
Introduction: Why Advanced Testing Matters in ML
In the rapidly evolving world of machine learning, deploying models to production is just the beginning. Ensuring that these models are accurate, reliable, and robust over time requires a comprehensive testing strategy that goes far beyond simple validation datasets. This is where advanced testing becomes essential.
Traditional software testing focuses on verifying code correctness and functionality. In machine learning, however, testing must also address the unique challenges of data, model behavior, and complex interactions between components. Advanced testing in ML involves a multi-layered approach that includes unit tests, integration tests, and end-to-end tests, each designed to catch different types of issues.
Why Advanced Testing Matters
Data Quality: ML models are highly sensitive to data quality. Advanced testing helps detect data drift, anomalies, and inconsistencies that can degrade model performance.
Model Robustness: Testing ensures that models are resilient to noisy inputs, adversarial attacks, and unexpected edge cases.
Reproducibility: Robust testing frameworks enable teams to reproduce experiments, validate results, and maintain a clear audit trail.
Compliance and Trust: In regulated industries, advanced testing supports compliance with data privacy laws and builds trust with stakeholders.
Scalability: Automated testing allows teams to iterate quickly and deploy new models with confidence, even as the complexity of their ML systems grows.
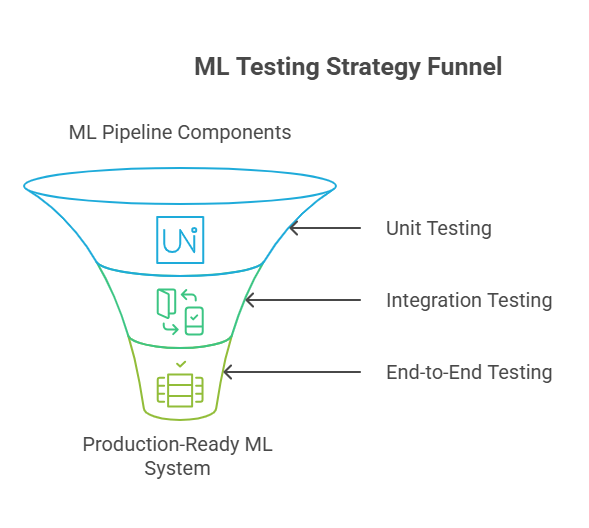
Overview of Testing Levels in Machine Learning
Testing in machine learning is fundamentally different from traditional software testing. While software testing focuses on code correctness and system integration, ML testing must address the unique challenges of data variability, model behavior, and the complex interactions between data, code, and infrastructure. To ensure robust, reliable, and production-ready ML systems, it’s essential to adopt a multi-level testing strategy.
Unit Testing in ML
Unit tests focus on the smallest components of the ML pipeline—such as data preprocessing functions, feature engineering scripts, or custom loss functions. These tests verify that individual units of code behave as expected, handle edge cases, and produce consistent outputs for given inputs. Unit testing helps catch bugs early, before they propagate through the pipeline.
Integration Testing
Integration tests validate that different components of the ML workflow work together correctly. This includes checking that data flows smoothly from ingestion to feature engineering, that models can be trained and evaluated with the expected data formats, and that outputs from one stage are compatible with the next. Integration testing is crucial for detecting issues that arise from changes in data schemas, pipeline dependencies, or third-party libraries.
End-to-End Testing
End-to-end (E2E) tests simulate the entire ML workflow, from raw data ingestion to final predictions or business outcomes. These tests validate the full pipeline in an environment that closely mirrors production, ensuring that all components—data sources, models, APIs, and downstream systems—work together seamlessly. E2E testing is essential for catching issues that only appear when the system is running as a whole, such as data drift, model staleness, or integration failures.
Unit Testing for ML Models: What and How to Test
Unit testing is the foundation of robust machine learning development. In the context of ML, unit tests focus on verifying the correctness of individual components—such as data preprocessing functions, feature engineering scripts, custom loss functions, and even small model modules—before they are integrated into larger pipelines. Well-designed unit tests catch bugs early, ensure code quality, and make it easier to refactor or extend ML systems with confidence.
