

Introduction: The Role of MLOps in Modern Development
In today’s fast-paced tech landscape, machine learning is no longer just a research topic—it’s a core part of many products and services. However, building and deploying machine learning models comes with unique challenges that can slow down even the most experienced developers. This is where MLOps (Machine Learning Operations) steps in, offering a set of practices and tools designed to streamline and automate the entire ML lifecycle.
For developers, MLOps is a game changer. It bridges the gap between data science and software engineering, making it easier to move models from experimentation to production. With MLOps, repetitive and time-consuming tasks—like data preprocessing, model training, deployment, and monitoring—can be automated, freeing up developers to focus on solving real business problems.
MLOps also introduces best practices from DevOps, such as version control, continuous integration, and automated testing, into the world of machine learning. This not only improves collaboration between teams but also increases the reliability and scalability of ML solutions.
In short, MLOps empowers developers to deliver machine learning projects faster, with fewer errors, and at scale. By adopting MLOps, developers can unlock new levels of productivity and innovation, making their work both easier and more impactful.
Common Pain Points for Developers in Machine Learning Projects
Working on machine learning projects can be exciting, but it also brings a unique set of challenges that often frustrate developers. Unlike traditional software development, ML projects involve not just code, but also large volumes of data, complex experiments, and models that can behave unpredictably in production.
One of the biggest pain points is managing data. Data is constantly changing, and keeping track of which version of the data was used for training, testing, or validation can quickly become a headache. Without proper versioning, it’s easy to lose track of experiments or struggle to reproduce results.
Another challenge is the lack of standardization in ML workflows. Developers often find themselves reinventing the wheel—writing custom scripts for data preprocessing, model training, and evaluation. This leads to fragmented codebases and makes collaboration difficult, especially when multiple people are working on the same project.
Deployment is another area where developers hit roadblocks. Moving a model from a Jupyter notebook to a production environment is rarely straightforward. Issues like dependency management, scaling, and integration with existing systems can cause significant delays.
Monitoring and maintaining models in production is also tricky. Unlike traditional software, ML models can degrade over time as data changes—a phenomenon known as data drift. Detecting and responding to these changes requires specialized tools and processes, which are often missing in early-stage projects.
Finally, collaboration between developers and data scientists can be challenging. Differences in tools, workflows, and even terminology can lead to misunderstandings and slow down progress.
All these pain points highlight the need for a more structured approach—one that MLOps is designed to provide. By addressing these challenges, MLOps helps developers work more efficiently and deliver better machine learning solutions.
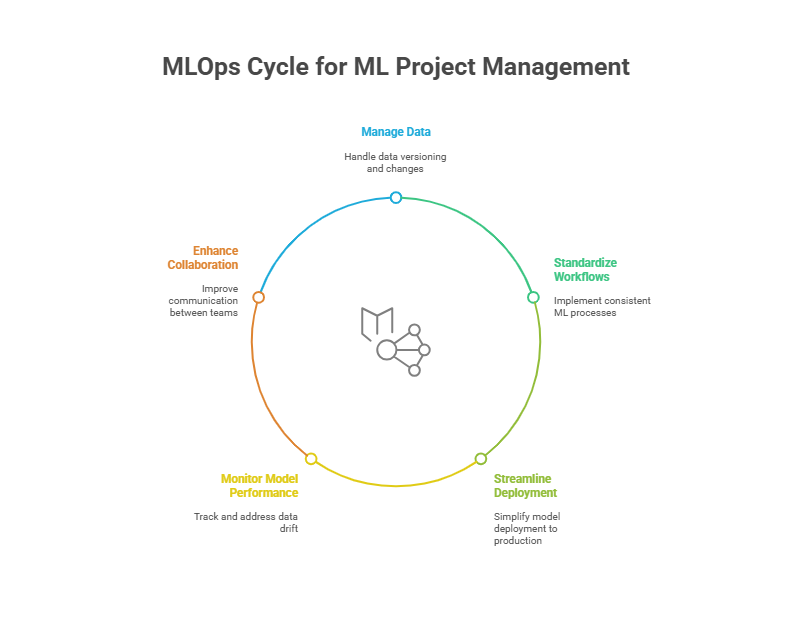
MLOps Fundamentals: What Every Developer Should Know
MLOps, or Machine Learning Operations, is rapidly becoming a must-have skill for developers working with artificial intelligence and data-driven applications. But what exactly is MLOps, and why is it so important for modern software teams? In this article, we’ll break down the fundamentals of MLOps, explain its core components, and show why every developer should understand its principles.
