

Introduction: Why Model Registry Matters in MLOps
In the world of modern machine learning operations (MLOps), a model registry is no longer a luxury—it’s a necessity. As organizations scale their AI initiatives, the number of models, experiments, and deployment environments grows rapidly. Without a centralized system to track, manage, and govern these models, teams risk confusion, duplication, and costly errors.
A model registry acts as the single source of truth for all machine learning models within an organization. It provides a structured way to store, version, and manage models throughout their entire lifecycle—from initial experimentation and validation, through staging and production, to eventual retirement or rollback. This centralization is crucial for ensuring reproducibility, traceability, and compliance, especially in regulated industries.
Why does this matter? In practice, teams often work on multiple versions of the same model, experiment with different algorithms, or retrain models as new data arrives. Without a registry, it’s easy to lose track of which model version is deployed, which data and code were used, or how a model performed in production. This can lead to inconsistent results, difficulties in debugging, and challenges in meeting audit or compliance requirements.
A robust model registry also streamlines collaboration between data scientists, ML engineers, and DevOps teams. It enables automated CI/CD workflows, supports model promotion and rollback, and integrates with monitoring and alerting systems. By making model management transparent and auditable, a model registry accelerates the path from research to reliable, production-ready AI.
Core Concepts: What Is a Model Registry?
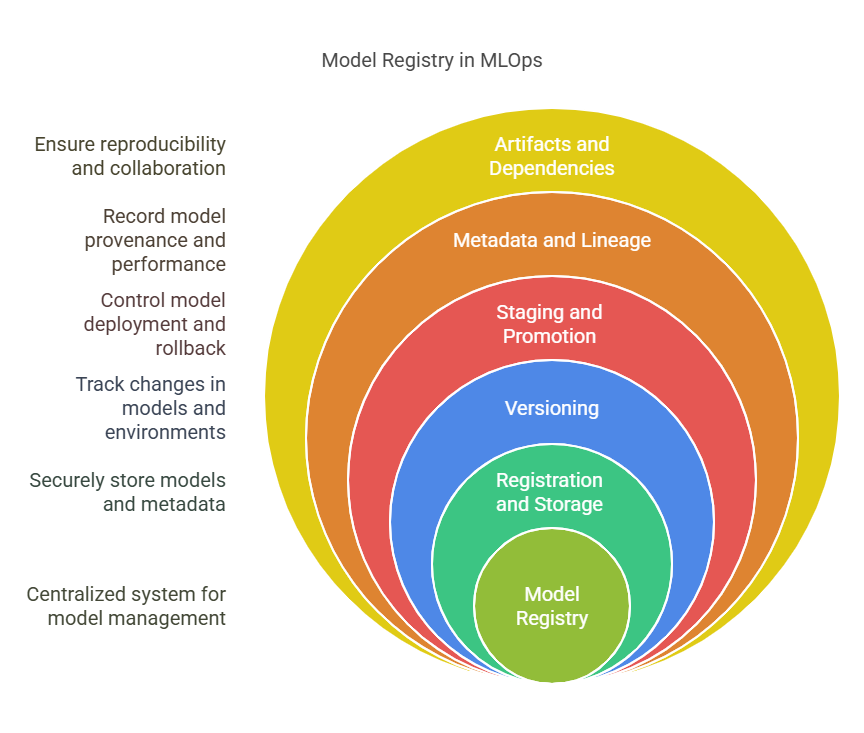
A model registry is a centralized system or platform designed to manage the full lifecycle of machine learning models. In the context of MLOps, it acts as the “single source of truth” for all models within an organization, providing structure, traceability, and control over every model artifact—from initial experimentation to production deployment and beyond.
Key Functions of a Model Registry
At its core, a model registry enables teams to:
Register and store models: Save trained models, along with their metadata, in a secure and organized repository.
Version models: Track every version of a model, including changes in code, data, hyperparameters, and training environment.
Stage and promote models: Move models through different lifecycle stages (e.g., “Staging,” “Production,” “Archived”) to control deployment and rollback.
Track metadata and lineage: Record information about model provenance, such as who trained the model, when, with what data, and what performance metrics were achieved.
Manage artifacts and dependencies: Store related files, such as preprocessing scripts, requirements, and documentation, ensuring reproducibility and easy handoff between teams.
Why Is a Model Registry Essential in MLOps?
