Stores in Cloud MLOps
Ensure Consistency: Use the same feature definitions and transformations for both training and inference to avoid training-serving skew.
Automate Feature Pipelines: Schedule regular updates and validations of features to keep models accurate and up-to-date.
Monitor Feature Drift: Continuously track feature distributions to detect changes that may impact model performance.
Implement Access Controls: Secure sensitive data and features with role-based access and encryption.
Version Features and Data: Maintain versioning to support reproducibility and rollback if needed.
Collaborate Across Teams: Use shared repositories and documentation to align data scientists, engineers, and business stakeholders.
Model Deployment and Serving in the Cloud
Model deployment and serving are critical stages in the machine learning lifecycle, where trained models are made available to end-users or applications for inference. In cloud-based MLOps, deploying and serving models efficiently, reliably, and at scale is essential to deliver real-time or batch predictions that power business decisions and user experiences. This article explores common approaches, tools, and best practices for model deployment and serving in the cloud.
Why Cloud for Model Deployment?
Cloud platforms provide flexible, scalable infrastructure and managed services that simplify deploying ML models. Key benefits include:
Elastic Scalability: Automatically scale resources up or down based on traffic and workload.
Managed Infrastructure: Reduce operational overhead by using serverless or containerized services.
Global Availability: Deploy models close to users with multi-region support.
Integration: Seamlessly connect with data sources, monitoring, and CI/CD pipelines.
Security and Compliance: Leverage built-in security features and compliance certifications.
Common Deployment Approaches
Serverless Model Serving
Serverless platforms (e.g., AWS Lambda, Azure Functions, Google Cloud Functions) allow deploying lightweight models or inference functions without managing servers. They offer automatic scaling and cost efficiency but may have limitations on execution time and resource size.
Containerized Deployment
Packaging models in containers (e.g., Docker) enables consistent environments and portability. Containers can be deployed on managed Kubernetes services like Amazon EKS, Azure AKS, or Google GKE, providing fine-grained control over scaling, networking, and resource allocation.
Managed Model Serving Services
Cloud providers offer specialized services for model deployment and serving, such as:
Amazon SageMaker Endpoints: Fully managed, scalable endpoints for real-time inference.
Azure ML Online Endpoints: Managed services for deploying models with autoscaling and versioning.
Google Vertex AI Prediction: Supports online and batch predictions with autoscaling and monitoring.
Batch Inference Pipelines
For use cases where real-time predictions are not required, batch inference processes run predictions on large datasets periodically. Cloud services like AWS Batch, Azure Data Factory, or Google Cloud Dataflow can orchestrate these workflows.
Key Considerations for Cloud Model Deployment
Latency Requirements: Real-time applications need low-latency serving, favoring managed endpoints or serverless functions.
Throughput and Scalability: High-traffic scenarios require autoscaling and load balancing.
Model Versioning and Rollbacks: Support multiple model versions and enable safe rollbacks to previous versions.
A/B Testing and Canary Deployments: Gradually roll out new models to subsets of users to monitor performance before full deployment.
Monitoring and Logging: Track prediction accuracy, latency, errors, and resource usage to detect issues early.
Security: Protect models and data with authentication, encryption, and network controls.
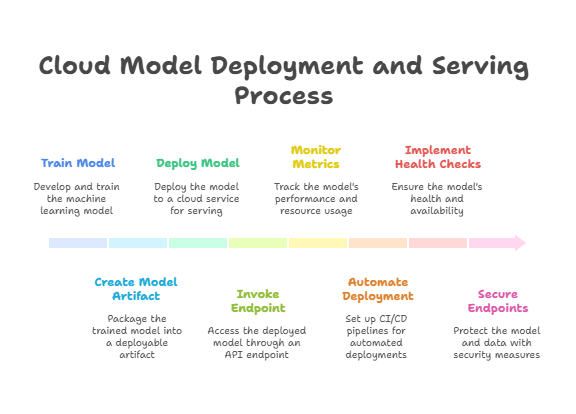
Example: Deploying a Model with Amazon SageMaker
Train the model using SageMaker training jobs.
Create a model artifact stored in Amazon S3.
Deploy the model to a SageMaker endpoint with autoscaling enabled.
Invoke the endpoint via REST API for real-time predictions.
Monitor endpoint metrics using Amazon CloudWatch.
Best Practices for Cloud Model Serving
Automate deployment with CI/CD pipelines to ensure repeatability and reduce errors.
Use containerization to maintain consistent environments across development and production.
Implement health checks and auto-recovery mechanisms to maintain high availability.
Secure endpoints with API gateways, authentication, and encryption.
Continuously monitor model performance and resource utilization.