What Is MLOps?
MLOps is a set of practices and tools that combine machine learning, DevOps, and data engineering to automate and streamline the entire machine learning lifecycle. This includes everything from data collection and preprocessing, through model training and validation, to deployment, monitoring, and maintenance in production environments. The main goal of MLOps is to make machine learning workflows more reliable, scalable, and efficient.
Key Components of MLOps
To understand MLOps, it’s helpful to look at its core components:
Version Control: Just like in traditional software development, version control in MLOps covers not only code, but also data and models. This ensures that every experiment is reproducible and that teams can track changes over time.
Continuous Integration and Continuous Delivery (CI/CD): MLOps brings CI/CD practices to machine learning, allowing teams to automate testing, validation, and deployment of models. This reduces manual errors and speeds up the release cycle.
Automated Testing: Automated tests for data, features, and models help catch issues early and ensure that only high-quality models make it to production.
Monitoring and Logging: Once a model is deployed, it’s crucial to monitor its performance and log predictions, errors, and data drift. This helps teams quickly identify and address issues in production.
Collaboration Tools: MLOps platforms often include tools for collaboration, making it easier for developers, data scientists, and operations teams to work together seamlessly.
Why MLOps Matters for Developers
For developers, understanding MLOps fundamentals means being able to build, deploy, and maintain machine learning models more efficiently. MLOps reduces the time spent on repetitive tasks, minimizes the risk of errors, and ensures that models remain reliable as data and requirements change. It also enables better collaboration across teams, making it easier to scale machine learning solutions in real-world applications.
MLOps Best Practices for Developers
To get started with MLOps, developers should focus on a few best practices: use version control for all project artifacts, automate as much of the workflow as possible, implement robust monitoring, and foster a culture of collaboration between teams. Adopting these practices will not only improve productivity but also lead to more successful machine learning projects.
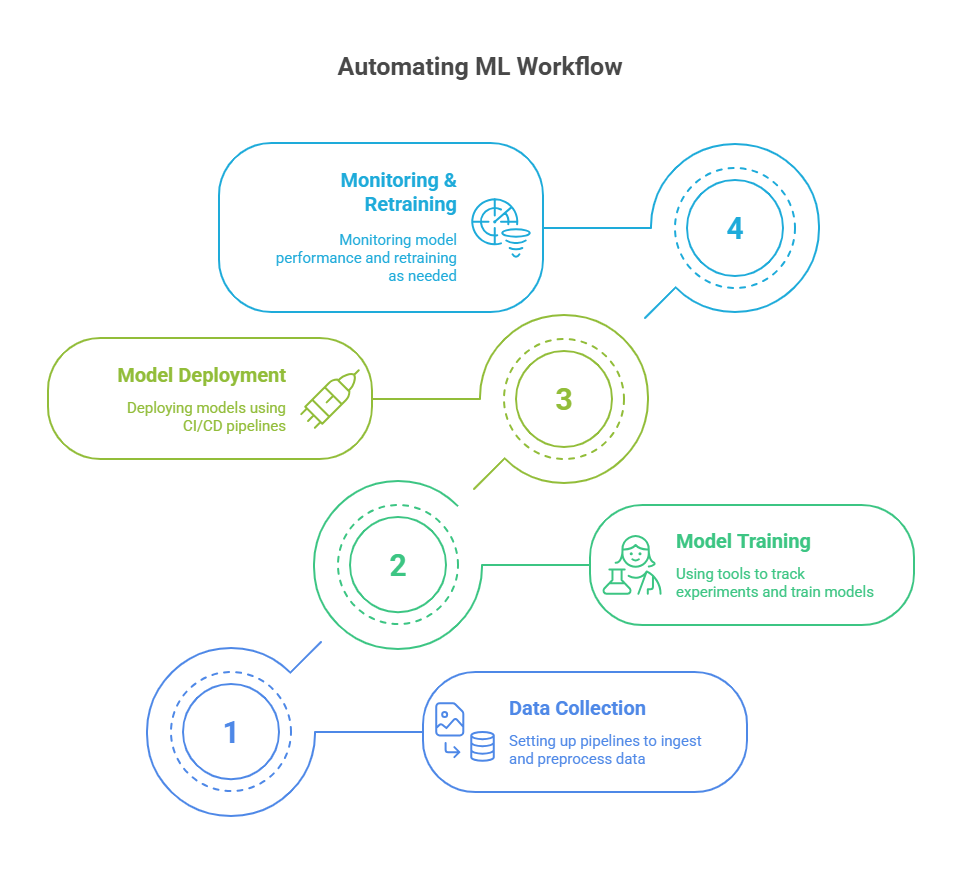
Automating the ML Workflow: From Data to Deployment
Automating the machine learning workflow is one of the most impactful ways to boost productivity and reliability in ML projects. For developers, automation means less time spent on repetitive manual tasks and more time focused on solving real business problems. But what does automation in the ML workflow actually look like, and how can you implement it effectively?
