

Introduction: Why Large-Scale MLOps Matters in the Enterprise
In recent years, machine learning has moved from experimental projects to the very core of enterprise operations. Companies in finance, retail, healthcare, and many other sectors are leveraging ML models to automate decision-making, personalize customer experiences, and gain a competitive edge. However, as organizations scale up their use of machine learning, they quickly discover that managing dozens or even hundreds of models in production is a completely different challenge than running a single proof-of-concept.
This is where large-scale MLOps (Machine Learning Operations) becomes essential. MLOps is the set of practices and tools that enable organizations to reliably build, deploy, monitor, and maintain ML models at scale. In the enterprise context, MLOps is not just about automation—it’s about creating robust, repeatable, and secure processes that can handle the complexity of real-world data, regulatory requirements, and the need for rapid innovation.
The importance of large-scale MLOps in the enterprise can be summarized in several key points. First, it ensures consistency and reliability across multiple teams and projects, reducing the risk of errors and model failures. Second, it enables faster time-to-market by automating repetitive tasks such as data preprocessing, model training, and deployment. Third, it supports compliance and governance, which are critical in regulated industries like finance and healthcare. Finally, large-scale MLOps provides the foundation for continuous improvement, allowing organizations to monitor model performance, detect drift, and retrain models as needed.
In summary, without a mature MLOps strategy, enterprises risk losing control over their ML initiatives, facing operational bottlenecks, and failing to realize the full value of their data science investments. Large-scale MLOps is the key to unlocking the true potential of machine learning in the enterprise—turning innovative ideas into reliable, scalable, and impactful solutions.
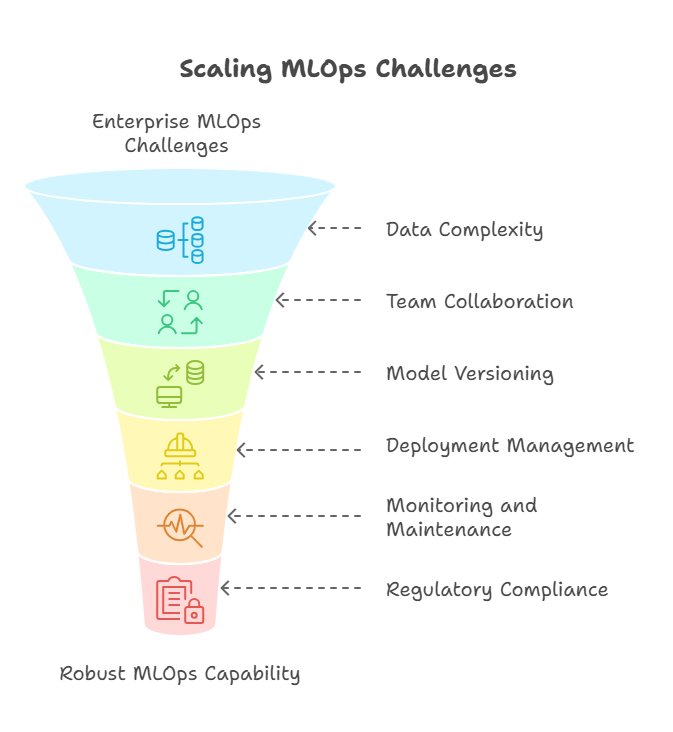
Key Challenges in Scaling MLOps for Enterprises
Scaling MLOps in an enterprise environment introduces a unique set of challenges that go far beyond those faced in small-scale or experimental machine learning projects. As organizations move from isolated models to managing entire fleets of ML systems, they encounter technical, organizational, and regulatory hurdles that require thoughtful solutions.
One of the primary challenges is data complexity and volume. Enterprises often deal with massive, heterogeneous datasets coming from multiple sources—structured databases, unstructured text, images, streaming data, and more. Ensuring data quality, consistency, and lineage at scale is a non-trivial task, especially when data is constantly evolving.
Another major challenge is collaboration across diverse teams. In large organizations, data scientists, ML engineers, DevOps specialists, and business stakeholders must work together. Aligning their workflows, tools, and expectations can be difficult, particularly when teams are distributed across different locations or time zones.
Model versioning and reproducibility also become critical at scale. With many models in development and production, tracking which data, code, and parameters were used for each version is essential for debugging, auditing, and compliance. Without robust version control, organizations risk deploying outdated or untested models.
Deployment and infrastructure management present further obstacles. Enterprises need to support a variety of deployment targets—on-premises servers, cloud platforms, edge devices—while ensuring scalability, reliability, and security. Automating deployment pipelines and managing resources efficiently is a complex engineering challenge.
Monitoring and maintenance are equally important. As the number of deployed models grows, so does the need for automated monitoring, alerting, and retraining. Detecting data drift, model degradation, or operational issues in real time is crucial to maintaining business value and trust.
