

Introduction to Automatic Model Retraining
Automatic model retraining is a crucial concept in modern machine learning and MLOps. As data evolves and business environments change, machine learning models can lose their predictive power over time—a phenomenon known as model drift. To maintain high accuracy and reliability, organizations must implement strategies for automatic model retraining.
Automatic model retraining refers to the process of updating machine learning models without manual intervention. This approach ensures that models stay relevant and continue to deliver value as new data becomes available. By automating retraining, companies can respond quickly to changes in data patterns, user behavior, or external factors, reducing the risk of outdated predictions.
In the context of MLOps, automatic retraining is often integrated into end-to-end machine learning pipelines. These pipelines monitor model performance, detect data drift, and trigger retraining workflows when necessary. This not only improves model accuracy but also streamlines the deployment and maintenance process, saving time and resources.
Implementing automatic model retraining is essential for businesses that rely on real-time analytics, personalized recommendations, fraud detection, or any application where data changes frequently. By leveraging automation, organizations can ensure their machine learning solutions remain robust, scalable, and competitive in dynamic environments.
In summary, automatic model retraining is a foundational practice in machine learning operations, enabling continuous improvement and adaptation of models to ever-changing data landscapes.
Why Is Model Retraining Important in Machine Learning?
Model retraining is essential in machine learning because it directly impacts the accuracy, reliability, and long-term value of predictive models. Over time, the data used by machine learning models can change due to evolving user behavior, market trends, seasonality, or external events. This phenomenon, known as data drift or concept drift, can cause models to make less accurate predictions if they are not regularly updated.
Retraining models ensures that they adapt to new patterns and maintain high performance. Without regular retraining, even the best models can become obsolete, leading to poor business decisions, decreased user satisfaction, or increased operational risks. For example, in industries like finance, e-commerce, or healthcare, outdated models can result in missed opportunities, financial losses, or compliance issues.
Automatic model retraining helps organizations respond quickly to changes in data, reducing the need for manual intervention and minimizing downtime. By continuously monitoring model performance and retraining when necessary, businesses can maintain a competitive edge and deliver consistent, high-quality results.
In summary, model retraining is a critical component of any robust machine learning strategy. It ensures that models remain accurate, relevant, and aligned with current data, which is vital for achieving reliable outcomes and maximizing the return on investment in AI and machine learning initiatives.
Key Indicators for Triggering Model Retraining
Identifying the right moment to retrain a machine learning model is crucial for maintaining its effectiveness and accuracy. There are several key indicators that signal when automatic model retraining should be triggered, ensuring that models stay up-to-date with the latest data trends.
One of the most important indicators is a decline in model performance metrics, such as accuracy, precision, recall, or F1 score. Regularly monitoring these metrics allows organizations to detect when a model’s predictions are no longer meeting business requirements. A sudden drop or gradual decrease in performance often suggests that the underlying data distribution has changed.
Another critical indicator is the detection of data drift or concept drift. Data drift occurs when the statistical properties of input data change over time, while concept drift refers to changes in the relationship between input features and the target variable. Tools and techniques for drift detection, such as statistical tests or monitoring feature distributions, help identify when retraining is necessary.
Additionally, significant changes in business processes, user behavior, or external factors—like new regulations or market shifts—can also signal the need for model retraining. For example, launching a new product, entering a new market, or experiencing a sudden surge in user activity may require models to be updated to reflect the new environment.
Scheduled retraining based on time intervals (e.g., weekly or monthly) is another common approach, especially in industries where data changes are predictable. However, combining scheduled retraining with performance-based triggers provides a more robust and adaptive solution.
In summary, key indicators for triggering model retraining include declining performance metrics, detection of data or concept drift, significant business changes, and scheduled intervals. By monitoring these signals, organizations can automate retraining processes and ensure their machine learning models remain accurate, reliable, and aligned with current data.
Data Drift and Concept Drift: How to Detect Changes
Detecting data drift and concept drift is a fundamental step in maintaining the accuracy and reliability of machine learning models. Both types of drift can significantly impact model performance, making it essential to monitor and address them as part of an automatic retraining strategy.