What to Unit Test in ML Projects
Data Preprocessing Functions:
Test that functions for cleaning, normalizing, or transforming data handle edge cases (e.g., missing values, outliers) and produce expected outputs for known inputs.
Feature Engineering Scripts:
Verify that new features are computed correctly and consistently, and that feature selection logic works as intended.
Custom Model Components:
For custom layers, loss functions, or activation functions, ensure mathematical correctness and compatibility with the rest of the model.
Utility Functions:
Test helper functions for metrics calculation, data splitting, or configuration parsing.
How to Write Unit Tests for ML Code
Use standard testing frameworks like pytest or unittest in Python.
Create small, focused test cases with clear input and expected output.
Mock external dependencies (e.g., file I/O, database calls) to isolate the unit under test.
Include tests for both typical and edge-case scenarios.
Example: Unit Test for a Data Preprocessing Function
python
import pytest
import numpy as np
def normalize(x):
"""Simple normalization function."""
return (x - np.mean(x)) / np.std(x)
def test_normalize_basic():
arr = np.array([1, 2, 3, 4, 5])
result = normalize(arr)
assert np.isclose(np.mean(result), 0)
assert np.isclose(np.std(result), 1)
def test_normalize_edge_case():
arr = np.array([5, 5, 5, 5, 5])
with pytest.raises(ZeroDivisionError):
normalize(arr)
if __name__ == "__main__":
pytest.main([__file__])Integration Testing: Ensuring Pipeline and Component Compatibility
Integration testing is a critical step in advanced ML model testing, bridging the gap between isolated unit tests and full end-to-end validation. In the context of machine learning, integration tests verify that different components of your pipeline—such as data ingestion, preprocessing, feature engineering, model training, and prediction—work together as expected. This level of testing helps catch issues that arise from changes in data formats, dependencies, or the interaction between modules.
Why Integration Testing Matters in ML
Detects Data and Schema Mismatches:
Integration tests ensure that the output of one pipeline stage is compatible with the input of the next, catching issues like missing columns, type mismatches, or unexpected data shapes.
Validates Pipeline Logic:
They confirm that the entire workflow—from raw data to model output—runs smoothly, even as individual components evolve.
Prevents Regression Bugs:
When updating a feature engineering script or retraining a model, integration tests help ensure that new changes don’t break downstream processes.
What to Test in ML Integration Tests
Data flows correctly from ingestion to preprocessing and feature engineering.
Feature sets are consistent and complete for model training and inference.
Model training and evaluation steps execute without errors on real or mock data.
Prediction APIs or batch scoring jobs return expected results when given valid inputs.
Example: Integration Test for a Simple ML Pipeline
python
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
def preprocess(df):
df = df.copy()
df['feature_sum'] = df['feature1'] + df['feature2']
return df
def train_and_predict(df):
X = df[['feature1', 'feature2', 'feature_sum']]
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
model = RandomForestClassifier(n_estimators=10, random_state=42)
model.fit(X_train, y_train)
preds = model.predict(X_test)
return preds, y_test
def test_pipeline_integration():
# Simulate raw data
data = pd.DataFrame({
'feature1': [1, 2, 3, 4, 5],
'feature2': [5, 4, 3, 2, 1],
'target': [0, 1, 0, 1, 0]
})
# Run preprocessing
processed = preprocess(data)
# Train and predict
preds, y_test = train_and_predict(processed)
# Check output length and type
assert len(preds) == len(y_test)
print("Integration test passed!")
if __name__ == "__main__":
test_pipeline_integration()End-to-End Testing: Validating the Full ML Workflow
End-to-end (E2E) testing is the gold standard for validating machine learning systems in real-world scenarios. Unlike unit or integration tests, which focus on individual components or their interactions, E2E tests simulate the entire ML workflow—from raw data ingestion to final predictions and business outcomes. This comprehensive approach ensures that every part of the pipeline works together as expected and that the system delivers reliable results in production.
Why End-to-End Testing Matters in ML
Catches Systemic Issues: E2E tests reveal problems that only appear when the full pipeline is exercised, such as data drift, model staleness, or integration failures with external systems.