Finally, regulatory compliance and security are top priorities, especially in industries like finance and healthcare. Enterprises must ensure that their MLOps processes meet strict requirements for data privacy, auditability, and explainability, which can add significant complexity to pipeline design and operations.
In summary, scaling MLOps in the enterprise is about much more than just technology—it’s about building processes, culture, and infrastructure that can support machine learning as a core business capability. Overcoming these challenges is essential for organizations that want to harness the full power of AI at scale.
Building Robust ML Pipelines: Architecture and Best Practices
Designing robust machine learning pipelines is a cornerstone of successful large-scale MLOps in the enterprise. A well-architected pipeline ensures that data flows smoothly from ingestion to model deployment, with each stage being automated, reproducible, and resilient to failure. This is especially important in enterprise environments, where reliability, scalability, and compliance are non-negotiable.
A typical enterprise ML pipeline consists of several key stages: data ingestion and validation, feature engineering, model training and evaluation, model validation, deployment, and ongoing monitoring. Each stage should be modular, allowing teams to update or replace components without disrupting the entire workflow. This modularity also supports experimentation and rapid iteration, which are crucial for innovation.
Automation is a best practice at every stage of the pipeline. Automated data validation helps catch errors early, while automated training and deployment reduce manual intervention and speed up the release cycle. Tools like Apache Airflow, Kubeflow Pipelines, and cloud-native solutions from AWS, Azure, or Google Cloud are commonly used to orchestrate these workflows.
Reproducibility is another critical aspect. Enterprises must ensure that every model can be traced back to the exact data, code, and parameters used during training. This is achieved through version control systems for both code and data, as well as metadata tracking for experiments and model artifacts.
Scalability is built into the architecture by leveraging distributed computing, containerization (e.g., Docker, Kubernetes), and cloud infrastructure. This allows pipelines to handle large datasets and high-throughput workloads without bottlenecks.
Resilience and fault tolerance are essential for minimizing downtime and data loss. Pipelines should include mechanisms for retrying failed steps, alerting on errors, and rolling back to previous stable versions if necessary.
Security and compliance must be integrated from the ground up. This includes access controls, data encryption, audit logging, and adherence to industry regulations.
In summary, building robust ML pipelines in the enterprise is about more than just connecting components—it’s about creating a flexible, automated, and secure architecture that can support the demands of large-scale machine learning. By following best practices in modularity, automation, reproducibility, scalability, and security, organizations can ensure their ML initiatives are both innovative and reliable.
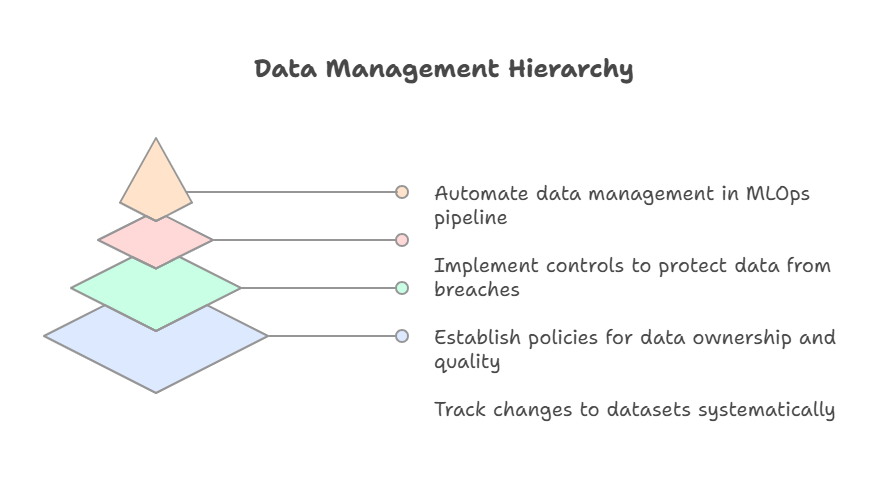
Data Management at Scale: Versioning, Governance, and Security
Effective data management is fundamental to large-scale MLOps in the enterprise. As organizations handle ever-growing volumes of data from diverse sources, ensuring that this data is accurate, accessible, and secure becomes a major challenge—and a critical success factor for machine learning initiatives.
Data versioning is the first pillar of robust data management. In enterprise settings, datasets are constantly evolving: new data is ingested, old data is updated, and corrections are made. Without systematic versioning, it becomes nearly impossible to reproduce experiments, audit model decisions, or roll back to previous states in case of errors. Tools like DVC (Data Version Control), LakeFS, and built-in features of cloud data platforms help track changes to datasets, enabling teams to link specific data versions to model training runs.