Data drift occurs when the statistical properties of the input data change over time. This might happen due to shifts in user behavior, market trends, or external factors. For example, if a recommendation system’s user base changes demographics, the input data distribution may shift, leading to data drift.
Concept drift refers to changes in the relationship between input features and the target variable. This means that even if the input data looks similar, the way it relates to the outcome can evolve. For instance, in fraud detection, new types of fraudulent behavior may emerge, altering the patterns the model needs to recognize.
To detect data drift, organizations often use statistical tests that compare the distribution of new data with historical data. Techniques like the Kolmogorov-Smirnov test, Population Stability Index (PSI), or monitoring summary statistics (mean, variance) can highlight significant changes in feature distributions.
Detecting concept drift is more challenging, as it involves monitoring the model’s predictive performance over time. A consistent drop in accuracy, precision, or recall may indicate that the relationship between features and labels has changed. Advanced methods, such as drift detection algorithms (e.g., DDM, ADWIN), can help identify concept drift in real time.
Automated monitoring tools integrated into MLOps pipelines can continuously track these metrics and trigger alerts or retraining workflows when drift is detected. This proactive approach ensures that models remain robust and effective, even as data and business environments evolve.
In summary, detecting data drift and concept drift is essential for timely model retraining. By leveraging statistical tests, performance monitoring, and automated tools, organizations can quickly identify changes and maintain high-performing machine learning models.
Scheduling vs. Event-Driven Retraining: Pros and Cons
Choosing the right strategy for automatic model retraining is crucial for maintaining high-performing machine learning systems. Two of the most common approaches are scheduled retraining and event-driven retraining. Each has its own advantages and trade-offs, and the best choice often depends on your business needs, data dynamics, and operational constraints.
Scheduled Retraining
Scheduled retraining involves updating your machine learning models at fixed intervals—such as daily, weekly, or monthly—regardless of changes in data or model performance. This approach is straightforward to implement and ensures that models are regularly refreshed with new data.
Pros:
Simplicity: Easy to automate and manage with standard workflow schedulers (e.g., cron jobs, Airflow).
Predictability: Retraining occurs at known times, making resource planning and compliance reporting easier.
Consistency: Ensures models are always updated, even if performance metrics are not actively monitored.
Cons:
Resource Inefficiency: May retrain models unnecessarily when data hasn’t changed, wasting compute and storage.
Delayed Response: If data or concept drift occurs between scheduled retraining, model performance may degrade before the next update.
Not Adaptive: Lacks responsiveness to sudden changes in data or business environment.
Event-Driven Retraining
Event-driven retraining triggers model updates based on specific events or conditions, such as a drop in model accuracy, detection of data drift, or the arrival of new labeled data. This approach is more dynamic and responsive to real-world changes.
Pros:
Efficiency: Retrains only when needed, saving resources and reducing operational costs.
Timeliness: Quickly adapts to data drift, concept drift, or business changes, maintaining model accuracy.
Automation: Can be fully integrated with monitoring systems for hands-off operation.
Cons:
Complexity: Requires robust monitoring and alerting infrastructure to detect retraining triggers.
Potential for Overfitting: Frequent retraining on small or noisy data changes can lead to instability.
Implementation Overhead: More challenging to set up and maintain, especially in legacy systems.
Which Approach Should You Choose?
Many organizations combine both strategies: scheduled retraining as a safety net, with event-driven retraining for rapid response to critical changes. The optimal solution depends on your data volatility, business requirements, and available infrastructure.