In modern machine learning workflows, multiple teams may be developing, testing, and deploying models simultaneously. Without a model registry, it’s easy to lose track of which model is in production, which version is the latest, or how a model was trained. This can lead to confusion, duplicated effort, and even compliance risks.
A model registry solves these problems by providing:
Centralized visibility: Everyone knows where to find the latest and historical models.
Reproducibility: Every model version is linked to its code, data, and environment, making it easy to reproduce results or debug issues.
Collaboration: Data scientists, ML engineers, and DevOps teams can work together seamlessly, using the registry as a shared platform.
Auditability: For regulated industries, a model registry provides the audit trails needed to demonstrate compliance and accountability.
Key Features of Modern Model Registries
Modern model registries are essential tools in the MLOps ecosystem, providing the structure and automation needed to manage machine learning models at scale. As organizations deploy more models into production, the need for robust, feature-rich registries becomes critical for ensuring traceability, reproducibility, and operational efficiency. Here are the key features that define a modern model registry and why they matter for successful ML lifecycle management.
- Model Versioning and Lineage
A core feature of any model registry is the ability to track multiple versions of each model. This includes not only the model artifact itself but also metadata such as training data versions, code commits, hyperparameters, and environment details. Lineage tracking ensures that every model in production can be traced back to its origin, supporting reproducibility and compliance.
- Lifecycle Staging and Promotion
Modern registries support model lifecycle stages such as “Staging,” “Production,” and “Archived.” This allows teams to promote models through testing and validation phases before deployment, and to roll back to previous versions if issues arise. Automated promotion and approval workflows streamline CI/CD for ML.
- Metadata and Artifact Management
A model registry stores rich metadata for each model, including performance metrics, training context, and related artifacts (e.g., preprocessing scripts, requirements files). This metadata is crucial for auditing, debugging, and collaboration between data science and engineering teams.
- Access Control and Security
Enterprise-grade registries offer fine-grained access control, allowing organizations to manage who can register, update, deploy, or delete models. Integration with identity providers and audit logging ensures that all actions are tracked for security and compliance.
- Integration with MLOps Pipelines
Modern registries are designed to integrate seamlessly with CI/CD pipelines, experiment tracking tools, and monitoring systems. This enables automated model registration, validation, deployment, and monitoring as part of end-to-end ML workflows.
- Search, Discovery, and Collaboration
A searchable interface allows users to quickly find models by name, tag, owner, or performance metric. Collaboration features—such as comments, annotations, and notifications—help teams share knowledge and coordinate model development and deployment.
- Cloud and Open Source Compatibility
The best model registries support both open source and cloud-native environments, enabling hybrid and multi-cloud MLOps strategies. This flexibility allows organizations to avoid vendor lock-in and choose the best tools for their needs.
Versioning Strategies for Machine Learning Models
Versioning is a cornerstone of effective model management in MLOps, ensuring that every machine learning model can be traced, reproduced, and safely updated or rolled back. As organizations scale their AI initiatives, robust versioning strategies become essential for collaboration, compliance, and operational reliability. Here’s how to approach model versioning in practice.
Why Model Versioning Matters
Machine learning models are dynamic artifacts—they evolve as new data arrives, algorithms improve, or business requirements change. Without systematic versioning, it’s easy to lose track of which model is in production, which data and code were used, or how a model performed in the past. This can lead to confusion, duplicated effort, and even compliance risks.
Key Versioning Strategies
Semantic Versioning:
Adopt a clear versioning scheme (e.g., MAJOR.MINOR.PATCH) to indicate the significance of changes. Major versions reflect breaking changes or new architectures, minor versions for improvements, and patch versions for bug fixes or retraining on new data.
Automated Version Assignment:
Integrate versioning into your CI/CD pipelines. Automatically increment model versions when new models are registered, and tag them with metadata such as training data version, code commit hash, and hyperparameters.
Linking Code, Data, and Model Versions:
Use tools like MLflow, DVC, or cloud-native registries to link each model version to the exact code, data, and environment used for training. This ensures full reproducibility and traceability.
Stage-Based Versioning:
Track not only the version number but also the model’s lifecycle stage (e.g., “Staging,” “Production,” “Archived”). This helps teams manage model promotion, rollback, and deprecation in a controlled way.
Artifact Management:
Store all related artifacts—such as preprocessing scripts, requirements files, and evaluation metrics—alongside each model version. This makes it easier to audit, debug, and reproduce results.