Data governance is equally important. Enterprises must establish clear policies for data ownership, access rights, and quality standards. This includes defining who can view, modify, or use certain datasets, as well as setting up processes for data validation and cleaning. Good governance ensures that only high-quality, relevant, and compliant data is used in ML pipelines, reducing the risk of bias, errors, or regulatory violations.
Security is a non-negotiable requirement, especially when dealing with sensitive or regulated data. Enterprises must implement strong access controls, encryption (both at rest and in transit), and regular audits to protect data from unauthorized access or breaches. Compliance with regulations such as GDPR, HIPAA, or industry-specific standards is essential, and often requires additional measures like data anonymization or detailed audit trails.
At scale, these aspects of data management must be automated and integrated into the MLOps pipeline. Automated data validation, lineage tracking, and policy enforcement help maintain data integrity and trustworthiness, even as the volume and complexity of data grow.
In summary, data management at scale is about more than just storage—it’s about creating a secure, governed, and versioned data ecosystem that supports reliable, auditable, and compliant machine learning. Enterprises that invest in strong data management practices lay the groundwork for successful, scalable, and trustworthy AI solutions.
Feature Stores in Enterprise MLOps
Feature stores have become a critical component of modern MLOps, especially at the enterprise level where teams must manage features across multiple projects, pipelines, and business units. A feature store is a centralized platform for storing, sharing, and serving features used in machine learning models, ensuring consistency, reusability, and governance throughout the ML lifecycle.
In large organizations, the same features—such as customer age, transaction frequency, or product category—are often used across different models and teams. Without a feature store, these features are typically engineered multiple times in silos, leading to duplication of effort, inconsistencies, and increased risk of errors. Feature stores solve this by providing a single source of truth for feature definitions, transformations, and metadata.
A robust enterprise feature store supports both batch and real-time feature serving, enabling models to access up-to-date data whether predictions are made in bulk or on demand. This is crucial for use cases like fraud detection or personalized recommendations, where low-latency access to fresh features can directly impact business outcomes.
Versioning and lineage tracking are also key benefits. Feature stores record how each feature was created, which data sources were used, and which models depend on them. This transparency supports reproducibility, auditing, and compliance—essential requirements in regulated industries.
Collaboration and governance are enhanced as well. Data scientists, ML engineers, and business analysts can discover, reuse, and improve features collaboratively, while access controls and approval workflows ensure that only validated features are used in production.
Popular enterprise feature store solutions include Feast, Tecton, Databricks Feature Store, and cloud-native offerings from AWS, Azure, and Google Cloud. These platforms integrate with existing data infrastructure and MLOps pipelines, making it easier to scale feature management as organizations grow.
In summary, feature stores are a foundational element of enterprise MLOps, enabling teams to build, deploy, and maintain high-quality ML models efficiently and at scale. By centralizing feature management, enterprises can accelerate development, reduce operational risk, and ensure consistency across all machine learning initiatives.
Automated Model Training, Validation, and Hyperparameter Tuning
Automating model training, validation, and hyperparameter tuning is a game-changer for enterprises operating at scale. Manual processes simply can’t keep up with the volume and complexity of modern machine learning workflows, especially when organizations need to train and maintain dozens or hundreds of models across different business domains.
Automated model training begins with orchestrating the end-to-end process: from data ingestion and preprocessing, through feature engineering, to model selection and training. Workflow orchestration tools like Kubeflow Pipelines, Apache Airflow, or cloud-native solutions enable teams to define, schedule, and monitor these steps, ensuring consistency and repeatability.
Validation is a critical step that must be integrated into the pipeline. Automated validation includes splitting data into training, validation, and test sets, running cross-validation, and evaluating models against predefined metrics. This ensures that only models meeting quality standards move forward to deployment, reducing the risk of performance issues in production.
Hyperparameter tuning is another area where automation delivers significant value. Instead of manually searching for the best model parameters, enterprises leverage automated techniques such as grid search, random search, or more advanced methods like Bayesian optimization and evolutionary algorithms. Tools like Optuna, Ray Tune, or built-in services from cloud providers can run hundreds or thousands of experiments in parallel, dramatically accelerating the search for optimal configurations.
Automation also supports experiment tracking and reproducibility. By logging every run, parameter set, and result, teams can compare models, reproduce results, and audit decisions—crucial for compliance and continuous improvement.
Finally, automated retraining can be triggered by monitoring pipelines when data drift or model degradation is detected, ensuring that models remain accurate and relevant over time.
In summary, automating model training, validation, and hyperparameter tuning empowers enterprises to scale their ML operations, improve model quality, and respond quickly to changing business needs. It transforms machine learning from a manual, artisanal process into a robust, industrialized capability that drives real business value.
CI/CD for Machine Learning in Large Organizations
Continuous Integration and Continuous Deployment (CI/CD) are well-established practices in software engineering, but their adoption in machine learning brings unique challenges and transformative benefits—especially at enterprise scale. Implementing CI/CD for ML enables organizations to deliver new models and updates rapidly, reliably, and with minimal manual intervention.