Plan for cost optimization by selecting appropriate instance types and scaling policies.
Monitoring, Logging, and Alerting for Cloud MLOps
Monitoring, logging, and alerting are essential components of a robust MLOps strategy, especially in cloud environments where machine learning models operate at scale and impact critical business processes. Effective monitoring ensures that models continue to perform as expected after deployment, while logging and alerting enable rapid detection and response to issues such as data drift, model degradation, or infrastructure failures. This article explores best practices, tools, and strategies for implementing comprehensive monitoring, logging, and alerting in cloud-based MLOps.
Why Monitoring Matters in MLOps
Machine learning models are not static; their performance can degrade over time due to changes in data distributions, evolving user behavior, or system issues. Without proper monitoring, these problems may go unnoticed, leading to inaccurate predictions, poor user experiences, and business risks. Monitoring helps to:
Track model accuracy and other performance metrics in production.
Detect data drift and concept drift that affect model reliability.
Identify infrastructure bottlenecks or failures impacting availability.
Ensure compliance with regulatory requirements through audit trails.
Provide insights for continuous improvement and retraining.
Key Aspects of Monitoring in Cloud MLOps
Model Performance Monitoring
Track metrics such as accuracy, precision, recall, F1 score, and prediction distributions. Compare real-time predictions against ground truth when available or use proxy metrics when labels are delayed.
Data Drift Detection
Monitor input data features for statistical changes over time using techniques like population stability index (PSI), Kolmogorov-Smirnov tests, or embedding-based methods.
Infrastructure and Resource Monitoring
Observe CPU, GPU, memory usage, latency, throughput, and error rates to ensure the serving environment is healthy and performant.
Logging
Collect detailed logs of prediction requests, responses, errors, and system events. Logs support debugging, auditing, and compliance.
Alerting and Incident Management
Set thresholds and triggers for key metrics to automatically notify teams of anomalies or failures via email, SMS, or integration with incident management tools like PagerDuty or Opsgenie.
Cloud Tools for Monitoring, Logging, and Alerting
Amazon CloudWatch: Provides metrics, logs, and alarms for AWS resources and SageMaker endpoints.
Azure Monitor: Offers comprehensive monitoring and diagnostics for Azure ML and related services.
Google Cloud Monitoring and Logging: Integrated tools for tracking model and infrastructure health on GCP.
Open-Source Tools: Prometheus for metrics collection, Grafana for visualization, ELK Stack (Elasticsearch, Logstash, Kibana) for log management.
Specialized ML Monitoring Platforms: Evidently AI, Fiddler AI, Arize AI, and WhyLabs provide advanced capabilities for drift detection, explainability, and fairness monitoring.
Best Practices for Effective Monitoring in Cloud MLOps
Define Clear Metrics and KPIs: Establish which metrics matter most for your use case and business goals.
Automate Data and Model Validation: Integrate validation checks into pipelines to catch issues early.
Implement Real-Time and Batch Monitoring: Combine immediate alerts with periodic in-depth analysis.
Use Baselines and Thresholds: Set baselines for normal behavior and thresholds for alerts based on historical data.
Ensure Data Privacy and Security: Protect sensitive data in logs and monitoring systems.
Integrate Monitoring with CI/CD Pipelines: Use monitoring feedback to trigger retraining or rollback workflows.
Foster Cross-Team Collaboration: Share monitoring dashboards and alerts with data scientists, engineers, and business stakeholders.
Security and Compliance in Cloud MLOps
Security and compliance are critical considerations in cloud-based MLOps, as machine learning models often handle sensitive data and support business-critical applications. Ensuring that MLOps pipelines and deployed models adhere to security best practices and regulatory requirements protects organizations from data breaches, legal risks, and reputational damage. This article explores key security challenges, compliance frameworks, and strategies for building secure and compliant MLOps workflows in the cloud.
Why Security and Compliance Matter in MLOps
Machine learning systems introduce unique security risks, including data privacy concerns, model theft or tampering, and vulnerabilities in automated pipelines. Additionally, many industries are subject to regulations such as GDPR, HIPAA, or CCPA that mandate strict controls over data handling and processing. Failure to address these issues can lead to costly fines, loss of customer trust, and operational disruptions.
Key Security Challenges in Cloud MLOps
Data Privacy and Protection
ML workflows often involve sensitive personal or proprietary data. Protecting this data at rest, in transit, and during processing is essential.
Access Control and Identity Management
Controlling who can access data, models, and infrastructure reduces the risk of unauthorized actions or insider threats.
Model Security
Models themselves can be targets for theft, reverse engineering, or adversarial attacks that manipulate predictions.