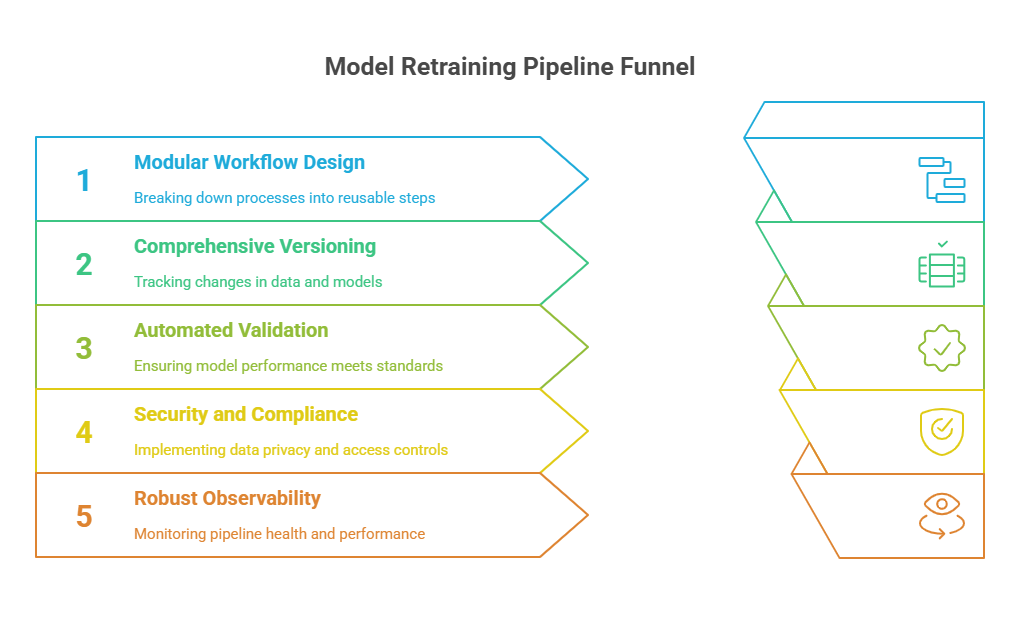
Best Practices for Automating Model Retraining Pipelines
Automating model retraining pipelines is essential for maintaining reliable, scalable, and efficient machine learning systems. By following best practices, organizations can ensure that retraining processes are robust, reproducible, and aligned with business goals.
A key best practice is to design retraining pipelines as modular, reusable workflows. This means separating data ingestion, preprocessing, feature engineering, model training, evaluation, and deployment into distinct, well-defined steps. Using workflow orchestration tools like Apache Airflow, Kubeflow Pipelines, or Prefect helps manage dependencies and automate complex retraining processes.
Versioning is another critical aspect. Always track versions of datasets, features, code, and models. This enables reproducibility, simplifies debugging, and ensures that you can roll back to previous states if issues arise. Integrating a model registry and data versioning tools (such as MLflow, DVC, or LakeFS) into your pipeline is highly recommended.
Automated monitoring and validation should be built into every retraining workflow. Before deploying a newly trained model, validate its performance against a holdout dataset and compare it to the current production model. Only promote the new model if it meets or exceeds predefined performance thresholds. This helps prevent performance regressions and ensures that only high-quality models reach production.
Security and compliance are also important. Automate checks for data privacy, access controls, and audit logging throughout the retraining process. This is especially crucial in regulated industries, where traceability and accountability are required.
Finally, make your retraining pipelines observable and maintainable. Implement logging, alerting, and dashboards to monitor pipeline health, resource usage, and model performance. This allows teams to quickly detect and resolve issues, minimizing downtime and operational risk.
In summary, the best practices for automating model retraining pipelines include modular workflow design, comprehensive versioning, automated validation, strong security and compliance, and robust observability. By following these guidelines, organizations can build reliable, scalable, and efficient retraining systems that keep machine learning models accurate and production-ready.
Tools and Frameworks for Automatic Model Retraining
The landscape of tools and frameworks for automatic model retraining has evolved significantly, offering organizations various options to implement robust and scalable retraining pipelines. Choosing the right combination of tools depends on your infrastructure, team expertise, and specific requirements.
MLflow is one of the most popular open-source platforms for managing the complete machine learning lifecycle, including automatic retraining. It provides experiment tracking, model registry, and deployment capabilities, making it easy to automate retraining workflows and maintain model versions.
Kubeflow Pipelines offers a comprehensive solution for building and deploying portable, scalable ML workflows on Kubernetes. It’s particularly well-suited for organizations already using Kubernetes infrastructure and provides excellent integration with cloud-native tools.