In the context of machine learning, CI/CD pipelines automate the process of building, testing, and deploying not just code, but also data, models, and configurations. This means every change—whether it’s a new feature engineering script, an updated dataset, or a retrained model—can be automatically validated and promoted through the pipeline.
A typical ML CI/CD workflow in a large organization includes several key steps. First, code and data changes are committed to version control systems like Git. Automated tests are triggered to validate data quality, code correctness, and model performance. If all checks pass, the pipeline proceeds to build and package the model, often using containerization tools like Docker for consistency across environments.
Next, the model is deployed to staging or production environments using orchestration platforms such as Kubernetes, SageMaker, or Azure ML. Automated monitoring and rollback mechanisms ensure that if a new model underperforms or causes issues, the system can quickly revert to a previous stable version.
Collaboration and governance are enhanced by CI/CD, as every change is tracked, reviewed, and auditable. This is especially important in regulated industries, where traceability and compliance are required.
Scalability is another major benefit. With automated pipelines, organizations can manage the deployment and maintenance of many models simultaneously, reducing bottlenecks and freeing up teams to focus on innovation rather than manual operations.
In summary, CI/CD for machine learning is a foundational practice for large organizations aiming to scale their AI initiatives. By automating the end-to-end lifecycle—from development to deployment and monitoring—enterprises can achieve faster iteration, higher reliability, and greater business impact from their machine learning investments.
Model Deployment Strategies: Batch, Real-Time, and Edge
Deploying machine learning models at scale in the enterprise requires flexible strategies that match business needs, technical constraints, and user expectations. The three most common deployment approaches—batch, real-time (online), and edge—each have distinct advantages and use cases.
Batch deployment involves running models on large volumes of data at scheduled intervals. This approach is ideal for scenarios where immediate predictions aren’t necessary, such as generating nightly sales forecasts, updating customer segments, or processing historical transaction data. Batch jobs are typically orchestrated using workflow tools like Apache Airflow or cloud-native schedulers, and results are stored for downstream applications to consume.
Real-time (online) deployment serves predictions instantly in response to user or system requests. This is essential for use cases like fraud detection, personalized recommendations, or dynamic pricing, where latency and responsiveness directly impact business outcomes. Real-time models are often deployed as REST APIs or microservices, managed by platforms such as Kubernetes, AWS SageMaker, or Google Vertex AI. These deployments require robust monitoring, autoscaling, and failover mechanisms to ensure high availability and reliability.
Edge deployment pushes models directly to devices at the edge of the network—such as smartphones, IoT sensors, or industrial equipment. This strategy is crucial when low latency, offline operation, or data privacy are priorities. Edge deployment enables real-time inference without relying on constant connectivity to the cloud, making it suitable for applications like predictive maintenance, autonomous vehicles, or on-device personalization. Tools like TensorFlow Lite, ONNX, and cloud IoT platforms support efficient model packaging and distribution to edge devices.
Enterprises often use a combination of these strategies, depending on the specific requirements of each application. For example, a retail company might use batch models for inventory planning, real-time models for personalized offers, and edge models for in-store analytics.
In summary, choosing the right deployment strategy—or mix of strategies—is essential for delivering scalable, reliable, and impactful machine learning solutions in the enterprise. By aligning deployment approaches with business goals and technical realities, organizations can maximize the value of their ML investments across diverse use cases.
Monitoring, Logging, and Automated Retraining in Production
Once machine learning models are deployed in production, the work is far from over. In fact, ongoing monitoring, logging, and automated retraining are essential for ensuring that models continue to deliver accurate, reliable, and trustworthy results at scale. For enterprises, these practices are critical to maintaining business value, meeting compliance requirements, and responding quickly to changing data or market conditions.
Monitoring involves continuously tracking both model performance and operational health. Key metrics include prediction accuracy, latency, throughput, and resource utilization, as well as business-specific indicators like conversion rates or fraud detection rates. Just as important is monitoring for data drift and concept drift—situations where the input data or the relationship between features and target variables changes over time, potentially degrading model performance. Modern monitoring tools such as Evidently AI, Arize AI, and built-in solutions from cloud providers help automate the detection of these issues and trigger alerts when anomalies are found.
Logging provides a detailed record of model inputs, outputs, and system events. Comprehensive logs are invaluable for debugging, auditing, and compliance, especially in regulated industries. They enable teams to trace predictions back to specific data points, investigate failures, and demonstrate accountability to stakeholders or regulators.