Pipeline Integrity
Automated pipelines must be safeguarded against tampering or injection of malicious code or data.
Auditability and Traceability
Maintaining detailed logs and metadata supports compliance audits and forensic investigations.
Compliance Frameworks Relevant to MLOps
General Data Protection Regulation (GDPR): Governs data privacy and protection for EU citizens.
Health Insurance Portability and Accountability Act (HIPAA): Regulates healthcare data security in the US.
California Consumer Privacy Act (CCPA): Protects consumer data privacy in California.
Federal Risk and Authorization Management Program (FedRAMP): US government cloud security standards.
ISO/IEC 27001: International standard for information security management.
Best Practices for Security and Compliance in Cloud MLOps
Data Encryption
Encrypt data at rest using cloud provider services (e.g., AWS KMS, Azure Key Vault, Google Cloud KMS) and enforce encryption in transit with TLS.
Role-Based Access Control (RBAC)
Implement fine-grained access policies using IAM roles and policies to restrict permissions to the minimum necessary.
Secure Development and Deployment
Use secure coding practices, scan for vulnerabilities, and automate security testing in CI/CD pipelines.
Model Protection Techniques
Apply techniques such as model watermarking, encryption, and access logging to safeguard models.
Monitoring and Incident Response
Continuously monitor for suspicious activities and establish incident response plans.
Data Anonymization and Minimization
Use techniques like data masking, tokenization, or synthetic data to reduce exposure of sensitive information.
Audit Logging and Documentation
Maintain comprehensive logs of data access, model changes, and pipeline executions to support audits.
Compliance Automation
Leverage cloud compliance tools and frameworks to automate policy enforcement and reporting.
Cloud Provider Security Features for MLOps
AWS: Identity and Access Management (IAM), Virtual Private Cloud (VPC), CloudTrail for auditing, and compliance certifications.
Azure: Azure Active Directory, Security Center, Policy Compliance, and extensive regulatory compliance.
Google Cloud: Cloud IAM, VPC Service Controls, Security Command Center, and compliance attestations.
Future Trends in Cloud MLOps
As machine learning operations (MLOps) continue to evolve, the cloud remains a central enabler of innovation, scalability, and efficiency. Looking ahead, several emerging trends are shaping the future of cloud-based MLOps, promising to transform how organizations develop, deploy, and maintain machine learning models. This article explores key future trends that practitioners and organizations should watch to stay ahead in the rapidly changing MLOps landscape.
- Increased Automation with AI-Driven MLOps
Automation will deepen beyond pipeline orchestration to include AI-powered tools that optimize model development, deployment, and monitoring. Automated feature engineering, hyperparameter tuning, and anomaly detection will reduce manual effort and accelerate time-to-market. AI-driven monitoring systems will proactively identify model drift, bias, and performance degradation, enabling self-healing ML systems.
- Unified Observability and Explainability
Future MLOps platforms will integrate observability tools that provide a holistic view of model health, data quality, infrastructure, and user impact. Explainability and interpretability features will be embedded into monitoring dashboards, helping teams understand model decisions and comply with regulatory requirements. This unified approach will improve trust and transparency in AI systems.
- Edge and Hybrid Cloud MLOps
With the rise of IoT and real-time applications, deploying and managing models at the edge will become more prevalent. Hybrid cloud architectures will enable seamless workflows across on-premises, edge, and cloud environments, balancing latency, privacy, and compute needs. MLOps tools will evolve to support distributed training, deployment, and monitoring across diverse infrastructures.
- Feature Store Evolution and Data-Centric AI
Feature stores will become more intelligent and integrated, supporting real-time feature computation, automated feature validation, and governance. The shift toward data-centric AI emphasizes improving data quality and feature engineering as key drivers of model performance. MLOps platforms will provide enhanced tools for data versioning, lineage tracking, and bias detection.
- Security and Compliance Automation
As regulatory scrutiny intensifies, MLOps will incorporate automated compliance checks, privacy-preserving techniques (e.g., differential privacy, federated learning), and robust security frameworks. Continuous auditing and policy enforcement will be standard features, helping organizations manage risk without slowing innovation.
- Low-Code and No-Code MLOps
To democratize AI, low-code and no-code MLOps platforms will gain traction, enabling business users and citizen data scientists to build, deploy, and monitor models with minimal coding. These platforms will integrate with cloud services to provide scalable, governed ML workflows accessible to a broader audience.
- Sustainability and Green AI
Environmental concerns will drive MLOps practices focused on energy-efficient model training and deployment. Cloud providers and organizations will adopt strategies to minimize carbon footprints, such as optimizing resource usage, leveraging renewable energy-powered data centers, and developing lightweight models.