Model Lifecycle Stages: From Experimentation to Production
Managing the lifecycle of machine learning models is crucial for ensuring that only validated, high-quality models reach production. Model lifecycle stages provide a structured approach to moving models from initial experimentation through testing, validation, and deployment. Here’s a simplified implementation of model lifecycle management.
Understanding Model Lifecycle Stages
Model lifecycle stages represent different phases in a model’s journey:
Experimentation: Initial model development and testing
Staging: Models ready for validation in a production-like environment
Production: Models actively serving predictions
Archived: Retired or replaced models
Simple Python Implementation
Here’s a concise Python example demonstrating model lifecycle management:
python
from enum import Enum
from dataclasses import dataclass
from typing import Dict, Optional
import json
class ModelStage(Enum):
EXPERIMENTATION = "experimentation"
STAGING = "staging"
PRODUCTION = "production"
ARCHIVED = "archived"
@dataclass
class ModelInfo:
name: str
version: str
stage: ModelStage
accuracy: float
created_by: str
class SimpleModelRegistry:
def __init__(self):
self.models: Dict[str, ModelInfo] = {}
self.promotion_criteria = {
ModelStage.STAGING: {"min_accuracy": 0.80},
ModelStage.PRODUCTION: {"min_accuracy": 0.85}
}
def register_model(self, model_info: ModelInfo):
"""Register a new model"""
key = f"{model_info.name}:{model_info.version}"
self.models[key] = model_info
print(f"✅ Registered: {key} in {model_info.stage.value}")
def promote_model(self, name: str, version: str, target_stage: ModelStage) -> bool:
"""Promote model to target stage"""
key = f"{name}:{version}"
if key not in self.models:
print(f"❌ Model not found: {key}")
return False
model = self.models[key]
# Check promotion criteria
if target_stage in self.promotion_criteria:
min_accuracy = self.promotion_criteria[target_stage]["min_accuracy"]
if model.accuracy < min_accuracy:
print(f"❌ Promotion failed: accuracy {model.accuracy} < {min_accuracy}")
return False
# Archive current production model if promoting to production
if target_stage == ModelStage.PRODUCTION:
self._archive_production_models(name)
# Update stage
model.stage = target_stage
print(f"✅ Promoted {key} to {target_stage.value}")
return True
def _archive_production_models(self, model_name: str):
"""Archive existing production models"""
for model in self.models.values():
if model.name == model_name and model.stage == ModelStage.PRODUCTION:
model.stage = ModelStage.ARCHIVED
print(f"📦 Archived: {model.name}:{model.version}")
def get_production_model(self, name: str) -> Optional[ModelInfo]:
"""Get current production model"""
for model in self.models.values():
if model.name == name and model.stage == ModelStage.PRODUCTION:
return model
return None
def list_models_by_stage(self, stage: ModelStage):
"""List models in specific stage"""
return [m for m in self.models.values() if m.stage == stage]
# Demo usage
def demo():
registry = SimpleModelRegistry()
# Register models
model_v1 = ModelInfo("fraud_detector", "1.0", ModelStage.EXPERIMENTATION, 0.82, "alice")
model_v2 = ModelInfo("fraud_detector", "2.0", ModelStage.EXPERIMENTATION, 0.88, "bob")
registry.register_model(model_v1)
registry.register_model(model_v2)
# Promote models
registry.promote_model("fraud_detector", "1.0", ModelStage.STAGING)
registry.promote_model("fraud_detector", "1.0", ModelStage.PRODUCTION) # Should fail
registry.promote_model("fraud_detector", "2.0", ModelStage.STAGING)
registry.promote_model("fraud_detector", "2.0", ModelStage.PRODUCTION) # Should succeed
# Check production model
prod_model = registry.get_production_model("fraud_detector")
if prod_model:
print(f"🚀 Production model: {prod_model.name}:{prod_model.version}")
if __name__ == "__main__":
demo()
# Created/Modified files during execution:
print("simple_registry.py")Integrating Model Registry with CI/CD Pipelines
Integrating a model registry with CI/CD pipelines is a best practice that brings automation, traceability, and reliability to the machine learning lifecycle. In modern MLOps, this integration ensures that every model version is properly tracked, validated, and deployed—just like traditional software releases.
Why Integrate Model Registry with CI/CD?