Validates Business Logic: They confirm that the ML system meets business requirements, not just technical ones, by testing real-world use cases and expected outputs.
Ensures Deployment Readiness: E2E tests provide confidence that the system will perform reliably after deployment, reducing the risk of costly production incidents.
What to Include in ML End-to-End Tests
Data Ingestion: Simulate the arrival of new raw data from real sources.
Preprocessing and Feature Engineering: Run the full transformation pipeline on the new data.
Model Training and Validation: Train the model on the processed data and validate its performance.
Deployment and Inference: Deploy the model (even if only in a test environment) and make predictions on new data.
Output Validation: Compare predictions to expected results or business KPIs.
Example: Simple End-to-End Test for an ML Pipeline
python
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
def ingest_data():
# Simulate raw data ingestion
return pd.DataFrame({
'feature1': [1, 2, 3, 4, 5, 6],
'feature2': [6, 5, 4, 3, 2, 1],
'target': [0, 1, 0, 1, 0, 1]
})
def preprocess(df):
df = df.copy()
df['feature_sum'] = df['feature1'] + df['feature2']
return df
def train_and_evaluate(df):
X = df[['feature1', 'feature2', 'feature_sum']]
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
model = RandomForestClassifier(n_estimators=10, random_state=42)
model.fit(X_train, y_train)
preds = model.predict(X_test)
acc = accuracy_score(y_test, preds)
return acc
def end_to_end_test():
data = ingest_data()
processed = preprocess(data)
accuracy = train_and_evaluate(processed)
assert accuracy >= 0.5, f"Accuracy too low: {accuracy}"
print(f"End-to-end test passed! Accuracy: {accuracy:.2f}")
if __name__ == "__main__":
end_to_end_test()Tools and Frameworks for ML Model Testing
Choosing the right tools and frameworks is crucial for implementing effective testing strategies in machine learning projects. The right stack enables teams to automate unit, integration, and end-to-end tests, ensuring that models and pipelines are robust, reproducible, and production-ready.
Popular Tools for ML Model Testing
pytest: The go-to testing framework for Python, widely used for unit and integration tests in ML code. It supports fixtures, parameterization, and easy test discovery.
unittest: Python’s built-in testing library, suitable for basic unit tests and compatible with most CI/CD systems.
Great Expectations: An open-source tool for data validation and testing, allowing teams to define, execute, and document data quality checks as part of their pipelines.
MLflow: While primarily an experiment tracking and model registry tool, MLflow supports automated testing of model performance and reproducibility.
DVC (Data Version Control): Enables versioning and testing of data and model artifacts, ensuring that tests are always run on the correct versions.
pytest-mock, unittest.mock: Useful for mocking external dependencies and isolating units of code during testing.
Testinfra: For infrastructure and environment validation, ensuring that ML pipelines run in the correct setup.
Seldon Core, KFServing: For testing model serving and deployment in Kubernetes environments, including canary and A/B testing.
Example: Using pytest for a Simple ML Unit Test
python
import pytest
from sklearn.preprocessing import StandardScaler
import numpy as np
def test_standard_scaler():
X = np.array([[1.0, 2.0], [3.0, 4.0]])
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Mean should be close to 0, std close to 1
assert np.allclose(X_scaled.mean(axis=0), 0)
assert np.allclose(X_scaled.std(axis=0), 1)
if __name__ == "__main__":
pytest.main([__file__])Automating ML Tests in CI/CD Pipelines
Automating machine learning tests in CI/CD pipelines is a best practice that ensures every code, data, or model change is validated before reaching production. This approach brings the rigor of software engineering to ML workflows, catching issues early and enabling rapid, reliable deployments.
Why Automate ML Tests in CI/CD?
Early Bug Detection: Automated tests catch errors in data preprocessing, feature engineering, model training, and inference before they impact users.
Reproducibility: CI/CD ensures that tests run in consistent, isolated environments, reducing “it works on my machine” problems.
Faster Iteration: Developers and data scientists get immediate feedback, enabling quicker experimentation and safer releases.