Automated retraining closes the loop by enabling models to adapt to new data and evolving patterns. When monitoring systems detect significant drift or performance degradation, automated pipelines can trigger retraining jobs using the latest data. This process may include data validation, feature engineering, model selection, and validation steps, all orchestrated with minimal manual intervention. Automated retraining ensures that models remain relevant and effective, reducing the risk of business disruption or missed opportunities.
In large organizations, integrating monitoring, logging, and retraining into the MLOps pipeline is essential for scaling machine learning operations. These practices not only safeguard model quality and compliance but also free up teams to focus on innovation rather than firefighting.
In summary, robust monitoring, logging, and automated retraining are the backbone of reliable ML in production. By investing in these capabilities, enterprises can ensure their models deliver sustained value, adapt to change, and operate with confidence in dynamic real-world environments.
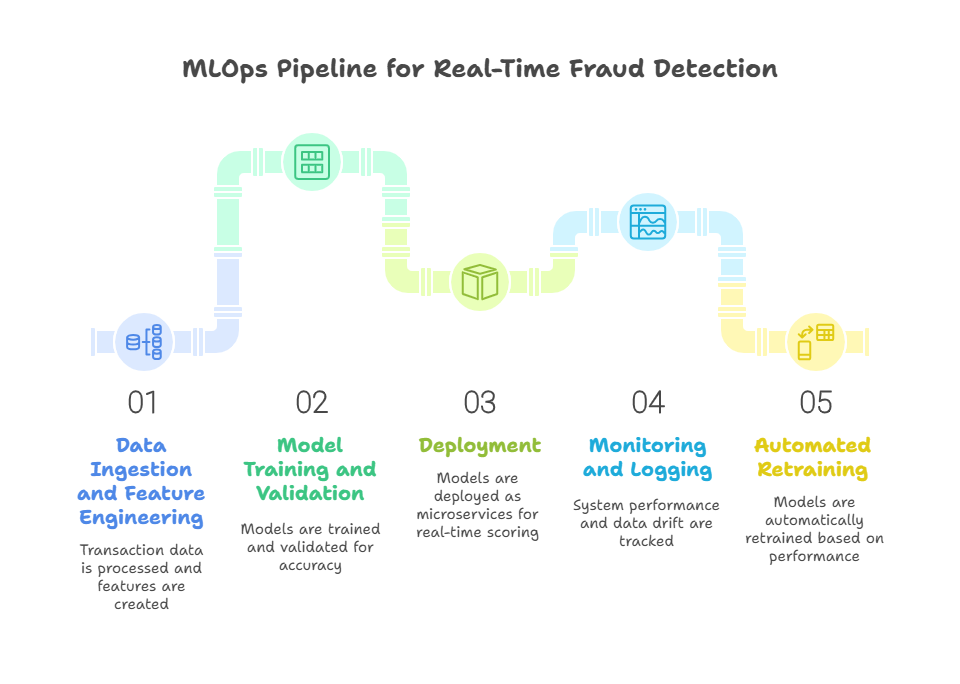
Case Study 1: Financial Services – Real-Time Fraud Detection
In the financial services industry, real-time fraud detection is a mission-critical application of machine learning that demonstrates the power and complexity of large-scale MLOps. Enterprises in this sector must process millions of transactions per day, identify suspicious activity within milliseconds, and adapt rapidly to evolving fraud tactics—all while maintaining strict regulatory compliance and data security.
Business Challenge:
A global bank wanted to modernize its fraud detection system, moving from rule-based approaches to machine learning models capable of detecting subtle, emerging fraud patterns. The goal was to deploy models that could analyze transactions in real time, minimize false positives, and continuously improve as new data became available.
MLOps Solution:
The bank implemented a robust MLOps pipeline designed for real-time inference and rapid iteration. Key components included:
Data Ingestion and Feature Engineering: Transaction data, customer profiles, and device information were ingested from multiple sources and processed in near real time. A feature store was used to ensure consistency and reusability of features across different models and teams.
Model Training and Validation: Automated pipelines orchestrated regular retraining using the latest labeled data, with rigorous validation to ensure high precision and recall. Hyperparameter tuning was automated to optimize model performance.
Deployment: Models were deployed as microservices on a scalable Kubernetes cluster, exposing REST APIs for real-time scoring. Canary deployments and A/B testing were used to safely roll out new models and monitor their impact.
Monitoring and Logging: Advanced monitoring tools tracked prediction accuracy, latency, and data drift. Detailed logs enabled rapid investigation of false positives and compliance with audit requirements.
Automated Retraining: When monitoring detected performance degradation or new fraud patterns, retraining pipelines were triggered automatically, ensuring the system stayed ahead of emerging threats.
Outcomes:
The new MLOps-driven system reduced fraud losses, improved customer experience by minimizing transaction delays and false alarms, and enabled the bank to respond quickly to new fraud schemes. The integration of monitoring, logging, and automated retraining ensured that the models remained effective and compliant, even as transaction volumes and fraud tactics evolved.