Apache Airflow is a powerful workflow orchestration platform that can be used to schedule and monitor complex retraining pipelines. Its flexibility and extensive plugin ecosystem make it a popular choice for data engineering teams.
AWS SageMaker, Google Cloud AI Platform, and Azure Machine Learning provide cloud-native solutions with built-in support for automatic retraining, model monitoring, and deployment. These platforms offer managed services that reduce operational overhead.
Here’s a practical example of implementing automatic model retraining using MLflow and scikit-learn:
python
import mlflow
import mlflow.sklearn
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from sklearn.datasets import make_classification
import logging
from datetime import datetime
import joblib
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class AutoRetrainingPipeline:
def __init__(self, model_name="fraud_detection_model",
performance_threshold=0.85, drift_threshold=0.1):
self.model_name = model_name
self.performance_threshold = performance_threshold
self.drift_threshold = drift_threshold
self.current_model = None
self.current_performance = None
def load_current_model(self):
"""Load the current production model from MLflow registry"""
try:
client = mlflow.tracking.MlflowClient()
model_version = client.get_latest_versions(
self.model_name, stages=["Production"]
)[0]
model_uri = f"models:/{self.model_name}/{model_version.version}"
self.current_model = mlflow.sklearn.load_model(model_uri)
# Get current model performance from MLflow
run = client.get_run(model_version.run_id)
self.current_performance = run.data.metrics.get('accuracy', 0.0)
logger.info(f"Loaded model version {model_version.version} "
f"with accuracy: {self.current_performance}")
return True
except Exception as e:
logger.warning(f"No production model found: {e}")
return False
def detect_data_drift(self, new_data, reference_data):
"""Simple data drift detection using statistical comparison"""
from scipy import stats
drift_detected = False
drift_features = []
for column in new_data.columns:
if column in reference_data.columns:
# Kolmogorov-Smirnov test for distribution comparison
statistic, p_value = stats.ks_2samp(
reference_data[column], new_data[column]
)
if p_value < 0.05: # Significant difference detected
drift_detected = True
drift_features.append(column)
logger.warning(f"Data drift detected in feature: {column}")
return drift_detected, drift_features
def train_new_model(self, X_train, y_train, X_val, y_val):
"""Train a new model and log it with MLflow"""
with mlflow.start_run() as run:
# Log parameters
mlflow.log_param("algorithm", "RandomForest")
mlflow.log_param("n_estimators", 100)
mlflow.log_param("max_depth", 10)
mlflow.log_param("training_timestamp", datetime.now().isoformat())
# Train model
model = RandomForestClassifier(
n_estimators=100,
max_depth=10,
random_state=42
)
model.fit(X_train, y_train)
# Evaluate model
y_pred = model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
# Log metrics
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("training_samples", len(X_train))
mlflow.log_metric("validation_samples", len(X_val))
# Log model
mlflow.sklearn.log_model(
model,
"model",
registered_model_name=self.model_name
)
logger.info(f"New model trained with accuracy: {accuracy}")
return model, accuracy, run.info.run_id
def should_retrain(self, new_performance, drift_detected):
"""Determine if retraining is needed based on performance and drift"""
performance_degraded = (
self.current_performance is not None and
new_performance < self.current_performance - 0.05
)
below_threshold = new_performance < self.performance_threshold
return performance_degraded or below_threshold or drift_detected
def promote_model(self, run_id):
"""Promote the new model to production"""
client = mlflow.tracking.MlflowClient()
# Get the model version from the run
model_versions = client.search_model_versions(
f"name='{self.model_name}' and run_id='{run_id}'"
)
if model_versions:
version = model_versions[0].version
# Transition current production model to archived
try:
current_prod = client.get_latest_versions(
self.model_name, stages=["Production"]
)
if current_prod:
client.transition_model_version_stage(
name=self.model_name,
version=current_prod[0].version,
stage="Archived"
)
except:
pass
# Promote new model to production
client.transition_model_version_stage(
name=self.model_name,
version=version,
stage="Production"
)
logger.info(f"Model version {version} promoted to production")
def run_retraining_pipeline(self, new_data_path, reference_data_path=None):
"""Main pipeline for automatic model retraining"""
logger.info("Starting automatic retraining pipeline...")