A model registry acts as the single source of truth for all machine learning models, storing artifacts, metadata, and version history. By connecting it to your CI/CD pipeline, you automate the process of registering new models, promoting them through lifecycle stages (e.g., staging, production), and rolling back if issues arise. This reduces manual errors, accelerates deployment, and ensures compliance with governance and audit requirements.
How the Integration Works
Automated Model Registration:
When a new model is trained and passes validation tests, the CI/CD pipeline automatically registers it in the model registry, along with relevant metadata (e.g., code version, data version, hyperparameters, metrics).
Promotion and Staging:
The pipeline can promote models to “staging” for further testing or “production” for live serving, based on automated checks or human approval. This ensures only validated models reach end users.
Rollback and Version Control:
If a new model underperforms or causes issues, the pipeline can automatically roll back to a previous version stored in the registry, minimizing downtime and risk.
Audit and Traceability:
Every model transition, deployment, and rollback is logged, providing a complete audit trail for compliance and debugging.
Example: Simple Python CI/CD Integration with MLflow
Below is a simplified example of how a CI/CD pipeline might register and promote a model using MLflow:
python
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Simulate CI/CD pipeline step: train and validate model
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
accuracy = accuracy_score(y_test, model.predict(X_test))
# Register model if it meets quality gate
if accuracy > 0.9:
with mlflow.start_run() as run:
mlflow.sklearn.log_model(model, "model")
mlflow.log_metric("accuracy", accuracy)
# Register in model registry
result = mlflow.register_model(
f"runs:/{run.info.run_id}/model", "iris_classifier"
)
print(f"Model registered as version: {result.version}")
# Optionally, promote to staging/production
client = mlflow.tracking.MlflowClient()
client.transition_model_version_stage(
name="iris_classifier",
version=result.version,
stage="Staging"
)
print(f"Model promoted to Staging")
else:
print("Model did not meet accuracy threshold; not registered.")Best Practices
Automate model registration and promotion in your CI/CD workflows.
Use quality gates (e.g., accuracy thresholds) to control promotion.
Store all relevant metadata and artifacts for traceability.
Integrate rollback logic to quickly revert to previous models if needed.
Ensure audit logs are maintained for compliance and debugging.
Model Promotion, Staging, and Rollback Workflows
Model promotion, staging, and rollback workflows ensure that only validated models reach production while providing quick recovery options. These workflows reduce deployment risk and enable reliable model updates through systematic validation and approval processes.
Key Workflow Components
Quality Gates: Automated checks before promotion
Staging Environment: Safe testing before production
Rollback Mechanism: Quick reversion to previous versions
Approval Process: Human oversight for critical deployments
Simple Python Implementation
python
from enum import Enum
from dataclasses import dataclass
from typing import Optional
class Stage(Enum):
STAGING = "staging"
PRODUCTION = "production"
@dataclass
class Model:
name: str
version: str
stage: Stage
accuracy: float
rollback_version: Optional[str] = None
class ModelWorkflow:
def __init__(self):
self.models = {}
self.min_accuracy = 0.85
def promote_to_staging(self, name: str, version: str, accuracy: float):
"""Promote model to staging"""
key = f"{name}:{version}"
self.models[key] = Model(name, version, Stage.STAGING, accuracy)
print(f"✅ {key} promoted to staging (accuracy: {accuracy:.3f})")
def promote_to_production(self, name: str, version: str, approved_by: str):
"""Promote model to production with validation"""
key = f"{name}:{version}"
if key not in self.models:
print(f"❌ Model {key} not found in staging")
return False
model = self.models[key]
# Quality gate
if model.accuracy < self.min_accuracy:
print(f"❌ Accuracy {model.accuracy:.3f} below threshold {self.min_accuracy}")
return False
# Archive current production model
current_prod = self._get_production_model(name)
if current_prod:
model.rollback_version = current_prod.version
current_prod.stage = Stage.STAGING # Demote to staging
# Promote to production
model.stage = Stage.PRODUCTION
print(f"🚀 {key} promoted to production by {approved_by}")
return True
def rollback(self, name: str):
"""Rollback to previous production version"""
current = self._get_production_model(name)
if not current or not current.rollback_version:
print(f"❌ No rollback available for {name}")
return False
# Find rollback model
rollback_key = f"{name}:{current.rollback_version}"
rollback_model = self.models.get(rollback_key)
if rollback_model:
current.stage = Stage.STAGING
rollback_model.stage = Stage.PRODUCTION
print(f"🔄 Rolled back {name} to version {current.rollback_version}")
return True
print(f"❌ Rollback version {current.rollback_version} not found")
return False
def _get_production_model(self, name: str):