Summary:
This case study highlights how large-scale MLOps empowers financial institutions to deploy, monitor, and maintain real-time ML solutions that deliver tangible business value. By automating the end-to-end lifecycle and building in resilience, enterprises can stay agile and secure in the face of ever-changing risks.
Case Study 2: Retail – Personalized Recommendation Systems
Personalized recommendation systems are a cornerstone of modern retail, driving customer engagement, increasing sales, and enhancing the overall shopping experience. At enterprise scale, building and maintaining these systems requires sophisticated MLOps practices to handle massive data volumes, rapid model iteration, and seamless integration with business operations.
Business Challenge:
A leading e-commerce retailer aimed to boost conversion rates and customer satisfaction by delivering highly personalized product recommendations in real time. The challenge was to process millions of user interactions daily, update recommendations as customer behavior changed, and ensure that the system could scale during peak shopping periods.
MLOps Solution:
The retailer adopted a comprehensive MLOps framework to support the end-to-end lifecycle of their recommendation models:
Data Management and Feature Engineering: User activity logs, product metadata, and contextual information (such as time of day or device type) were ingested and processed using a centralized feature store. This enabled consistent, reusable features across multiple recommendation models.
Automated Model Training and Validation: The team implemented automated pipelines for regular retraining and validation, leveraging historical and real-time data. Hyperparameter tuning and experiment tracking ensured that only the best-performing models were promoted to production.
Deployment Strategies: Models were deployed as scalable microservices, with real-time APIs integrated into the retailer’s website and mobile app. Blue-green deployments and shadow testing allowed for safe model updates without disrupting the user experience.
Monitoring and Logging: Continuous monitoring tracked key metrics such as click-through rates, conversion rates, and model latency. Detailed logs supported rapid troubleshooting and compliance with data privacy regulations.
Automated Retraining: The system automatically triggered retraining when significant changes in user behavior or product catalog were detected, ensuring recommendations stayed relevant and effective.
Outcomes:
The MLOps-driven approach led to a measurable increase in sales and customer engagement. The ability to rapidly iterate and deploy new models allowed the retailer to respond quickly to trends, seasonal changes, and promotional campaigns. Automated monitoring and retraining minimized manual intervention and kept the system performing at a high level, even as data and business needs evolved.
Summary:
This case study illustrates how enterprise MLOps enables retailers to deliver personalized, scalable, and reliable recommendation systems. By automating the ML lifecycle and integrating robust monitoring, organizations can continuously enhance customer experiences and drive business growth.
Case Study 3: Healthcare – Predictive Analytics at Scale
In the healthcare sector, predictive analytics is transforming patient care, resource allocation, and operational efficiency. A leading healthcare provider implemented a large-scale predictive analytics platform to identify high-risk patients, reduce hospital readmissions, and optimize population health management. By integrating data from electronic health records, claims, and social determinants of health, the organization used machine learning models to proactively target interventions for patients most at risk of chronic disease or hospitalization.
Key elements of the solution included:
Holistic Data Integration: Combining clinical, claims, and social data for a comprehensive patient view.
Automated Model Training and Validation: Regular retraining pipelines ensured models adapted to new data and changing patient populations.
Real-Time Monitoring: Dashboards and alerting systems enabled clinicians to act quickly on model insights.
Governance and Compliance: Strict data governance and audit trails ensured HIPAA and GDPR compliance.
Here’s a practical implementation of a healthcare predictive analytics pipeline:
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.metrics import classification_report, roc_auc_score
import joblib
import logging
from datetime import datetime
import warnings
warnings.filterwarnings('ignore')
# Configure logging for audit trails
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('healthcare_mlops.log'),
logging.StreamHandler()
]
)
class HealthcarePredictiveModel:
"""
Healthcare Predictive Analytics Model for Hospital Readmission Risk
"""
def __init__(self):
self.model = None
self.scaler = StandardScaler()
self.label_encoders = {}
self.feature_names = None
def load_and_preprocess_data(self, file_path):
"""
Load and preprocess healthcare data
"""
logging.info("Loading healthcare data...")