The ML workflow typically starts with data collection and preprocessing. Automation at this stage involves setting up pipelines that can regularly ingest new data, clean it, and transform it into features ready for model training. Tools like Apache Airflow, Kubeflow Pipelines, or cloud-native solutions such as AWS Step Functions allow developers to schedule and orchestrate these data workflows, ensuring consistency and reducing the risk of human error.
Once the data is ready, the next step is model training and validation. Here, automation can be achieved by using experiment tracking tools and automated training scripts. Platforms like MLflow, Weights & Biases, or TensorBoard help track experiments, compare results, and manage model versions. Automated hyperparameter tuning and model selection can further streamline this process, ensuring that the best-performing models are identified without manual intervention.
Deployment is another critical area for automation. Instead of manually packaging and deploying models, developers can use CI/CD pipelines tailored for ML, such as GitHub Actions, Jenkins, or cloud-based ML deployment services. These pipelines can automatically test, validate, and deploy models to production environments, reducing deployment time and minimizing the risk of errors.
Finally, automation doesn’t stop at deployment. Monitoring and retraining models are essential for maintaining performance as data evolves. Automated monitoring tools can detect data drift, performance degradation, or anomalies in real time, triggering alerts or even automated retraining workflows when necessary.
By automating the entire ML workflow—from data ingestion to deployment and monitoring—developers can achieve faster iteration cycles, higher reliability, and more scalable machine learning solutions. Embracing automation is a key step toward building robust, production-ready ML systems that deliver real value to organizations.
Versioning Code, Data, and Models: Best Practices
Versioning is the foundation of reproducibility, collaboration, and reliability in any machine learning project. In MLOps, where code, data, and models evolve rapidly, robust versioning practices are essential for tracking changes, debugging issues, and ensuring that experiments can be reproduced or rolled back at any time. Here’s how to approach versioning each critical component of your ML workflow.
Why Versioning Matters in MLOps
Machine learning projects are dynamic by nature. Code changes, datasets are updated, and models are retrained as new data arrives or requirements shift. Without systematic versioning, it’s easy to lose track of which code produced which model, with what data, and under what conditions. This can lead to confusion, wasted effort, and even compliance risks in regulated industries.
Best Practices for Versioning Code
For code, the gold standard is using a distributed version control system like Git. Every change—whether it’s a bug fix, feature addition, or refactor—should be committed with a clear message. Branching strategies (such as GitFlow or trunk-based development) help teams collaborate efficiently and keep production code stable. Tagging releases and using pull requests for code reviews further enhance traceability and quality.
Best Practices for Versioning Data
Data versioning is more complex, but just as critical. Tools like DVC (Data Version Control), LakeFS, or Delta Lake allow you to track changes to datasets, link data versions to code commits, and reproduce experiments with the exact same data. Store raw and processed data separately, and always document data sources, preprocessing steps, and schema changes. For large datasets, use storage solutions that support efficient diffing and snapshotting.
Best Practices for Versioning Models
Model versioning ties everything together. Each trained model should be uniquely identified and linked to the code and data versions used to create it. Model registries (such as MLflow Model Registry, Sagemaker Model Registry, or Neptune.ai) provide a central place to store, manage, and promote models through different stages (e.g., staging, production, archived). Always log model parameters, metrics, and artifacts, and automate the process as much as possible to avoid manual errors.
Integrating Versioning Across the Workflow
The real power of versioning in MLOps comes from integrating code, data, and model versioning into a seamless workflow. Use commit hashes, experiment IDs, or metadata tags to link code, data, and models together. Automate versioning steps in your CI/CD pipelines so that every experiment, retraining, or deployment is fully traceable and reproducible.