Compliance and Auditability: Automated logs and test results provide a clear audit trail for regulatory and business requirements.
How to Automate ML Tests in CI/CD
Write Unit, Integration, and End-to-End Tests:
Use frameworks like pytest or unittest for code and pipeline tests, and data validation tools like Great Expectations for data checks.
Integrate with CI/CD Tools:
Configure your pipeline (e.g., GitHub Actions, GitLab CI, Jenkins, Azure DevOps) to run tests automatically on every pull request, commit, or scheduled job.
Automate Model Validation:
Include steps to train models on test data, evaluate performance, and compare metrics to quality gates. Fail the pipeline if thresholds aren’t met.
Mock External Dependencies:
Use mocking libraries to simulate databases, APIs, or cloud services, ensuring tests are fast and reliable.
Store and Visualize Results:
Save test results, logs, and artifacts for review. Use dashboards or CI/CD plugins to visualize test outcomes and trends.
Example: Simple GitHub Actions Workflow for ML Testing
yaml
# .github/workflows/ml-test.yml
name: ML Test Pipeline
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: '3.9'
- name: Install dependencies
run: pip install -r requirements.txt
- name: Run unit and integration tests
run: pytest tests/
- name: Run end-to-end tests
run: python tests/test_e2e.pyMocking and Test Data Strategies for ML
Mocking and test data strategies are essential for effective and reliable machine learning testing. They enable teams to isolate components, simulate edge cases, and validate ML pipelines without relying on production data or external systems. By using mocks and well-designed test datasets, you can catch bugs early, ensure reproducibility, and accelerate development.
Why Mocking Matters in ML Testing
Isolation: Mocking allows you to test individual functions or pipeline steps without depending on databases, APIs, or cloud services.
Speed: Tests run faster when they don’t need to access large datasets or external resources.
Safety: Using synthetic or anonymized test data prevents accidental exposure of sensitive information.
Edge Case Simulation: Mocks and custom test data make it easy to simulate rare or problematic scenarios that may not be present in real data.
Common Mocking and Test Data Techniques
Mocking Data Sources: Use libraries like unittest.mock or pytest-mock to simulate database queries, API responses, or file reads.
Synthetic Data Generation: Create small, controlled datasets with known properties using tools like numpy, pandas, or scikit-learn’s make_classification.
Fixture Files: Store sample CSV, JSON, or Parquet files in your test directory for repeatable tests.
Parameterized Tests: Use test frameworks to run the same test logic on multiple datasets or input scenarios.
Example: Mocking a Data Loader in Python
python
from unittest.mock import patch
import pandas as pd
def load_data_from_db():
# Simulate a database call (would be replaced in production)
raise NotImplementedError("This should connect to a real database.")
def preprocess_data(df):
df['feature_sum'] = df['feature1'] + df['feature2']
return df
def test_preprocess_with_mocked_data():
# Create synthetic test data
test_df = pd.DataFrame({'feature1': [1, 2], 'feature2': [3, 4]})
# Mock the data loading function
with patch('__main__.load_data_from_db', return_value=test_df):
df = load_data_from_db()
processed = preprocess_data(df)
assert (processed['feature_sum'] == [4, 6]).all()
print("Mocked data test passed!")
if __name__ == "__main__":
test_preprocess_with_mocked_data()Monitoring and Alerting for Test Failures in Production
Monitoring and alerting for test failures in production is a critical aspect of advanced ML model testing. While pre-deployment tests catch most issues, real-world data and changing environments can still cause unexpected failures after deployment. Proactive monitoring and automated alerts ensure that teams can detect, diagnose, and resolve problems before they impact users or business outcomes.
Why Monitor Tests in Production?
Data Drift and Model Degradation: Even a well-tested model can fail if the input data distribution changes or if the model becomes stale.
Pipeline Failures: Data ingestion, feature engineering, or serving components may break due to upstream changes or infrastructure issues.
Silent Errors: Some failures may not trigger obvious errors but can degrade model performance or business KPIs over time.
What to Monitor
Model Performance Metrics: Track accuracy, precision, recall, F1-score, and business KPIs on live data.