"""Get current production model"""
for model in self.models.values():
if model.name == name and model.stage == Stage.PRODUCTION:
return model
return None
def status(self, name: str):
"""Show model status"""
prod = self._get_production_model(name)
staging = [m for m in self.models.values()
if m.name == name and m.stage == Stage.STAGING]
print(f"Production: {prod.version if prod else 'None'}")
print(f"Staging: {[m.version for m in staging]}")
if prod and prod.rollback_version:
print(f"Rollback available: {prod.rollback_version}")
# Demo
workflow = ModelWorkflow()
# Promote models
workflow.promote_to_staging("fraud_model", "1.0", 0.87)
workflow.promote_to_production("fraud_model", "1.0", "alice")
workflow.promote_to_staging("fraud_model", "2.0", 0.89)
workflow.promote_to_production("fraud_model", "2.0", "bob")
# Check status
workflow.status("fraud_model")
# Rollback demo
workflow.rollback("fraud_model")
workflow.status("fraud_model")Managing Metadata, Artifacts, and Dependencies
Efficient management of metadata, artifacts, and dependencies is a cornerstone of modern MLOps and model registry best practices. As machine learning projects scale, tracking not just the models themselves, but also the context in which they were created, becomes essential for reproducibility, collaboration, and compliance.
Why Metadata Management Matters in MLOps
Metadata provides the context for every model version: who trained it, when, with what data, which code commit, and what hyperparameters or environment settings were used. Without this information, it’s nearly impossible to reproduce results, debug issues, or satisfy audit requirements. A robust model registry should automatically capture and store this metadata for every registered model.
Artifact Management: More Than Just Models
Artifacts include not only the serialized model files (e.g., .pkl, .onnx, .h5), but also related files such as preprocessing scripts, feature transformers, requirements files, and evaluation reports. Storing these alongside the model ensures that anyone can re-run the full pipeline or deploy the model in a new environment with confidence. Many registries support artifact versioning and storage in cloud or on-premises repositories.
Dependency Tracking for Reproducibility
Machine learning models often depend on specific versions of libraries, frameworks, and even operating systems. Capturing these dependencies—using tools like requirements.txt, conda.yaml, or Docker images—ensures that models can be reliably reproduced and deployed, even months or years after their initial creation. Advanced registries may even store environment snapshots or container images as part of the model record.
Security, Access Control, and Auditability
Security, access control, and auditability are critical pillars of any robust model registry and MLOps workflow—especially as machine learning models become core assets in production systems. Ensuring that only authorized users can register, update, deploy, or delete models is essential for protecting intellectual property, maintaining compliance, and preventing costly mistakes.
Security in Model Registries
Modern model registries must support enterprise-grade security features. This includes encryption of model artifacts and metadata both at rest and in transit, integration with identity providers (such as LDAP, SSO, or OAuth), and secure storage of sensitive information. Cloud-native registries often provide built-in encryption and key management, while open source solutions may require additional configuration.
Access Control: Who Can Do What?
Role-based access control (RBAC) is a best practice for managing permissions in model registries. RBAC allows organizations to define roles (e.g., data scientist, ML engineer, admin) and assign granular permissions for actions like registering models, promoting to production, or rolling back versions. This minimizes the risk of unauthorized changes and supports separation of duties in regulated environments.
Auditability and Compliance
Auditability means having a complete, tamper-proof record of all actions taken on models and artifacts. Every registration, update, promotion, deployment, or deletion should be logged with a timestamp, user identity, and details of the change. This audit trail is essential for compliance with regulations (such as GDPR, HIPAA, or SOX), as well as for debugging and incident response.
Popular Model Registry Tools: Open Source and Cloud Solutions
Choosing the right model registry tool is a key decision in any MLOps strategy. The right registry streamlines model versioning, lifecycle management, and deployment, while supporting collaboration, security, and compliance. Here’s an overview of the most popular open source and cloud-native model registry solutions, along with their strengths and ideal use cases.
Open Source Model Registry Tools
MLflow Model Registry
One of the most widely adopted open source registries, MLflow offers experiment tracking, model versioning, stage transitions (e.g., Staging, Production), and integration with popular ML frameworks. It can be self-hosted on-premises or in the cloud, making it ideal for organizations seeking flexibility and control.