CI/CD for Machine Learning: Streamlining Releases
Continuous Integration and Continuous Deployment (CI/CD) for machine learning transforms how teams deliver ML models to production. This guide demonstrates essential CI/CD practices with concise, practical Python examples.
Core ML CI/CD Pipeline Implementation
Here’s a streamlined Python implementation covering the essential CI/CD components:
python
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from sklearn.preprocessing import StandardScaler
import pickle
import json
from datetime import datetime
class MLPipeline:
def __init__(self):
self.model = None
self.scaler = StandardScaler()
self.metrics = {}
self.min_accuracy = 0.75
def validate_data(self, data):
"""Basic data validation"""
if len(data) < 100:
raise ValueError("Insufficient data: need at least 100 rows")
missing_ratio = data.isnull().sum().sum() / (len(data) * len(data.columns))
if missing_ratio > 0.1:
raise ValueError(f"Too many missing values: {missing_ratio:.2%}")
print(f"✓ Data validation passed: {len(data)} rows, {missing_ratio:.2%} missing")
return True
def preprocess_data(self, data):
"""Data preprocessing"""
# Handle missing values
data = data.fillna(data.median())
# Separate features and target
X = data.drop('target', axis=1)
y = data['target']
# Scale features
X_scaled = self.scaler.fit_transform(X)
return X_scaled, y
def train_model(self, X, y):
"""Train and validate model"""
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Train model
self.model = RandomForestClassifier(n_estimators=100, random_state=42)
self.model.fit(X_train, y_train)
# Evaluate
y_pred = self.model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
# Store metrics
self.metrics = {
'accuracy': accuracy,
'classification_report': classification_report(y_test, y_pred, output_dict=True),
'timestamp': datetime.now().isoformat()
}
print(f"✓ Model trained: {accuracy:.3f} accuracy")
return accuracy
def validate_model(self):
"""Model quality validation"""
accuracy = self.metrics['accuracy']
if accuracy < self.min_accuracy:
raise ValueError(f"Model accuracy {accuracy:.3f} below threshold {self.min_accuracy}")
print(f"✓ Model validation passed: {accuracy:.3f} >= {self.min_accuracy}")
return True
def save_artifacts(self, output_dir="artifacts"):
"""Save model artifacts"""
import os
os.makedirs(output_dir, exist_ok=True)
# Save model and scaler
with open(f"{output_dir}/model.pkl", 'wb') as f:
pickle.dump(self.model, f)
with open(f"{output_dir}/scaler.pkl", 'wb') as f:
pickle.dump(self.scaler, f)
# Save metrics
with open(f"{output_dir}/metrics.json", 'w') as f:
json.dump(self.metrics, f, indent=2)
print(f"✓ Artifacts saved to {output_dir}/")
return output_dir
def create_sample_data():
"""Generate sample dataset"""
np.random.seed(42)
n_samples = 1000
data = pd.DataFrame({
'feature1': np.random.normal(0, 1, n_samples),
'feature2': np.random.normal(0, 1, n_samples),
'feature3': np.random.normal(0, 1, n_samples),
})
# Create target based on features
data['target'] = ((data['feature1'] + data['feature2'] * 0.5) > 0).astype(int)
return data
def run_pipeline():
"""Execute ML CI/CD pipeline"""
try:
print("🚀 Starting ML CI/CD Pipeline...")
# Initialize pipeline
pipeline = MLPipeline()
# Load data
data = create_sample_data()
print(f"📊 Data loaded: {len(data)} samples")
# Validate data
pipeline.validate_data(data)
# Preprocess data
X, y = pipeline.preprocess_data(data)
# Train model
accuracy = pipeline.train_model(X, y)
# Validate model
pipeline.validate_model()
# Save artifacts
pipeline.save_artifacts()
print(f"✅ Pipeline completed successfully! Accuracy: {accuracy:.3f}")
return True
except Exception as e:
print(f"❌ Pipeline failed: {str(e)}")
return False
# Testing functions
def test_pipeline():
"""Run basic tests"""
print("🧪 Running tests...")