Data Quality Checks: Monitor for missing values, outliers, schema changes, and feature drift.
Pipeline Health: Watch for failed jobs, increased latency, or resource bottlenecks.
Test Assertions: Run automated “canary” or shadow tests on production data to validate model predictions and pipeline outputs.
Automated Alerting
Set up automated alerts for:
Performance drops below defined thresholds
Data validation failures or schema mismatches
Pipeline or job failures
Anomalies in prediction distributions or feature statistics
Alerts can be sent via email, Slack, PagerDuty, or integrated with incident management systems for rapid response.
Example: Simple Python Alert for Production Test Failure
python
def monitor_production_metrics(current_accuracy, min_threshold=0.85):
if current_accuracy < min_threshold:
send_alert(f"Model accuracy dropped to {current_accuracy:.2f} (threshold: {min_threshold})")
else:
print(f"Model accuracy OK: {current_accuracy:.2f}")
def send_alert(message):
# In production, integrate with email, Slack, or PagerDuty
print(f"ALERT: {message}")
# Example usage
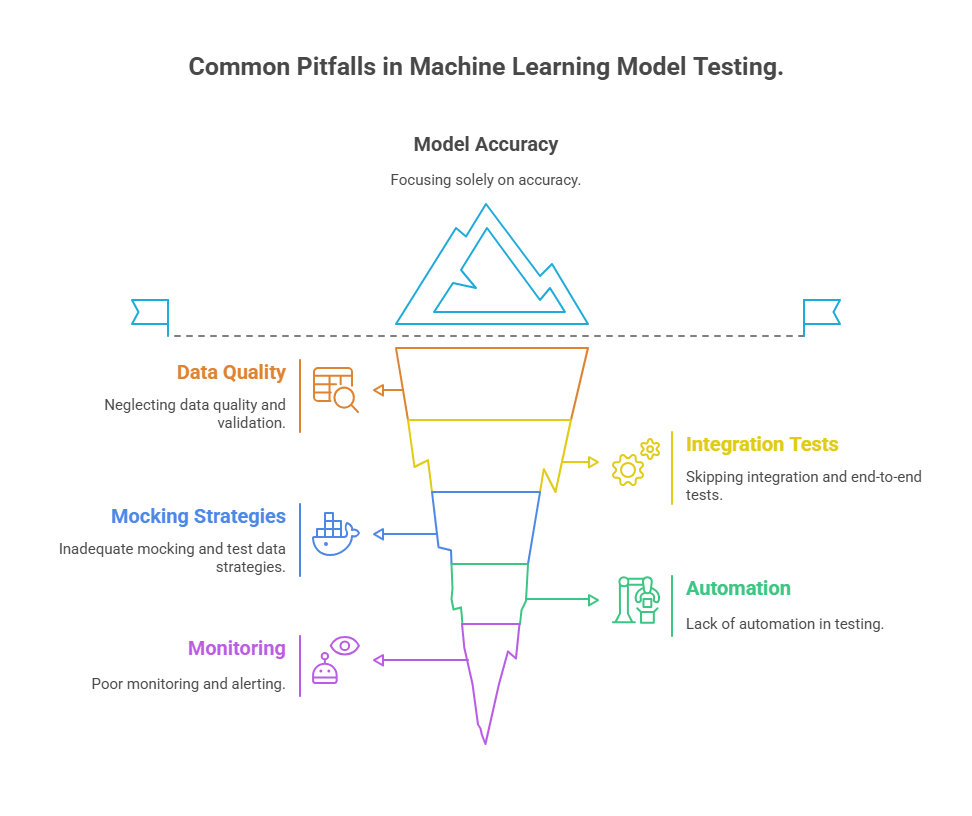
monitor_production_metrics(0.81)Common Pitfalls and How to Avoid Them
Testing machine learning models is a complex process, and even experienced teams can fall into common traps that undermine the reliability and effectiveness of their ML systems. One of the most frequent pitfalls is focusing solely on model accuracy or a single performance metric. While accuracy is important, it can mask deeper issues such as data drift, class imbalance, or poor performance on specific user segments. Relying on a narrow set of metrics may lead to models that look good in testing but fail in real-world scenarios.