DVC (Data Version Control)
DVC extends Git-based version control to data and models, enabling teams to track every change to model artifacts and datasets alongside code. It’s especially useful for teams that want to keep everything in their existing Git workflows.
Seldon Core and KFServing
While primarily focused on model serving, these open source tools also provide model versioning and deployment management, and can be integrated with other registries for end-to-end MLOps.
Cloud-Native Model Registry Solutions
AWS SageMaker Model Registry
Fully managed and tightly integrated with the AWS ecosystem, this registry supports model versioning, approval workflows, deployment automation, and access control. It’s ideal for teams already invested in AWS infrastructure.
Azure ML Model Registry
Part of Azure Machine Learning, this registry offers model tracking, versioning, and deployment to Azure endpoints, with built-in security and compliance features.
Google Vertex AI Model Registry
Google’s managed registry supports model versioning, deployment, and monitoring, and integrates with Vertex AI Pipelines and other GCP services.
Key Considerations When Choosing a Model Registry
Integration: Does the registry integrate with your existing ML tools, CI/CD pipelines, and cloud infrastructure?
Scalability: Can it handle your expected volume of models, artifacts, and users?
Security and Compliance: Does it support RBAC, encryption, and audit logging?
Portability: Can you move models between environments or clouds easily?
Cost: Consider both licensing (for managed services) and operational overhead (for self-hosted solutions).
Real-World Case Studies and Best Practices
Real-world case studies offer invaluable lessons for organizations looking to implement model registries and manage the lifecycle of machine learning models at scale. By examining how leading companies have tackled these challenges, teams can adopt proven best practices, avoid common pitfalls, and accelerate their own MLOps maturity.
Case Study 1: E-commerce Personalization at Scale
A global e-commerce company faced the challenge of managing hundreds of recommendation models across multiple regions and business units. They adopted MLflow Model Registry as the backbone of their MLOps workflow. By integrating the registry with their CI/CD pipelines, they automated model registration, promotion, and rollback. This allowed data scientists to experiment rapidly, while ensuring that only validated models reached production.
Best practices implemented:
Automated quality gates: Models were only promoted if they met predefined accuracy and business metric thresholds.
Centralized logging: Every model transition, approval, and rollback was logged for traceability and compliance.
Regular audits: Model lineage and metadata were reviewed regularly to ensure regulatory compliance and reproducibility.
Case Study 2: Financial Services and Regulatory Compliance
A large financial institution needed to track and manage credit risk models in a highly regulated environment. They used Azure ML Model Registry to enforce strict governance and compliance. Role-based access control (RBAC) ensured that only authorized users could promote models to production, and detailed audit logs were maintained for every action.
Best practices implemented:
RBAC and approval workflows: All production deployments required multi-level approvals.
Audit trails: Every model version, transition, and deployment was logged for regulatory review.
Access reviews: Permissions were reviewed and updated regularly to minimize risk.
Case Study 3: Healthcare AI and Data Privacy
A healthcare startup developed clinical AI models using a hybrid cloud environment. They combined DVC for data and model versioning with MLflow for experiment tracking and registry. Automated pipelines validated data quality and model performance before any promotion to staging or production.
Best practices implemented:
Full versioning: All data, code, and models were versioned for complete reproducibility.
Automated validation: Data and model quality checks were built into CI/CD workflows.
Comprehensive documentation: Every model’s training context, data sources, and performance metrics were documented for clinical validation and audits.
Lessons Learned and Best Practices
Automate everything: Use CI/CD to automate model registration, validation, promotion, and rollback, reducing manual errors and speeding up deployment.
Centralize metadata: Store all model metadata, artifacts, and lineage in a single registry for easy access, compliance, and collaboration.
Enforce security and compliance: Implement RBAC, encryption, and audit logging from the start to protect sensitive models and data.
Monitor continuously: Set up monitoring and alerting for model performance, drift, and data quality to catch issues early.
Document and communicate: Maintain clear documentation and foster collaboration between data science, engineering, and compliance teams to ensure smooth operations and knowledge sharing.
Common Pitfalls and How to Avoid Them
Even with the best intentions, organizations often encounter common pitfalls when implementing model registries and managing the lifecycle of machine learning models. Recognizing these challenges early—and knowing how to avoid them—can save time, reduce risk, and ensure a smoother path to scalable, production-ready MLOps.