# Test data creation
data = create_sample_data()
assert len(data) > 0, "Data creation failed"
# Test pipeline components
pipeline = MLPipeline()
pipeline.validate_data(data)
X, y = pipeline.preprocess_data(data)
accuracy = pipeline.train_model(X, y)
pipeline.validate_model()
print("✅ All tests passed!")
return True
if __name__ == "__main__":
# Run tests first
if test_pipeline():
# Run main pipeline
success = run_pipeline()
exit(0 if success else 1)
else:
exit(1)Automated Testing and Deployment Script
python
# deploy.py - Simple deployment automation
import subprocess
import sys
import json
def run_tests():
"""Run automated tests"""
print("Running automated tests...")
try:
result = subprocess.run([sys.executable, "ml_pipeline.py"],
capture_output=True, text=True)
if result.returncode == 0:
print("✅ Tests passed")
return True
else:
print(f"❌ Tests failed: {result.stderr}")
return False
except Exception as e:
print(f"❌ Test execution failed: {e}")
return False
def deploy_model():
"""Deploy model to production"""
print("Deploying model...")
# Load model metrics
try:
with open("artifacts/metrics.json", 'r') as f:
metrics = json.load(f)
accuracy = metrics['accuracy']
print(f"📊 Model accuracy: {accuracy:.3f}")
# Simple deployment simulation
if accuracy >= 0.75:
print("🚀 Model deployed to production!")
return True
else:
print("❌ Model accuracy too low for production")
return False
except FileNotFoundError:
print("❌ Model artifacts not found")
return False
def main():
"""Main deployment workflow"""
print("🔄 Starting CI/CD workflow...")
# Step 1: Run tests
if not run_tests():
print("❌ Deployment blocked: tests failed")
return False
# Step 2: Deploy model
if not deploy_model():
print("❌ Deployment failed")
return False
print("✅ CI/CD workflow completed successfully!")
return True
if __name__ == "__main__":
success = main()
exit(0 if success else 1)GitHub Actions Workflow
yaml
# .github/workflows/ml-cicd.yml
name: ML CI/CD
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
test-and-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.9'
- name: Install dependencies
run: |
pip install pandas scikit-learn numpy
- name: Run ML Pipeline
run: python ml_pipeline.py
- name: Deploy Model
if: github.ref == 'refs/heads/main'
run: python deploy.py
- name: Upload Artifacts
uses: actions/upload-artifact@v3
with:
name: model-artifacts
path: artifacts/Key Benefits and Best Practices
This streamlined CI/CD implementation provides essential automation for ML workflows while maintaining simplicity. The pipeline automatically validates data quality, trains models, checks performance thresholds, and saves artifacts for deployment.
Key best practices include setting clear quality gates (minimum accuracy thresholds), automating all validation steps, and maintaining complete traceability through saved metrics and artifacts. The modular design allows teams to extend functionality as needed while keeping the core pipeline lightweight and maintainable.
Key Cost Drivers in Feature Store Operations
Understanding the main cost drivers in feature store operations is crucial for building scalable and efficient machine learning infrastructure. Feature stores, as central repositories for storing, managing, and serving features, can quickly become expensive if not properly managed—especially at scale. Here’s a concise overview of the most important factors that influence costs in feature store environments.
1. Storage Costs
The volume and frequency of data stored in a feature store are primary cost drivers. Storing raw, processed, and historical feature data—especially for real-time and batch use cases—can lead to significant storage expenses. The choice of storage backend (cloud object storage, distributed file systems, or databases) and the retention policy for historical data both directly impact costs.
2. Compute Resources
Feature stores often require substantial compute resources for feature engineering, transformation, and serving. Real-time feature computation, streaming data pipelines, and on-demand feature retrieval can all increase CPU and memory usage. The complexity of feature transformations and the need for low-latency serving further drive up compute costs.
3. Data Transfer and Egress
Moving data between storage, compute, and serving layers—especially across cloud regions or between on-premises and cloud environments—can incur significant data transfer and egress fees. Real-time feature serving to production systems or external consumers amplifies these costs.
4. Integration and Orchestration Overhead
Integrating the feature store with various data sources, ML pipelines, and monitoring tools often requires additional orchestration services and connectors. These integrations can introduce extra infrastructure components, each with their own operational and licensing costs.
5. Maintenance and Monitoring
Ongoing maintenance, including system updates, scaling, and monitoring, adds to the total cost of ownership. Ensuring high availability, data quality, and compliance may require dedicated resources or third-party services, further increasing operational expenses.
Strategies for Cost Optimization in Feature Stores
Efficient cost management is essential for running feature stores at scale, especially as data volumes and usage grow. Below are practical strategies to optimize costs in feature store operations, focusing on storage, compute, and data access.