# Load data
new_data = pd.read_csv(new_data_path)
X = new_data.drop('target', axis=1)
y = new_data['target']
# Split data
X_train, X_val, y_train, y_val = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Load current model
has_current_model = self.load_current_model()
# Check for data drift if reference data is provided
drift_detected = False
if reference_data_path and has_current_model:
reference_data = pd.read_csv(reference_data_path)
drift_detected, drift_features = self.detect_data_drift(
X, reference_data.drop('target', axis=1)
)
# Evaluate current model performance on new data
current_performance = 0.0
if has_current_model:
y_pred_current = self.current_model.predict(X_val)
current_performance = accuracy_score(y_val, y_pred_current)
logger.info(f"Current model performance on new data: {current_performance}")
# Train new model
new_model, new_performance, run_id = self.train_new_model(
X_train, y_train, X_val, y_val
)
# Decide whether to retrain/promote
if self.should_retrain(new_performance, drift_detected):
if new_performance > current_performance:
self.promote_model(run_id)
logger.info("Model successfully retrained and promoted!")
else:
logger.warning("New model performance is not better. Keeping current model.")
else:
logger.info("No retraining needed. Current model is performing well.")
# Example usage
if __name__ == "__main__":
# Generate sample data for demonstration
X, y = make_classification(
n_samples=1000, n_features=10, n_informative=5,
n_redundant=2, random_state=42
)
# Create sample datasets
sample_data = pd.DataFrame(X, columns=[f'feature_{i}' for i in range(10)])
sample_data['target'] = y
sample_data.to_csv('new_data.csv', index=False)
sample_data.to_csv('reference_data.csv', index=False)
# Set MLflow tracking URI (use local for demo)
mlflow.set_tracking_uri("sqlite:///mlflow.db")
# Initialize and run pipeline
pipeline = AutoRetrainingPipeline()
pipeline.run_retraining_pipeline('new_data.csv', 'reference_data.csv')
# Created/Modified files during execution:
print("new_data.csv")
print("reference_data.csv")
print("mlflow.db")This comprehensive example demonstrates how to build an automated retraining pipeline using MLflow, incorporating data drift detection, model evaluation, and automated promotion. The pipeline can be easily extended with additional monitoring capabilities and integrated with workflow orchestration tools like Airflow for production deployment.
Other notable tools include Weights & Biases for experiment tracking, DVC for data versioning, Feast for feature stores, and Evidently AI for model monitoring and drift detection. The key is to choose tools that integrate well with your existing infrastructure and provide the scalability and reliability your organization needs.
Monitoring Model Performance After Retraining
Monitoring model performance after retraining is a critical step in any automated machine learning pipeline. Even after a model has been retrained and deployed, its real-world performance can fluctuate due to changing data patterns, user behavior, or external factors. Without robust monitoring, organizations risk deploying models that degrade over time, leading to poor business outcomes or even compliance issues.
The first aspect of post-retraining monitoring is tracking key performance metrics such as accuracy, precision, recall, F1-score, or business-specific KPIs. These metrics should be calculated on both validation data during retraining and on live production data after deployment. Comparing these values helps detect issues like overfitting or data leakage that might not be apparent during offline evaluation.
Another important practice is monitoring for data drift and concept drift in production. This involves continuously comparing the distribution of incoming data and model predictions to historical baselines. Tools like Evidently AI, WhyLabs, or custom statistical tests can automate this process, triggering alerts or even rolling back deployments if significant drift is detected.
Latency and resource usage are also important to monitor, especially for models serving real-time predictions. Unexpected increases in response time or memory consumption can indicate problems with the retrained model or changes in the input data.
Automated alerting is essential. Set up thresholds for key metrics and configure notifications for data scientists or MLOps engineers when these thresholds are breached. This enables rapid response to performance degradation and minimizes business impact.
Finally, all monitoring data should be logged and visualized using dashboards (e.g., Grafana, Kibana, or cloud-native solutions). This provides transparency, supports root-cause analysis, and helps with compliance and auditing requirements.