Another common mistake is neglecting data quality and validation. If test data is not representative of production data, or if it contains errors and inconsistencies, the results of your tests will be misleading. Data quality issues can silently degrade model performance, making it essential to automate validation checks at every stage of the pipeline. Without robust data validation, even the best model can produce unreliable results.
Skipping integration and end-to-end tests is another pitfall. While unit tests are valuable for catching bugs in individual functions, many issues only emerge when components interact or when the full pipeline is exercised. Integration and end-to-end tests are crucial for ensuring that data flows correctly, features are engineered as expected, and models perform reliably from ingestion to prediction.
Inadequate mocking and test data strategies can also lead to problems. Using production data for tests can be risky and may not cover edge cases or rare scenarios. Poorly designed test data can miss important logic or fail to trigger critical code paths. Creating synthetic or anonymized test data, and mocking external dependencies, helps ensure that tests are both safe and comprehensive.
A lack of automation in testing is a significant risk. Manual testing is time-consuming, error-prone, and doesn’t scale as projects grow. If tests aren’t integrated into your CI/CD pipeline, regressions and bugs are more likely to slip into production. Automated testing at every level—unit, integration, and end-to-end—should be a standard practice.
Finally, poor monitoring and alerting can result in alert fatigue or missed incidents. Too many alerts, or poorly tuned thresholds, can overwhelm teams and cause them to ignore real issues. It’s important to set meaningful, actionable alert thresholds and regularly review them to ensure they remain relevant as your system evolves.
Real-World Examples and Best Practices
Real-world examples of advanced ML model testing highlight how leading organizations ensure reliability, scalability, and trust in their machine learning systems. By adopting best practices and learning from practical experiences, teams can avoid costly mistakes and accelerate their MLOps maturity.
Example 1: E-commerce Personalization
A global e-commerce company implemented a multi-level testing strategy for its recommendation engine. They used unit tests to validate feature engineering scripts, integration tests to ensure data pipelines and model training worked together, and end-to-end tests to simulate the full user journey from data ingestion to personalized recommendations. Automated tests were integrated into their CI/CD pipeline, so every code or data change triggered a full suite of tests before deployment. This approach reduced production incidents, improved model accuracy, and enabled rapid experimentation.
Example 2: Financial Services and Regulatory Compliance
A financial institution needed to comply with strict regulations for credit risk models. They adopted Great Expectations for automated data validation, pytest for unit and integration tests, and MLflow for model versioning and experiment tracking. Every model promotion to production required passing all tests and approval from both data science and compliance teams. Detailed logs and audit trails were maintained for every test run, supporting regulatory audits and internal reviews.
Example 3: Healthcare Predictive Analytics
A healthcare analytics company used synthetic test data and mocking to validate their patient risk prediction models. They ran end-to-end tests that simulated real-world data flows, including edge cases like missing values and outliers. Automated monitoring and alerting were set up to detect performance drops or data drift in production, triggering retraining workflows when needed. This ensured patient safety, model reliability, and compliance with healthcare regulations.