# Simulate healthcare dataset
np.random.seed(42)
n_patients = 10000
data = {
'patient_id': range(1, n_patients + 1),
'age': np.random.normal(65, 15, n_patients),
'gender': np.random.choice(['M', 'F'], n_patients),
'diabetes': np.random.choice([0, 1], n_patients, p=[0.7, 0.3]),
'hypertension': np.random.choice([0, 1], n_patients, p=[0.6, 0.4]),
'heart_disease': np.random.choice([0, 1], n_patients, p=[0.8, 0.2]),
'previous_admissions': np.random.poisson(2, n_patients),
'length_of_stay': np.random.exponential(5, n_patients),
'emergency_visits': np.random.poisson(1, n_patients),
'medication_adherence': np.random.uniform(0.5, 1.0, n_patients),
'social_support_score': np.random.normal(7, 2, n_patients),
'income_level': np.random.choice(['Low', 'Medium', 'High'], n_patients, p=[0.4, 0.4, 0.2])
}
df = pd.DataFrame(data)
# Create target variable (readmission risk)
risk_score = (
0.3 * df['age'] / 100 +
0.2 * df['diabetes'] +
0.2 * df['hypertension'] +
0.3 * df['heart_disease'] +
0.1 * df['previous_admissions'] / 5 +
0.2 * df['emergency_visits'] / 3 +
-0.1 * df['medication_adherence'] +
-0.1 * df['social_support_score'] / 10
)
df['readmission_risk'] = (risk_score + np.random.normal(0, 0.1, n_patients) > 0.5).astype(int)
logging.info(f"Loaded {len(df)} patient records")
return df
def feature_engineering(self, df):
"""
Perform feature engineering for healthcare data
"""
logging.info("Performing feature engineering...")
# Age groups
df['age_group'] = pd.cut(df['age'], bins=[0, 30, 50, 70, 100],
labels=['Young', 'Middle', 'Senior', 'Elderly'])
# Risk factors count
df['risk_factors_count'] = df['diabetes'] + df['hypertension'] + df['heart_disease']
# Healthcare utilization score
df['utilization_score'] = (df['previous_admissions'] * 0.4 +
df['emergency_visits'] * 0.6)
# Encode categorical variables
categorical_cols = ['gender', 'age_group', 'income_level']
for col in categorical_cols:
if col not in self.label_encoders:
self.label_encoders[col] = LabelEncoder()
df[col + '_encoded'] = self.label_encoders[col].fit_transform(df[col])
else:
df[col + '_encoded'] = self.label_encoders[col].transform(df[col])
return df
def train_model(self, df):
"""
Train the predictive model
"""
logging.info("Training predictive model...")
# Select features
feature_cols = [
'age', 'diabetes', 'hypertension', 'heart_disease',
'previous_admissions', 'length_of_stay', 'emergency_visits',
'medication_adherence', 'social_support_score', 'risk_factors_count',
'utilization_score', 'gender_encoded', 'age_group_encoded', 'income_level_encoded'
]
X = df[feature_cols]
y = df['readmission_risk']
self.feature_names = feature_cols
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Scale features
X_train_scaled = self.scaler.fit_transform(X_train)
X_test_scaled = self.scaler.transform(X_test)
# Train model
self.model = RandomForestClassifier(
n_estimators=100,
max_depth=10,
random_state=42,
class_weight='balanced'
)
self.model.fit(X_train_scaled, y_train)
# Evaluate model
y_pred = self.model.predict(X_test_scaled)
y_pred_proba = self.model.predict_proba(X_test_scaled)[:, 1]
auc_score = roc_auc_score(y_test, y_pred_proba)
logging.info(f"Model trained successfully. AUC Score: {auc_score:.3f}")
print("\nClassification Report:")
print(classification_report(y_test, y_pred))
# Feature importance
feature_importance = pd.DataFrame({
'feature': feature_cols,
'importance': self.model.feature_importances_
}).sort_values('importance', ascending=False)
print("\nTop 10 Most Important Features:")
print(feature_importance.head(10))
return X_test_scaled, y_test, y_pred_proba
def predict_risk(self, patient_data):
"""
Predict readmission risk for new patients
"""
if self.model is None:
raise ValueError("Model not trained yet!")