Storage Optimization
To reduce storage costs, start by implementing data retention policies—store only what’s necessary for your models and delete outdated or unused features regularly. Use efficient data formats like Parquet or ORC, which compress data and reduce storage footprint. Partitioning data by time or feature group can also help minimize the amount of data scanned and stored.
Compute Optimization
Optimize compute costs by scheduling heavy feature engineering jobs during off-peak hours when resources are cheaper. Use batch processing for non-urgent feature calculations instead of real-time pipelines, and cache frequently accessed features to avoid redundant computations. Monitor resource usage and autoscale compute clusters to match demand, preventing over-provisioning.
Data Access and Transfer
Minimize data transfer costs by colocating your feature store with your main data sources and ML infrastructure—this reduces cross-region or cross-cloud egress fees. Use APIs that support selective feature retrieval, so you only move the data you need. For distributed teams or multi-cloud setups, consider using edge caching or regional replicas to serve features closer to where they’re consumed.
Example: Python Code for Storage Cost Estimation
Here’s a simple Python script to estimate storage costs for your feature store, based on data size and cloud provider pricing:
python
# feature_store_cost_estimator.py
def estimate_storage_cost(data_size_gb, price_per_gb_month, retention_months):
"""
Estimate total storage cost for a feature store.
:param data_size_gb: Total data size in GB
:param price_per_gb_month: Storage price per GB per month (e.g., 0.023 for AWS S3 Standard)
:param retention_months: Number of months data is retained
:return: Total estimated cost
"""
total_cost = data_size_gb * price_per_gb_month * retention_months
return round(total_cost, 2)
# Example usage
data_size_gb = 500 # e.g., 500 GB of features
price_per_gb_month = 0.023 # AWS S3 Standard as of 2024
retention_months = 6
cost = estimate_storage_cost(data_size_gb, price_per_gb_month, retention_months)
print(f"Estimated storage cost for {data_size_gb} GB over {retention_months} months: ${cost}")Monitoring and Reporting Feature Store Costs
Effective cost monitoring and transparent reporting are essential for managing feature store expenses, especially as usage scales across teams and projects. Without clear visibility, costs can quickly spiral out of control, impacting the overall ROI of machine learning initiatives. Here’s how to approach cost monitoring and reporting in feature store operations.
Why Monitor Feature Store Costs?
Feature stores often serve multiple teams, projects, and environments. Storage, compute, and data transfer costs can accumulate from various sources—batch pipelines, real-time serving, and historical data retention. Monitoring these costs helps identify inefficiencies, prevent budget overruns, and inform optimization strategies.
Key Metrics to Track
To get a complete picture of feature store spending, track metrics such as total storage used (in GB), monthly storage costs, compute hours consumed by feature engineering jobs, API call counts for feature serving, and data egress volumes. Breaking down costs by project, team, or feature group enables more granular analysis and accountability.
Example: Python Script for Cost Monitoring
Below is a simple Python script that aggregates and reports feature store costs from different sources. In a real-world scenario, you’d pull these numbers from your cloud provider’s billing API or internal monitoring tools.
python
# feature_store_cost_report.py
def report_feature_store_costs(storage_gb, storage_cost_per_gb, compute_hours, compute_cost_per_hour, api_calls, api_cost_per_1000):
storage_cost = storage_gb * storage_cost_per_gb
compute_cost = compute_hours * compute_cost_per_hour
api_cost = (api_calls / 1000) * api_cost_per_1000
total_cost = storage_cost + compute_cost + api_cost
print("Feature Store Cost Report")
print(f"Storage: {storage_gb} GB x ${storage_cost_per_gb}/GB = ${storage_cost:.2f}")
print(f"Compute: {compute_hours} hours x ${compute_cost_per_hour}/hour = ${compute_cost:.2f}")
print(f"API Calls: {api_calls} calls x ${api_cost_per_1000}/1000 = ${api_cost:.2f}")
print(f"Total Estimated Cost: ${total_cost:.2f}")
# Example usage
report_feature_store_costs(
storage_gb=500,
storage_cost_per_gb=0.023, # AWS S3 Standard
compute_hours=120,
compute_cost_per_hour=0.40, # Example EC2 cost
api_calls=200000,
api_cost_per_1000=0.01 # Example API pricing
)Best Practices for Cost Reporting
Automate cost aggregation and reporting using dashboards or scheduled scripts. Set up alerts for unusual spending spikes. Share regular reports with stakeholders to drive awareness and accountability. Tag resources by project or team to enable detailed breakdowns and chargebacks.