- Integration with Generative AI and Foundation Models
The rise of large foundation models and generative AI will influence MLOps by introducing new challenges and opportunities in model management, fine-tuning, and deployment. MLOps tools will adapt to handle massive models, support multi-modal data, and enable rapid experimentation with pre-trained models.
Future Trends in Model Monitoring
Model monitoring is a rapidly evolving field within MLOps, driven by the increasing complexity of machine learning systems and the growing demand for reliable, fair, and explainable AI. As organizations deploy more models in production, new trends are shaping how monitoring is performed to ensure models remain accurate, trustworthy, and compliant. This article explores key future trends in model monitoring that will define the landscape in the coming years.
- AI-Powered Monitoring and Anomaly Detection
Future monitoring systems will increasingly leverage machine learning and AI techniques themselves to detect subtle patterns of data drift, concept drift, and performance degradation. These intelligent systems will go beyond simple threshold-based alerts to identify complex anomalies and predict potential failures before they impact business outcomes.
- Integration of Explainability and Fairness Monitoring
With rising regulatory scrutiny and ethical concerns, monitoring will extend to include explainability and fairness metrics. Tools will provide real-time insights into model decisions, highlighting biases or unfair treatment of subgroups. This integration will help organizations maintain compliance and build trust with users and stakeholders.
- Unified Observability Platforms
Model monitoring will become part of broader observability platforms that combine metrics from data pipelines, infrastructure, application performance, and business KPIs. This holistic view enables teams to correlate model behavior with system health and user impact, facilitating faster root cause analysis and remediation.
- Real-Time and Continuous Monitoring
The demand for immediate detection of issues will drive adoption of real-time monitoring solutions that analyze streaming data and predictions continuously. Continuous monitoring pipelines will enable rapid feedback loops, supporting automated retraining and deployment to maintain model accuracy.
- Automated Remediation and Self-Healing Models
Advances in automation will enable monitoring systems to trigger automated responses such as alerting, model rollback, or retraining without human intervention. Self-healing models will adapt dynamically to changing data distributions, reducing downtime and manual maintenance.
- Privacy-Preserving Monitoring
As privacy regulations tighten, monitoring solutions will incorporate privacy-preserving techniques like federated monitoring and differential privacy to analyze model performance without exposing sensitive data.
- Standardization and Interoperability
The ecosystem of monitoring tools will move toward standardization of metrics, APIs, and data formats, enabling interoperability between platforms and easier integration into existing MLOps workflows.
Conclusion: Building a Robust Monitoring Framework for 2025
As machine learning models become increasingly integral to business operations, building a robust monitoring framework is essential to ensure their continued accuracy, reliability, and fairness. The year 2025 brings new challenges and opportunities in model monitoring, driven by advances in AI, regulatory demands, and the growing complexity of ML systems. This conclusion summarizes key principles and best practices for establishing an effective monitoring framework that supports responsible and scalable AI deployment.
Comprehensive Monitoring Beyond Accuracy
A modern monitoring framework must go beyond tracking traditional performance metrics like accuracy or error rates. It should include:
Data Drift Detection: Continuously monitor input data distributions to identify shifts that may degrade model performance.
Model Drift and Degradation: Track changes in model predictions and outcomes over time.
Fairness and Bias Checks: Ensure models treat all user groups equitably and comply with ethical standards.
Operational Health: Monitor infrastructure metrics such as latency, throughput, and error rates to maintain service quality.
Seamless Integration with MLOps Pipelines
Monitoring should be an integral part of the MLOps lifecycle, tightly integrated with data pipelines, model training, deployment, and retraining workflows. Automated alerts and feedback loops enable rapid response to detected issues, minimizing downtime and performance degradation.
Automation and Intelligence
Leveraging AI-driven monitoring tools that can detect complex anomalies, predict failures, and trigger automated remediation will be critical. Self-healing systems that adapt to changing conditions reduce manual intervention and improve resilience.
Governance, Compliance, and Transparency
A robust framework must support auditability, explainability, and compliance with evolving regulations. Maintaining detailed logs, metadata, and documentation ensures transparency and accountability in AI systems.
Collaboration and Culture
Successful monitoring requires collaboration across data scientists, engineers, operations teams, and business stakeholders. Shared dashboards, clear communication channels, and aligned objectives foster a culture of continuous improvement and responsible AI use.
Final Thoughts
Building a robust monitoring framework in 2025 is not just a technical necessity but a strategic imperative. It safeguards the value of machine learning investments, protects users and organizations from risks, and enables AI systems to deliver sustained business impact. By embracing comprehensive, automated, and integrated monitoring practices, organizations can confidently scale their AI initiatives and navigate the complexities of modern machine learning operations.