In summary, effective monitoring after retraining involves tracking performance metrics, detecting drift, observing resource usage, and setting up automated alerts and dashboards. This ensures that retrained models continue to deliver value and remain trustworthy in production environments.
Challenges and Pitfalls in Automatic Model Retraining
Implementing automatic model retraining brings significant benefits, but it also introduces complex challenges that can undermine the reliability and effectiveness of machine learning systems. Understanding these pitfalls is crucial for building robust, production-ready retraining pipelines.
One of the most common challenges is data quality degradation. Automatic retraining systems often assume that new data maintains the same quality standards as the original training data. However, data sources can change over time, introducing missing values, outliers, or inconsistent formats. Without proper data validation, models may be retrained on corrupted data, leading to performance degradation rather than improvement.
Concept drift presents another significant challenge. While automatic retraining can help adapt to gradual changes in data patterns, sudden or complex concept shifts may require human intervention and model architecture changes. Blindly retraining on new data without understanding the underlying changes can result in models that perform poorly on edge cases or fail to capture new business logic.
Resource management is often underestimated. Automatic retraining can consume substantial computational resources, especially for large models or frequent retraining schedules. Without proper resource planning and cost monitoring, organizations may face unexpected infrastructure costs or system performance issues that impact other critical services.
Model stability is another critical concern. Frequent retraining can lead to inconsistent model behavior, where predictions for the same input vary significantly between model versions. This instability can confuse users, break downstream systems, or violate regulatory requirements that demand consistent decision-making processes.
Testing and validation become more complex in automatic retraining scenarios. Traditional A/B testing approaches may not be sufficient when models are constantly changing. Organizations need sophisticated testing frameworks that can validate model performance across different time periods, user segments, and edge cases before promoting new models to production.
Regulatory compliance poses unique challenges, particularly in highly regulated industries like finance or healthcare. Automatic retraining must maintain audit trails, ensure model explainability, and comply with fairness requirements. Changes in model behavior must be documented and justified, which can be difficult when retraining happens automatically without human oversight.
Feedback loops can create unexpected problems. If model predictions influence the data collection process, automatic retraining may amplify biases or create self-reinforcing patterns that degrade model performance over time. For example, a recommendation system that retrains on user interactions may become increasingly narrow in its suggestions.
Finally, monitoring complexity increases significantly with automatic retraining. Teams must track not only model performance but also retraining frequency, resource usage, data quality metrics, and the impact of model changes on business outcomes. This requires sophisticated monitoring infrastructure and skilled personnel to interpret the results.
To mitigate these challenges, organizations should implement comprehensive data validation, establish clear retraining triggers and thresholds, maintain robust testing frameworks, ensure regulatory compliance from the start, and invest in monitoring and alerting systems. Most importantly, automatic retraining should complement, not replace, human expertise and oversight in critical machine learning applications.
Case Study: Automated Retraining in a Real-World Production System
Automated model retraining is no longer just a theoretical best practice—it’s a necessity for organizations that rely on machine learning in dynamic, data-rich environments. To illustrate how this works in practice, let’s look at a real-world case study from the e-commerce sector, where a company implemented an automated retraining pipeline for its product recommendation engine.
Business Context
The company’s recommendation system was initially trained on historical user interactions, product metadata, and seasonal trends. Over time, however, user preferences shifted, new products were introduced, and shopping behaviors evolved. The static model began to lose accuracy, resulting in less relevant recommendations and a noticeable drop in user engagement.
Solution: Automated Retraining Pipeline
To address this, the data science and MLOps teams designed an automated retraining pipeline with the following key components:
Data Ingestion and Validation: New user interaction data was ingested daily from multiple sources. Automated validation checks were implemented to catch missing values, schema changes, and outliers before retraining began.
Feature Engineering: The pipeline automatically generated new features based on recent user activity, product launches, and trending categories, ensuring the model stayed relevant.
Model Training and Evaluation: Each week, the pipeline triggered a retraining job using the latest validated data. The new model was evaluated on a holdout set and compared to the current production model using metrics like click-through rate (CTR) and mean reciprocal rank (MRR).