# Preprocess patient data
patient_df = pd.DataFrame([patient_data])
patient_df = self.feature_engineering(patient_df)
# Select features and scale
X = patient_df[self.feature_names]
X_scaled = self.scaler.transform(X)
# Predict
risk_probability = self.model.predict_proba(X_scaled)[0, 1]
risk_category = "High" if risk_probability > 0.7 else "Medium" if risk_probability > 0.3 else "Low"
return {
'risk_probability': risk_probability,
'risk_category': risk_category,
'timestamp': datetime.now().isoformat()
}
def save_model(self, model_path):
"""
Save trained model and preprocessing components
"""
model_artifacts = {
'model': self.model,
'scaler': self.scaler,
'label_encoders': self.label_encoders,
'feature_names': self.feature_names
}
joblib.dump(model_artifacts, model_path)
logging.info(f"Model saved to {model_path}")
def load_model(self, model_path):
"""
Load trained model and preprocessing components
"""
model_artifacts = joblib.load(model_path)
self.model = model_artifacts['model']
self.scaler = model_artifacts['scaler']
self.label_encoders = model_artifacts['label_encoders']
self.feature_names = model_artifacts['feature_names']
logging.info(f"Model loaded from {model_path}")
def monitor_model_performance(y_true, y_pred_proba, threshold=0.05):
"""
Monitor model performance and detect drift
"""
current_auc = roc_auc_score(y_true, y_pred_proba)
# Simulate baseline AUC (in production, this would be stored)
baseline_auc = 0.85
performance_drift = abs(current_auc - baseline_auc)
if performance_drift > threshold:
logging.warning(f"Performance drift detected! Current AUC: {current_auc:.3f}, "
f"Baseline AUC: {baseline_auc:.3f}, Drift: {performance_drift:.3f}")
return True
else:
logging.info(f"Model performance stable. Current AUC: {current_auc:.3f}")
return False
# Main execution
if __name__ == "__main__":
# Initialize model
healthcare_model = HealthcarePredictiveModel()
# Load and preprocess data
df = healthcare_model.load_and_preprocess_data("healthcare_data.csv")
df = healthcare_model.feature_engineering(df)
# Train model
X_test, y_test, y_pred_proba = healthcare_model.train_model(df)
# Monitor performance
drift_detected = monitor_model_performance(y_test, y_pred_proba)
# Save model
healthcare_model.save_model("healthcare_readmission_model.pkl")
# Example prediction for a new patient
new_patient = {
'age': 72,
'gender': 'M',
'diabetes': 1,
'hypertension': 1,
'heart_disease': 0,
'previous_admissions': 3,
'length_of_stay': 7.5,
'emergency_visits': 2,
'medication_adherence': 0.6,
'social_support_score': 5.0,
'income_level': 'Low'
}
prediction = healthcare_model.predict_risk(new_patient)
print(f"\nPrediction for new patient:")
print(f"Risk Probability: {prediction['risk_probability']:.3f}")
print(f"Risk Category: {prediction['risk_category']}")
# Created/Modified files during execution:
print("\nCreated/Modified files during execution:")
for file_name in ["healthcare_mlops.log", "healthcare_readmission_model.pkl"]:
print(file_name)This implementation demonstrates key aspects of healthcare MLOps at scale, including data integration, automated model training, real-time monitoring, and compliance logging. The code provides a foundation for building production-ready healthcare predictive analytics systems while maintaining the governance and audit trails essential in healthcare environments.
Lessons Learned: Common Pitfalls and How to Avoid Them
1. Data Silos and Incomplete Integration:
Many healthcare analytics projects fail when data remains fragmented across departments. Successful initiatives break down silos, integrate diverse data sources, and ensure data quality from the outset.
2. Lack of Clinical Buy-In:
Predictive models are only as effective as their adoption by clinicians. Engaging end-users early, providing explainable AI outputs, and integrating insights into existing workflows are critical for success.
3. Overlooking Social Determinants:
Focusing solely on clinical data can limit model accuracy. Including social and behavioral data provides a fuller picture of patient risk and leads to better interventions.
4. Insufficient Model Monitoring:
Without continuous monitoring, models can quickly become outdated due to data drift or changing patient populations. Automated retraining and performance tracking are essential.
5. Compliance and Privacy Risks:
Healthcare data is highly sensitive. Robust governance, access controls, and audit trails are non-negotiable to avoid regulatory penalties and maintain patient trust.
Future Trends in Enterprise MLOps
AI-Driven Automation:
MLOps platforms will increasingly automate data integration, feature engineering, model selection, and retraining, reducing manual effort and accelerating time-to-value.
Unified Observability:
Enterprises will adopt unified monitoring platforms that track data quality, model performance, and business outcomes in real time, enabling rapid response to issues.
Edge and Federated Learning:
With the rise of IoT and privacy concerns, more healthcare models will be trained and deployed at the edge or using federated learning, keeping data local and secure.
Explainability and Responsible AI:
As regulations tighten, explainable AI and bias detection will become standard features in enterprise MLOps, ensuring transparency and fairness in model decisions.
Low-Code/No-Code MLOps:
To democratize AI, low-code and no-code platforms will empower clinicians and business users to build, deploy, and monitor models without deep technical expertise.
Conclusion: Building Sustainable and Scalable MLOps Solutions
Large-scale MLOps is the backbone of sustainable, impactful AI in healthcare and beyond. By investing in robust data integration, automated pipelines, continuous monitoring, and strong governance, enterprises can unlock the full potential of predictive analytics. Avoiding common pitfalls—such as data silos, lack of user engagement, and insufficient monitoring—ensures that models remain accurate, trusted, and compliant.
Looking ahead, embracing automation, unified observability, and responsible AI practices will be key to scaling MLOps successfully. Organizations that prioritize these strategies will be best positioned to deliver better outcomes for patients, providers, and the business as a whole.
The Future of MLOps: Trends and Innovations in Machine Learning Operations
MLOps in the Era of Generative Artificial Intelligence: New Challenges and Opportunities