1. Lack of Versioning Discipline
A frequent mistake is failing to consistently version models, data, and code. Without strict versioning, teams struggle to reproduce results, debug issues, or roll back to previous states.
How to avoid:
Adopt automated versioning in your CI/CD pipelines and enforce policies that require every model, dataset, and code change to be tracked and linked in the registry.
2. Incomplete Metadata and Artifact Tracking
Storing only the model file, without associated metadata (e.g., training data version, hyperparameters, environment), makes it nearly impossible to understand or reproduce a model’s behavior.
How to avoid:
Use a model registry that supports rich metadata and artifact management. Automate the capture of all relevant information during model registration.
3. Weak Access Control and Security
Allowing unrestricted access to model registries can lead to accidental deletions, unauthorized deployments, or data leaks.
How to avoid:
Implement role-based access control (RBAC), strong authentication, and audit logging. Regularly review permissions and monitor for suspicious activity.
4. Manual Promotion and Rollback
Relying on manual processes for model promotion or rollback increases the risk of human error and slows down deployment.
How to avoid:
Automate promotion, staging, and rollback workflows in your CI/CD pipelines, with clear quality gates and approval steps.
5. Siloed Registries and Fragmented Workflows
Using multiple, disconnected registries or failing to integrate the registry with other MLOps tools leads to confusion and inefficiency.
How to avoid:
Centralize your model registry and ensure seamless integration with experiment tracking, monitoring, and deployment tools.
6. Ignoring Compliance and Auditability
Neglecting compliance requirements or failing to maintain audit trails can result in regulatory penalties and loss of trust.
How to avoid:
Choose a registry with built-in audit logging and compliance features. Document all model transitions, approvals, and deployments.
7. Poor Documentation and Communication
Lack of clear documentation and communication between teams can cause misunderstandings, duplicated work, and deployment delays.
How to avoid:
Maintain up-to-date documentation for all models, workflows, and registry processes. Foster collaboration between data science, engineering, and compliance teams.
Future Trends in Model Registry and ML Lifecycle Management
As machine learning becomes increasingly central to business operations, the future of model registry and ML lifecycle management is evolving rapidly. Organizations are seeking more automation, scalability, and intelligence in how they track, deploy, and govern their models. Here are the key trends shaping the next generation of model registry and lifecycle management:
1. Deeper Integration with CI/CD and MLOps Platforms
Model registries will become even more tightly integrated with CI/CD pipelines, experiment tracking, and monitoring tools. This will enable fully automated workflows—from model training and validation to deployment, monitoring, and rollback—reducing manual intervention and speeding up time-to-production.
2. AI-Driven Automation and Self-Healing Pipelines
Expect to see more AI-powered features in registries, such as automated drift detection, performance monitoring, and self-healing pipelines that can trigger retraining or rollback without human input. These capabilities will help organizations maintain model accuracy and reliability at scale.
3. Enhanced Explainability and Compliance
Future model registries will offer built-in explainability tools and compliance checks, making it easier to meet regulatory requirements and build trust with stakeholders. Automated documentation, lineage tracking, and bias detection will become standard features.
4. Multi-Cloud and Hybrid Support
As organizations adopt multi-cloud and hybrid strategies, model registries will need to support seamless model movement, versioning, and deployment across diverse environments. Cloud-agnostic APIs and open standards (like ONNX for models and Parquet for data) will be key enablers.
5. Real-Time and Edge Model Management
With the rise of edge computing and real-time AI applications, registries will evolve to manage models deployed on edge devices, track their performance, and orchestrate updates remotely—ensuring consistency and security across distributed systems.
6. Cost and Resource Optimization
Registries will increasingly provide insights into model usage, resource consumption, and cost, helping organizations optimize their ML infrastructure and prioritize high-value models.
7. Collaboration and Marketplace Features
Expect more collaborative features, such as model sharing, peer review, and even internal or external model marketplaces, where teams can discover, reuse, and monetize models securely.
Summary
The future of model registry and ML lifecycle management is about intelligent automation, seamless integration, and robust governance across the entire AI landscape. By embracing these trends, organizations can build scalable, compliant, and future-proof MLOps workflows that drive real business value and innovation.
MLOps for Developers – A Guide to Modern Workflows
From Code to Production: The Best MLOps Tools for Developers
MLOps in Practice – How to Automate the Machine Learning Model Lifecycle