Model Registry and Promotion: If the retrained model outperformed the current one, it was automatically registered and promoted to production using a model registry (MLflow). Otherwise, the existing model remained active.
Monitoring and Alerting: Post-deployment, the system continuously monitored key metrics and data drift. Alerts were sent to the MLOps team if performance dropped or if unusual data patterns were detected.
Results
The automated retraining pipeline led to several tangible benefits. The recommendation engine’s relevance improved, as measured by a 12% increase in CTR and a 9% boost in average order value. The system adapted quickly to new products and changing user preferences, reducing the lag between market shifts and model updates. Operationally, the data science team spent less time on manual retraining and more on innovation, as the pipeline handled routine updates and monitoring.
Lessons Learned
Several lessons emerged from this implementation. First, robust data validation was essential—early versions of the pipeline occasionally retrained on corrupted data, leading to performance drops. Second, automated monitoring and alerting were critical for catching issues quickly and maintaining trust in the system. Finally, while automation streamlined operations, human oversight remained important for interpreting edge cases and making strategic decisions about model updates.
Best Practices for Maintaining Retraining Pipelines
Maintaining robust and reliable retraining pipelines is essential for ensuring that machine learning models remain accurate, relevant, and trustworthy in production. As organizations scale their ML operations, the complexity of these pipelines increases, making best practices even more critical. Here’s a comprehensive look at the most important principles for maintaining retraining pipelines in real-world environments.
1. Automate, but Don’t Eliminate Human Oversight
Automation is the backbone of modern retraining pipelines, enabling frequent updates and rapid adaptation to new data. However, full automation without human checks can be risky. Always include checkpoints for human review—especially when significant performance changes, data anomalies, or unexpected behaviors are detected. This hybrid approach balances efficiency with safety.
2. Implement Rigorous Data Validation
Data is the foundation of every retraining cycle. Before any retraining job starts, validate incoming data for schema consistency, missing values, outliers, and distribution shifts. Automated validation scripts should halt the pipeline if critical issues are found, preventing the propagation of bad data into new models.
3. Track Data and Model Lineage
Maintain detailed records of which data, features, and code versions were used for each retraining run. Tools like MLflow, DVC, or cloud-native solutions can help track lineage, making it easier to reproduce results, debug issues, and comply with regulatory requirements.
4. Monitor Model and Pipeline Performance
Set up continuous monitoring for both model performance (e.g., accuracy, precision, recall, business KPIs) and pipeline health (e.g., job success rates, resource usage, latency). Use dashboards and automated alerts to quickly detect and respond to problems, minimizing downtime and business impact.
5. Use Version Control for Code and Configurations
Store all pipeline code, configuration files, and infrastructure-as-code scripts in version control systems like Git. This ensures that changes are tracked, rollbacks are possible, and collaboration is streamlined across teams.
6. Establish Clear Retraining Triggers
Define explicit criteria for when retraining should occur. Triggers can be time-based (e.g., weekly), event-based (e.g., significant data drift), or performance-based (e.g., drop in key metrics). Clear triggers prevent unnecessary retraining and ensure timely updates when needed.
7. Test Extensively Before Promotion
Before deploying a retrained model to production, run comprehensive tests—including unit tests, integration tests, and shadow deployments. Compare new model predictions with the current model on live or historical data to catch regressions or unexpected behaviors.
8. Document Everything
Maintain thorough documentation for your retraining pipeline architecture, data sources, validation rules, retraining triggers, and monitoring strategies. Good documentation accelerates onboarding, troubleshooting, and compliance audits.
9. Plan for Rollbacks and Failures
No pipeline is perfect. Design your system to support easy rollbacks to previous model versions if issues are detected post-deployment. Automate rollback procedures where possible and ensure that monitoring can quickly trigger these actions.
10. Foster Collaboration Between Teams
Retraining pipelines often span data engineering, data science, DevOps, and business teams. Encourage regular communication, shared ownership, and clear escalation paths to resolve issues efficiently and continuously improve the pipeline.
Feature Stores in Large-Scale ML Systems