Case Study: Cost Optimization in a Large-Scale Feature Store
Let’s look at a real-world-inspired case study that demonstrates how a large enterprise optimized costs in their feature store while supporting hundreds of machine learning models across multiple business units.
Background
A global retail company used a cloud-based feature store to serve features for demand forecasting, recommendation engines, and fraud detection. As the number of models and data sources grew, monthly feature store costs began to rise sharply—mainly due to increased storage, compute for real-time feature engineering, and cross-region data transfers.
Challenges
The main pain points were:
Storing large volumes of historical feature data for compliance and retraining.
High compute costs from real-time feature pipelines.
Expensive data egress fees from serving features to applications in different cloud regions.
Lack of cost visibility by team or project, making it hard to identify optimization opportunities.
Optimization Strategies Implemented
The company took a multi-pronged approach:
Data Retention and Tiered Storage
They implemented strict data retention policies, keeping only the last 90 days of features in fast-access storage and archiving older data to cheaper, infrequently accessed storage.
Batch Over Real-Time
Non-critical features were moved from real-time to batch pipelines, reducing the need for always-on compute resources.
Colocation and Edge Caching
Feature store instances were colocated with the main data sources and ML serving infrastructure. For remote regions, they used edge caching to minimize cross-region data transfer.
Cost Monitoring and Tagging
All feature store resources were tagged by project and team. Automated scripts aggregated costs and generated monthly reports, highlighting the top cost drivers.
Efficient Data Formats and Partitioning
Features were stored in Parquet format and partitioned by date and feature group, reducing storage and query costs.
Results
Within three months, the company achieved:
A 40% reduction in monthly feature store costs.
Faster feature retrieval times for most applications.
Improved cost transparency, enabling teams to take ownership of their usage.
The ability to scale feature store operations to new business units without runaway expenses.
Lessons Learned
Regular cost reviews and transparent reporting are essential for sustainable growth.
Not all features need real-time freshness—batch processing is often sufficient and much cheaper.
Data retention and storage tiering can yield significant savings with minimal impact on model performance.
Tagging and monitoring enable granular cost control and accountability.
Lessons Learned and Best Practices for Cost-Efficient Feature Store Operations
As organizations scale their machine learning initiatives, managing the costs of feature store operations becomes increasingly important. Drawing from industry experience and real-world case studies, here are the key lessons learned and best practices for maintaining a cost-efficient, high-performing feature store.
1. Prioritize Data Retention and Lifecycle Management
One of the most effective ways to control storage costs is to implement clear data retention policies. Regularly review which features and historical data are truly necessary for compliance, retraining, or auditing. Archive or delete obsolete data to avoid unnecessary storage expenses.
2. Choose the Right Processing Mode
Not every feature requires real-time computation. Evaluate the business impact and latency requirements for each use case. Use batch processing for features that don’t need instant updates, reserving real-time pipelines for mission-critical applications. This approach can significantly reduce compute costs.
3. Optimize Data Formats and Partitioning
Store features in efficient, compressed formats like Parquet or ORC, and partition data by time or feature group. This reduces both storage and query costs, especially for large-scale analytics and model training.
4. Monitor, Tag, and Report Costs
Set up automated monitoring and reporting for all feature store resources. Use resource tagging to attribute costs to specific teams, projects, or business units. Regular cost reports and dashboards help identify trends, spot anomalies, and drive accountability.
5. Colocate Infrastructure and Use Edge Caching
Whenever possible, colocate your feature store with your main data sources and ML serving infrastructure to minimize data transfer and egress fees. For distributed or global teams, leverage edge caching or regional replicas to serve features closer to where they’re consumed.
6. Automate and Schedule Resource Usage
Automate the scaling of compute resources based on demand, and schedule heavy feature engineering jobs during off-peak hours. This helps avoid over-provisioning and takes advantage of lower-cost compute windows.
7. Foster a Culture of Cost Awareness
Encourage teams to regularly review their feature usage and associated costs. Provide training and documentation on cost-efficient practices, and make cost metrics visible to all stakeholders.
Summary
Cost-efficient feature store operations require a combination of technical strategies and organizational discipline. By prioritizing data lifecycle management, choosing the right processing modes, optimizing storage, monitoring costs, and fostering a culture of cost awareness, organizations can support robust ML workflows without overspending. These best practices not only reduce expenses but also improve the agility and scalability of machine learning platforms.
MLOps in the Cloud: Tools and Strategies