Future Directions in MLOps
As machine learning continues to transform industries, MLOps—the practice of managing the end-to-end lifecycle of ML models—must evolve to meet new demands and challenges. Looking forward, several key directions will shape the future of MLOps, enabling organizations to build more scalable, reliable, and responsible AI systems. This article explores these emerging trends and innovations that will define the next generation of MLOps.
- Increased Automation and AI-Driven MLOps
Automation will deepen across the ML lifecycle, from data preprocessing and feature engineering to model training, deployment, and monitoring. AI-powered tools will assist in hyperparameter tuning, anomaly detection, and automated retraining, reducing manual effort and accelerating development cycles.
- End-to-End Integration and Unified Platforms
Future MLOps platforms will offer seamless integration of all components—data, code, models, infrastructure, and monitoring—into unified environments. This integration will improve collaboration, reduce friction, and enable consistent governance across teams and projects.
- Focus on Model Governance and Compliance
As regulatory requirements around AI ethics, fairness, and transparency grow, MLOps will incorporate stronger governance frameworks. This includes automated compliance checks, audit trails, explainability tools, and bias detection integrated into pipelines.
- Support for Foundation Models and Large-Scale AI
The rise of large foundation models and generative AI will require MLOps tools to handle massive models, distributed training, and fine-tuning workflows. Managing these complex models at scale will be a key focus area.
- Hybrid and Edge MLOps
With increasing deployment of ML models on edge devices and hybrid cloud environments, MLOps will evolve to support distributed training, deployment, and monitoring across diverse infrastructures, balancing latency, privacy, and resource constraints.
- Data-Centric MLOps
The shift toward data-centric AI emphasizes improving data quality, feature management, and data versioning as critical to model success. MLOps will provide enhanced tools for data validation, lineage tracking, and feature store integration.
- Sustainability and Green AI
Environmental concerns will drive MLOps practices focused on energy-efficient model training and deployment. Optimizing resource usage and leveraging renewable energy sources will become standard considerations.
- Democratization of MLOps
Low-code and no-code MLOps platforms will empower a broader range of users, including citizen data scientists and business analysts, to participate in ML workflows, accelerating AI adoption across organizations.
Conclusion
The future of MLOps is poised for greater automation, integration, and inclusivity, enabling organizations to build AI systems that are scalable, trustworthy, and aligned with business goals. Staying abreast of these trends and adopting flexible, forward-looking MLOps practices will be essential for success in the evolving AI landscape.
Conclusion: The Importance of MLOps in Realizing Business Value from Data Science Initiatives
As organizations increasingly rely on machine learning to drive innovation and competitive advantage, MLOps has emerged as a critical discipline for turning data science efforts into tangible business outcomes. This concluding article summarizes why MLOps is essential for maximizing the value of machine learning projects and outlines best practices for embedding MLOps into organizational workflows.
Bridging the Gap Between Data Science and Production
MLOps addresses the challenges of moving models from experimentation to production by providing standardized processes, automation, and collaboration tools. This bridge ensures that models are not only developed effectively but also deployed, monitored, and maintained reliably to deliver consistent results.
Ensuring Scalability and Reliability
By automating repetitive tasks such as data validation, model training, deployment, and monitoring, MLOps enables organizations to scale their machine learning initiatives without sacrificing quality. Reliable pipelines reduce errors, minimize downtime, and accelerate time-to-market.
Enhancing Collaboration Across Teams
MLOps fosters collaboration between data scientists, engineers, operations, and business stakeholders through shared tools, version control, and clear workflows. This alignment ensures that machine learning solutions meet business requirements and adapt to changing needs.
Supporting Compliance and Governance
With growing regulatory and ethical considerations around AI, MLOps frameworks incorporate governance mechanisms such as audit trails, explainability, and bias detection. These features help organizations build trustworthy AI systems that comply with legal and societal expectations.
Driving Continuous Improvement and Innovation
MLOps enables continuous integration and continuous delivery (CI/CD) for machine learning, allowing teams to iterate rapidly, incorporate feedback, and improve models over time. This agility is key to maintaining competitive advantage in dynamic markets.
Final Thoughts
MLOps is not just a technical practice but a strategic enabler that transforms data science from isolated experiments into scalable, reliable, and impactful business solutions. Organizations that invest in robust MLOps capabilities position themselves to fully realize the promise of AI and sustain long-term value from their data science initiatives.
MLOps for Experts: Workflow Optimization
MLOps: Enterprise Practices for Developers
MLOps in Practice: Automation and Scaling of the Machine Learning Lifecycle