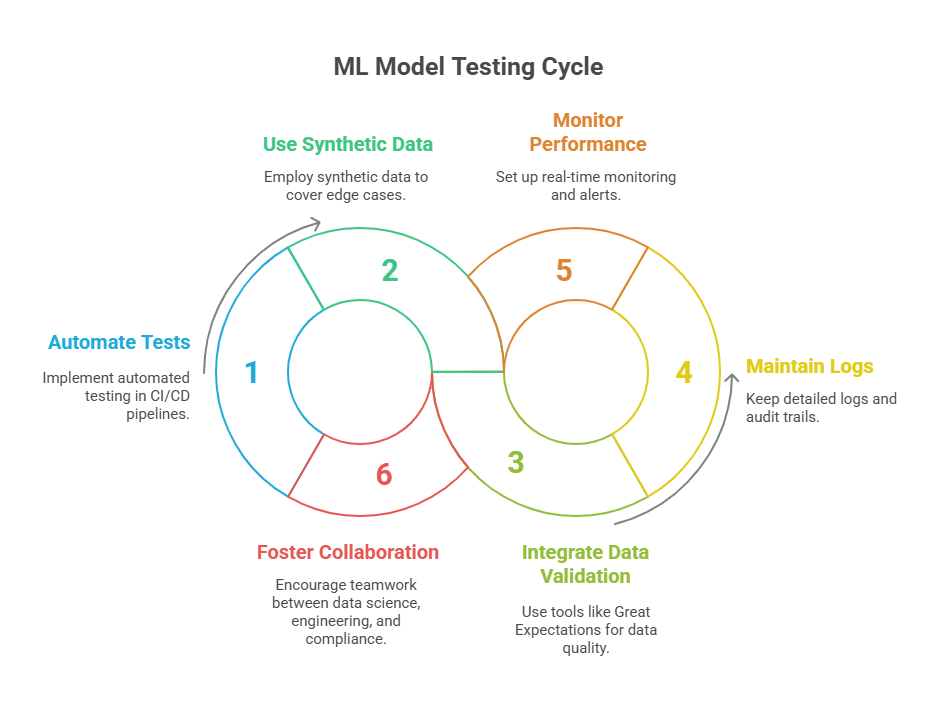
Best Practices from Real-World Deployments
Automate all tests (unit, integration, end-to-end) and run them in CI/CD pipelines.
Use synthetic and anonymized test data to cover edge cases and protect privacy.
Integrate data validation tools (like Great Expectations) to catch data quality issues early.
Maintain detailed logs and audit trails for all test runs and model transitions.
Set up real-time monitoring and alerts for model performance, data drift, and pipeline health.
Foster collaboration between data science, engineering, and compliance teams to ensure robust, production-ready ML systems.
Future Trends in ML Model Testing
As machine learning becomes more deeply embedded in business operations, the field of ML model testing is rapidly evolving. The future of ML testing will be shaped by automation, intelligence, and integration—enabling teams to deliver more reliable, scalable, and trustworthy AI solutions. Here are the key trends to watch:
1. AI-Driven and Self-Healing Testing Pipelines
The next generation of ML testing will leverage AI to automatically generate, execute, and adapt tests. Self-healing pipelines will detect failures, diagnose root causes, and even suggest or implement fixes—reducing manual intervention and accelerating incident response.
2. Continuous and Real-Time Testing
With the rise of streaming data and real-time ML applications, testing will move from batch validation to continuous, in-production monitoring. Automated canary tests, shadow deployments, and live data validation will become standard, ensuring that models remain robust as data and environments change.
3. Deeper Integration with DataOps and MLOps
Testing will be more tightly integrated with DataOps and MLOps workflows. Data validation, model validation, and pipeline health checks will be orchestrated together, providing end-to-end assurance from raw data to business outcomes. Unified dashboards and alerting will enable rapid detection and resolution of issues across the entire ML lifecycle.
4. Explainability and Fairness Testing
As regulations and ethical standards evolve, explainability and fairness will become first-class citizens in ML testing. Automated tests will check for bias, drift, and compliance with explainability requirements, ensuring that models are not only accurate but also transparent and equitable.
5. Test Data Management and Synthetic Data Generation
Managing high-quality, privacy-preserving test data will be a major focus. Tools for generating synthetic data, anonymizing sensitive information, and simulating rare edge cases will become essential for comprehensive testing.
6. Edge and Federated ML Testing
With the growth of edge computing and federated learning, testing frameworks will need to support distributed, decentralized environments. This includes validating models on edge devices, monitoring performance across heterogeneous hardware, and ensuring consistency in federated updates.
7. Cost and Resource Optimization in Testing
Future ML testing platforms will provide insights into test coverage, resource usage, and cost, helping teams optimize their testing strategies and infrastructure spend.
MLOps: Enterprise Practices for Developers
Monitoring ML models in production: tools, challenges, and best practices
MLOps in Practice: Automation and Scaling of the Machine Learning Lifecycle